kafka消息队列小解
关于kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据,具有类似JMS的特性,但设计与实现完全不同,也并不是JMS规范实现的,显式分布式架构设计,producer、broker(kafka)和consumer都可以有多个
消息的生产及消息传递:Producer,consumer实现Kafka注册的接口,topic消息从producer发送到broker,broker承担一个中间缓存和分发的作用。broker分发注册到系统中的consumer。broker的作用类似于缓存,即活跃的数据和离线处理系统之间的缓存。客户端和服务器端的通信,是基于简单,高性能,且与编程语言无关的TCP协议
概念解析
JMS:即Java消息服务(Java Message Service)应用程序接口,是一个Java平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间,或分布式系统中发送消息,进行异步通信
Topic:特指Kafka处理的消息源(feeds of messages)的不同分类,topic只是存储消息的一个逻辑的概念,他并没有实际的文件存在磁盘上,可以认为是某一类型的消息的集合。所有发送到kafka上的消息都一个类型,这个类型就是他的topic。在物理上来说,不同的topic的消息是分开存储的。同时,一个topic可以有多个producer和多个consumer
partition:Topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)
Message:消息,是通信的基本单位
producers:消息和数据生产者,向Kafka的一个topic发布消息的过程叫做producers
consumers:消息和数据消费者,订阅topics并处理其发布的消息的过程叫做consumers
Broker:缓存代理,Kafa集群中的一台或多台服务器统称为broker
消息队列的两种模式
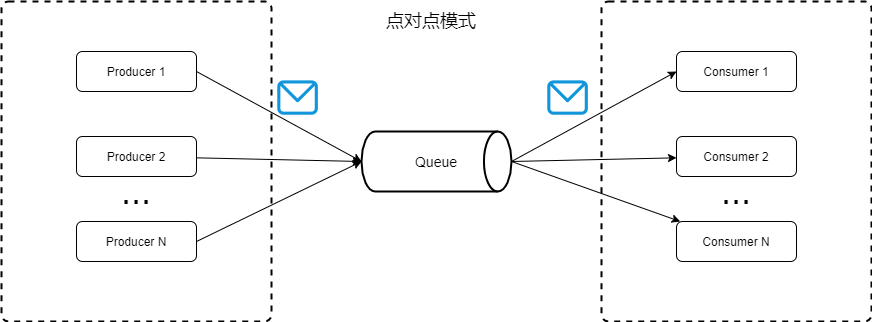
点对点模式:生产者将消息发送消息队列中,消费者获取队列消息消费,queue不再存储被消费的消息,所以消费者不可能消费到已经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只能被一个消费者消费
发布/订阅模式:生产者将消息发布到topic中,同时可以有多个消费者订阅该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费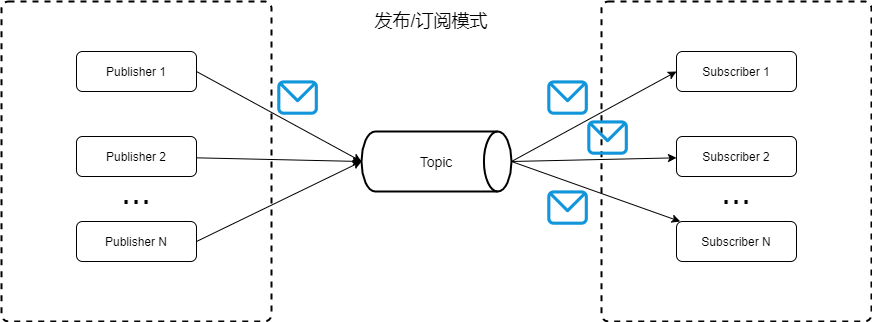
发布与订阅的实现
1、kafka消息生产过程
① 生产者与集群建立连接:通过本地broker集群配置,与集群建立连接,会获取一个集群映射关系,从映射关系中选择一个最终的broker地址建立连接,此刻会获取到集群的所有topic集合,判断当前topic是否在集合中,并从topic所对应的partitio中随机选择一个分区作为leader,建立连接。
② 生产topic消息:topic消息一次可以生产多组,生产者在推送集群前,会进行消息转化,内部会在判断集群中是否存在相应topic,并组装成集群可识别的消息格式
③ 为保证数据不丢失,在生产者端,数据推送分为三种:0-不等集群回复即默认成功,1-leader接收成功并回复,all-主从同步成功后回复
2、集群处理kafka消息
一个独立的kafka服务器被称为broker,而kafka的高可用、容灾性强的特性要求了kafka是一个集群制,也就是有多个broker组成。
集群是由一个基于观察者模式设计的分布式服务管理框架zookeeper管理的,它负责存储和管理大家都关心的数据,topic、consumers、producers、brokers要接受观察者的注册,一旦这些数据的状态发生变化,ZooKeeper就将负责通知已经在。ZooKeeper上注册的那些观察者做出相应的反应,从而实现集群中类似Master/Slave管理模式
broker接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。broker为消费者提供服务,对读取分区的请求作出相应,返回已经提交到磁盘上的消息
Broker处理请求:broker会在它所监听的每个端口上运行一个Acceptor线程,这个线程会创建一个连接并把它交给Processor线程去处理。Processor线程(也叫网络线程)的数量是可配的,Processor线程负责从客户端获取请求信息,把它们放进请求队列,然后从响应队列获取响应信息,并发送给客户端
