

k8s笔记--驱逐与重调度,以及deschueduler的一次实验
在Kubernetes中,调度是指将Pod放置到合适的Node上,然后对应的Node上的Kubelet才能够运行这些pod。调度器通过Kubernetes的监测机制来发现集群中新创建且尚未被调度的Node上的Pod。K8s中默认的调度器是kube-scheduler, 当然,也可以自行实现一个自定义的调度器。
在开始之前,先来看几个相关的概念:
驱逐:
kubelet监控集群节点的CPU, 内存,磁盘空间和文件系统的inode等资源。当这些资源中的一个或多个达到特定的消耗水平,kubelet可以通过主动地使节点上一个或多个Pod失效,以回收资源防止资源不足。(当然,kubelet在终止最终用户Pod之前会尝试回收节点级资源。例如,它会在磁盘资源不足时删除未使用的容器镜像。当然这不在我们的考虑范围内。) 驱逐实质上是kubelet主动终止Pod以回收节点上资源的过程。
由kubelet发起的驱逐称为节点压力驱逐,这种方式下,如果使用了 软驱逐条件 kubelet会考虑配置的 eviction-max-pod-grace-period (驱逐宽限期), 如果使用了 硬驱逐条件 它会立即驱逐pod。
当然也可以通过API发起驱逐,API发起的驱逐通过Eviction API创建驱逐对象,由它来体面地中止Pod。API发起的驱逐将尊村你的PodDisruptionBudgets (干扰预算,即PDB) 和 terminationGracePeriodSeconds (pod生命周期)配置。
重调度:
将pod调度到指定的Node上运行是一个比较复杂的过程,有几个概念需要介绍一下:
- nodeSelector 通过在PodSpec中定义它,选择node标签中包含每个键值对的对应的节点
- 亲和性与反亲和性(affinity/antiaffinity) 相比之下,这个规则更想是 软需求 或是 偏好,因此如果调度器无法满足该要求,仍然调度该pod
- 可以使用node里的pod的标签来约束,而不是使用node本身的标签。这可以实现允许哪些pod应当放到一起,或者不应当放到一起。
- 污点和容忍度(taints/tolerations) 上面的亲和性与反亲和性,nodeSelector都是Pod的一种属性。而污点则是Node上属性,它能使节点排斥一类特定的Pod
- 想像一下pod都是有洁癖的,一旦node上有污点并且pod不能容忍这个污点,那么这个pod就不会被分配在这个node上
- 同样,pod如果可以容忍污点,还是可以正常的分配。
- 一个node上可以有0个或多个污点
- PDB: PodDisruptionBudget能够针对自发的驱逐(即上面提到的通过API发起驱逐)提供保护
- 例如将minAvailable设置为10,那么即使是在干扰期间,也必须保证始终有10个Pod可用
- PDB不能完全保证指定数量/指定百分比的Pod一直处于运行状态,如当Pod集合的规模处于预算指定的最小值时,恰好某个pod又发生了故障,就会导致pod数量低于预期值。
污点的effect值NoExecute会影响已经在节点上运行的Pod,此时
- 如果pod不能忍受effect值为NoExecute的污点,那么Pod将被马上驱逐
- 如果Pod能忍受这个污点,但在容忍度tolerationSeconds上没有定义,则Pod还会一直在节点上运行
- 如果Pod能够忍受这个污点,并且指定了tolerationSeconds,那么pod还会在这个节点上运行指定的时间长度
------------------------------------------------分割线-------------------------------------------------------------------------------------------------
下面是笔者关于descheduler的一次实验
先简单介绍一下,descheduler是由社区提供,用于支持多种策略的调度器,可以根据不同策略对pod进行二次调度,使得node的使用率更加均衡一些。descheduler本身也支持许多不同的调度策略。
准备工作:
deschueduler部署:
社区提供了基于Helm, Kustomize等多种部署方式,这次实验采用的是手动部署的方式
- git clone 源代码
- make image 生成镜像文件
- docker tag / docker push 准备好镜像文件
- 修改descheduler/kubernetes/base下的configMap文件,禁用其他策略,仅保留RemoveDuplicates,用于驱逐在同一个node上部署的多个相同pod的副本
kubectl create -f kubernetes/base/rbac.yaml 为descheduler授权- kubectl create -f kubernetes/base/configmap.yaml 初始化配置相关文件
其他准备:
针对要测试用的pod
- 修改pod spec, 添加nodeSelector
- 为集群下105,106,108node添加对应的labels
- 部署pod有一定概率在108机器上同时部署两个相同的pod (此处基于kube-scheduler的默认调度策略,未查看具体原因)
实验记录:
1. 通过kubectl get pods -n 你的namespace -o wide 查看pod,确认确实有两个相同的pod都部署到了108节点上

