

go map源码
概要
分别讲
- bmap
- hmap
- get方法的逻辑
这是一个bmap
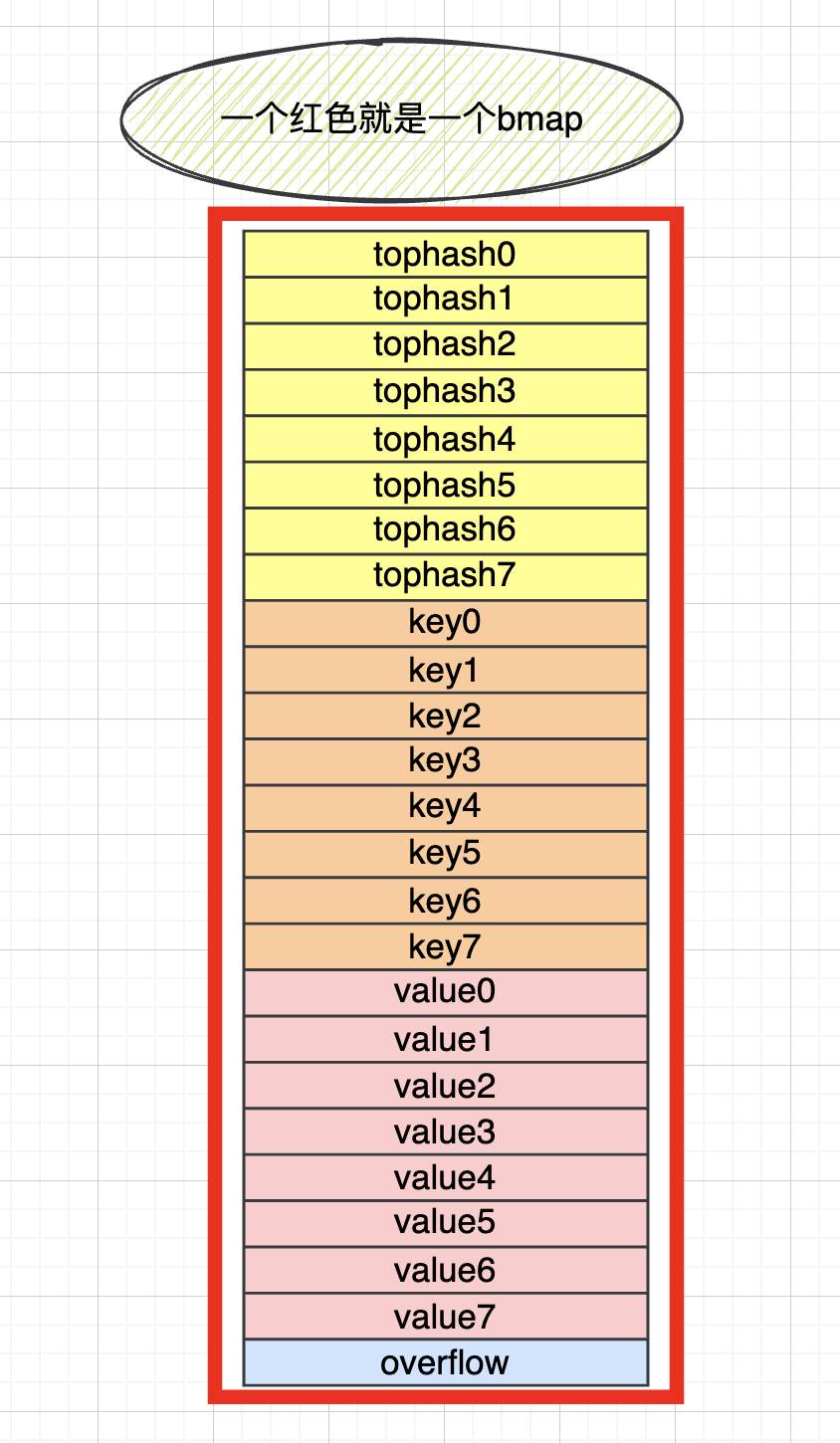
bmap里面包含
-
一个长度为8的tophash数组,保持了每个key的高8位hash值和状态信息
-
-
状态具体,包括,
-
某一个位置是不是空的,
-
是不是正在扩容,等等
-
-
一个长度为8的key数组,保存了key
-
一个长度为8的value数组,保存了value
-
一个指向溢出桶的指针,!实际使用了在内存中移动地址的方式获取到下一个桶,
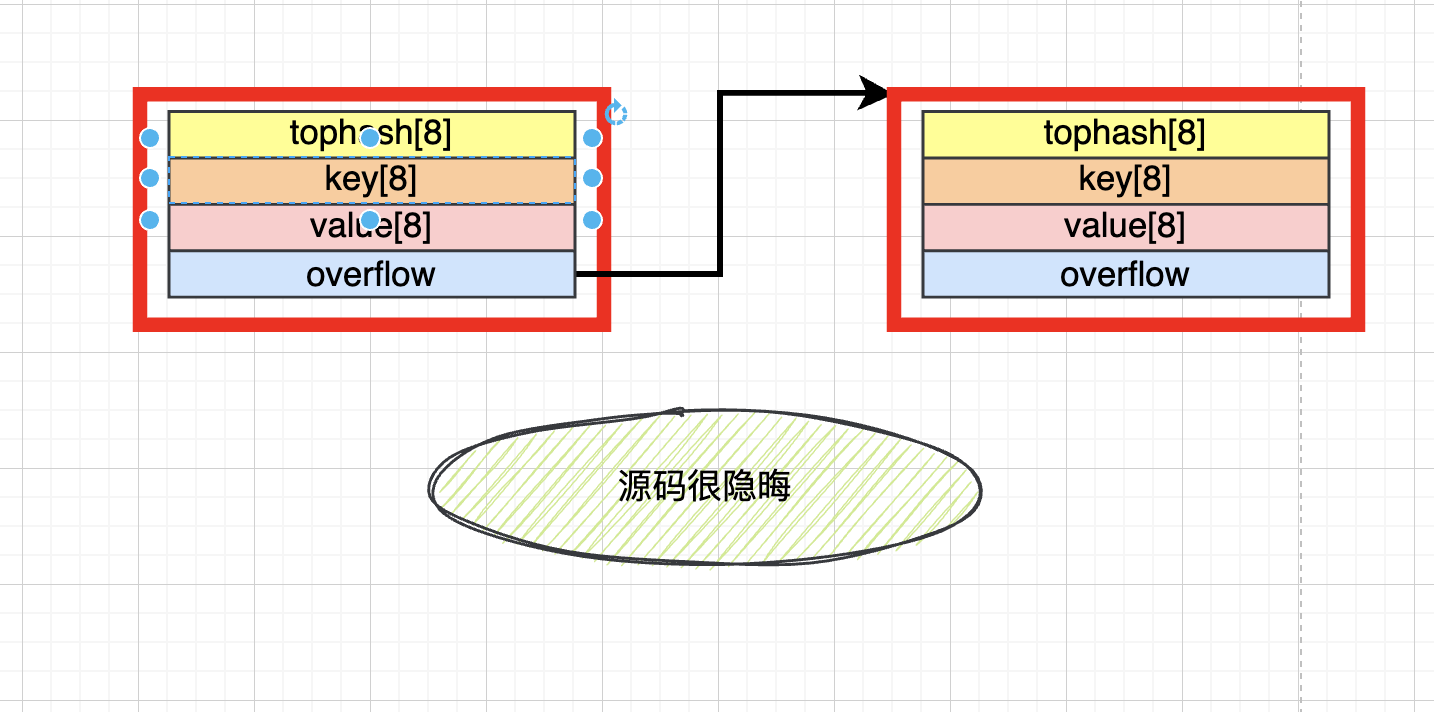
这里使用了内存对齐形式的排列方式
什么是内存对齐?
1
数据在内存上不是紧密排布的,不是一个数据挨着一个数据排列的,而是数据一定会放在自己宽度的整倍数上,这是因为cpu由于硬件限制只能从0,4,8这样的起始位置一次取4个字节(假设要取一个 4字节的int)
2
举例子
