
汇编学习
一. 计算机组成简单学习
1. 计算机如何与内存通信
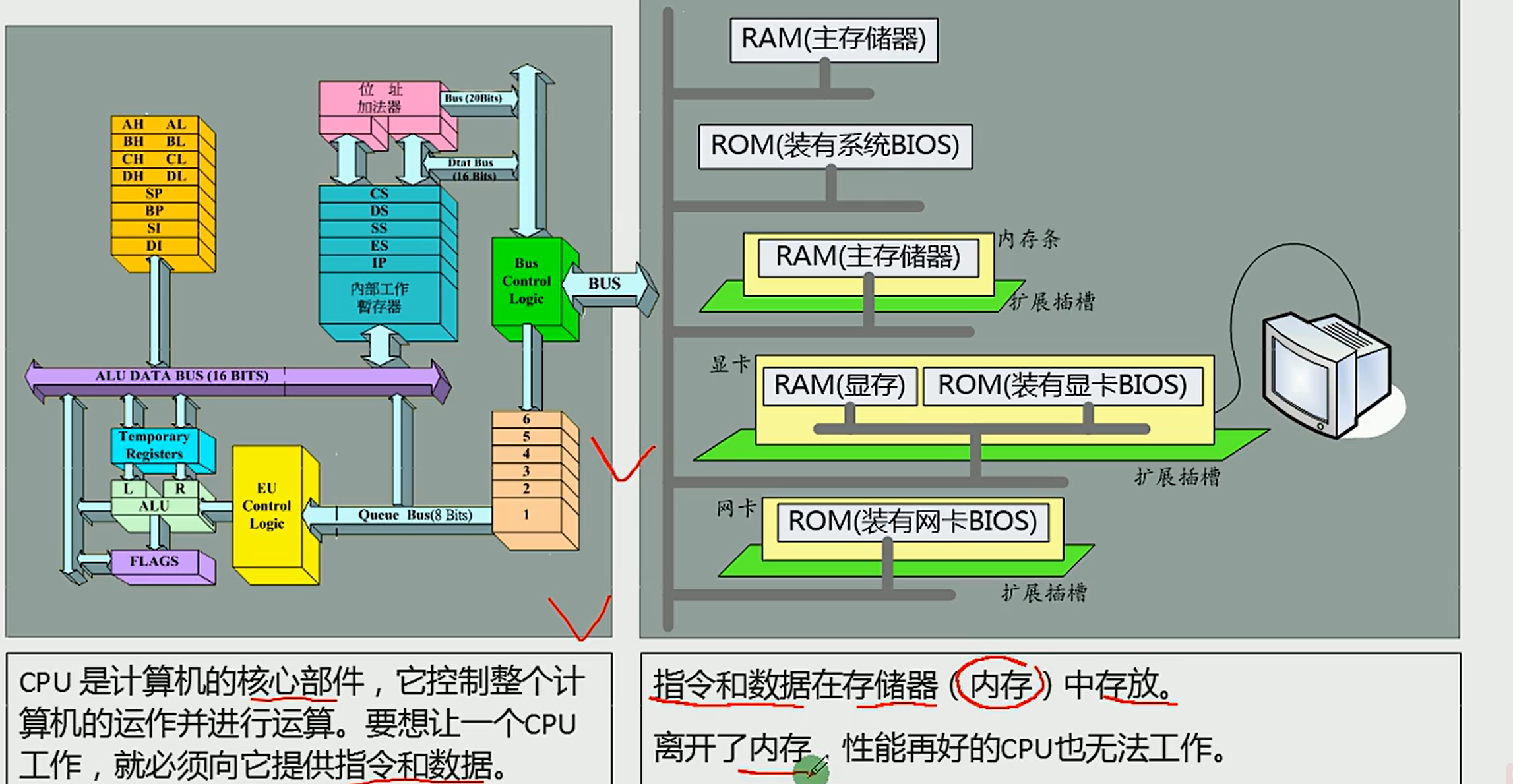
2. 计算机的总线
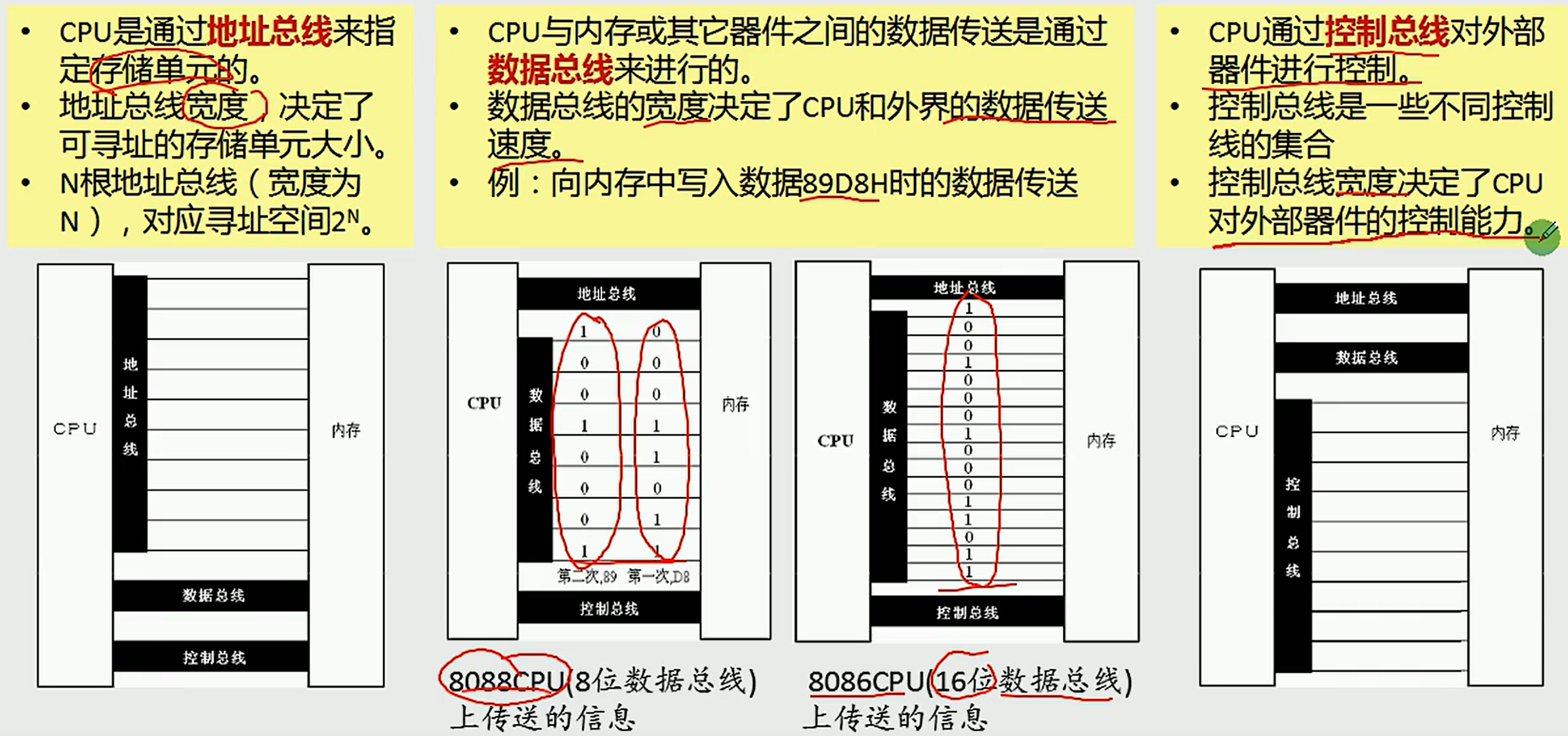
逻辑划分:地址总线 数据总线 控制总线
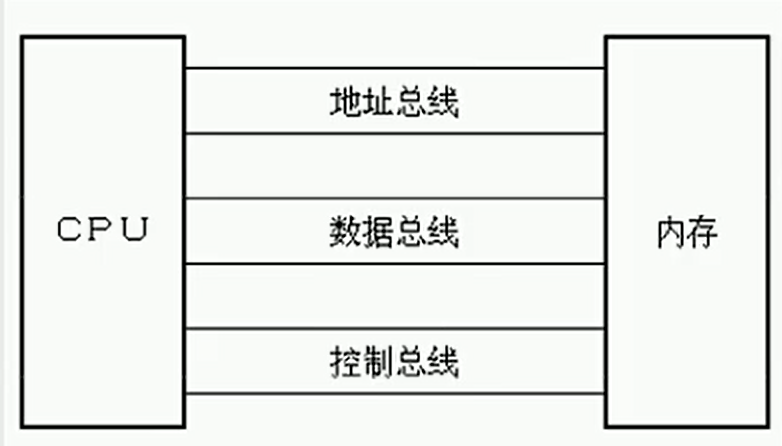
2.1 三类总线各自的功能
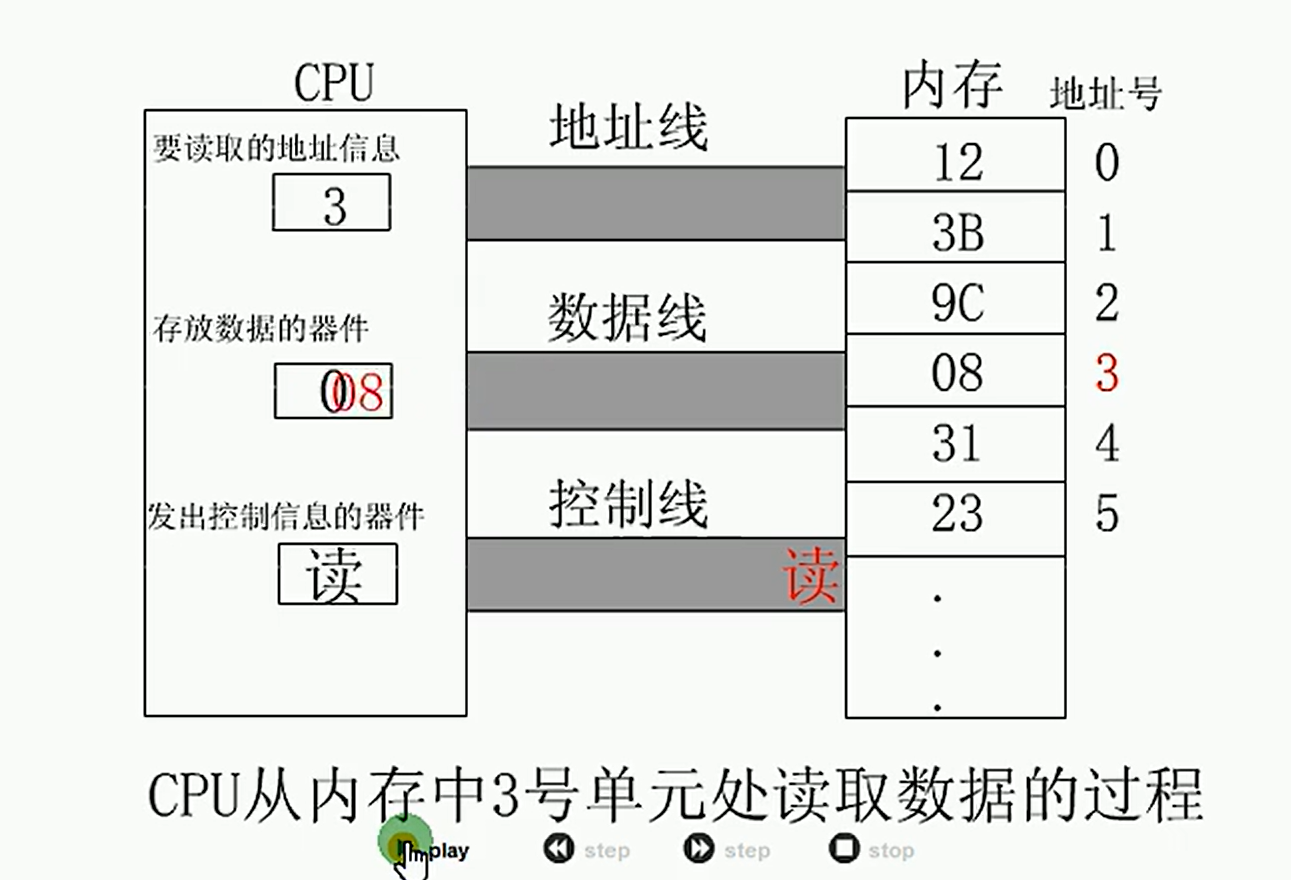
3. CPU有存储器的读写
CPU想读取数据,必须与外部器件进行三类信息的交互
- 存储单元的地址(地址信息)
- 器件的选择,读或者写命令(控制信息)
- 读或写的数据(数据信息)
过程图:
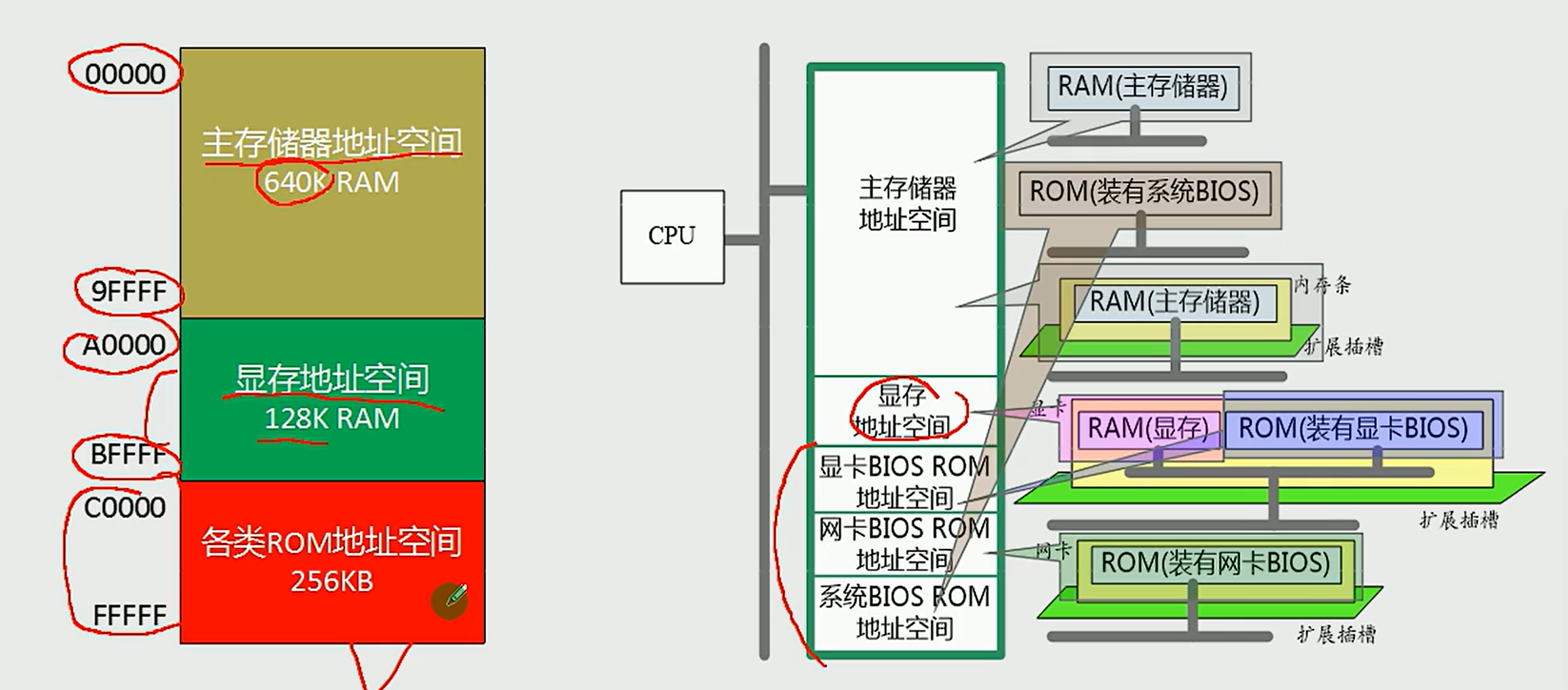
3.1 内存地址空间

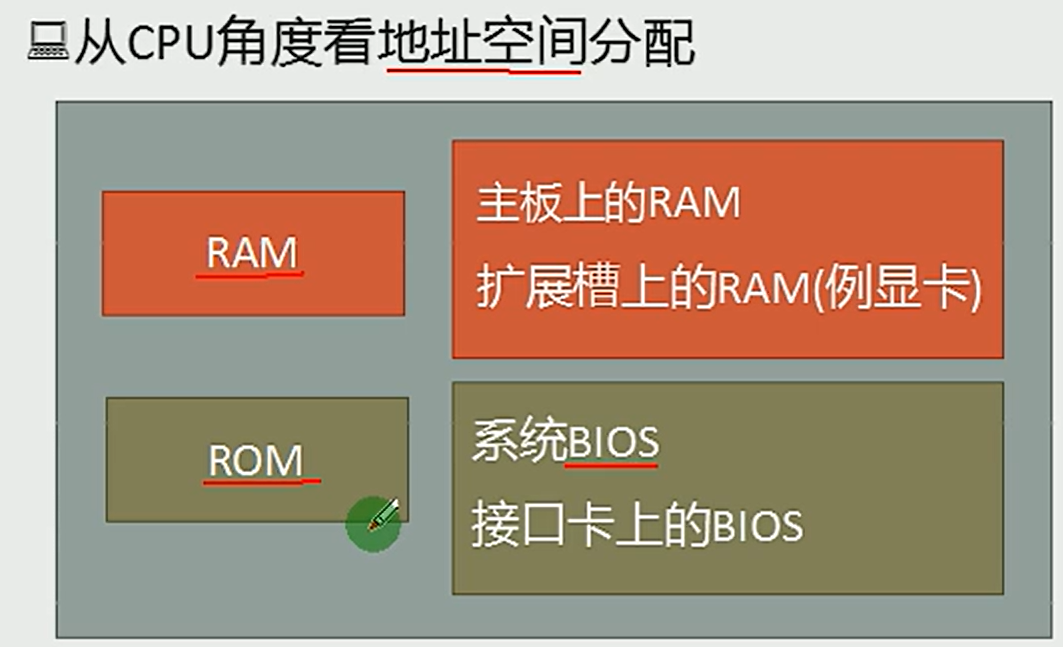
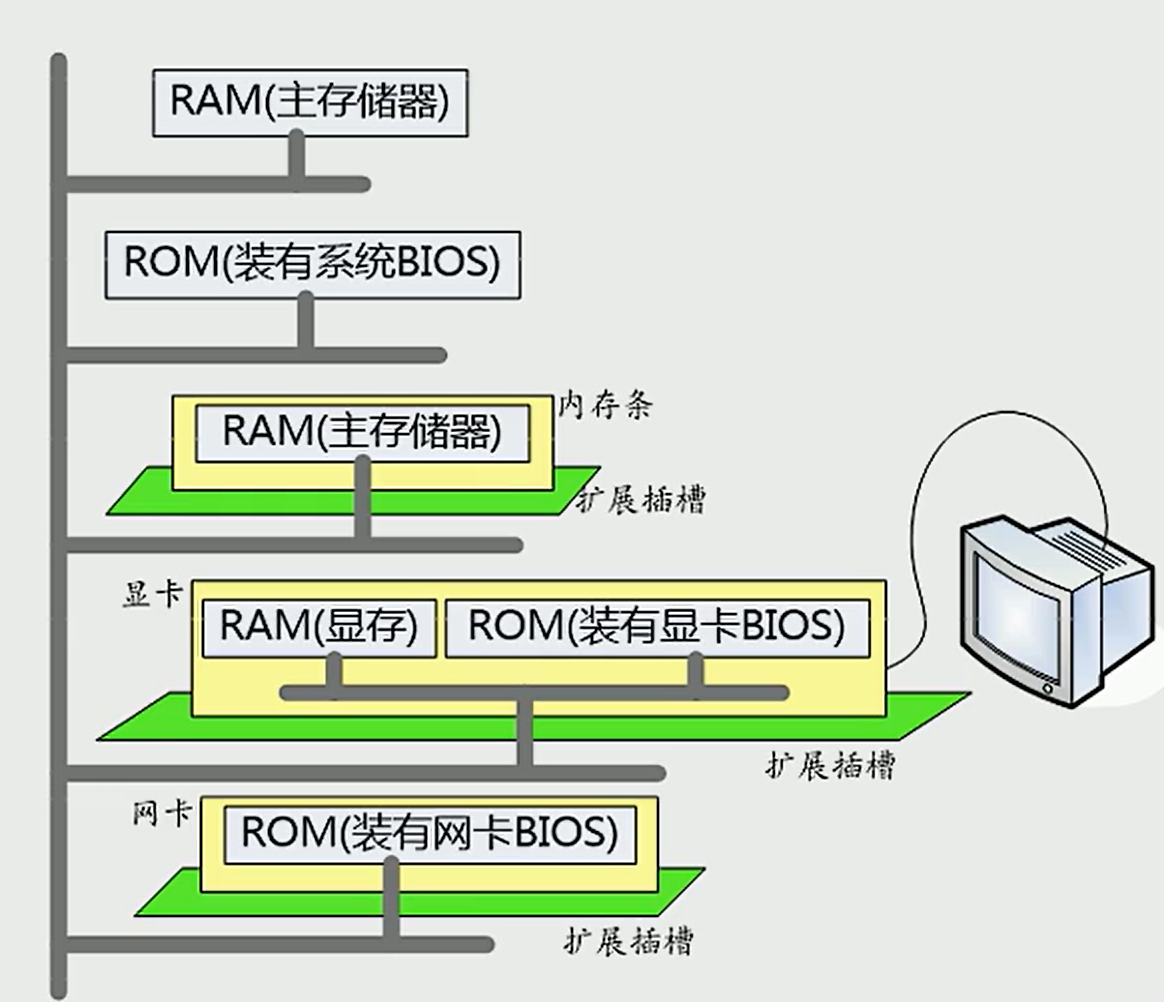
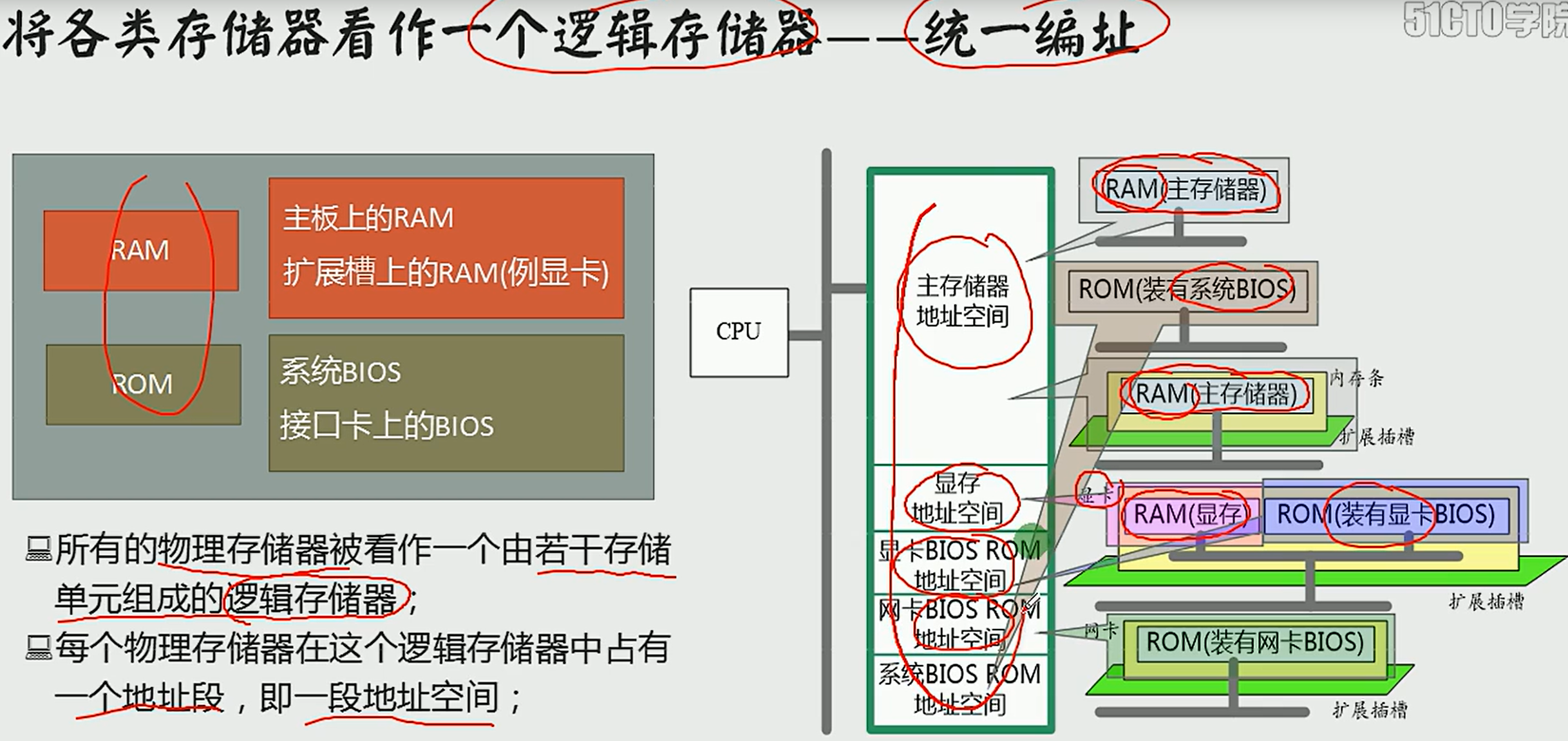
3.2 内存地址空间的分配方案
DOS的基本语法规则
二. 进入DEBUG
要观察计算机内部的情况,可直接进入 DEBUG。如果要调试及观察可执行文件,则要在 DEBUG 后加上文件名和扩展名 .EXE。我们先观察,因此直接键入 DEBUG 进入系统,如图所示。

DEBUG 的提示符是小短线 - ,在其后输入命令。
(1)R 命令——查看和修改寄存器
R 命令有两种用法:直接键入 R —— 将显示 CPU 所有的寄存器和标志位;
修改寄存器 —— 在 R 后跟写寄存器名(比如 R AX),回车后先显示寄存器的内容,在冒号后键入新的值;再用 R 命令就可看到修改后的内容了。如图所示,使用 R AX 将 AX 寄存器的值改为 1234H。
