
Redis学习
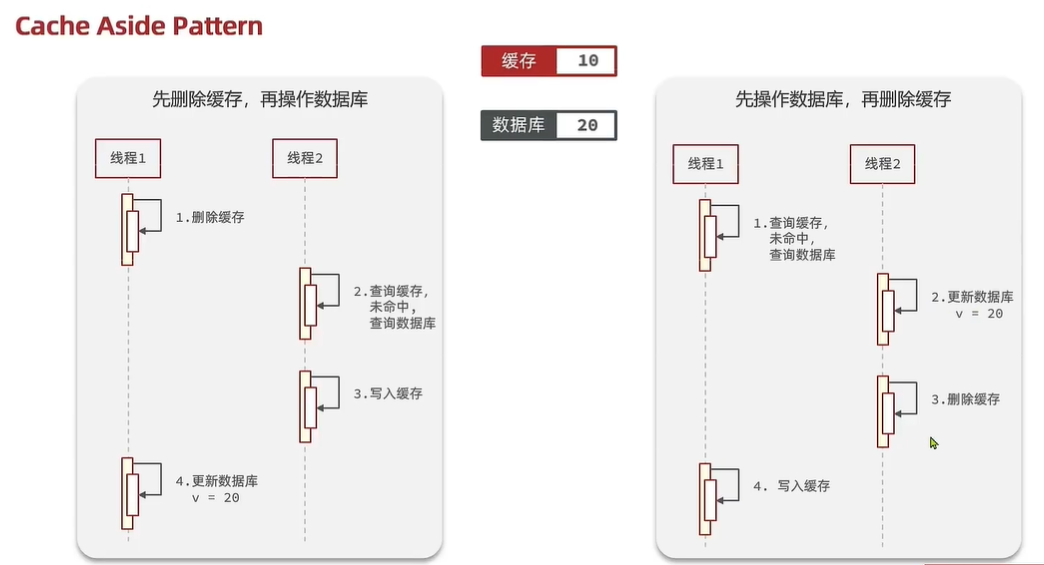
结论:先操作数据库,在操作缓存
1到4的时间很短,概率极低


布隆过滤实际上就是
select电from user
where userid=- 1
在不在集合中,不在就不给

缓存更新策略
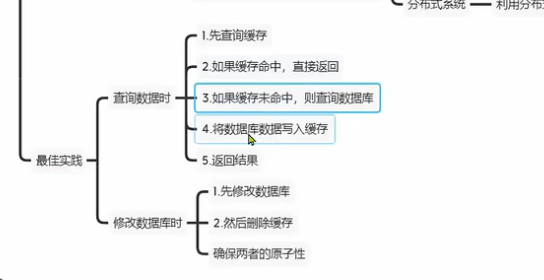
先查询数据库,如果缓存命中,直接返回
缓存穿透实际上就是在缓存(reidis)中找不到,也不再数据库中,恶意的操作,一般选择缓存空对象,设置很短的过期时间
,布隆过滤的话,会误判
缓存雪崩
大量的key同时过期,或者是redis挂了,
针对同时过期,加上随机值
缓存击穿,高并发,需要高频访问的忽然过期了