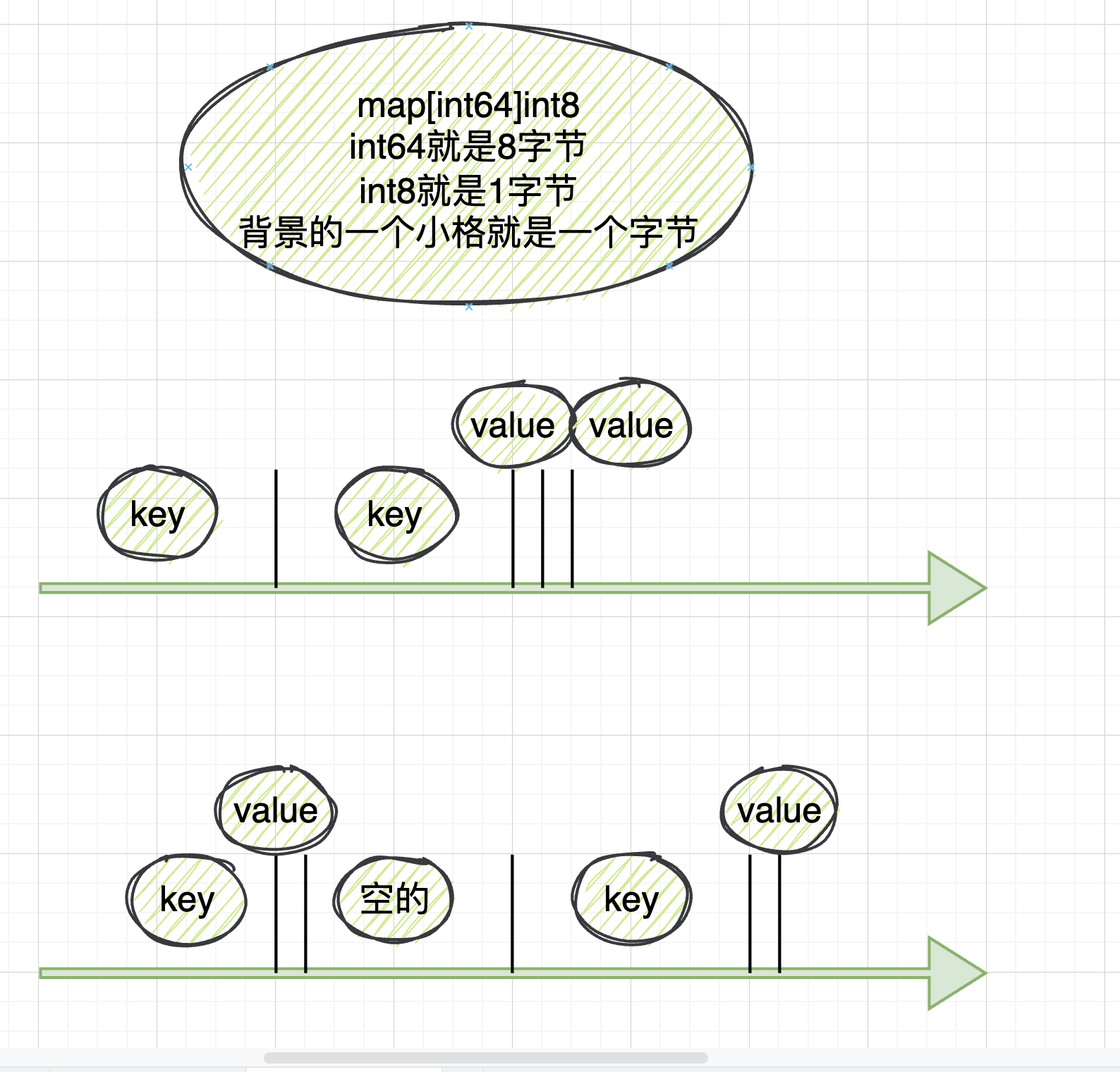
如果是map[int64]int8
int64就是8字节
int8就是1字节
背景的一个小格就是一个字节
然后
假设这个map有2个元素
按内存对齐的排列方式,需要 每个key占8字节,2个value一共占8字节。总共:8*3=24字节
按一般的排列方式,需要,第一个key占8字节,第一个value占8字节,第2个key再占8字节,第2个value再占8字节,总共:8*4=32字节。
如果不对齐,有空闲的,有点浪费内存(上面画的是数据在内存上的排布吗,为什么有空?是的,是内存排布,这么空就是规则。数据在内存的是在宽度的整数倍上排列的。假设此时按8字节为最小内存单元大小。)
3
所以做成内存对齐的结构更节省空间
再讲hmap
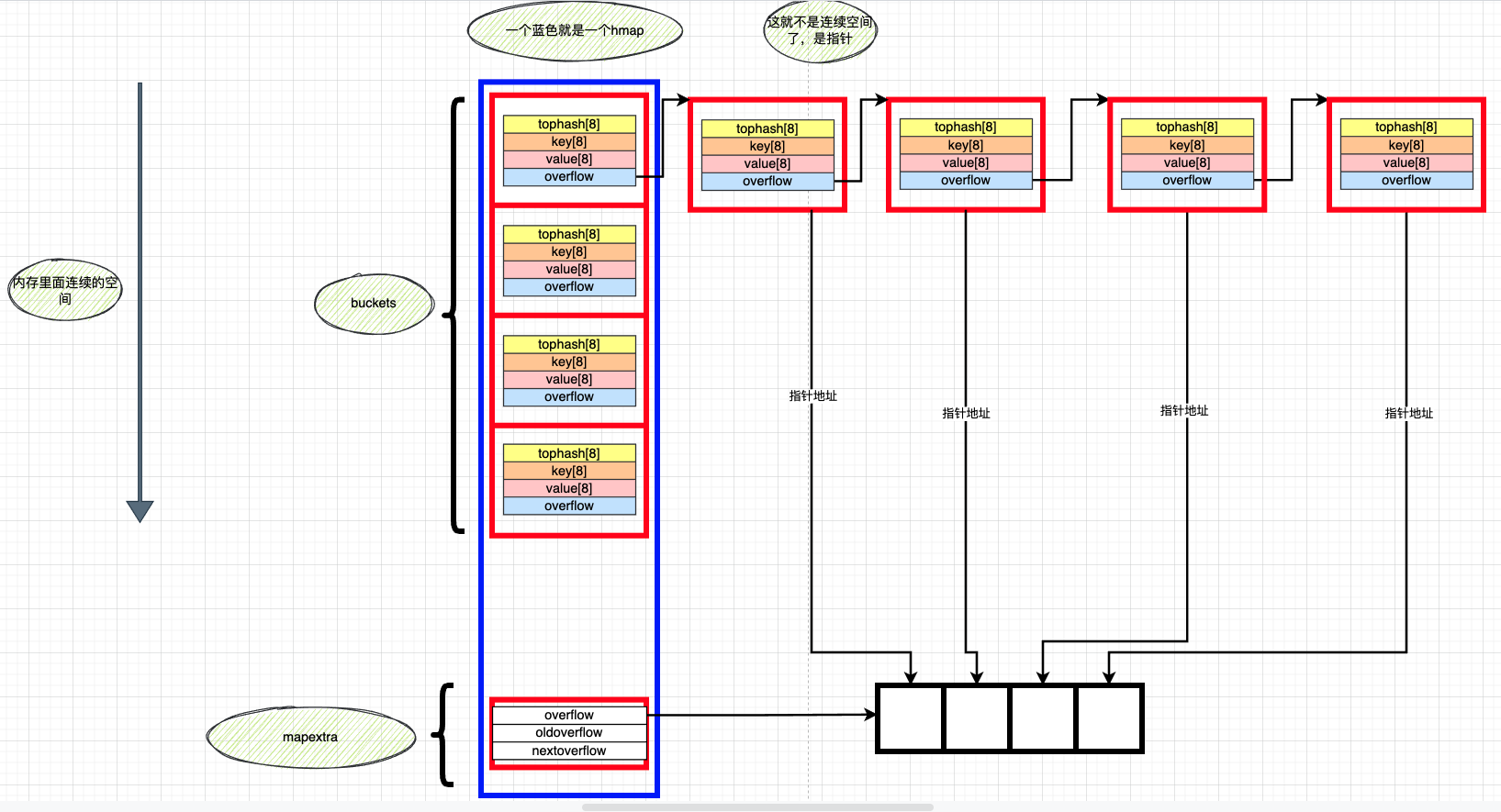
这是一个hmap
1
hmap使用数组+链表法存储数据
hmap里面的buckets,就是他的数组,就是多个bmap,是内存中申请的一片连续的空间
