可扩展设计的三个维度
可扩展性是响应式系统设计追求的重要特性之一,那么如何考虑设计系统的可扩展性呢?
《可扩展的艺术》一书提出了一个更加系统的可扩展模型—— AKF可扩展立方 (Scalability Cube)。这个立方体中沿着三个坐标轴设置分别为:X、Y、Z。
X轴扩展 —— 关注水平的数据和服务克隆,也就是前文提到的“加机器解决问题”
Y轴扩展 —— 关注应用中职责的划分,比如数据类型,交易执行类型的划分
Z轴扩展 —— 关注服务和数据的优先级划分,如分地域划分
整个扩展模型,用下图来表示,其中原点代表完全无扩展的状态。

一.X轴扩展
X轴扩展与我们前面朴素理念是一致的,通过绝对平等地复制服务与数据,以解决容量和可用性的问题。我们以生产汽车的工厂来举例:假设一个车间能完整的生产一辆汽车,为了短时间内生产更多的汽车,我们可以建设更多的车间,任何新增车间除了工作的效率可能不同之外,都是一个新的复制品,也能提供与原来车间相同的工作,生产出完整的汽车。给复制品分配工作就是一个X轴扩展的一个完美示例,说明了X轴扩展的思路,即把工作无偏向的分配给复制品,每个复制品在不考虑生产效率的情况下,谁来做这项工作是无偏向的, 各个复制品之间不共享任何内容 。
而在工程技术上来讲,X轴扩展主要有以下两种技术方案:
1.负载均衡
故名思议,负载均衡就是将用户的访问请求通过负载均衡器,均衡分配到由各个“复制品”组成的集群中去。当某个复制品出现故障,也能轻易地将相应“工作”转移给其它的复制品来“代为完成”。这中间涉及到的工程技术点包括了反向代理,DNS轮询,哈希负载均衡算法(一致性哈希),动态节点负载均衡(如按CPU,I/O)等。它的难点在于要求集群中的“复制品”是不共享任何内容,也就是我们常说的 无状态 。
2.数据复制
数据复制是指在数据存储层进行绝对平等地数据迁移,用于解决存储层I/O瓶颈以及可用性上的问题。由于存在多个复制品存储,为了使得每个复制品提供无差异的数据服务,我们需要在复制品之间同步或异步地复制数据。数据复制的方式包括了主从同步(常见的读/写分离),双主同步等。因为数据存储天生就是有状态的,数据复制的难点在于 一致性 的保证上,为了一致性的保证,从而也衍生了很多复杂的技术,比如Paxos选举算法等。
二.Y轴扩展
Y轴扩展表示的是根据数据的类型或者交易执行的类型(或者两者都有)来划分工作职责。一般称为面向服务或面向资源的扩展。我们再以生产汽车的工厂来举例:如亨利.福特所做的一样,将汽车制造的工序按专业性分成不同车间和流水线,不再是一个车间负责完成100%的任务,制造一辆完整的汽车,而是让这每个车间都执行一些子任务,如安装发动机,喷漆,安装玻璃等等。这样的分工,益处是明显的,每个车间负责的 任务更简单 ,从而能更专业更高效的完成生产。
与汽车工厂的分工类似,为了降低系统复杂度,Y轴扩展会将庞大的整体应用拆分为一组服务。每个服务实现一组相关的功能,如订单管理、客户管理等。在工程上常见的方案是 服务化架构(SOA) 。比如对于一个电子商务平台,我们可以拆分成不同的服务,组成下面这样的架构:
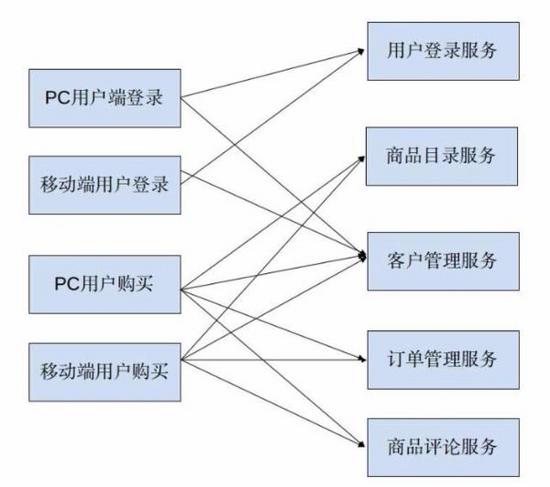
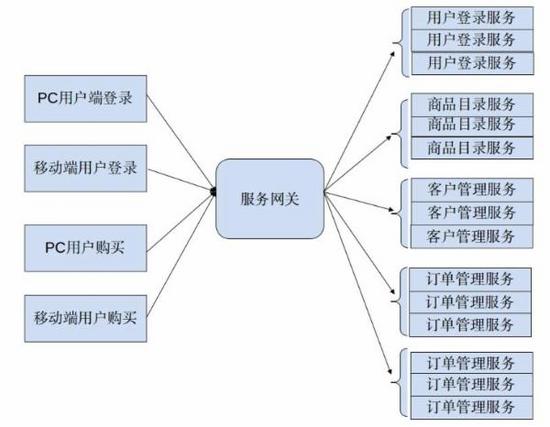
但通过观察上图容易发现,当服务数量增多时,服务调用关系变得复杂。为系统添加一个新功能,要调用的服务数也变得不可控,由此引发了服务管理上的混乱。所以,一般情况下,需要采用服务注册的机制形成服务网关来进行服务治理。系统的架构将变成下图所示:

同时,为了提升单个服务的可用性和容量, 对每一个服务进行X轴扩展划分 。
三.Z轴扩展
Z轴扩展通常是指基于请求者或用户独特的需求,进行系统划分,并使得划分出来的子系统是相互隔离但又是完整的。继续以生产汽车的工厂来举例:福特公司为了发展在中国的业务,或者利用中国的廉价劳动力,在中国建立一个完整的子工厂,与美国工厂一样,负责完整的汽车生产。这就是一种Z轴扩展。
对于系统而言,Z轴扩展一般是为了满足差异性的需求或者是为了安全隔离而采取的扩展措施。比如为了提供VIP用户服务,可以将系统完整地复制一份出来,与普通用户所使用的系统完全隔离开来;再如,针对不同的地域用户,系统自动切换到对应地域的子系统,为用户提供服务,都可以认为是Z轴扩展。同时,在系统的灰度部署上,我们也通常使用Z轴扩展来完成。
工程领域常见的Z轴扩展有以下两种方案:
1.单元化架构
在分布式服务设计领域,一个单元(Cell)就是满足某个分区所有业务操作的自包含闭环。如上面我们说到的Y轴扩展的SOA架构,客户端对服务端节点的选择一般是随机的,但是,如果在此加上Z轴扩展,那服务节点的选择将不再是随机的了,而是每个单元自成一体。如下图:

2.数据分区
为了性能数据安全上的考虑,我们将一个完整的数据集按一定的维度划分出不同的子集。 一个分区(Shard),就是是整体数据集的一个子集。比如用尾号来划分用户,那同样尾号的那部分用户就可以认为是一个分区。数据分区为一般包括以下几种数据划分的方式:
数据类型(如:业务类型)
数据范围(如:时间段,用户ID)
数据热度(如:用户活跃度,商品热度)
按读写分(如:商品描述,商品库存)
当然,数据分区也是有代价的,它将增加数据运维的难度,关联搜索的复杂度增加等。
总结:
一个在可扩展性上设计良好的系统,会充分考虑三个维度上的可扩展性。X轴上扩展处理的是平台或系统执行的交易量或工作量增长,虽然X轴扩展能够很好处理交易量的增长,但当系统复杂度的大幅度增加,或用户数量增加以及差异化服务需求出现,X轴扩展就难以应付了,如是我们可以通过Y轴扩展来处理系统复杂度增长的问题以及Z轴扩展来处理差异性化需求的问题。而当采用的扩展坐标轴不止一条时,那么 X轴扩展总是其它扩展方法的次级划分 。同时,这三个维度扩展性,使得系统性能上改善有了更多的方向,对于系统性能优化,也是至关重要。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号