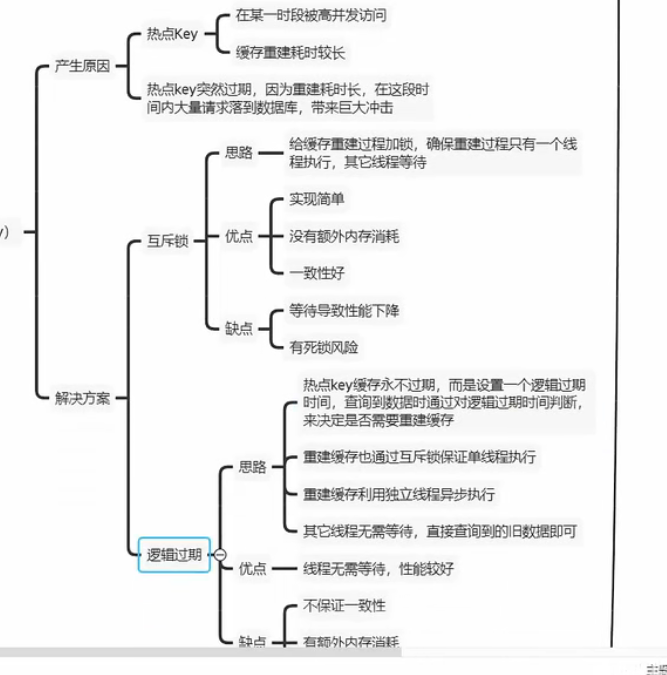
逻辑过期实际上也用上了互斥锁,不同的地方是在于设置独立线程来进行,这样目的是防止死锁和提高效率,但是访问可能是旧数据
秒杀实现
//数据库查询
//查询时间
//在时间内,查看库存
// 不够
//查询订单id ,用户id,代金券id,返回订单id
//将信息放入阻塞队列
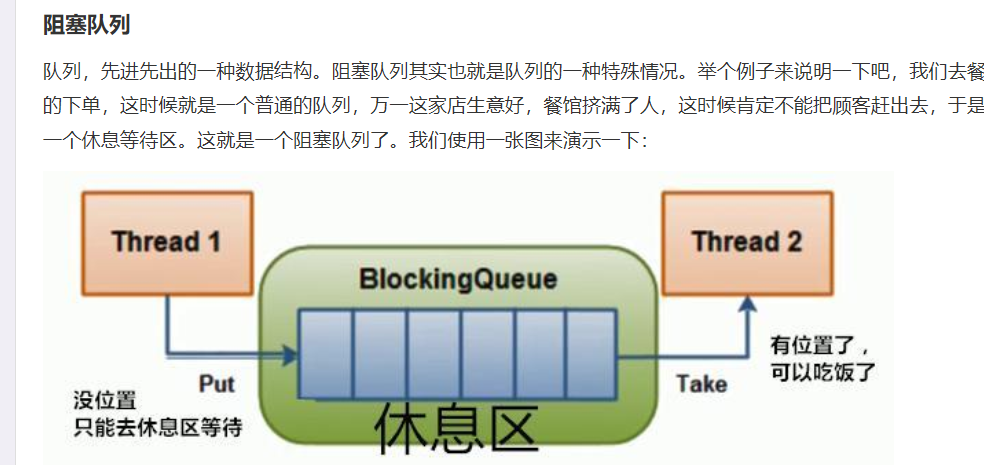
异步秒杀:开启线程任务,不断从阻塞队列中获取信息,实现异步下单功能
-
-
再将下单业务放入阻塞队列,利用独立线程异步下单
-
基于阻塞队列的异步秒杀存在哪些问题?
-
内存限制问题
-
-
