python re模块
re模块常用方法 :
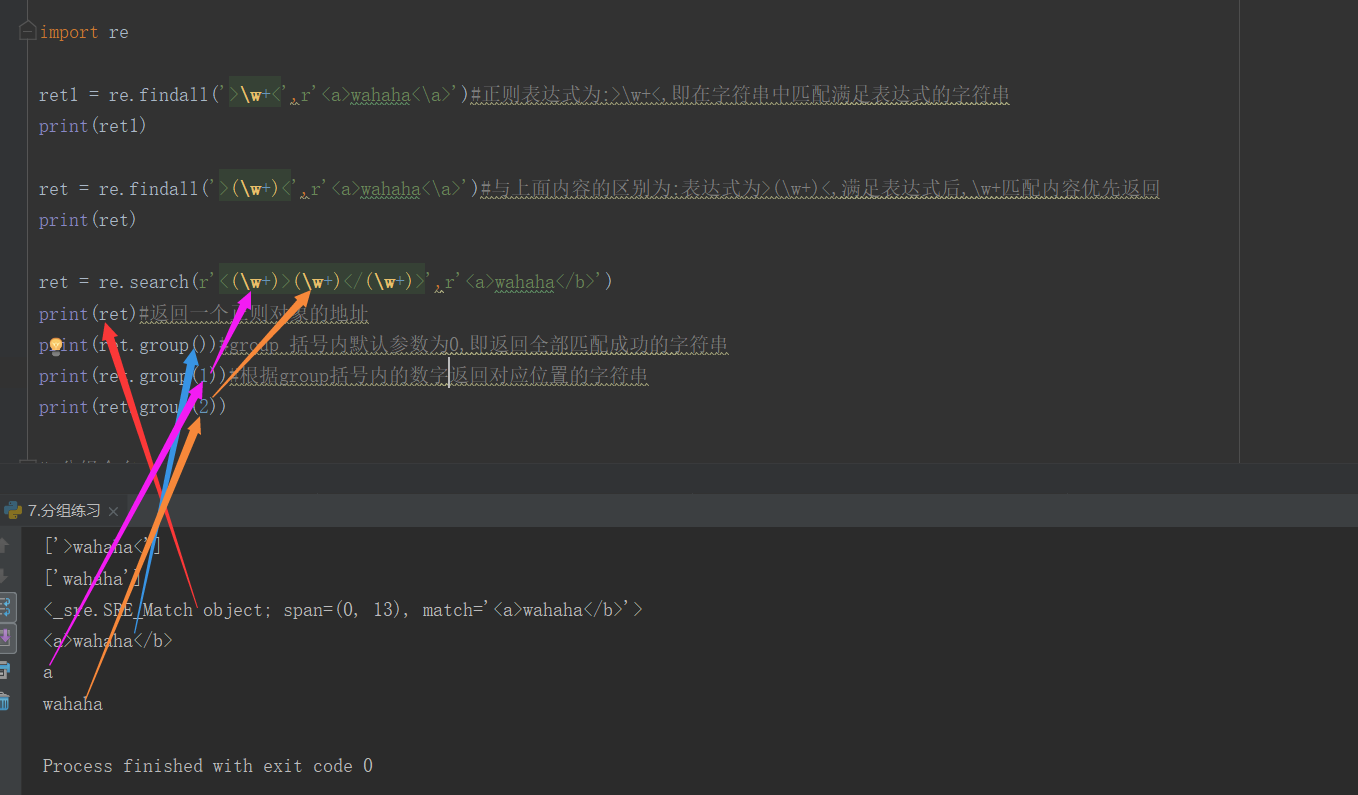
import re ret = re.findall('a', 'eva egon yuan') # 返回所有满足匹配条件的结果,放在列表里, #re.findall( '正则表达式','待匹配字符串') 返回待匹配字符串中满足表达式的字符串 print(ret) #结果 : ['a', 'a'] ret = re.search('a', 'eva egon yuan').group() #search方法在字符串内查找第一个满足表达式的字符串并返回一个正则对象地址 # ,通过group()查看返回的内容,无匹配成功字符串返回None print(ret) #结果 : 'a' # 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以 # 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 ret = re.match('a', 'abc').group() # 同search,不过只在字符串开始处进行匹配,开始出没有符合表达式的字符串,返回None, # 匹配成功的话通过group()查看返回的字符串 print(ret) #结果 : 'a' ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割 print(ret) # ['', '', 'cd'] ret = re.sub('\d', 'H', 'eva3egon4yuan4', 1)#将数字替换成'H',参数1表示只替换1个 print(ret) #evaHegon4yuan4 ret = re.subn('\d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次) print(ret) #结果: ('evaHegonHyuanH',3) obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串 