机器学习流行算法一览
http://www.jdon.com/bigdata/a-tour-of-machine-learning-algorithms.html
这篇文章介绍几个最流行的机器学习算法。现在有很多机器学习算法,困难的是进行方法归类,这里我们介绍两种方法进行思考和分类这些算法。第一组算法是学习风格,第二组是在形式和功能上类似。
学习风格
一个算法基于问题建模有不同的方法,无论这个问题是基于经验或环境的交互,或者是基于我们需要输入的数据,学习风格是机器学习首先必须考虑的问题。
下面我们看看一些算法的主要学习风格或者称为学习模型。
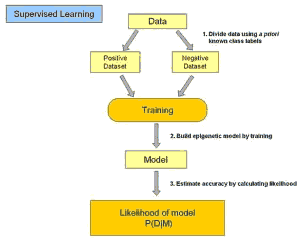
- Supervised Learning有监督式学习: 输入的数据被称为训练数据,一个模型需要通过一个训练过程,在这个过程中进行预期判断,如果错误了再进行修正,训练过程一直持续到基于训练数据达到预期的精确性。其关键方法是分类和回归,算法是逻辑回归(Logistic Regression)和BP神经网络(Back Propagation Neural Network)
![]()
- Unsupervised Learning无监督学习: 没有任何训练数据,基于没有标记的输入数据采取推导结构的模型,其关键方式是关联规则学习和聚合,算法有Apriori 算法和k-means.
![]()
- Semi-Supervised Learning半监督式学习: 输入数据是标记和非标记的混合案例,模型必须学习其中结构然后按照预期组织数据,其关键方法是分类和回归。
![]()
- 强化学习:模型必须能从一个环境刺激中进行应对和反应。反馈不会作为一个教学过程的形式,但是可以环境的奖惩。其关键方法是系统和机器人控制。算法有Q-learning和Temporal difference learning。

当为了商业决策建模而处理数据时,你通常使用监督和无监督学习方法。目前的一个热点话题是图像分类等领域的半监督学习,很少有标记的例子大型数据集的方法。强化学习是更容易在机器人控制与其他控制系统等领域有应用。
分类算法
分类是找出数据库中的一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据库中的数据项映射到摸个给定的类别中。可以应用到涉及到应用分类、趋势预测中,如淘宝商铺将用户在一段时间内的购买情况划分成不同的类,根据情况向用户推荐关联类的商品,从而增加商铺的销售量。
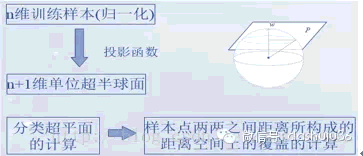
空间覆盖算法-基于球邻域的空间划分
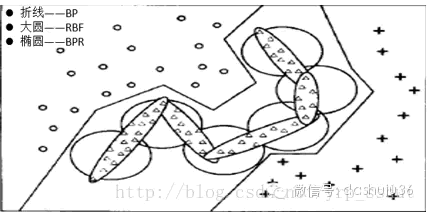
空间覆盖算法-仿生模式识别
空间覆盖算法-视觉分类方法
VCA把数据看作一幅图像,核心是基于尺度空间理论,选择合适的尺度使得同类样本区域融合在一起。
分类超曲面算法HSC
设训练样本所在空间为一封闭维方体区域,将此区域按照一定细分规则划分成若干小区域,使每个小区域只包含同一类样本点,并用样本点的类别标定该区域,合并相邻同类区域边界,获得若干超平面片封闭组成的分类超曲面。输入新样本点,根据分类判别定理判断样本点所在的类别。
特点:
- 通过特征区域细化直接解决非线性分类问题,不需要考虑使用何种函数,不需要升维变换。
- 通用可操作的分类超曲面构造法,基于分类超曲面的方法通过区域合并计算获得分类超曲面对空间进行划分
- 独特、简便、易行的分类判别方法,基于分类超曲面的方法是基于Jordan定理的分类判断算法,使得基于非凸的超曲面的分类判别变得简便、易行。
极小覆盖子集
覆盖型分类算法的极小覆盖子集——对特定的训练样本集,若其子样本集训练后得到的分类模型与与原样本集训练后得到的分类模型相同,则称子样本集是原样本集的一个覆盖。在一个样本集的所有覆盖中,包含样本个数最少的覆盖称为样本集的极小覆盖子集。
(1)计算极小覆盖子集的基本步骤:
用一个方形区域覆盖所有样本点;将该区域划分成一系列小区域 (单元格),直到每个小区域内包含的样本点都属于同一类别;将落在同一小区域内的样本点中选择且仅选择一个样本构成极小覆盖子集。
(2)采样受限于极小覆盖子集
全样本空间必然包含极小覆盖子集,任意一个数据集未必包含完整的极小覆盖子集。大数据环境下,极小覆盖子集中的样本更多地包含在大数据中,较多的数据可以战胜较好的算法、再多的数据亦不会超过极小覆盖子集的代表性、再好的提升手段亦不会超过极小覆盖子集确定的精度。
相似度算法
算法通常在功能或形式上呈现一定相似度。例如,基于树的方法和神经网络方法的启发。这是一个有用的分组方法,但它是不完美的。仍然有一些算法容易地融入多个类别,如学习矢量量化Learning Vector Quantization,它既是一个神经网络的启发方法又是一个基于实例的方法的算法。