为了提高redis的可用性,我们会搭建集群或者主从,现在以主从为例
乐观锁
执乐观锁的时候,去加上一个条件,更新时候,是否同一个,不是就取消更新
超卖的线程安全方案,执行率太低了,1000个人买,存货多,只能有一个人成功
悲观锁,同步锁,串行执行,资源被占用,
加锁,解决一人一单安全问题,
一个项目部署到多个机器上
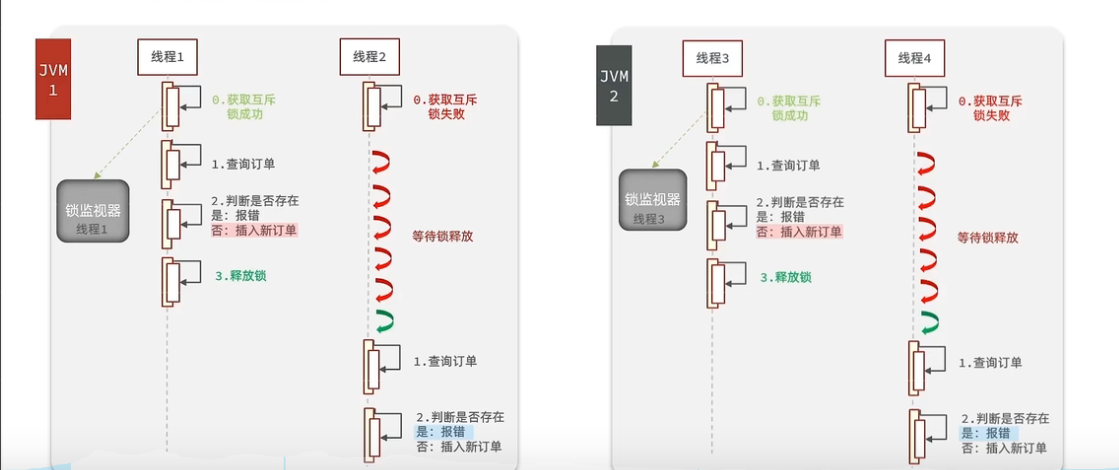
分部式锁,不同端口(机器)
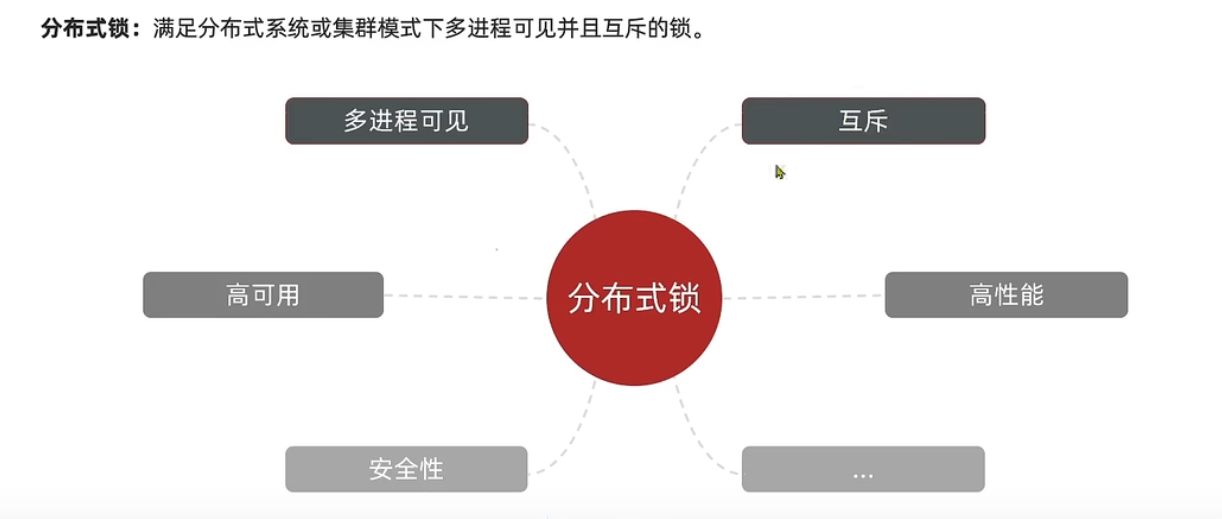
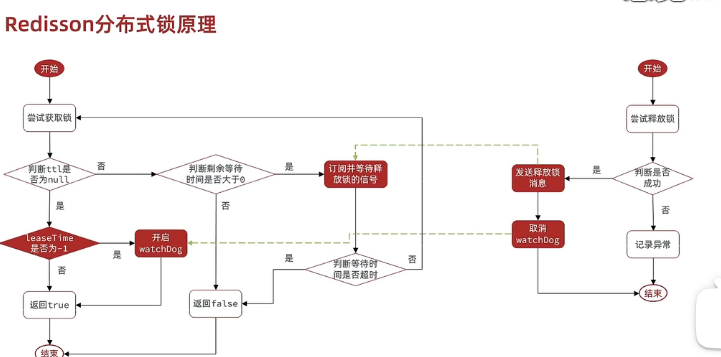
分布式锁
mysql数据库的互斥,redis
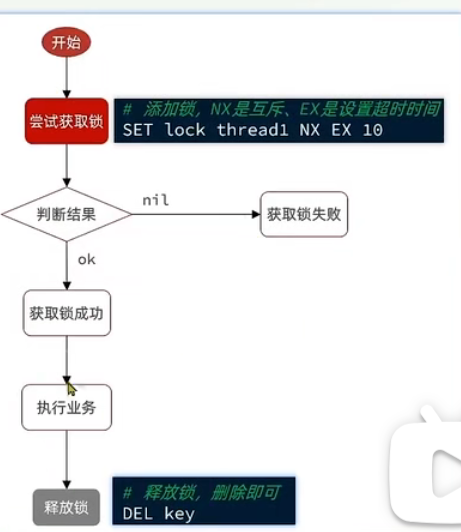
