

java——HashMap,Hashtable
今天面试的时候突然被问到hashMap的具体实现,一脸懵逼的感觉,平时经常用的也不过是直接new一个hashMap,然后进行put(key,value),get(key)和remove(key)操作,突然问道原理,所以还是需要恶补一下的。
1. 首先说一下一些常用的数据结构
(1) 数组:数组的话一般需要开辟连续的空间,因此占用的内存严重,空间复杂度很大。但是查找的时候比较方便,可以使用二分查找,复杂度大概就是O(l)。当然删除和插入操作就比较复杂了,因为需要元素的移动
(2) 链表:不需要连续的存储空间,可以离散化存储。所以占用内存比较宽松,空间复杂度很小。但是查找的话比较复杂,需要从head开始遍历,判断是否是需要的元素。
(3) 栈:栈的话其实是从Vector扩展来的,而Vector则是implements 了List这个接口,因此其实上栈是基于链表来实现的。不过由于其特殊性,只有push(object)和pop()两个函数,因此操作的时间复杂度也是O(1)。
(4) hashMap:这个就是接下来的重点了。既然数组的查找方便,而链表的存储方便,那有没有一种方式,可以结合两者的优点。hashMap就是这样被实现出来的。
HashMap就是数组和链表的结合,如图所示,是HashMap的示意图。首先有一个数组,之后数组的每一个可以跟着一个链表。
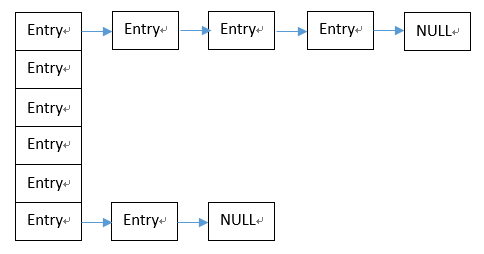
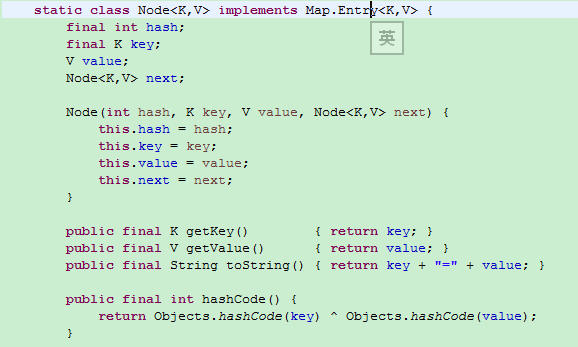
数组的每一个以及链表的每一个都是一个结构体,结构体是如下图的Node,每一个Node包含一个hash值,一个key,一个value以及一个指向下一个结构体的链表。
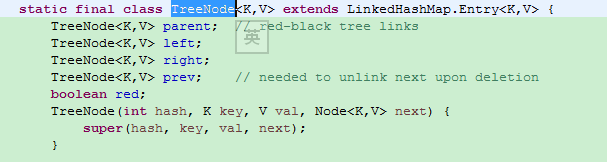
另一个结构体是TreeNode,在java中每一个链表其实用到了树形结构来存储,这样就方便了更快的查找
2. HashMap的put函数
下面所示是HashMap的源码实现,首先对于每一个key,会进行hash(key),然后hash(key)%length来获取应该存入的下标index。如果两个具有相同的hash值,比如entry1以及entry2,index都是1,首先将entry1加入,entry1指向null。然后加入entry2的时候,entry2指向entry1,entry1指向null,就是新加入的永远放在最前面。
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }
3. get函数
首先查找hash(key),找到index,然后查找index对应的treeNode来根据key值查找
public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; } final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) return first; if ((e = first.next) != null) { if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; }
4. remove函数
和get函数差不多,具体注解如下
* @param hash hash for key * @param key the key * @param value the value to match if matchValue, else ignored * @param matchValue if true only remove if value is equal * @param movable if false do not move other nodes while removing * @return the node, or null if none
public V remove(Object key) { Node<K,V> e; return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value; } final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) { Node<K,V>[] tab; Node<K,V> p; int n, index; if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) { Node<K,V> node = null, e; K k; V v; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) node = p; else if ((e = p.next) != null) { if (p instanceof TreeNode) node = ((TreeNode<K,V>)p).getTreeNode(hash, key); else { do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { node = e; break; } p = e; } while ((e = e.next) != null); } } if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) { if (node instanceof TreeNode) ((TreeNode<K,V>)node).removeTreeNode(this, tab, movable); else if (node == p) tab[index] = node.next; else p.next = node.next; ++modCount; --size; afterNodeRemoval(node); return node; } } return null; }
5. Hashtable
提到了HashMap,肯定也是需要了解Hashtable的,Hashtable和HashMap一样,同样是基于Map来实现的,两者的区别主要有以下几点
(1) HashMap允许有null的键和null的值,当然两个都是null也是可以的。而Hashtable不允许有null的键或者值
(2) 线程安全性,HashMap是线程不安全的,因此效率也会高一点。而Hashtable是线程安全的,因此效率上会低一点。当然HashMap也可以变成线程同步的
Map m = Collections.synchronizeMap(hashMap)
(3) Hashtable的多数方法是Synchronize的,这也是为什么他是同步的,而HashMap方法并不是Synchronize的
(4) 两者的实现是有差别的
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable { public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable {
(5) HashMap 不能保证随着时间的推移Map中的元素次序保持不变(散列映射导致的),如果需要保证顺序,可以使用LinkedHashMap
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> {
(6) 迭代器 HashMap的迭代器是fail-fast的,如果在迭代的时候改变结构会抛出ConcurrentModificationException异常。而Hashtable的enumerator迭代器不是fail-fast的。