2
mapextra里面存overflow是一个数组
数组里面存了bmap上溢出桶的指针
所以说溢出桶有2种访问方式
hmap.mapextra.overflow的数组可以找到
从bmap.overflow也可以找到
3
hmap的oldbuckets用于扩容
get的逻辑
-
计算hash
-
找到桶
-
-
取hash值的低B位bit找到桶
-
ps:源码中大量使用了位运算来加速
-
如果当前桶没有,尝试去找溢出桶
-
-
找到桶中的8个位置的哪一个位置
-
-
先比较tophash,如果相同,那么继续比较key
-
如果key相同就找到了
-
PS:get方法有2种,一种带是否存在key的bool返回,一种不带。本质上2个函数,逻辑一样
-
PS:用于选择桶序号的是哈希的最低B位,而用于加速访问的是哈希的高 8 位,这种设计能够减少同一个桶中有大量相等 tophash 的概率影响性能
找桶的例子:
假设是4个桶,B=2,桶掩码就是 0b11
不过hash值是多少,低B位只有4种组合,分别是00,11,01,10
然后 0b11 & hash值= 只有4中结果,分别是0,1,2,3
就找到了桶
set的逻辑
-
计算hash
-
找到桶
-
遍历8个位置,找一个空位置,set进去
-
当前桶如果都满了,尝试去溢出桶找空位置
-
如果都没找到,新建溢出桶
grow的逻辑
1
渐进式扩容。不是一次搞定,而是每次set和delete的时候移动一个桶
2
触发扩容的时机是,当负载因子大于6.5
或者溢出桶太多
-
负载因子等于,k-v对数量 除以 桶数量
-
ps:6.5在源码中是 乘13 除以2 实现的,估计也是为了加速
3
使用hmap的oldbuckets对象来扩容
每次扩容,桶数量乘2
4
每次移动一个桶的逻辑:
把一个旧桶的数据(包括溢出桶)移动到2个新桶上
移动的时候还有规律,一半去新桶数组的上半段,一半去新桶数组的下半段
假设,之前一共4个桶,现在一共8个桶,正在处理第1个桶,那么在扩容后,数据去第1个桶和第5个桶