也有一些描述问题域和算法类别上有相同名称的算法,如回归分析和聚合。因此,像机器学习算法本身一样,没有完美的模型,只有适合的模型。
下面我们陈列出一些流行的机器学习算法。
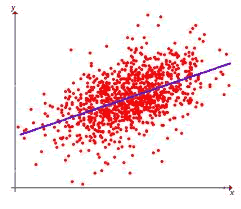
Regression回归
回归是关注变量之间关系的建模,利用模型预测误差测量进行反复提炼。回归方法是统计工作,已纳入统计机器学习。这可能是令人困惑,因为我们可以用回归来引用各类的问题及各类算法。回归其实是一个过程。
在市场营销中,回归分析可以被应用到各个方面。如通过对本季度销售的回归分析,对下一季度的销售趋势作出预测并做出针对性的营销改变。
一些示例算法是:
- Ordinary Least Squares普通最小二乘法
- Logistic Regression逻辑回归
- Stepwise Regression逐步回归
- Multivariate Adaptive Regression Splines (MARS)多元自适应回归
- Locally Estimated Scatterplot Smoothing (LOESS)本地散点平滑估计
基于实例的方法
基于实例的学习模型是使用那些对于模型很重要训练数据,这类方法通常使用基于示例数据的数据库,用新数据和数据库数据以一种相似度方式从中找到最佳匹配,从而作出预测。出于这个原因,基于实例的方法也被称为赢家通吃所有的方法和基于记忆的学习。重点放在存储实例之间的相似性度量表现上。
- k-Nearest Neighbour (kNN)
- Learning Vector Quantization (LVQ)学习矢量量化
- Self-Organizing Map (SOM)自组织映射算法
Regularization正则化方法
正则化方法是其他算法(回归算法)的延伸,根据算法的复杂度对算法进行调整。正则化方法通常对简单模型予以奖励而对复杂算法予以惩罚。基于正则化方法的扩展 (典型是基于regression回归方法) 可能比较复杂,越简单可能会利于推广,下面列出的正则化方法是因为它们比较流行 强大简单。
- Ridge Regression岭回归数值计算方法
- Least Absolute Shrinkage and Selection Operator (LASSO)至少绝对的收缩和选择算子
- Elastic Net弹性网络
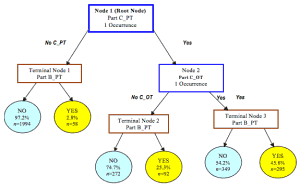
决策(Decision)树学习
决策树方法是建立一种基于数据的实际属性值的决策模型。决策使用树型结构直至基于一个给定记录的预测决策得到。决策树的训练是在分类和回归两方面的数据上进行的。
- Classification and Regression Tree (CART)分类回归树
- Iterative Dichotomiser 3 (ID3)迭代二叉树3代
- C4.5
- Chi-squared Automatic Interaction Detection (CHAID)卡方自动交互检测
- Decision Stump单层决策树
- Random Forest随机森林
- Multivariate Adaptive Regression Splines (MARS)多元自适应回归样条
- Gradient Boosting Machines (GBM)梯度推进机
Bayesian贝叶斯
贝叶斯方法是明确使用贝叶斯定理进行分类和回归:
- Naive Bayes朴素贝叶斯
- Averaged One-Dependence Estimators (AODE)平均单依赖估计
- Bayesian Belief Network (BBN)贝叶斯信念网络
Kernel Methods内核方法
Kernel Methods最有名的流行的支持向量机的方法, Kernel Methods更关注将数据映射到高维空间向量,在那里可以进行一些分类或回归问题的建模。
- Support Vector Machines (SVM)支持向量机
- Radial Basis Function (RBF)径向基函数
- Linear Discriminate Analysis (LDA)线性鉴别分析
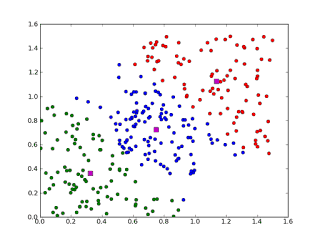
聚类Clustering方法
Clustering聚类方法, 类似回归,是属于描述问题和方法的类别,聚集方法通常被建模于基于几何中心centroid-based和层次组织等系统。所有的方法都是有关使用数据中固有的结构,这样以便更好将数据组织为存在最大共性的分组。