print(ret.group()) #结果 : 123 import re ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器 print(ret) # <callable_iterator object at 0x10195f940> print(next(ret).group()) #查看第一个结果 print(next(ret).group()) #查看第二个结果 # for i in ret: #可以对迭代器进行迭代,查看每一个内容 # print(i.group()) print([i.group() for i in ret]) #查看剩余的左右结果
注意 :
1. findall的优先查询 : ' ?: ' 为取消优先返回匹配
import re ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['www.oldboy.com']
2. split的优先级查询 :
ret=re.split("\d+","eva3egon4yuan") print(ret) #结果 : ['eva', 'egon', 'yuan'] ret=re.split("(\d+)","eva3egon4yuan") print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan'] #在匹配部分加上()之后所切出的结果是不同的, #没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项, #这个在某些需要保留匹配部分的使用过程是非常重要的。
例 :
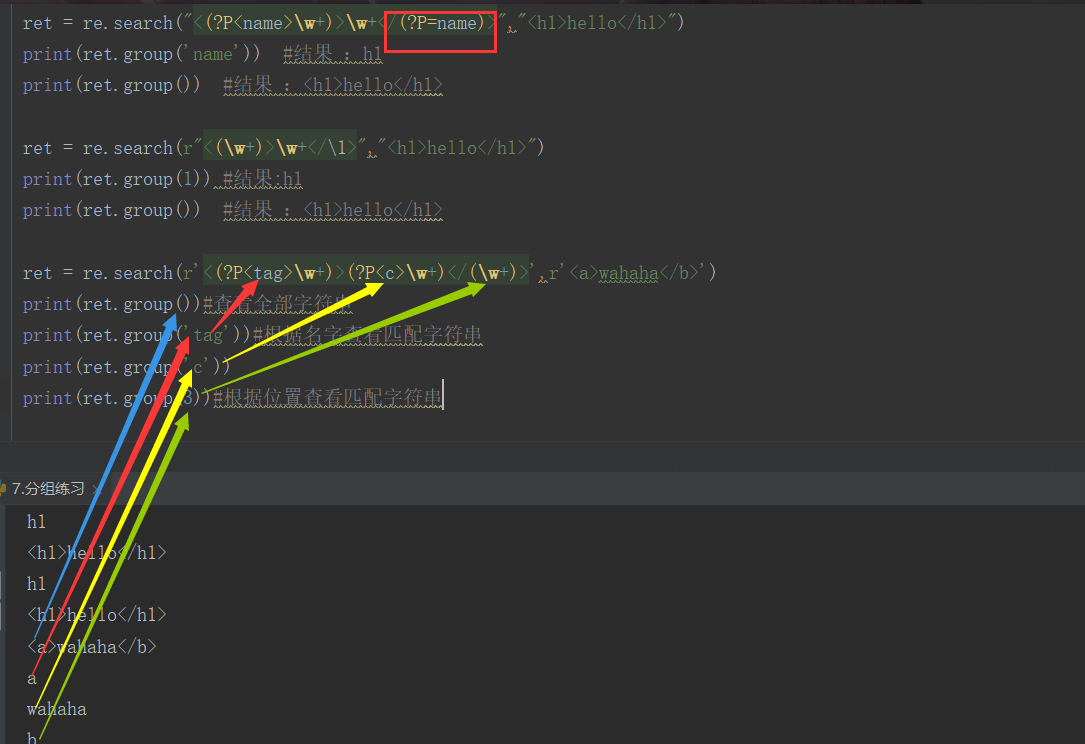
分组命名 :
(?P<name>正则表达式) ,表示给分组起名字
(?P = name) 表示使用这个分组,这里匹配到的内容应该和分组中的内容完全相同

 浙公网安备 33010602011771号
浙公网安备 33010602011771号