3、kafka消费
同样的,消费端会与集群建立连接,获取broker的leader分区,拉取消息。真实的应用中一般都回去有多个分区,在有效对broker上面的数据进行分片减少io性能问题的同时提高了消费能力,可以有多个consumer进行数据消费。
在多个consumer和partition消费策略时,会有group分组。组内的所有consumer均可以订阅这个topic下的所有的消息。
consumer与partition:一般partition是consumer的整数倍。消费者数量多于partition的数量的时候,会有消费者消费不到数据的情况。消费者数量少于partition的数量的时候,会有消费者消费多个partition
consumer的rebalance机制
该机制规定了同一个group下的consumer如何达成一致来消费订阅各个分区的消息,具体的策略是范围策略,或者轮询策略
1、触发时机
① 同一个consumer group内新增了消费者
② 消费者离开当前所属的consumer group,比如主动停机或者宕机
③ topic新增或者减少了分区
2、rebalance管理
① 首先我们会确定的一个coordinate角色,当启动第一个consumer的时候我们就会确定为coordinate,之后所有的consumer都会与这个coordinate保持通信。而我们的coordinate就是对consumer group进行管理
② 确定coordinate:消费者向kafka集群中的任意一个broker发送一个GroupCoordinatorRequest请求,服务端会返回一个负载最小的broker节点的id,并将该broker设置为coordinator
③ 进行第一阶段joinGroup(选举leader)的过程:所有的消费者都会向consumer发送joinGroup的请求,当所有的consumer都发送了请求之后,我们的coordinate就会在选举出一个consumer来作为leader,而且会把订阅消息,组成员信息反馈回去
④ 进行第二阶段同步leader的分区分配方案,简单来说就是leader把分区分配方案发送给coordinate,然后,coordinate再把这个分区发送给各个consumer
Leader选举的相关范围
AR:分区中的所有副本统称为AR (Assigned Replicas)
ISR:所有与leader 副本保持一定程度同步的副本(包括leader 副本在内〕组成ISR (On-Sync Replicas),leader会从改组织中选取第一个
OSR:与leader 副本同步滞后过多的副本(不包括leader 副本)组成OSR (Out-of-Sync Replicas)
Mq保证分布式事务消息最终一致性
最终一致性的分布式事务,就是说它保证的是消息最终一致性,而不是像2PC、3PC、TCC那样强一致分布式事务
两点:生产者要保证100%的消息投递,消费者这一端需要保证幂等消费(唯一ID+业务自己实现的幂等)
RocketMQ分布式事务流程:
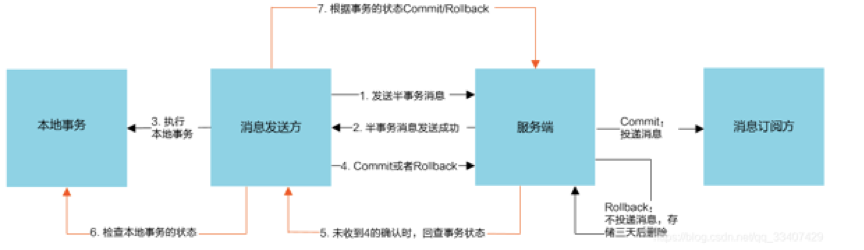
名词解释:
① 半事务消息:
是指暂不能被Consumer消费的消息。Producer 已经把消息成功发送到了 Broker 端,但此消息被标记为暂不能投递状态,处于该种状态下的消息称为半消息。需要 Producer对消息的二次确认后,Consumer才能去消费它。
② 消息回查
由于网络闪段,生产者应用重启等原因。导致 Producer 端一直没有对 Half Message(半消息) 进行 二次确认。这是Brock服务器会定时扫描长期处于半消息的消息,会主动询问 Producer端 该消息的最终状态(Commit或者Rollback),该消息即为 消息回查
① 用户端后台发送一条更新商户B余额的半事务消息至MQ服务端
② MQ服务端收到则会返回Success至用户端
③ 用户端收到Success,则会去执行更新用户端余额的事务
④ 执行结束后会根据本地事务执行结果返回状态Commint或rollback给MQ服务器端(如果MQ端长时间没有接收到用户端事务状态,则会去调用用户端检查服务,判断当前用户端事务是否成功)
⑤ MQ端接受Commit则将该消息修改成可投递状态,商户端会去消费,并且去执行对应的修改余额的事务。如果是RollBack则不投递消息,存储三天后删除
参考最终一致性解决方案:http://www.javashuo.com/article/p-xbgjaohm-y.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号