聚类类似于分类,但与分类的目的不同,是针对数据的相似性和差异性将一组数据分为几个类别。属于同一类别的数据间的相似性很大,但不同类别之间数据的相似性很小,跨类的数据关联性很低。
- k-Means
- Expectation Maximisation (EM)期望最大化算法
关联规则学习
关联规则的学习方法是提取那些能解释观察到的变量之间的数据关系的规则。这些规则可以用于在大型多维数据集里,以便能发现重要的和商业上对某个组织或公司有用的的关联。
关联规则的挖掘过程主要包括两个阶段:第一阶段为从海量原始数据中找出所有的高频项目组;第二极端为从这些高频项目组产生关联规则。关联规则挖掘技术已经被广泛应用于金融行业企业中用以预测客户的需求,各银行在自己的ATM 机上通过捆绑客户可能感兴趣的信息供用户了解并获取相应信息来改善自身的营销。
- Apriori 算法
- Eclat 算法
人工神经网络
人工神经网络模型的灵感来自于生物神经网络的结构和功能。他们是一类的模式匹配,常用于回归和分类问题。
神经网络作为一种先进的人工智能技术,因其自身自行处理、分布存储和高度容错等特性非常适合处理非线性的以及那些以模糊、不完整、不严密的知识或数据为特征的处理问题,它的这一特点十分适合解决数据挖掘的问题。典型的神经网络模型主要分为三大类:第一类是以用于分类预测和模式识别的前馈式神经网络模型,其主要代表为函数型网络、感知机;第二类是用于联想记忆和优化算法的反馈式神经网络模型,以Hopfield 的离散模型和连续模型为代表。第三类是用于聚类的自组织映射方法,以ART 模型为代表。虽然神经网络有多种模型及算法,但在特定领域的数据挖掘中使用何种模型及算法并没有统一的规则,而且人们很难理解网络的学习及决策过程
因为各种各样的问题类型有数百种分支的算法。一些经典的流行的方法:
- Perceptron感知器神经网络
- Back-Propagation反向传递
- Hopfield Network(Hopfield网络)
- Self-Organizing Map (SOM)自组织映射
- Learning Vector Quantization (LVQ)学习矢量量化
深度学习
深度学习方法是一个现代的人工神经网络方法升级版,利用丰富而又廉价的计算,建立更大和更复杂的神经网络,许多方法都是涉及半监督学习(大型数据中包含很少有标记的数据)。
- Restricted Boltzmann Machine (RBM)受限波尔兹曼机
- Deep Belief Networks (DBN)深度信念网络
- Convolutional Network回旋神经网
- Stacked Auto-encoders堆栈式自动编码器
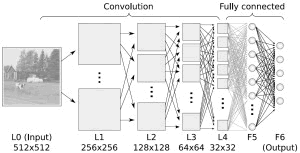
Dimensionality Reduction降维方法
类似群集clustering方法, 降维是寻求和利用数据的内在结构,但在这种情况下,使用无监督的方式只能较少的信息总结或描述数据。以监督方式使用是有用的,能形成可视化的三维数据或简化数据。
- Principal Component Analysis (PCA)主成分分析
- Partial Least Squares Regression (PLS)偏最小二乘回归
- Sammon Mapping
- Multidimensional Scaling (MDS)多维尺度
- Projection Pursuit投影寻踪
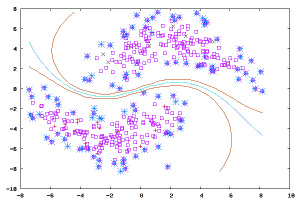
Ensemble集成方法
集成方法是由多个独立训练的弱模型组成,这些模型以某种方式结合进行整体预测。大量的精力需要投入学习什么弱类型以及它们的组合方式。这是一个非常强大的很受欢迎的技术类别:
- Boosting
- Bootstrapped Aggregation (Bagging)自展输入引导式聚合
- AdaBoost
- Stacked Generalization (blending)堆栈泛化
- Gradient Boosting Machines (GBM)梯度Boosting机器
- Random Forest随机森林
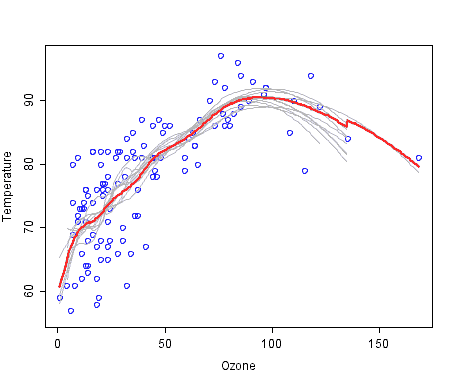
弱者是灰色的,组合预测是红色的。具体显示的是温度/臭氧数据.
Flickr使用Hadoop和Storm扩展计算机视觉处理能力

 浙公网安备 33010602011771号
浙公网安备 33010602011771号