
聊一聊深度学习中的调参技巧?
转自这里: http://www.imooc.com/article/305024
作者为 会写代码的好厨师
本期问题
能否聊一聊深度学习中的调参技巧?
我们主要从以下几个方面来讲.
1. 深度学习中有哪些参数需要调? 2. 深度学习在什么时候需要动用调参技巧?又如何调参? 3. 训练网络的一般过程是什么?
1. 深度学习有哪些需要们关注的参数呢?
大家记住一点:需要用到调参技巧的参数都是超参数!!因此,这个问题还可以换成更专业一点:神经网络中有哪些超参数?主要从两个方面来看:
-
和网络设计相关的参数:神经网络的网络层数、不同层的类别和搭建顺序、隐藏层神经元的参数设置、LOSS层的选择、正则化参数
-
和训练过程相关的参数:网络权重初始化方法、学习率使用策略、迭代次数、小批量数据 minibatch的大小、输入数据相关
2. 深度学习在什么时候需要动用调参技巧,以及如何进行调参呢?
通常网络训练的结果一般表现为以下五种情况:过拟合、欠拟合、恰好拟合,趋于收敛但一直在震荡以及完全不收敛。关于过拟合、欠拟合和恰好拟和,在机器学习中的定义描述如下:(不知道的可以移步此博客:https://www.imooc.com/article/44090 )
过拟合、欠拟合、恰好拟合的现象,从图像看就表现成如下:

我们分别来看一下,在这几种种情况下,需要考虑调整哪些参数?
先上图:
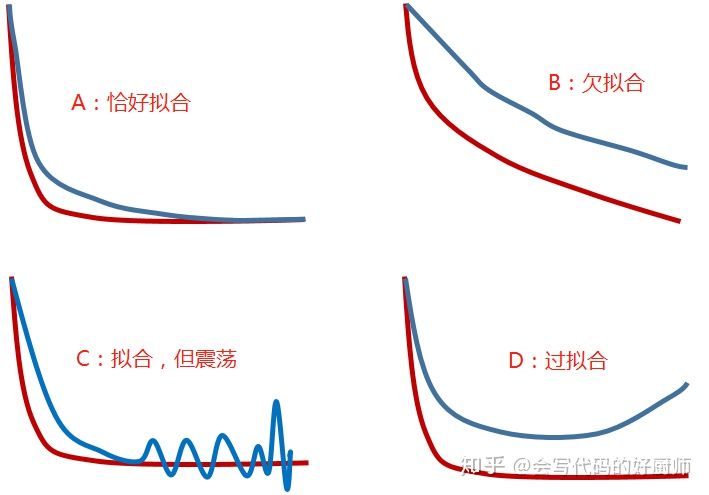
首先来看恰好拟合的情况!
恰好拟合:从LOSS曲线上看,训练集和测试集的LOSS都已经收敛,且很接近!模型能够拟合训练样本和测试样本的分布,且是一致的!这样的优点就是模型的泛化能力强,简单来讲就是在训练集和测试集上效果都很好。通常表现如A图所示。
这个时候还需要调参??效果都这么好。需要调参! 主要集中在网络结构设计方面的参数,在工程项目上,同样的效果。我们需要考虑更小、更轻量型的网络结构,计算量=====功耗,网络大小=======内存!!!一定要学会减少计算量、较小网络大小,当然如果说你的算力随便用,后面的内容可以忽略了。这时候可以考虑:
-
减少网络层数
-
减少不同的层的参数,主要是卷积核的数量
-
考虑深度可分离这样的轻量型卷积结构
还有一种情况,就是虽然训练集和测试集都已经完美收敛,拟合。
但是测试集的LOSS没办法达到训练集的LOSS,这时候也是考验丹师的实力的时候了!
别急,我们在后面聊!
再来看欠拟合的情况!
欠拟合:从LOSS曲线上看,训练集和测试集从趋势上还没有收敛!如图B所示。(不要告诉我不知道什么是收敛,好吧..就是loss曲线变平了,如A所示)
当然,欠拟合也有可能表现在训练集和测试集上效果都一般,在训练集上的精度也不高。
这个时候,怎么办?需要调整哪些参数?通常考虑以下几个方面的参数调整:
-
加大训练迭代次数,有可能是网络还没训练完!!这种低级错误千万不能犯
-
加大迭代次数的同时可以考虑进一步衰减调小学习率
-
添加更多的层,也有可能是网络容量不够!
-
去掉正则化约束的部分,l1\l2正则(正则主要是为了防止过拟合)
-
加入BN层加快收敛速度
-
增加网络的非线性度(ReLu),
-
优化数据集,进行数据清洗,参考博客《炼丹笔记之数据清洗》
再来看过拟合的情况!
过拟合:从样本曲线上看,从看都趋向收敛,但是测试集上的LOSS很高,甚至出现回升的现象。如D图所示。说明模型的泛化能力很差,有可能训练集和测试集数据分布不一致,更加可能的是模型太复杂。
其实,过拟合才是困扰丹师们最大的痛!怎么解决呢?通常有以下策略:
-
增加样本数量,训练样本太少或者说小样本问题,很容易导致过拟合。推荐阅读博主的另一篇文章,关于小样本问题的博客:《炼丹笔记之小样本学习》
-
数据增强,可以参考博主的另一篇博客《炼丹笔记之数据增强》
-
早停法(Early stopping),从LOSS不在下降的地方拿到模型,作为训练好的模型
-
增加网络的稀疏度,
-
降低网络的复杂度(深度)
-
L1 regularization,
-
L2 regulariztion,
-
添加Dropout,
-
适当降低Learning rate,
-
适当减少epoch的次数,
再来看,趋于收敛但是震荡的情况!