观察上图,由于此时 DEBUG 进入的是操作系统环境,R 命令显示的是系统下的寄存器的值。可看出,AX、BX、CX、DX 均为 0,如果将 AX 寄存器的值修改为 1234H,执行 R AX 之后在冒号后输入 1234 即可。注意,DEBUG 下的数据都是十六进制数。
再来看四个段寄存器 DS、ES、SS、CS 的值都是 07BEH,说明现在系统处在同一个逻辑段中(不同的系统环境下,段寄存器的值可能不一样,dosemu 虚拟机中为 07BEH)。操作系统根据内存的情况为各段分配段地址,因此每台机器或每次运行时段地址值可能会不一样。IP 指令指针寄存器的值是 0100H,表示将要执行的指令在代码段的 0100H 单元中。该指令单元的逻辑地址应该由 CS:IP 构成,即 07BE:0100H。
我们来看在寄存器的下面那一行的表示。该行显示的是代码段的一条指令的反汇编。所谓反汇编,指的是将二进制的机器指令显示成汇编指令。由三部分构成:最左边 07BE:0100 表示该指令所在单元的逻辑地址,中间 F60000 表示该指令的机器码,第 3 列显示为汇编指令 TEST BYTEPTR [BX+SI],00,该指令为 TEST 测试指令。
通过 DEBUG,我们就可知道一条汇编指令翻译成机器代码是什么值了;反之也一样,对一条机器指令也可得知它代表什么汇编指令。
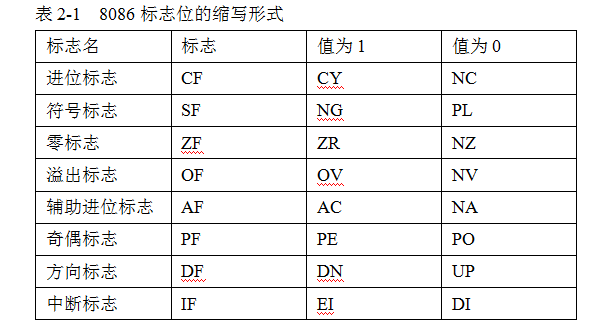
在图的最右边显示的是 CPU 标志寄存器各标志位的状态,可对照表 2-1 观察一下现在系统的状态。
(2)D 命令——查看内存单元
前面我们学到,内存每 16 个字节单元为一小段,逻辑段必须从小段的首址开始。用 D 命令可以查看存储单元的地址和内容。
D 命令格式为:
D 段地址:起始偏移地址 [结尾偏移地址] [L范围]例如:
D DS:0 查看数据段,从 0 号单元开始
D ES:0 查看附加段,从 0 号单元开始