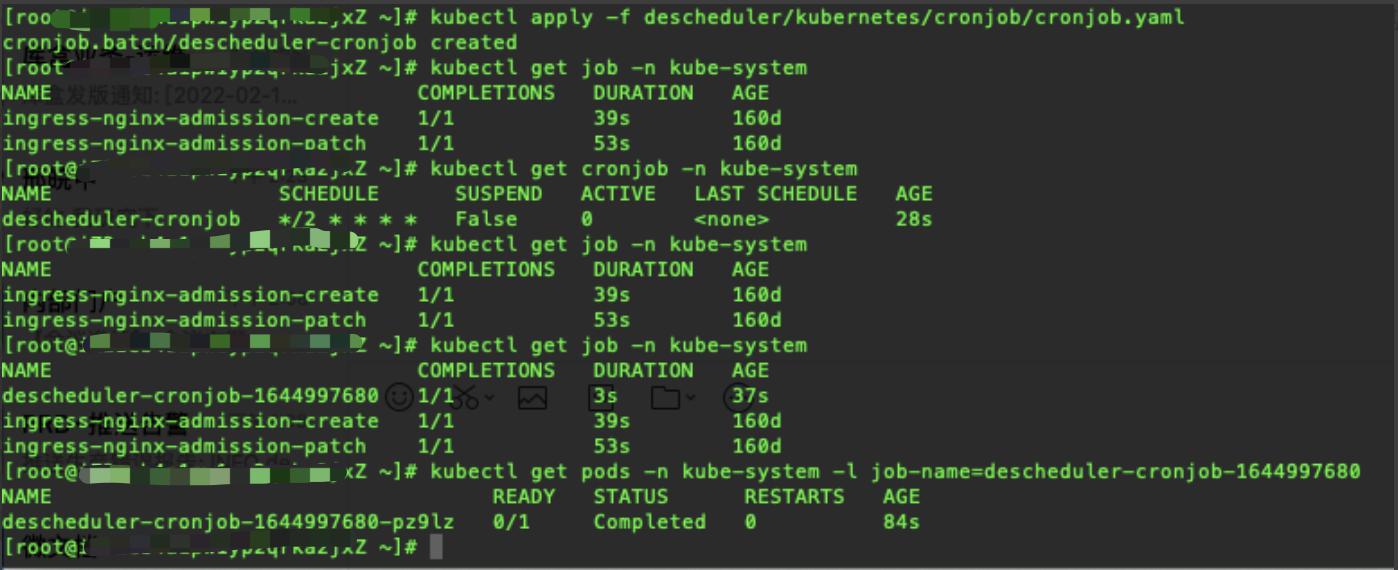
2. 通过kubectl apply -f descheduler/kubernetes/cronjob/cronjob.yaml 开启descheduler的cronjob (cronjob 根据cron表达式指定的周期定期执行job,具体针对k8s来说,cronjob controller会定期创建对应的job pod)
此时的descheduler的配置为:
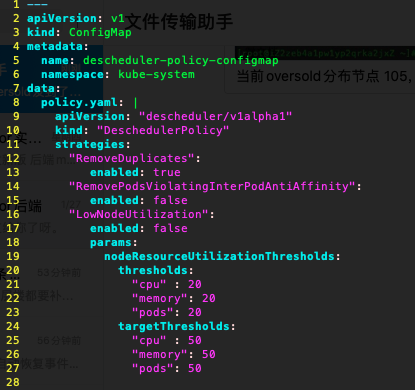
仅开启了RemoveDuplicates策略
3. 一段时间后再次通过kubectl get pods -n cloudadvisor-qa -o wide 查看pod,显示结果如下,发现原有pod已被驱逐并在105节点上重建

4. 通过 kubectl get jobs -n kube-system 找到当前cronjob创建的descheduler job, 然后再通过kubectl get pods -n kube-system -l job-name='jobname' 查看当前job所在的pod 注意-l 根据label选择的使用

5. 查看这个pod对应的日志,并搜索与我们要观察的oversold相关的部分(这里为了后续查看,已经导出为文件了)

这里可以看到descheduler先是发现了 duplicate的node节点,然后进行Adjusting feasible调整,并且可以看到驱逐的节点hkcl8正是刚刚我们在108创建的重复pod之一

 浙公网安备 33010602011771号
浙公网安备 33010602011771号