在C图中,我们还提到了一种情况,就是网络在训练集上已经趋于收敛,但是在测试集上存在很严重的LOSS震荡的情况,怎么办?这时候,可以从以下几个角度考虑:
-
训练集和测试集分布是否存在较大的差异?
-
是否由于数据增强做的太过分了?
-
学习率是不是还很高?如果是,降低学习率,或者在等等,等到学习率到 10e-6/10e-7这样的大小
-
测试集LOSS的计算是基于单个batch还是整个测试集?(一定要基于整个测试集来看)
-
网络是否存在欠拟合的可能,如果欠拟合参考上面欠拟合的方法
再来看,完全不收敛的情况!
在上面,我们并没有给出完全不收敛的情况曲线图。
那这要怎么判断网络有没有完全没收敛?一个是LOSS一直都很高,自己按照自己定义的LOSS函数估计下,全部为0的时候LOSS是多少,就可以大致估计出LOSS要低于多少网络才能算作是收敛了。
如果网络不收敛怎么办?考虑以下几点:
-
数据错误,先检查数据!输入数据是不是有问题?预处理是不是有问题?数据增强是不是有问题?标签是不是有问题!避免低级错误啊!!
-
网络设计或者参数使用错误,一定要确保网络层的设计和参数设置正确,确保没有问题啊!!
-
考虑LOSS设计是否存在问题,优化函数是否合理?
-
设计的算法本身是够存在问题,是否存在正负样本严重失衡的问题? 推荐阅读博客,《炼丹笔记之样本不平衡问题》
最后,我们再来考虑,在已经收敛的情况下,如何进一步提高模型的精度!
-
优化网络结构,使用更好的backbone
-
使用更好的LOSS函数,比如:回归问题可以考虑smooth-l1等
-
考虑使用难例挖掘的方法
-
有条件的话,加大batchsize
-
考虑预训练模型
-
观察测试样本,查找case,针对Case来,补充样本+数据增强
-
以上方法都试过发现,依然不行,可以重新开始阅读论文了。推荐arxiv、各大顶会系列、trans系列
-
当然,也可能遇到算法极限了,要么自己创新,要么多烧香拜佛等着大牛提出新方法吧。
-
尝试不同的优化函数,交替训练,fine-tuning
-
不同的权重初始化方法
-
尝试不同的学习率初始值和衰减值
-
考虑在梯度上做文章,可以是梯度裁剪、梯度校验、梯度归一化等方法
再来聊一聊,关于自动调参的问题。目前正处于研究阶段,有一些方法,但是不通用。
-
Gird Search. 这个是最常见的。具体说,就是每种参数确定好几个要尝试的值,然后像一个网格一样,把所有参数值的组合遍历一下。优点是实现简单暴力,如果能全部遍历的话,结果比较可靠。缺点是太费时间了,特别像神经网络,一般尝试不了太多的参数组合。
-
Random Search。Bengio在Random Search for Hyper-Parameter Optimization中指出,Random Search比Gird Search更有效。实际操作的时候,一般也是先用Gird Search的方法,得到所有候选参数,然后每次从中随机选择进行训练。
-
Bayesian Optimization. 贝叶斯优化,考虑到了不同参数对应的实验结果值,因此更节省时间。和网络搜索相比简直就是老牛和跑车的区别。具体原理可以参考这个论文:Practical Bayesian Optimization of Machine Learning Algorithms,这里同时推荐两个实现了贝叶斯调参的Python库,可以上手即用:1)jaberg/hyperopt, 比较简单。2)fmfn/BayesianOptimization, 比较复杂,支持并行调参。
如果有时间,推荐一些其他的博客:见参考文献
3. 调参的一般过程是什么?
基本上遵循从粗到细,先易后难的顺序,具体给出炼丹流程如下:
1. 首先是搭建模型:
-
如果有源码,先直接把源码跑通,没有源码考虑自己的搭建模型;
-
主干网络可以直接考虑:resnet(后续网络优化部分在考虑裁剪或者其他网络结构)
-
loss根据相应的任务来进行选择,可能是交叉熵损失(分类任务)、smooth-l1(回归任务)等
-
优化函数,采用Adam或者SGD都可以。先随便选一个常用的优化方法就可以
-
学习率可以从0.1或者0.01开始
-
batchsize:32或者64
2. 准备小规模样本,比如存在100w数据,可以先打包1w数据或者几千样本,可以暂时先不考虑数据增强,正常打包后直接训练网络,用小批量样本来测试网络搭建中可能存在的bug,直到网络可以收敛,确保网络搭建的准确性,方便后续出现问题时,问题的定位。
3. 小规模样本训练收敛之后,则可以确定模型框架没有问题。开始加大样本规模到100W,使用大规模样本训练;
4. 训练后,分析训练集和测试集LOSS的变化情况,考虑上述过拟合、欠拟合、收敛不稳定等不同情况,优化相应的参数;
5. 在LOSS出现较为理想的结果之后,基本上网络训练也趋于稳定。接下来则是重点排查难点问题,尝试创新性的调整网络架构,尝试新的loss,调整数据增强策略,不同优化函数,不同学习率,不同batchsize等等,通过各种手段,来提高准确度。其中,最关键的一定是“数据清洗”。推荐阅读博客《炼丹笔记之数据清洗》
6. 另外,丹师应该对业界内的baseline方法有一个大概的了解,方法能够调到什么程度,也要做到心里有数。这样,才能在上面的这些操作,都完成的差不多了,算法没办法调优的时候,有一个借口,告诉自己:业界也就这个水平了~~~哈哈。
作者:会写代码的好厨师
链接:http://www.imooc.com/article/305024
来源:慕课网
本文原创发布于慕课网 ,转载请注明出处,谢谢合作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号