D DS:100 查看数据段,从 100H 号单元开始
D 0200:5 15 查看 0200H 段的 5 号单元到 15H 号单元(在虚拟机上该命令不能执行)
D 0200:5 L 11 用 L 选择范围。查看 0200H 段的 5 号单元到 15H 号单元共 17 个单元D 命令的执行情况如下图所示。(由于 D 0200:5 15 无法在虚拟机中执行,因此我们给大家提供了一张非环境中的图片,用来展示效果)

其中左边一列为逻辑地址,中间部分为存储单元的内容。每行为 16 个字节单元,中间的小横线用于区分前 8 个单元和后 8 个单元。在逻辑地址中只给出每行第一个单元的偏移地址,其余 15 个单元的偏移地址没有标出。可以推断出图中第一行单元的偏移地址从 0000H 到 000FH,第二行单元的偏移地址为 0010H~001FH,以此类推。右边部分显示出内存单元中的 ASCII 码表示的字符,无法显示时用小点代替。
图中第一条 D 命令显示的是数据段存储单元的内容,可以看到数据段的段地址为 DS,其值 0B05H。0 号单元的内容为 CDH,1 号单元为 20H ,...,第 15 号单元的内容为 03H;第二行 0010H 号(16 号)单元的内容为 69H,它是小写字母 i 的 ASCII 码,因此右边区域中显示了 i ,表示该单元的值 69H 可以看成 ASCII 码。
第二条 D 命令显示 0200H 段中的内容,也是从 0 号单元开始。
第三条 D 命令从 0200H 段的 5 号单元开始显示直到 15H 号单元。
如果在 D 后面直接写出偏移地址,则显示当前数据段下偏移地址开始的内存单元,如:
D 10 从数据段10H号单元开始显示
D100 从数据段100H号单元开始显示注意:多次键入 D,可连续显示后面的单元内容。
(3)E 命令——修改内存单元
用 E 命令可以改写多个存储单元的内容。格式为:E 起始地址 修改值 修改值...
