Spring中资源的加载是定义在ResourceLoader接口中的,它跟前面提到的抽象资源的关系如下:

ResourceLoader的源码
- public interface ResourceLoader {
-
-
- String CLASSPATH_URL_PREFIX = ResourceUtils.CLASSPATH_URL_PREFIX;
-
- Resource getResource(String location);
-
- ClassLoader getClassLoader();
-
- }
- public interface ResourcePatternResolver extends ResourceLoader {
-
-
-
-
-
-
-
-
- String CLASSPATH_ALL_URL_PREFIX = "classpath*:";
-
-
- Resource[] getResources(String locationPattern) throws IOException;
-
- }
ResourcePatternResolver有一个实现类:PathMatchingResourcePatternResolver,那我们直奔主题,查看PathMatchingResourcePatternResolver的getResources()
- public Resource[] getResources(String locationPattern) throws IOException {
- Assert.notNull(locationPattern, "Location pattern must not be null");
-
- if (locationPattern.startsWith(CLASSPATH_ALL_URL_PREFIX)) {
-
- if (getPathMatcher().isPattern(locationPattern.substring(CLASSPATH_ALL_URL_PREFIX.length()))) {
-
- return findPathMatchingResources(locationPattern);
- }
- else {
-
- return findAllClassPathResources(locationPattern.substring(CLASSPATH_ALL_URL_PREFIX.length()));
- }
- }
- else {
-
-
- int prefixEnd = locationPattern.indexOf(":") + 1;
-
- if (getPathMatcher().isPattern(locationPattern.substring(prefixEnd))) {
-
- return findPathMatchingResources(locationPattern);
- }
- else {
-
- return new Resource[] {getResourceLoader().getResource(locationPattern)};
- }
- }
- }
处理的流程图如下:
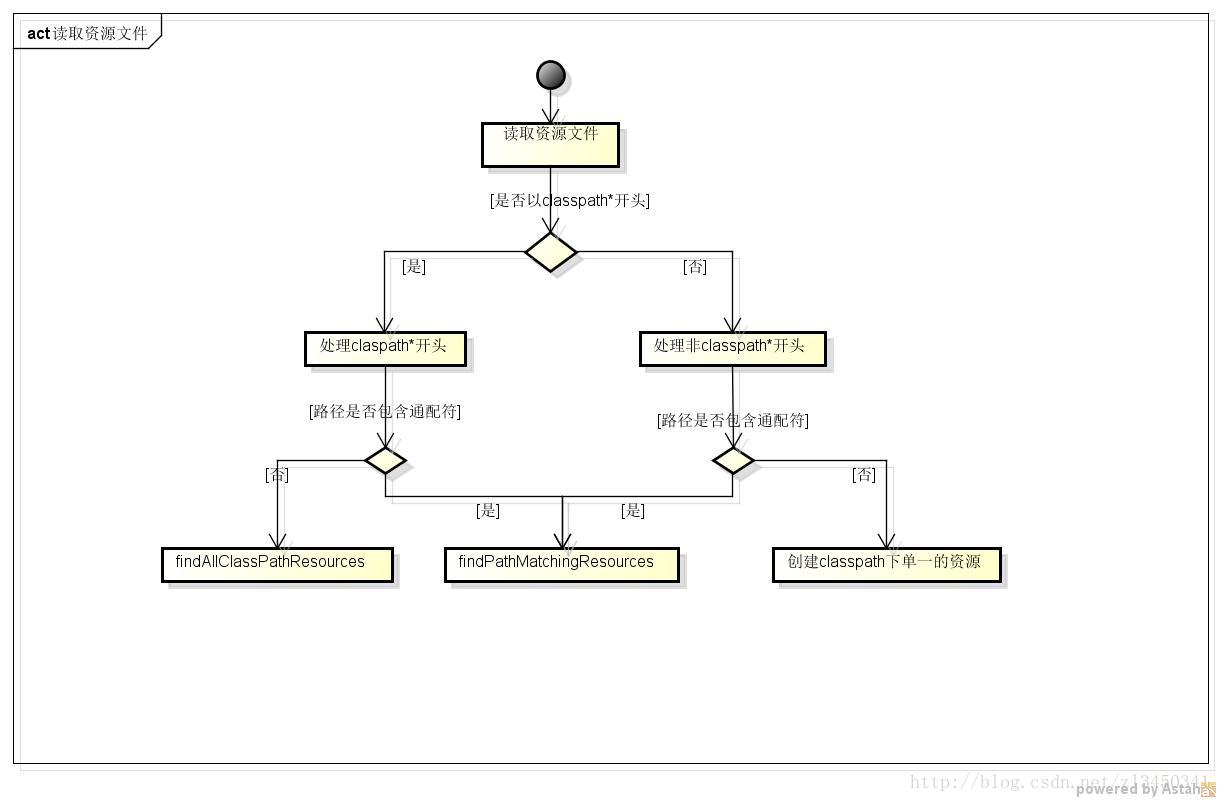
从上图看,整个加载资源的场景有三条处理流程
让我们来看看findAllClassPathResources是怎么处理的
- protected Resource[] findAllClassPathResources(String location) throws IOException {
- String path = location;
- if (path.startsWith("/")) {
- path = path.substring(1);
- }
- Enumeration<URL> resourceUrls = getClassLoader().getResources(path);
- Set<Resource> result = new LinkedHashSet<Resource>(16);
- while (resourceUrls.hasMoreElements()) {
- URL url = resourceUrls.nextElement();
- result.add(convertClassLoaderURL(url));
- }
- return result.toArray(new Resource[result.size()]);
- }
我们可以看到,最关键的一句代码是:Enumeration<URL> resourceUrls = getClassLoader().getResources(path);
- public ClassLoader getClassLoader() {
- return getResourceLoader().getClassLoader();
- }
-
-
- public ResourceLoader getResourceLoader() {
- return this.resourceLoader;
- }
-
-
- public PathMatchingResourcePatternResolver() {
- this.resourceLoader = new DefaultResourceLoader();
- }
其实上面这3个方法不是最关键的,之所以贴出来,是让大家清楚整个调用链,其实这种情况最关键的代码在于ClassLoader的getResources()方法。那么我们同样跟进去,看看源码
- public Enumeration<URL> getResources(String name) throws IOException {
- Enumeration[] tmp = new Enumeration[2];
- if (parent != null) {
- tmp[0] = parent.getResources(name);
- } else {
- tmp[0] = getBootstrapResources(name);
- }
- tmp[1] = findResources(name);
-
- return new CompoundEnumeration(tmp);
- }
是不是一目了然了?当前类加载器,如果存在父加载器,则向上迭代获取资源, 因此能加到jar包里面的资源文件。
- 不以classpath*开头,且路径不包含通配符的
处理逻辑如下
- return new Resource[] {getResourceLoader().getResource(locationPattern)};
上面我们已经贴过getResourceLoader()的逻辑了, 即默认是DefaultResourceLoader(),那我们进去看看getResouce()的实现
