K-近邻
首先K-近邻是个分类问题,属于所谓的有监督学习
1、工作原理:
计算一个点A与样本空间所有点之间的距离,取出与该点最近的K个点,然后统计出K个点里面所属分类比例最大的分类,则该点A就属于这个所占比例最大的分类
2、算法步骤:
- 计算距离:给定测试对象,计算它与训练集中的每个对象的距离
- 找最近的K个邻居:圈定距离最近的K个训练对象,作为测试对象的近邻
- 根据这K个邻居确定分类:根据K个近邻归属的主要类别,来测试对象分类
3、计算距离的方式(相似性度量):
- 欧式距离:
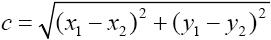
- 曼哈顿距:

4、类别的判定方法:
- 投票法:
- 加权投票法:
5、优缺点:
- 优点:给新对象分类的时候,不需要基于训练数据建立模型;算法简单易懂;
- 缺点:因为要算测试点到每个样本点的距离,所以计算量大;样本容量小还容易产生误会
6、接下来就是手动实现这个算法过程:
下面我写了两份代码,基本大差不差,就是个别地方有更改,先放几张第二份代码的运行截图看看效果:




第一份代码
import csv import numpy as np import matplotlib.pyplot as plt def createDataSet(): dataset = [] for line in open("data.csv"): x, y, label = line.split(",") dataset.append([int(x), int(y), int(label)]) return dataset # 计算各点到预测点的距离 def calcDis(dataSet, socuse, k): calcList = [] for i in range(len(dataSet)): calcList.append( (((socuse[0] - dataSet[i][0]) ** 2 + (socuse[1] - dataSet[i][1]) ** 2) ** 0.5)) # print("各点与质心的距离:",calcList) calcList = np.array(calcList) dis_sort_index = np.argsort(calcList) # 排序并且得到的是下标 dis_sort_index_near = dis_sort_index[0:k] # 取得前k个下标 for i in dis_sort_index_near: # 查看前k个到底是哪一类 print(dataSet[i]) # print(dis_sort_index_near) # labels = [] counts = [0, 0, 0] # 统计前k名中三个标签出现的次数 for i in range(k): # labels.append(dataSet[dis_sort_index_near[i]]) # print(dataSet[dis_sort_index_near[i]][2]) counts[dataSet[dis_sort_index_near[i]][2]] += 1 print(counts) max_label = 0 max_value = 0 for i in range(3): if counts[i] > max_value: max_value = counts[i] max_label = i return max_label if __name__ == '__main__': dataSet = createDataSet() for data in dataSet: plt.scatter(data[0], data[1], marker='o', color='green', s=40, label='原始点') a = [14, 17] plt.scatter(a[0], a[1], marker='o', color='red', s=40, label='预测点') plt.show() b = calcDis(dataSet, a, 5) print(a, "被预测为的类别是:", b)
第二份代码
import csv import numpy as np import matplotlib.pyplot as plt # 每个数据包括三列,[x,y,label] .x,y分别为两个属性,label为该数据的类别 def createDataSet(): dataset = [] for line in open("data.csv"): x, y, label = line.split(",") dataset.append([int(x), int(y), int(label)]) return dataset # 计算各点到预测点的距离 def calcDis(dataSet, socuse, k): calcList = [] dataSet = np.array(dataSet) dataSize = dataSet.shape[0] dataSet1 = np.delete(dataSet, 2, axis=1) """ 将socuse在横向重复dataSetSize次,纵向重复1次 例如socuse=([1,2])--->([[1,2],[1,2],[1,2],[1,2]])便于后面计算距离 """ diff = np.tile(socuse, (dataSize, 1)) - dataSet1 """ 计算距离:欧式距离, 特征相减后乘方,然后再开方 """ sqdifMax = diff ** 2 seqDistances = sqdifMax.sum(axis=1) calcList = seqDistances ** 0.5 # print(calcList) # for i in range(len(dataSet)): # calcList.append( # (((socuse[0] - dataSet[i][0]) ** 2 + (socuse[1] - dataSet[i][1]) ** 2) ** 0.5)) # # print("各点与质心的距离:",calcList) # calcList = np.array(calcList) dis_sort_index = np.argsort(calcList) # 排序并且得到的是排序后的下标 # dis_sort_index_near = dis_sort_index[0:k] # 取得前k个下标 for i in range(k): # 查看前k个到底是哪一类 print(dataSet[dis_sort_index[i]]) # print(dis_sort_index_near) # labels = [] counts = [0, 0, 0] # 记录前k个数据中各标签出现的个数 for i in range(k): # labels.append(dataSet[dis_sort_index_near[i]]) # print(dataSet[dis_sort_index_near[i]][2]) # counts[dataSet[dis_sort_index_near[i]][2]] += 1 counts[dataSet[dis_sort_index[i]][2]] += 1 max_label = 0 # max_value = 0 # for i in range(5): # if counts[i] > max_value: # max_value = counts[i] # max_label = i # print(counts) counts_sort = np.argsort(counts) # print(counts_sort) max_label = counts_sort[2] return max_label, dis_sort_index[0:k] if __name__ == '__main__': dataSet = createDataSet() for data in dataSet: plt.scatter(data[0], data[1], marker='o', color='green', s=40, label='原始点') a = [45, 17] plt.scatter(a[0], a[1], marker='o', color='red', s=40, label='预测点') k = 5 b, near_point = calcDis(dataSet, a, k) print(a, "被预测为的类别是:", b) ''' 增加预测点与最近点的连线 ''' x = [] y = [] for i in range(k): x.append(a[0]) y.append(a[1]) x.append(dataSet[near_point[i]][0]) y.append(dataSet[near_point[i]][1]) plt.plot(x, y, color='r', linewidth=0.5) # print(a, dataSet[near_point[i]][:2]) plt.show()
上面的代码和data.csv都已经上传GitHub: GitHub入口

 浙公网安备 33010602011771号
浙公网安备 33010602011771号