例如:将数据段中的 DS:3~DS:5 三个单元的内容修改为 14、15、16。命令为
E DS:3 14 15 16如下图所示。(由于 D DS:0 20 无法在虚拟机中执行,因此我们给大家提供了一张非环境中的图片,用来展示效果)

用 D DS:0 命令显示后,可以看到,这三个单元的值由原来的 9F 00 9A 修改为 14 15 16。
如果 E 后面直接跟偏移地址,则修改当前数据段下偏移地址所指单元值;还可以用 E 命令修改其它段的存储单元内容。
E 10 修改当前数据段10H号单元内容
E ES:100 修改附加段100H号单元内容
D ES:100 查看一下100H单元的内容是否修改了(4)U 命令 ——反汇编
程序员编写的汇编语言源程序经过汇编(编译)后生成了二进制的机器指令代码,而 U 命令可将二进制的机器指令变为助记符形式的汇编指令,因此称之为“反汇编”。通过 U 命令,我们可以得到机器指令与汇编指令的对照,了解机器指令的存储情况,如图所示。

左边为代码段中存储单元的逻辑地址,段地址 CS 的值为 0AFEH,偏移地址从 0100H 开始。紧靠偏移地址的一列为机器指令代码,右边部分是机器指令对应的汇编指令。例如第一行中,机器指令为 7419H,它对应的汇编指令为 JZ 011B,该指令是条件转移指令,表示当结果为 0 时跳转到偏移地址 011BH 单元中的指令继续执行。而 0AFE:011BH 单元的指令为 MOV BX,0034,是一条传送指令。(dosemu 虚拟机中是另一组不同的指令)。
注意:多次键入 U,可连续显示后面的程序部分。
U 后跟偏移地址,则从该地址开始反汇编。如:
U 0 从代码段0号单元开始反汇编
U100 从代码段100H号单元开始反汇编需要注意的是,图 2-22 中显示的程序代码并不是用户编写的程序,因为在输入 DEBUG 命令时没有写用户程序名.EXE。这段程序代码是系统代码段中保存的内容,有可能是系统程序,也有可能是无效的代码。
(5)A 命令——输入汇编指令
在 DEBUG 中,使用 A 命令可以输入汇编指令,系统自动地将键入的汇编指令翻译成机器代码,并相继地存放在从指定地址开始的存储区中。由于 DEBUG 下的数值默认为十六进制数,因此先要将十进制数转换成十六进制数。
例如,第 1 章提到的计算 Z = 35 + 27 的汇编指令为:
MOV AX,23H
ADD AX,1BH
MOV [0000],AX加法的结果 Z=62=3EH。变量 Z 用存储单元[0000]表示。这三条指令可在 DEBUG 下用 A 命令直接输入。输入 A 命令后,系统自动地给出逻辑地址为 0AEE:0100(CS:偏移地址),在其后输入汇编指令,回车后可输入下一条指令,直接回车则退出输入。
操作过程如下:

也可以在 A 命令后给出指令的存放地址,如 A CS:0000,表示从代码段的 0 号单元开始存放输入的指令。
(6)T/P 命令——单步执行
输入完指令后,应该执行它。T 命令可以一条一条地执行指令。P 命令的作用与 T 命令相同,当遇到中断指令 INT n 和调用指令 CALL 时,应该使用 P 命令,以确保程序正常执行。这是因为 INT n 指令和 CALL 指令都要转移到子程序去执行,T 命令进入子程序后可能无法返回;而 P 命令则直接执行该指令,并将结果带回。遇到循环指令 LOOP 时也应该使用 P 命令,可以使循环快速结束。
本次执行前,先用 R 命令查看指令指针寄存器 IP 的值是否为 0100,如果不是,用 R IP 命令修改为 0100。表示现在要从 CS:0100 单元开始执行指令。T 命令每执行一次,都要显示当前寄存器的状况,我们可以随时了解指令的执行情况。计算 Z = 35 + 27 的汇编指令的执行过程如下图所示。

查看执行结果:第一次执行 T 命令后,AX 寄存器的值改为 0023,第二次执行后,AX 的值变成 003E 了,说明已经执行完加法 ADD 指令了,第三次执行 T 后,寄存器的值并未发生变化,说明第三条指令没有对寄存器操作。第三条指令 MOV [0000],AX 是把结果保存到数据段的存储单元 0 号字单元中,用 D DS:0 命令查看该单元的值已经为 003EH 了(两个字节单元为一个字单元)。
T 命令还可以连续执行多条指令。如上例中连续执行 3 条指令,可用如下 T 命令:
-T 3T 命令也可以设置开始地址和执行条数。如上例中从 0100H 开始连续执行 3 条指令,可用如下 T 命令:
-T =0100 3(7)G 命令——连续执行程序
有关连续执行命令 G 的用法我们放到后面章节中学习。
(8)Q 命令 ——退出 DEBUG
键入 Q,回车后退出 DEBUG,返回到 DOS 下。
提示: DEBUG 的更多命令及用法参见本书附录 C。
(9) 参考的视频讲解和练习
汇编语言(第 2 版,郑晓薇著)配套实验 - DOS及DEBUG介绍
三. 汇编学习
1. 寄存器组
8086 寄存器都是 16 位的寄存器,根据用途可分为 4 种类型。分别是数据寄存器、地址寄存器、段寄存器和控制寄存器。
如图所示:

(1)数据寄存器
数据寄存器中每个寄存器又可以分为 2 个 8 位的寄存器。分别为 AH、AL,BH、BL,CH、CL,DH、DL。H 表示高字节(高 8 位)寄存器、L 表示低字节(低 8 位)寄存器。
例如:用 AX 寄存器存放一个字 1234H,表示为 (AX)=1234H,即高字节 12 放在 AH,低字节 34 放在 AL 中。
(2)地址寄存器
地址寄存器包括指针和变址寄存器 SP、BP、SI、DI 四个 16 位寄存器。
顾名思义,它们可用来存放存储器操作数的偏移地址。另外,它们也可以作为通用寄存器用。
(3)段寄存器
8086CPU 有 4 个 16 位的段寄存器,分别是 CS 代码段寄存器、DS 数据段寄存器、ES 附加段寄存器、SS 堆栈段寄存器。
(4)控制寄存器
控制寄存器包括 IP 和 FLAGS(又称为 PSW 程序状态字)两个 16 位寄存器,用于控制程序的执行。
IP 指令指针寄存器,用来存放代码段中的偏移地址,指出当前正在执行指令的下一条指令所在单元的偏移地址。