stringRedisTemplate.opsForValue().setIfAbsent,如果有返回true,并设置
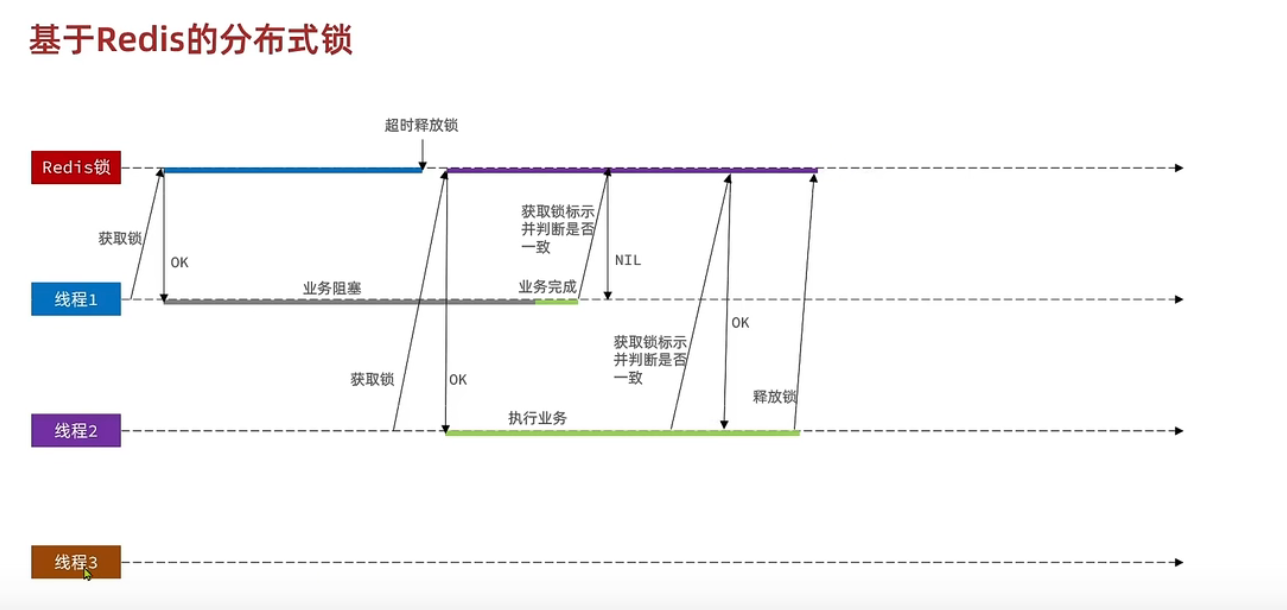
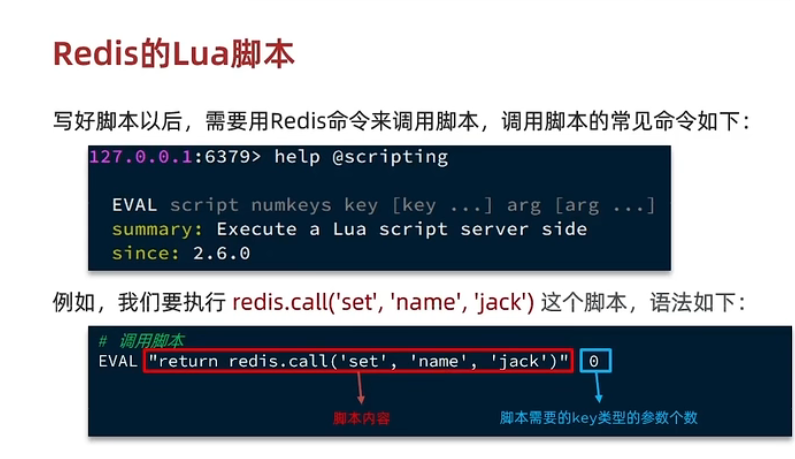

Lua使用
静态代码块,马上执行
private static final DefaultRedisScirpt<Long> unlock_scrip=new DefaultRedisScirpt<>()
unlock_scrip.setLocation(new ClassPathResource("unlock.lua"));