- public Resource getResource(String location) {
- Assert.notNull(location, "Location must not be null");
- if (location.startsWith(CLASSPATH_URL_PREFIX)) {
- return new ClassPathResource(location.substring(CLASSPATH_URL_PREFIX.length()), getClassLoader());
- }
- else {
- try {
-
- URL url = new URL(location);
- return new UrlResource(url);
- }
- catch (MalformedURLException ex) {
-
- return getResourceByPath(location);
- }
- }
- }
其实很简单,如果以classpath开头,则创建为一个ClassPathResource,否则则试图以URL的方式加载资源,创建一个UrlResource.
这种情况是最复杂的,涉及到层层递归,那我把加了注释的代码发出来大家看一下,其实主要的思想就是
1.先获取目录,加载目录里面的所有资源
2.在所有资源里面进行查找匹配,找出我们需要的资源
- protected Resource[] findPathMatchingResources(String locationPattern) throws IOException {
-
- String rootDirPath = determineRootDir(locationPattern);
-
- String subPattern = locationPattern.substring(rootDirPath.length());
-
- Resource[] rootDirResources = getResources(rootDirPath);
- Set<Resource> result = new LinkedHashSet<Resource>(16);
-
- for (Resource rootDirResource : rootDirResources) {
- rootDirResource = resolveRootDirResource(rootDirResource);
- if (isJarResource(rootDirResource)) {
- result.addAll(doFindPathMatchingJarResources(rootDirResource, subPattern));
- }
- else if (rootDirResource.getURL().getProtocol().startsWith(ResourceUtils.URL_PROTOCOL_VFS)) {
- result.addAll(VfsResourceMatchingDelegate.findMatchingResources(rootDirResource, subPattern, getPathMatcher()));
- }
- else {
- result.addAll(doFindPathMatchingFileResources(rootDirResource, subPattern));
- }
- }
- if (logger.isDebugEnabled()) {
- logger.debug("Resolved location pattern [" + locationPattern + "] to resources " + result);
- }
- return result.toArray(new Resource[result.size()]);
- }
值得注解一下的是determineRootDir()方法的作用,是确定根目录,这个根目录必须是一个能确定的路径,不会包含通配符。如果classpath*:aa/bb*/spring-*.xml,得到的将是classpath*:aa/ 可以看下他的源码
- protected String determineRootDir(String location) {
- int prefixEnd = location.indexOf(":") + 1;
- int rootDirEnd = location.length();
- while (rootDirEnd > prefixEnd && getPathMatcher().isPattern(location.substring(prefixEnd, rootDirEnd))) {
- rootDirEnd = location.lastIndexOf('/', rootDirEnd - 2) + 1;
- }
- if (rootDirEnd == 0) {
- rootDirEnd = prefixEnd;
- }
- return location.substring(0, rootDirEnd);
- }
分析到这,结合测试我们可以总结一下:
1.无论是classpath还是classpath*都可以加载整个classpath下(包括jar包里面)的资源文件。
2.classpath只会返回第一个匹配的资源,查找路径是优先在项目中存在资源文件,再查找jar包。
3.文件名字包含通配符资源(如果spring-*.xml,spring*.xml), 如果根目录为"", classpath加载不到任何资源, 而classpath*则可以加载到classpath中可以匹配的目录中的资源,但是不能加载到jar包中的资源
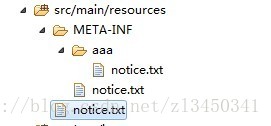
第1,2点比较好表理解,大家可以自行测试,第三点表述有点绕,举个例,现在有资源文件结构如下:
classpath:notice*.txt 加载不到资源
classpath*:notice*.txt 加载到resource根目录下notice.txt
classpath:META-INF/notice*.txt 加载到META-INF下的一个资源(classpath是加载到匹配的第一个资源,就算删除classpath下的notice.txt,他仍然可以 加载jar包中的notice.txt)
classpath:META-*/notice*.txt 加载不到任何资源
classpath*:META-INF/notice*.txt 加载到classpath以及所有jar包中META-INF目录下以notice开头的txt文件
classpath*:META-*/notice*.txt 只能加载到classpath下 META-INF目录的notice.txt


 浙公网安备 33010602011771号
浙公网安备 33010602011771号