FLAGS 标志寄存器中的某位代表 CPU 的 1 个标志,表示出 CPU 的某种执行状态。最低位为 D0,最高位为 D15。8086CPU 的标志寄存器共有 9 个标志,分别为 6 个条件码标志和 3 个控制标志。如图:
(1)条件码标志
- CF 进位标志。当指令执行结果的最高位向前有进位时,CF=1,否则 CF=0。
- SF 符号标志。当指令执行结果的最高位(符号位)为负时,SF=1,否则 SF=0。
- ZF 零标志。当指令执行结果为 0 时,ZF=1,结果不为 0 时,ZF=0。
- OF 溢出标志。当指令执行结果有溢出(超出了数的表示范围)时,OF=1,否则 OF=0。
- AF 辅助进位标志。当指令执行结果的第 3 位(半字节)向前有进位时,AF=1,否则 AF=0。
- PF 奇偶标志。当指令执行结果中 1 的个数为偶数个时,PF=1,否则 PF=0。
(2)控制标志
- DF 方向标志。执行串处理指令时,若设置 DF=0,存储单元的地址寄存器的值自动增加,若设置 DF=1,存储单元的地址寄存器的值自动减小。
- IF 中断标志。设置 IF=1,允许 CPU 响应可屏蔽中断,IF=0 则不响应。
- TF 陷阱标志。在 DEBUG 调试时,TF=1,采用单步执行方式,即进入陷阱;TF=0,正常执行程序。
例:两个二进制数相加运算,有关标志位自动发生变化。
根据计算结果可知 CPU 会自动地把标志位设为:CF=0,SF=1,ZF=0,OF=0,PF=0,即无进位,结果为负数,结果不为 0,没有溢出,奇数个 1。
对溢出的判断也可以从简单的角度理解,因为进行运算的二进制数是补码,可看出本题是一个负数和一个正数相加,结果为负数,不溢出。若两个正数相加,结果为负数,或者两个负数相加,结果为正数,那都是溢出了,说明 8 位补码已经表示不了该结果。
小贴士 DEBUG 下的标志位表示
在 DEBUG 调试环境下以字母缩写的形式表示各个标志位的状态。进入 DEBUG 后,用 R 命令查看寄存器状态时,可以看到除了陷阱标志以外的标志位的状态。
如表 2-1 所示:
小贴士 数的补码运算
在计算机中,对带符号数可用真值和机器数两个概念表示。
真值,就是带有“+”、“-”号的实际数值;所谓机器数,则是把“+”、“-”符号数值化(0、1)后所得到的计算机实际能表示的数。
机器数有三种码表示,分别是原码、反码和补码。汇编语言中,数都是以补码的形式表示的,因此必须掌握数的补码表示和补码的运算。这三种码的定义如下:
- 原码。原码将最高位作为符号位,正数为 0,负数为 1,其余 7 位作为数值位。
- 反码。正数的反码与正数的原码一样。而求负数的反码时,符号位为 1,数值位在原码的基础上求反。
- 补码。正数的补码与正数的原码一样。求负数的补码时,符号位为 1,数值位在原码的基础上求反加 1。
例:十进制数 +5 和 -5 分别表示成二进制数原码、反码和补码。
[+5]原 = [+5]反 = [+5]补 = 00000101B
[-5]原 = 10000101B
[-5]反 = 11111010B
[-5]补 = 11111011B2. 内存
在汇编语言中,内存是非常重要的学习内容。我们先要对内存地址和存储单元的概念进行学习。
对存储单元的标识可以用物理地址或逻辑地址表示。
(1)物理地址
物理地址是内存单元的真实地址,存储单元的物理地址是唯一的。
Intel 8086 CPU 有 20 根地址线,因此其存储空间可达 2 的 20 次方 = 1 M 个字节单元(1MB)。地址都是从 0 开始的,在 20 位地址线的存储空间中采用十六进制表示的物理地址范围是 00000H ~ FFFFFH。
(2)逻辑地址
逻辑地址是用户编程时使用的地址,分为段地址和偏移地址两部分。
在 8086 汇编语言中,把内存地址空间划分为若干逻辑段,每段由一些存储单元构成,每段最大为 65536 个字节单元(0 号单元~65535 号单元 0000H~FFFFH)。用段地址指出是哪一段,偏移地址标明是该段中的哪个单元。段地址和偏移地址都是 16 位二进制数。
为什么要这么搞:因为20根地址线的寻址能力是1M ,而寄存器只有16位,所以用两个16位地址的寄存器拼成一个20位的物理地址
逻辑地址的形式:段地址:偏移地址。
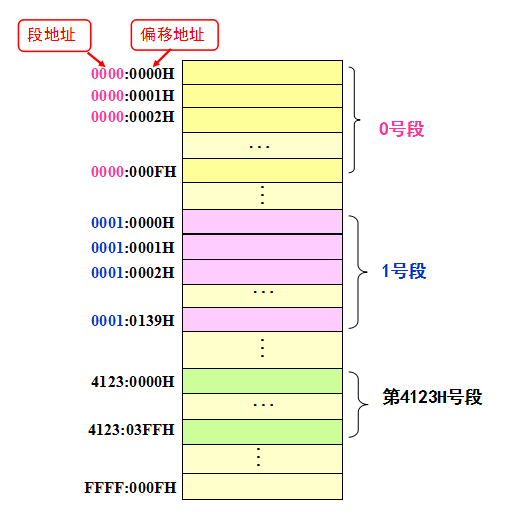
例如:在上图中,内存划分出了若干段。0 号段,1 号段,...,每一段都有 0 号单元、1 号单元、2 号单元,...。每段的长度可以不一样,如 0 号段从 0 号单元到 0FH 号单元共 16 个字节单元,1 号段从 0 号单元到 0139H 号单元共 314 个字节单元。
用段地址表示段号,偏移地址代表每一段中的单元号,比如 0000:0002H 代表 0 号段的 2 号单元,0001:0002H 代表 1 号段的 2 号单元,以此类推。因此,偏移地址的通俗含义是在该段内,相对于段地址偏移了多少个单元。
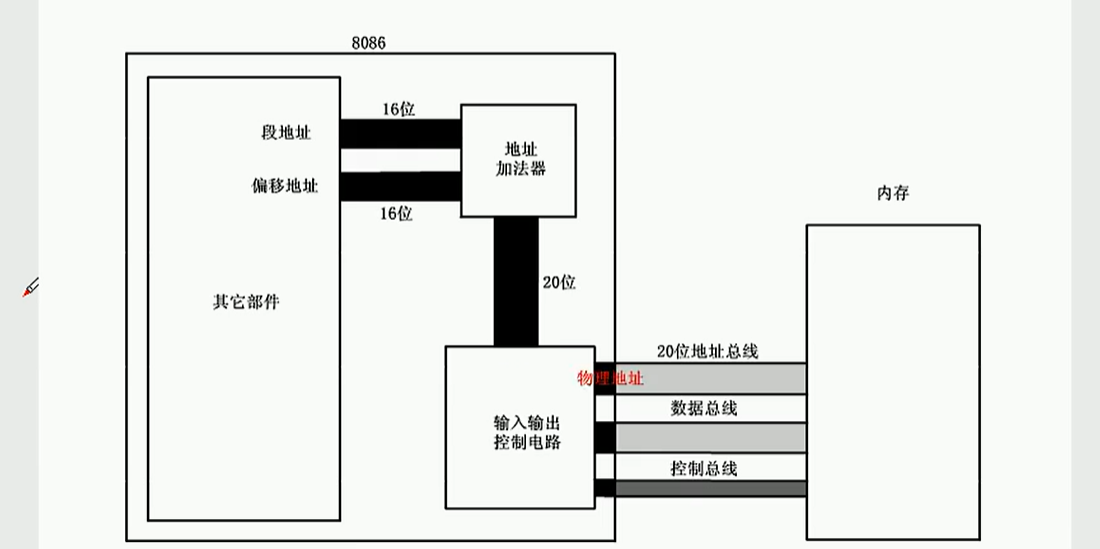
(3)逻辑地址转换为物理地址
用户编程时采用的逻辑地址在 CPU 执行程序时都要转换成实际的物理地址,这个转换过程是由 CPU 中的地址加法器自动完成的。
转换时先将 16 位的段地址左移 4 位,相当于乘以 16 或十六进制的 10H,再和偏移地址相加。转换公式为:
物理地址 = 段地址 × 10H(也就是*16) + 偏移地址例:若某单元的逻辑地址为 0001:0002H,其物理地址 = 0001H × 10H + 0002H = 00012H;另一单元的逻辑地址为 3020:055AH,其物理地址 = 3020H × 10H + 055AH = 3075AH。
存储器逻辑分段类型如下:
- 代码段:用于存放指令,段地址存放在段寄存器 CS。
- 数据段:用于存放数据,段地址存放在段寄存器 DS。
- 附加段:用于辅助存放数据,段地址存放在段寄存器 ES。
- 堆栈段:是重要的数据结构,可用来保存数据、地址和系统参数,段地址存放在段寄存器 SS。