unlock_scrip.setResultType(Long.class);

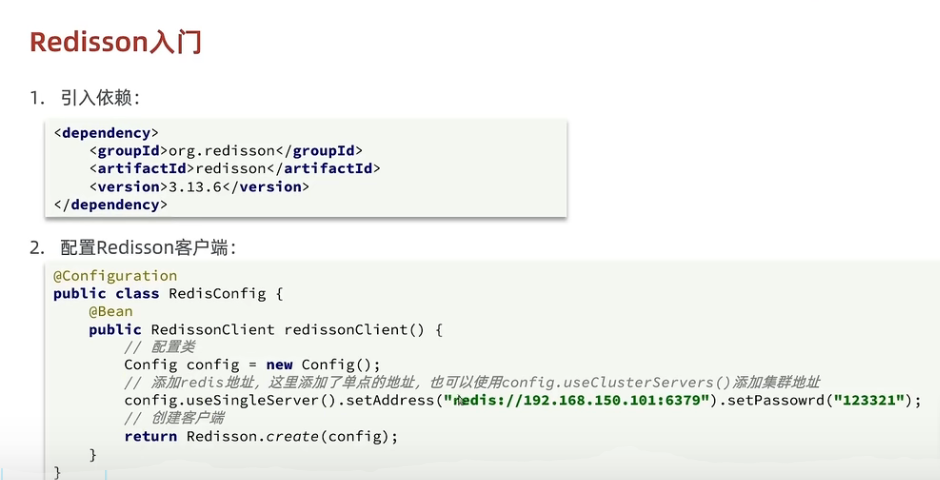
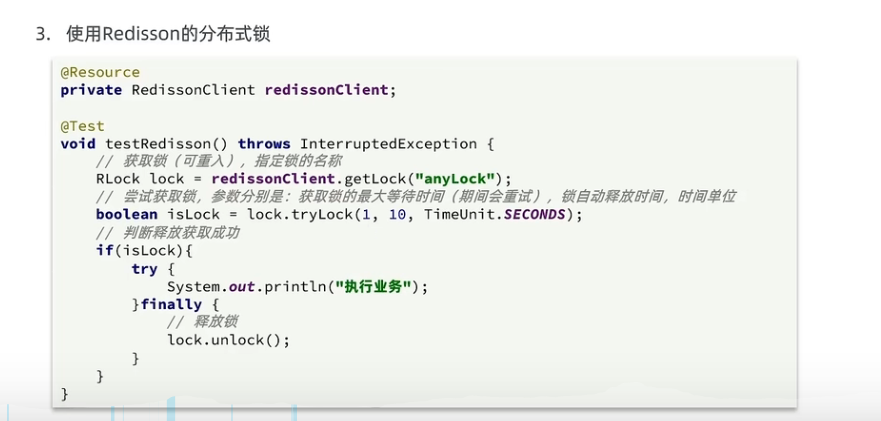
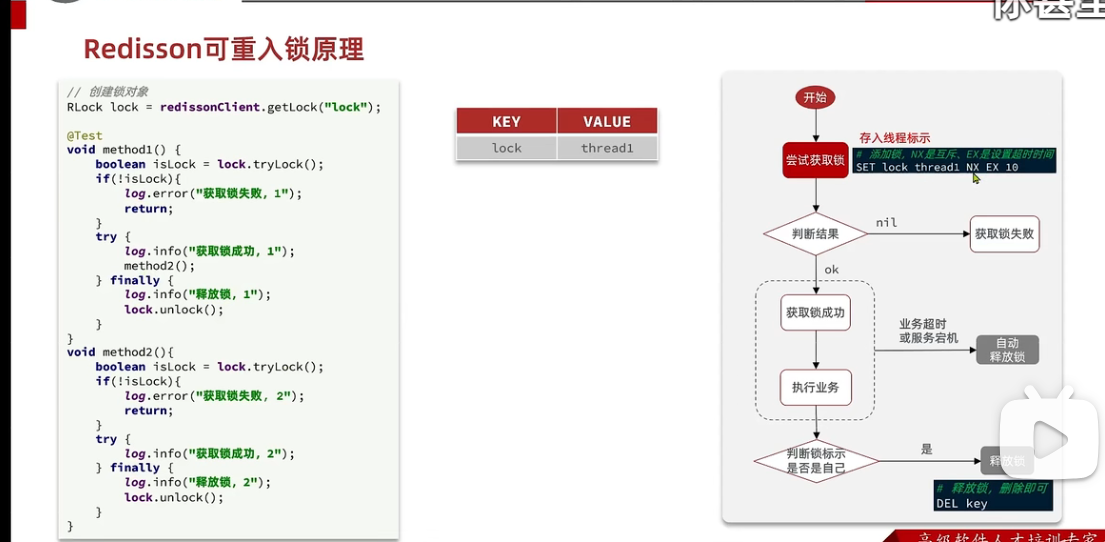
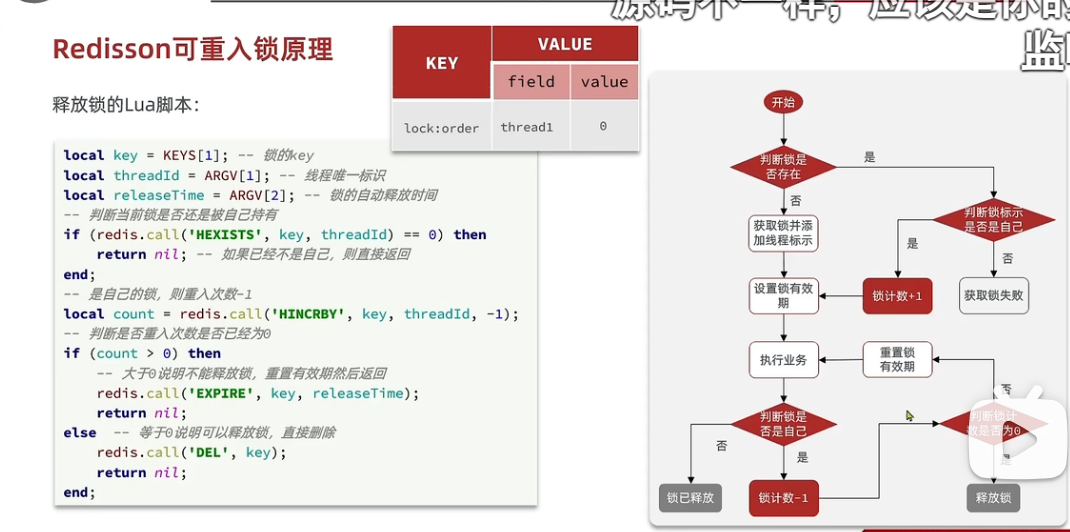
66锁重入,很难懂


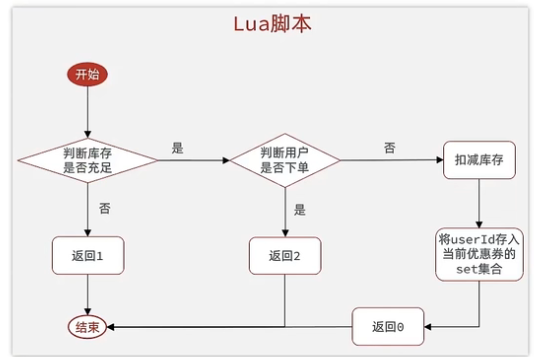
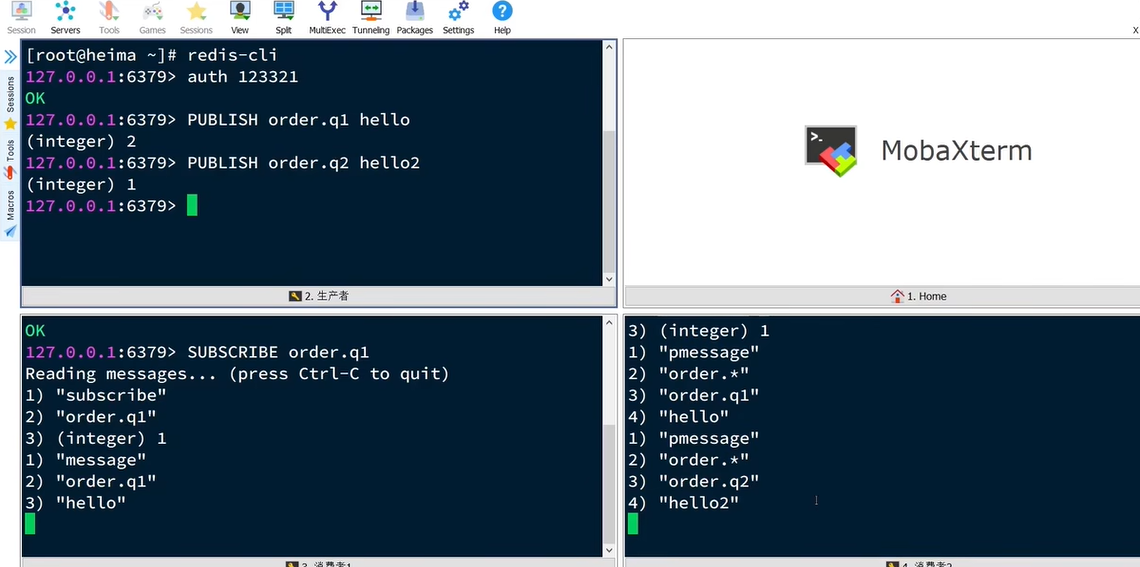
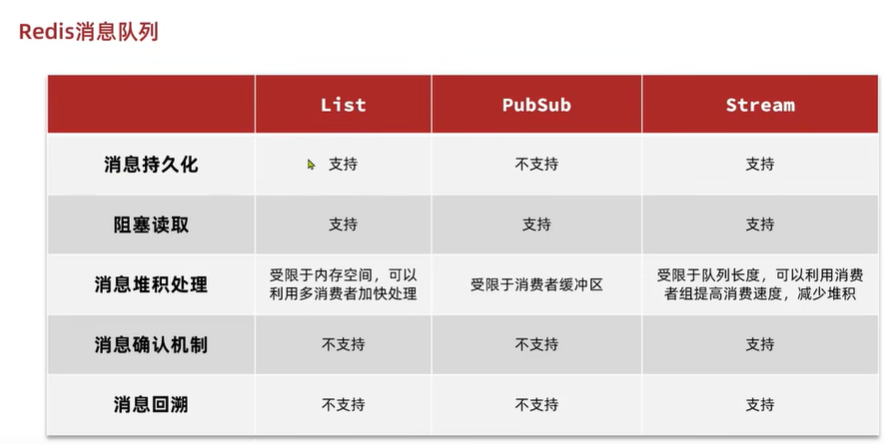