存储单元中的数据称为存储单元内容,一个实际的存储单元只能存放一个字节(8 位二进制)的数据。存储单元的地址和内容的表示形式为用括号将地址括起来以代表单元的内容。如(3075AH)=12H,表示 3075AH 号单元中的内容是 12 H,称为字节单元;若(37692H)=5678H,表示 37692H 单元和 37693H 单元一起存放 5678H,该单元是字单元。字单元在存储的时候,高字节放在高地址单元,低字节放在低地址单元,即 56H 放在 37693H 单元,78H 放在 37692H 单元。如图:
有关 CPU 和存储单元的概念我们已经了解了,那么如何观察实际机器内部的情况呢?能不能看到具体的寄存器、标志、存储单元的内容呢?可不可以修改和控制它们呢?
这一系列的疑问我们可以在调试工具软件 DEBUG 的支持下得到解答。通过上机实验,可加强相关理论概念的理解;而掌握了 DEBUG 这个有力工具,就可以深入到机器内部进行观察了。
(4)逻辑地址到物理地址的具体实现方法
段地址和偏移地址通过地址加法器来实现从其它部件寻址到相应内存
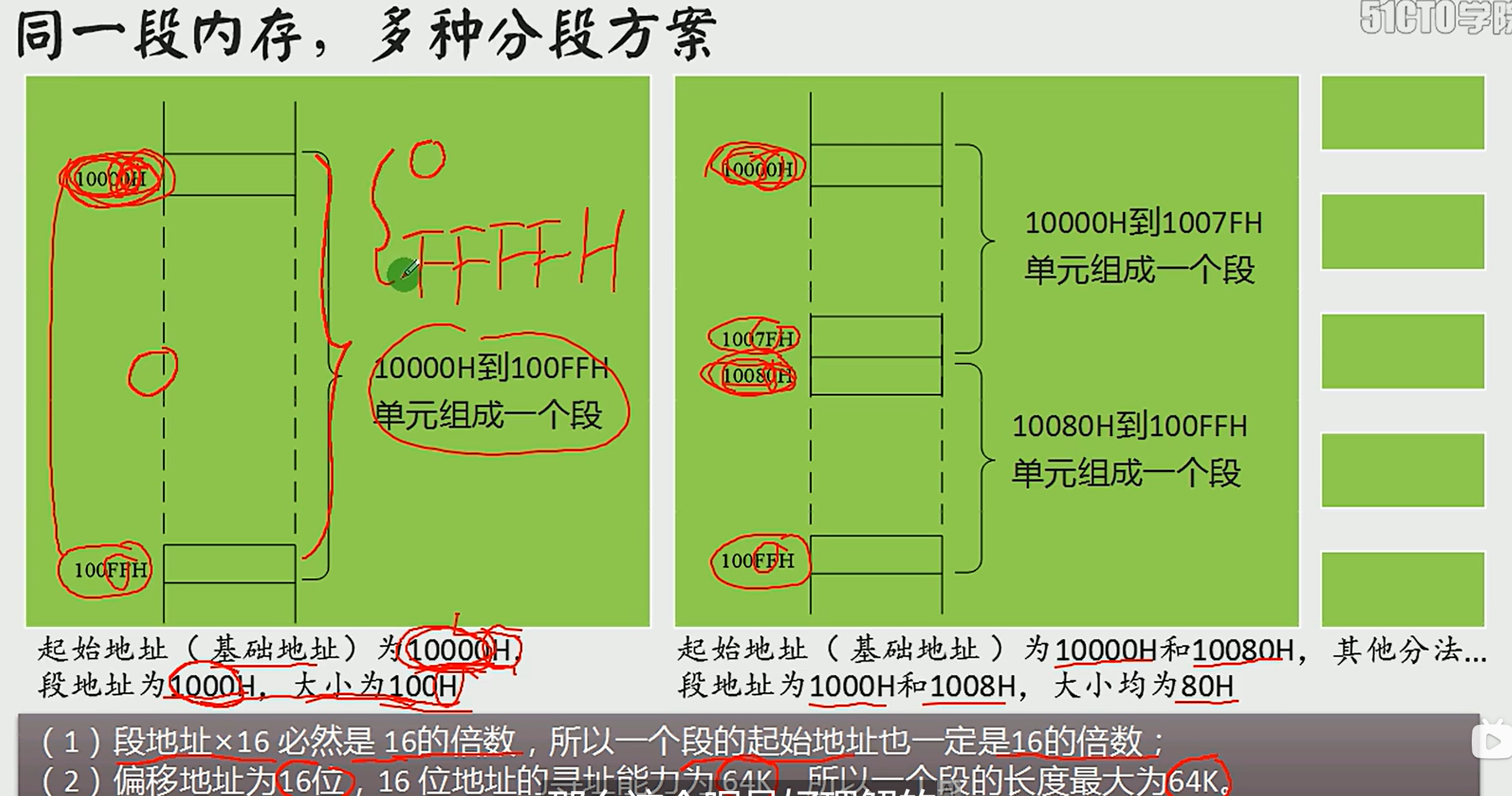
(5)不同内存的分配方案
内存没有分段,段的划分来自于CPU 我们可以随意分段
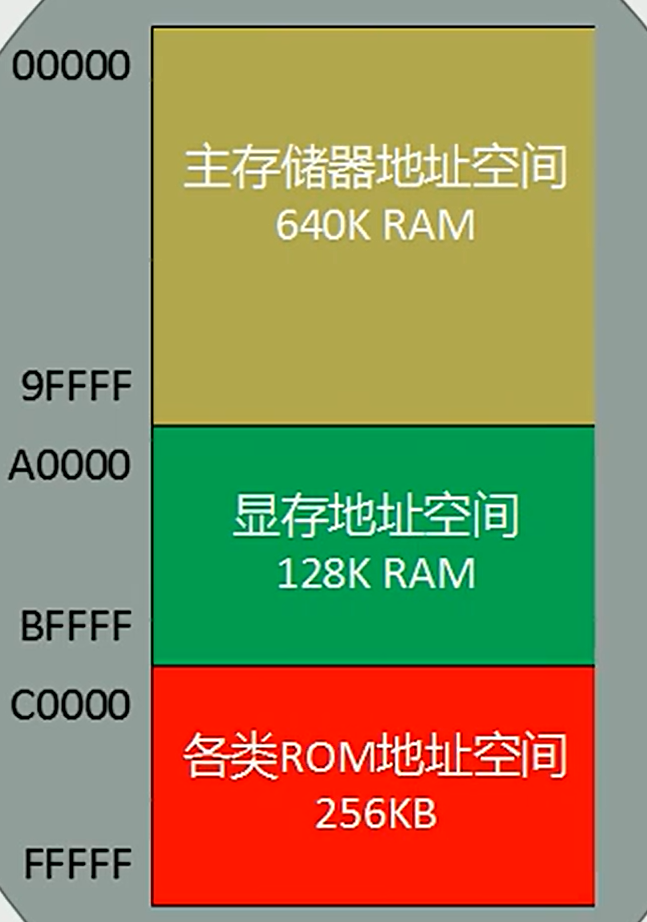
所以同一种地址有不同的分段方案,不同的物理地址可以使用不同的不同的段地址和偏移地址来表示
3. 寻址方式
汇编指令由 操作码字段 和 操作数字段 构成。对于双操作指令,第一个操作数称为目的操作数,表示操作后的结果;第二个操作数称为源操作数,表示来源操作数。两者以逗号分隔。如:
所谓寻址方式,即指令中提供操作数或操作数地址的方式。通俗地说就是寻找操作数地址的方法。寻址方式的数量代表了微机系统对存储器管理能力的强弱,合理地使用寻址方式可以扩大访存空间,缩短指令长度,满足各种程序设计需要。
与数据有关的寻址方式划分为三类:立即寻址方式,寄存器寻址方式,存储器寻址方式。
七种与数据有关的寻址方式。其中后五种属于存储器寻址方式。
- 立即寻址方式(Immediate addressing)
- 寄存器寻址方式(Register addressing)
- 直接寻址方式(Direct addressing)
- 寄存器间接寻址方式(Register indirect addressing)
- 寄存器相对寻址方式(Register relative addressing)
- 基址变址寻址方式(Based indexed addressing)
- 相对基址变址寻址方式(Relative based indexed addressing)
我们看到,常用的寻址方式有 7 种之多,到底选择哪一种为好呢?选择寻址方式有两条原则:第一实用,第二有效。最终都应达到运行速度快、指令代码短的高效率目标程序的目的。立即寻址和寄存器寻址无论从指令长度和指令执行时间都比存储器寻址要好,但是也要根据具体情况选用。
学会使用寻址方式是理解指令作用的关键,也是掌握程序设计技巧的一种途径
3.1 立即寻址
所要找的操作数直接写在指令中,这种操作数叫立即数。在 8086、80286 中立即数是 8 位或 16 位的,在 80386 以上可以是 32 位的立即数。立即寻址方式用来表示常数。相当于给寄存器赋值
在 DEBUG 下数据都是十六进制表示的,因此不需要用 H 标注,同时要把十进制变为十六进制才行。
在 DEBUG 下执行:
-A
MOV AX,3060
MOV AL,5
MOV BL,FF
MOV BX,A46D
MOV CX,17接着用 T 命令单步执行,观察各寄存器的值。
注意: 执行 T 命令之前,指令指针寄存器 IP 的值要用 R IP 修改成第一条指令的偏移地址,这样 T 命令才能从第一条指令开始执行。
3.2 寄存器寻址方式
在寄存器寻址方式中,操作数在寄存器中,在指令中指定寄存器名即可。
在 DEBUG 下执行:
-A
MOV AX,0
MOV BX,1234
MOV AX,BX
MOV CL,AH
MOV AX,4650接着用 T 命令单步执行,观察各寄存器的值。要注意指令指针 IP 的值是否指向了要执行的指令。
3.3 直接寻址方式
操作数存放在内存中。操作数的偏移地址(也称为有效地址 EA)直接写在指令中。
(1)存储器读操作
MOV 指令可以实现 CPU 对存储器的读写。若传送指令的目的操作数是 CPU 的寄存器,源操作数是存储单元,就完成了对存储器的读操作。
例如:MOV AX,DS:[2000H] 表示该指令表示从数据段的 2000H 单元读出一个字送入 AX。
(2)存储器写操作
如果要实现 CPU 写内存操作,只要把 MOV 指令的目的操作数变为存储单元,源操作数为 CPU 的寄存器即可。
例如:MOV DS:[4000H],AX 将 AX 的值写入数据段的 4000H 单元。
在 DEBUG 下执行:
-A
MOV AX,DS:[2000]
MOV DS:[4000],AX接着用 T 命令单步执行,观察 AX 寄存器的值;用 D DS:2000 和 D DS:4000 命令观察这两个存储单元的值。
3.4 寄存器间接寻址方式
操作数存放在内存中。
指令形式如:
MOV AX,[BX]操作数的 EA 在基址寄存器 BX、BP 或变址寄存器 SI、DI 中,而操作数的段地址在数据段 DS 或堆栈段 SS 中。如果有效地址由 BX、SI、DI 指出,则默认为对应于数据段,而用 BP 指出则对应于堆栈段。
思考一下,在 DEBUG 下执行时,如果按照上例给出的数据段地址和 BX 值来执行,如何实现呢?执行后怎样看到 AX=2364H?
-R DS 1500
-E DS:4580 64 23
-D DS:4580
-A
MOV BX,4580
MOV AX,[BX]接着用 T 命令单步执行,观察 AX 寄存器的值。
注意:指令指针 IP 的值是否指向了要执行的指令?
3.5 寄存器相对寻址方式
操作数存放在内存中。
指令形式如:
MOV AX,[BX+1200H]操作数的 EA 是一个基址或变址寄存器的内容再加上 8 位或 16 位位移量之和。也就是说在寄存器间接寻址的基础上,增加一个相对量(位移量)。这个位移量可以是立即数,也可以是符号地址。
思考一下,如果按照上例给出的参数来执行,在 DEBUG 下执行时如何修改指令呢?执行后怎样看到 AX=2428H?