消息队列分为list,pubsu吧,steam

先进先出
如果挂了,就没了
只给一个人
就像广播一样


如果来了多条,只能看到最后一条

配置文件的方式高版本已经替换为了replicaof

在主机B上执行slave of “主机A的ip:端口号”

本质上来说,redis是一个基于内存实现的key,value结构的nosql数据库(非关系数据库
数据类型主要有string,map,set,Zset,List,对应的数据类型可以解决大部分的 业务场景,比如说好友关注列表,很好的提高效率
通过hash槽的方式,实现数据的分片,提升了整体的性能和可扩展性
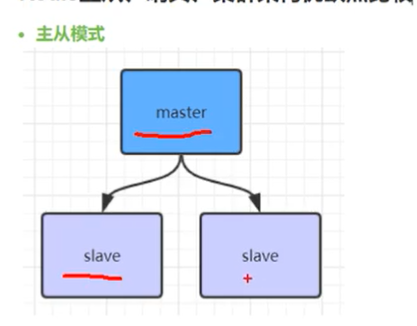
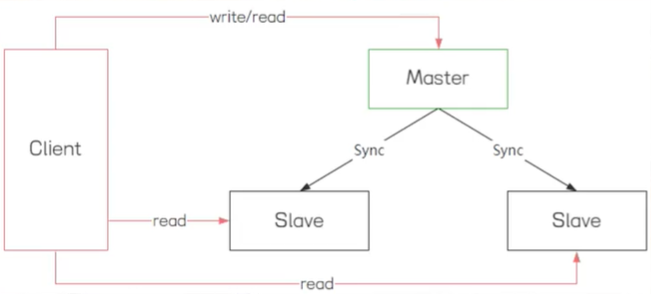