提示:符号地址 TOP 直接用 25H 表示。
-R DS 1500
-E DS:7335 28 24
-D DS:7335
-A
MOV SI,7310
MOV AX,25[SI]接着用 T 命令单步执行,观察 AX 寄存器的值。
注意:执行 T 命令之前,指令指针寄存器 IP 的值要用 R IP 修改成第一条指令的偏移地址。
3.6 基址变址寻址方式
操作数存放在内存中。
指令形式如:
MOV AX,[BX+SI]操作数的 EA 为一个基址寄存器和一个变址寄存器的内容之和。
3.7 相对基址变址寻址方式
操作数存放在内存中。
指令形式如:
MOV AX,[BX+SI+1200H] 操作数的 EA 为一个基址寄存器加一个变址寄存器再加一个位移量,三者之和。可用于二维表查表和栈处理。
自己做:自定各个寄存器的参数,在 DEBUG 下执行指令后得到 AX=3568H。
4. 指令学习(不区分大小写)
4.1 MOV和ADD指令
例子如下:

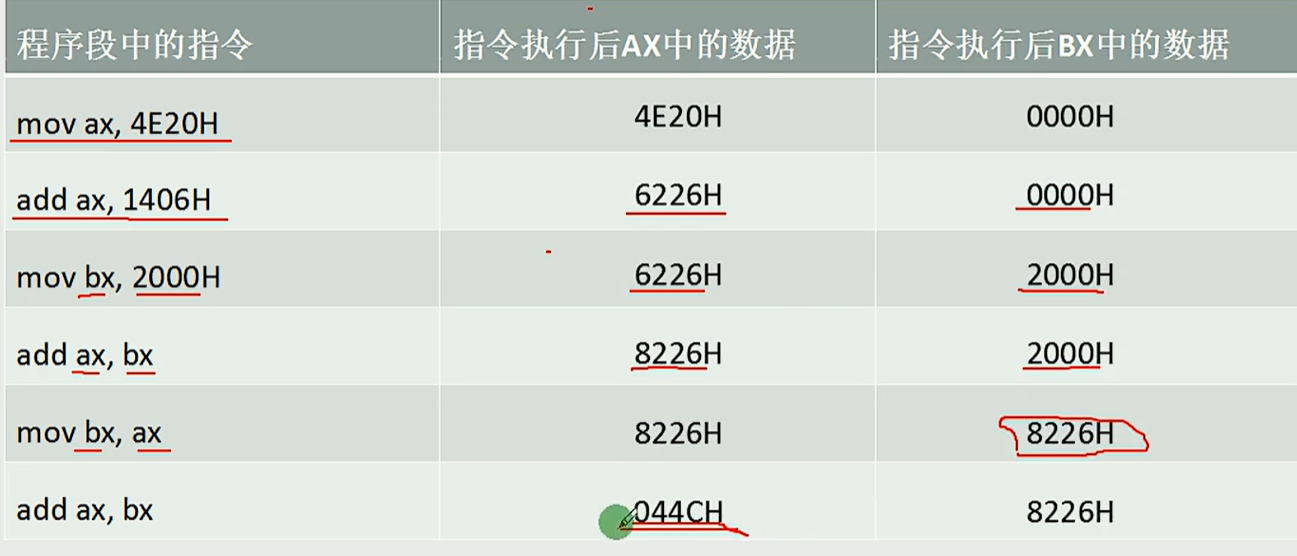
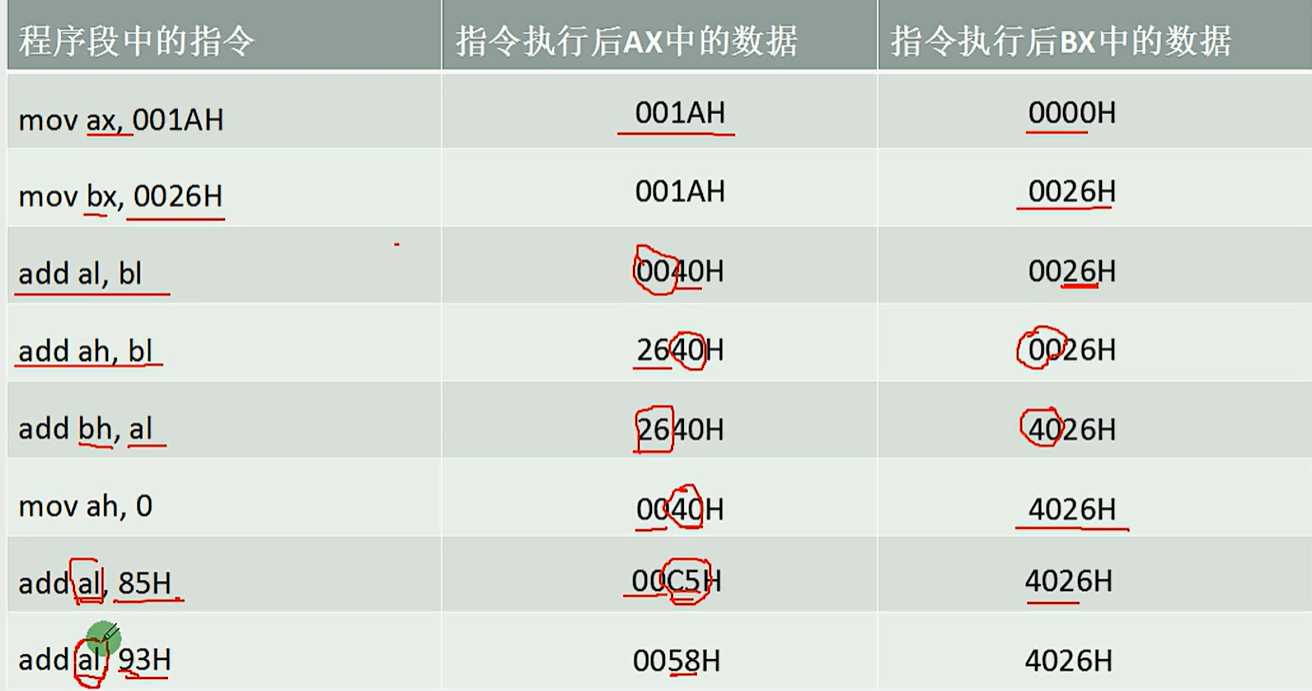
注意:低位相加不能进到高位
4.2 CS IP和代码段
两个关键的寄存器
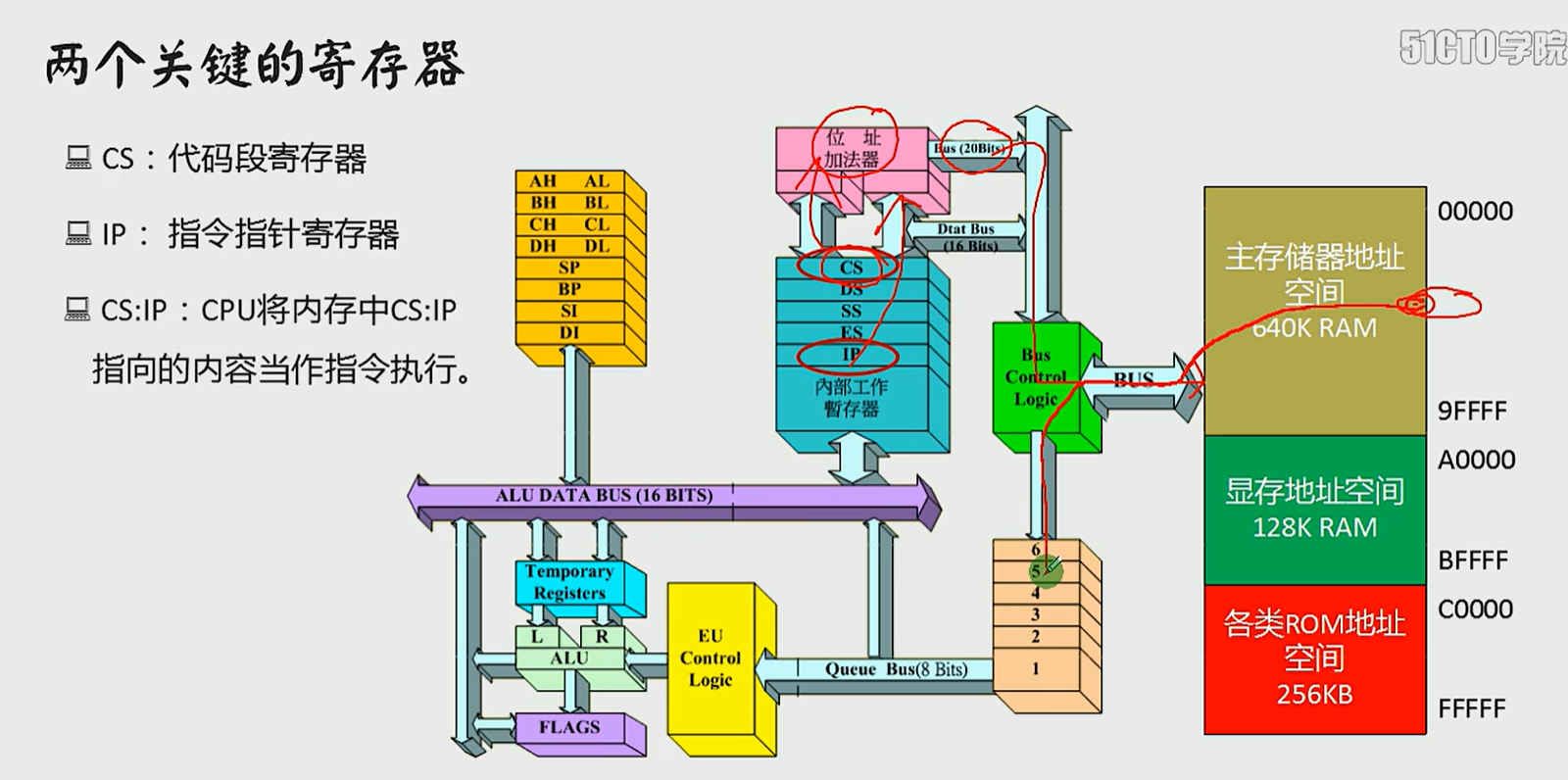
具体的静态示意图
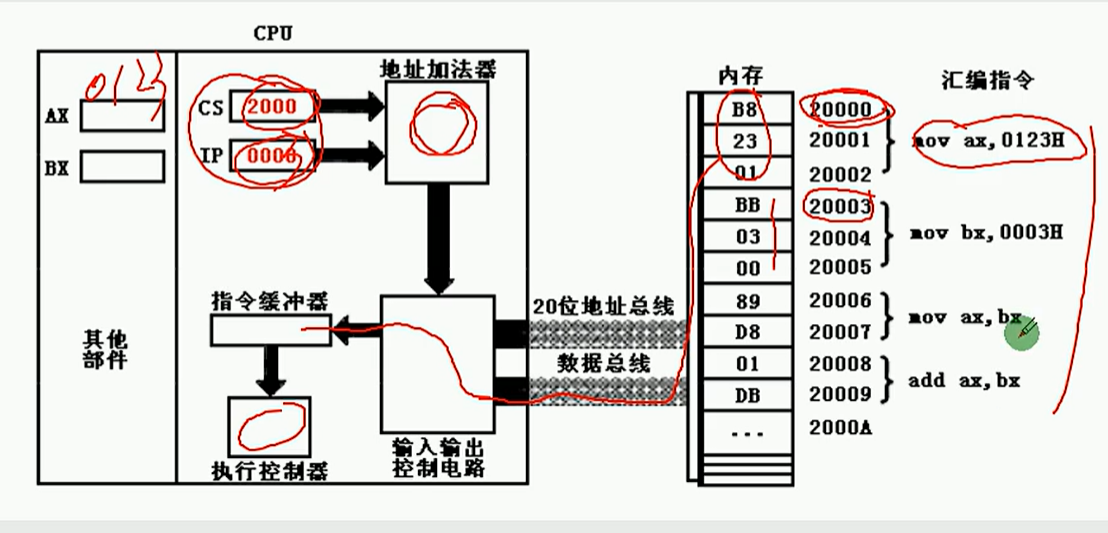
动态示意图:
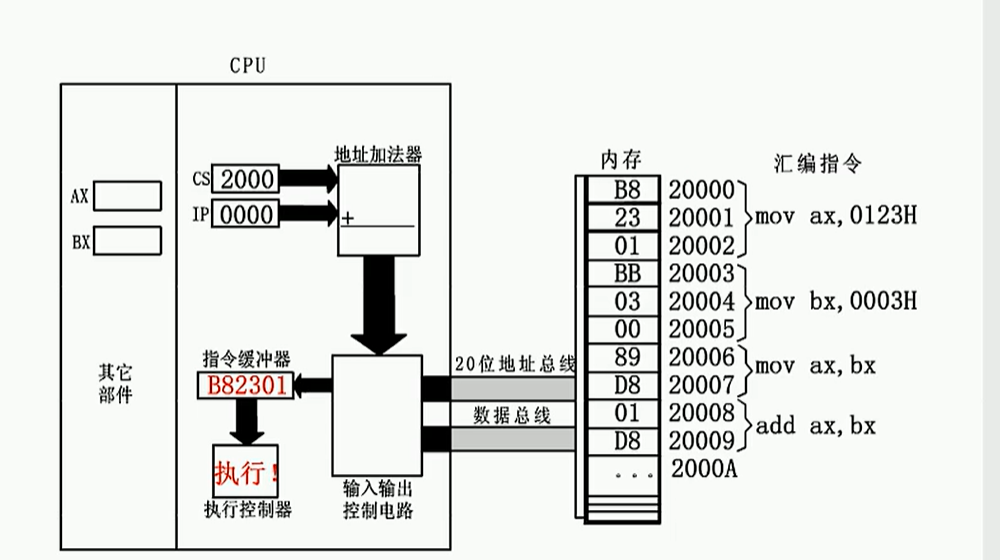
执行之后IP自动加3

- 一段内存中的数据比如B8 23 01 BB 03 00 ...是作为一般数据使用还是作为指令使用取决于程序员
- 当CPU将CS:IP指向内存单元的某一个内容,该内容就可以看作是指令,否则就是数据
4.3 jmp指令
- 原因:修改CS、IP的指令
- 事实:执行何处的指令,取决于CS:IP
- 应用:可以通过改变CS、IP中的内容,来控制CPU要执行的目标指令
- 问题:如何改变CS、IP的值 ?
- 方法1 : Debug中的R)命令可以改变寄存器的值- - - -rcs, rip
- 方法2 :用指令修改
- 方法3:jmp指令
不能直接移动修改
mov cs, 2000
mov ip, 0100
这些都是错误的
下面的可以
mov ax,2000
mov cs ,ax
ip就不能修改
通常是用jmp
jmp 2ae3:3 两个都修改
jmp ax 相当于上面的--修改了某一个合法的寄存器4.4 内存中的字
8086CPU 用16位作为一个字 高8位放在高字节,低8位放在低字节,如图所示,存储4e20 0012 容易看反了,一定要注意!!!

字单元的定义

4.5 DS和[address]实现字传送
原因:CPU要读取一一个内存单元的时候,必须先给出这个内存单元的地址;
解决方案:(DS和[address])配合——用DS寄存 器存放要访问的数据的段地址,偏移地址用[..]形式直接给出;
例子:必须使用通用寄存器,不能直接赋值


一个完整的案例:(一步一步画出来就好了)
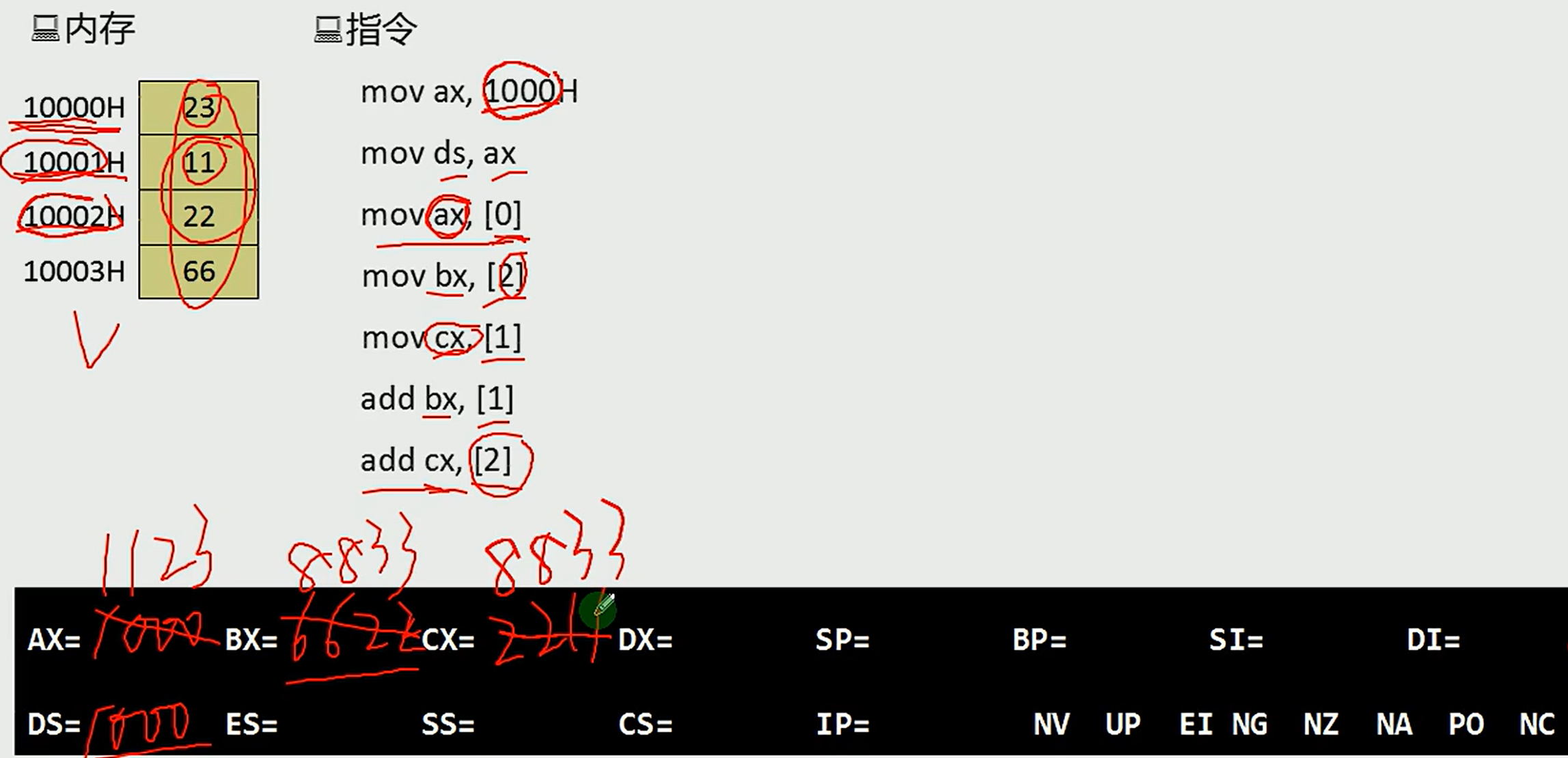
CS和DS的总结:
CS是代码段寄存器,存储的是要执行的代码,而DS是数据段寄存器,存储的是要移动的数据,两个寄存器存储的都是地址,分别是要执行代码的地址以及数据存储所在的地址
5. 汇编的程序设计
5.1 一个简单小例子
编写一个汇编语言程序,实现下列公式计算(假设 X = 4、Y = 5)。
汇编指令如下:
如果在 DEBUG 下用 A 命令输入这些指令,必须把 X、Y 换成具体的数值(假设 X = 4、Y = 5);Z、Z1 是存储单元地址,最后两条指令可写为 MOV [0],AL 和 MOV [1],AH,这样才能用 T 命令执行。
D:\dos〉DEBUG
-A
MOV AL,4 ; X = 4
ADD AL,5 ; Y = 5
MOV BL,8
IMUL BL
MOV BL,4
MOV B,0
SUB AX,BX
MOV BL,2
IDIV BL
MOV [0],AL
MOV [1],AH最后我们使用 T 命令执行。
采用 DEBUG 的 A 命令输入程序的做法明显不方便,一是无法给出变量名即符号地址,二是调试修改程序不便。因此,采用编写源程序的方式更有利于程序的调试和执行
5.2 编写汇编语言源程序
一个完整的汇编语言源程序需要增加段定义伪指令和定义数据存储单元伪指令等必须有的伪指令。伪指令与 C 语言等高级语言中的说明性语句的含义类似,起到说明作用。有了伪指令,系统在汇编该程序时,就会正确的将源程序翻译、连接成可执行文件。(有关伪指令的其他用法参看本教材 4.2 节)
我们先给这个源程序起名为 ABC.ASM(汇编源程序的扩展名为.ASM)。在宿主机中用记事本 gedit 或者在 dos 子目录下用 edit 输入源程序。
实验步骤:
(1)双击实验楼环境桌面上的记事本 gedit,录入下列程序(分号后为注释,可不输入)
汇编语言源程序既可以用大写字母也可以用小写字母书写。
(2)按 save 按钮保存程序:
(3)选择路径、文件夹及输入文件名:
5.3 源程序到可执行程序
汇编语言程序建立及汇编过程如图所示。
用户编写的源程序要经汇编程序 MASM 汇编(翻译)后生成二进制目标程序,文件名默认与源程序同名、扩展名为 .OBJ;再经过 LINK 连接生成可执行程序,文件名默认与源程序同名、扩展名为 .EXE。
注意:源程序一定要和 MASM、LINK 文件放在同一个文件夹中(在实验楼的环境中,它们都在 dosemu 环境的 D:\dos\ 文件夹中,可以进入这个目录后用 dir 命令查看)。
执行 MASM 和 LINK 命令时需要按多次回车。
执行步骤:
(1)输入汇编命令 masm abc.asm
注意:此处显示 0 个警告性错误,0 个严重性错误。如果有错误,必须对源程序进行修改。有关出错提示信息参见教材附录 B。
(2)输入连接命令 link abc.obj
注意:此处有一个警告性错误:no stack segment 没有堆栈段。这个提示是由于我们的程序中没有定义堆栈段,此错误可以忽略,不影响生成 .exe 文件。如果出现严重性错误,必须再检查一下源程序有无错误。
(3)用 dir 查看一下
已经生成了 abc.exe 可执行程序了。如果程序有错误,再回到记事本修改错误;之后需要重新汇编和连接。
(4)接着运行该程序 abc.exe(运行的方式是直接在 dosemu 中输入 abc.exe),可以看到没有显示任何结果就退回到 DOS 下了。
5.4 在DEBUG下执行程序
如果源程序无错误,就能汇编、连接成为可执行程序 abc.exe。
由于该程序没有写显示结果的指令语句,要想观察结果必须用 DEBUG 调试工具。
(1)输入 DEBUG abc.exe
(2)输入两次 U 命令后可以看到结束程序语句 MOV AH,4C 指令对应的偏移地址是 0023,这就是断点(所谓断点,就是程序执行到该处停下来不再继续)。用 G 0023(G 断点)执行程序。此时得到 AX=0022,再执行 D DS:0 查看存储单元,第 0 号单元是 04,即 X 单元,05 是 Y 的值,22 就是计算结果 Z 的十六进制数。
(3)按 Q 退出 DEBUG

 浙公网安备 33010602011771号
浙公网安备 33010602011771号