master,和slave实现读写分离,
但是如果master挂了,不会选举出新的master,导致后续的请求失败,这边一般是运维介入,选举master
哨兵实际上就是解决这个问题的
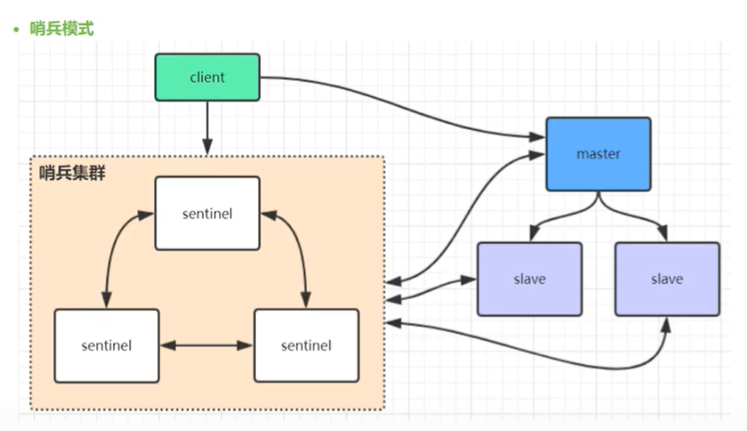
优点:哨兵会主动选举从节点,自动化,
缺点,换master需要时间,
一个master一般10G,方便恢复数据
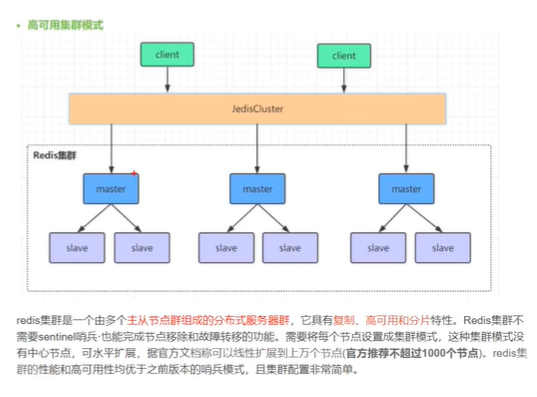
一般扩容到1000个,保持性能
对于master和slave的思考
如果同时大量的过期,master性能会变得很低,如果在slave上的话,会造成死循环,因为slave没有删除能力,只能找其他的key,然而找不到
如果mater和slave的时钟不一样,slave这里过期,master没有过期,当salve成为master的时候,会面对大量的过期,就会发生缓存雪崩
如果master使用supervisor管理,设置为服务挂了,自动重启,会导致数据丢失
master挂了,马上被拉起来,数据都没了,slave为了保持一致,会主动清空数据
redis Rdb持久化
正在写命令的时候,触发了save 60 1000之类的命令,就会发生阻塞
解决方案,采用bgsave,后台就不回阻塞
线上redis持久化策略设置
一般不在master做持久化,但是在salve做持久化,AOF,每秒一次
用GEOHASH来进行地理位置的判断,统计用户量的话就用
