爬取数据
-
更多 -> 扩展程序 -> 管理扩展程序 -> 开发者模式 -> 加载已解压的扩展程序
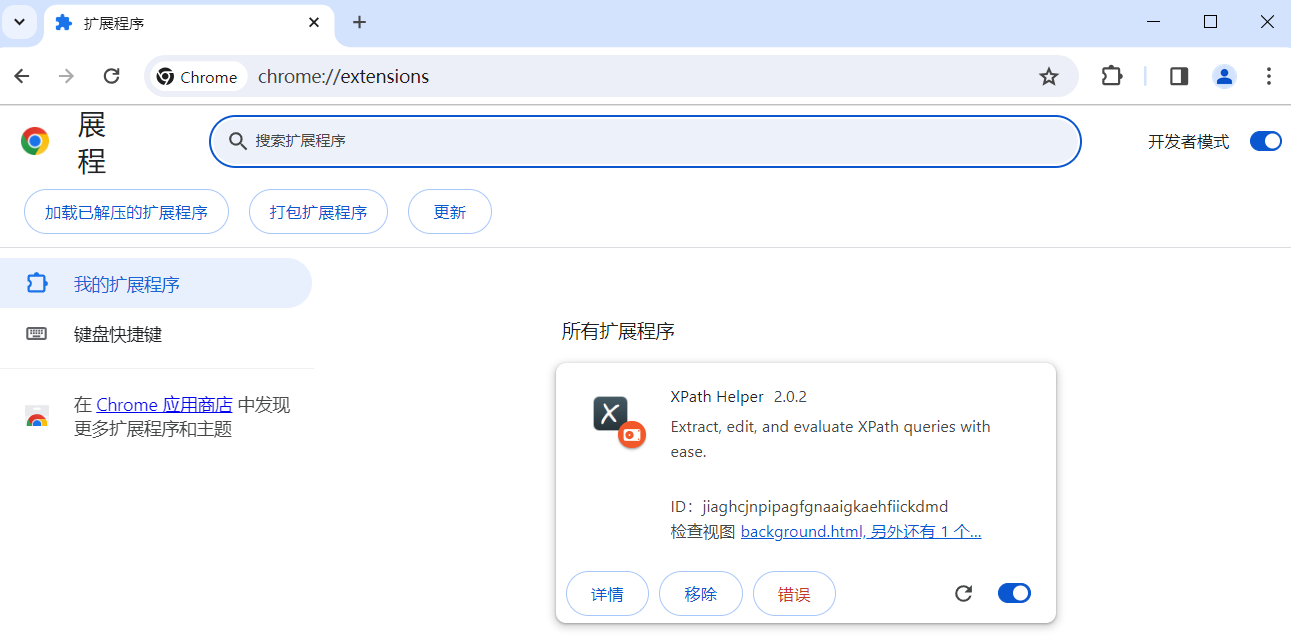
-
谷歌浏览器任意打开1个网页,F12打开开发者工具,右键右侧a标签区域 -> copy -> copy xpath
-
复制到左上角黑框
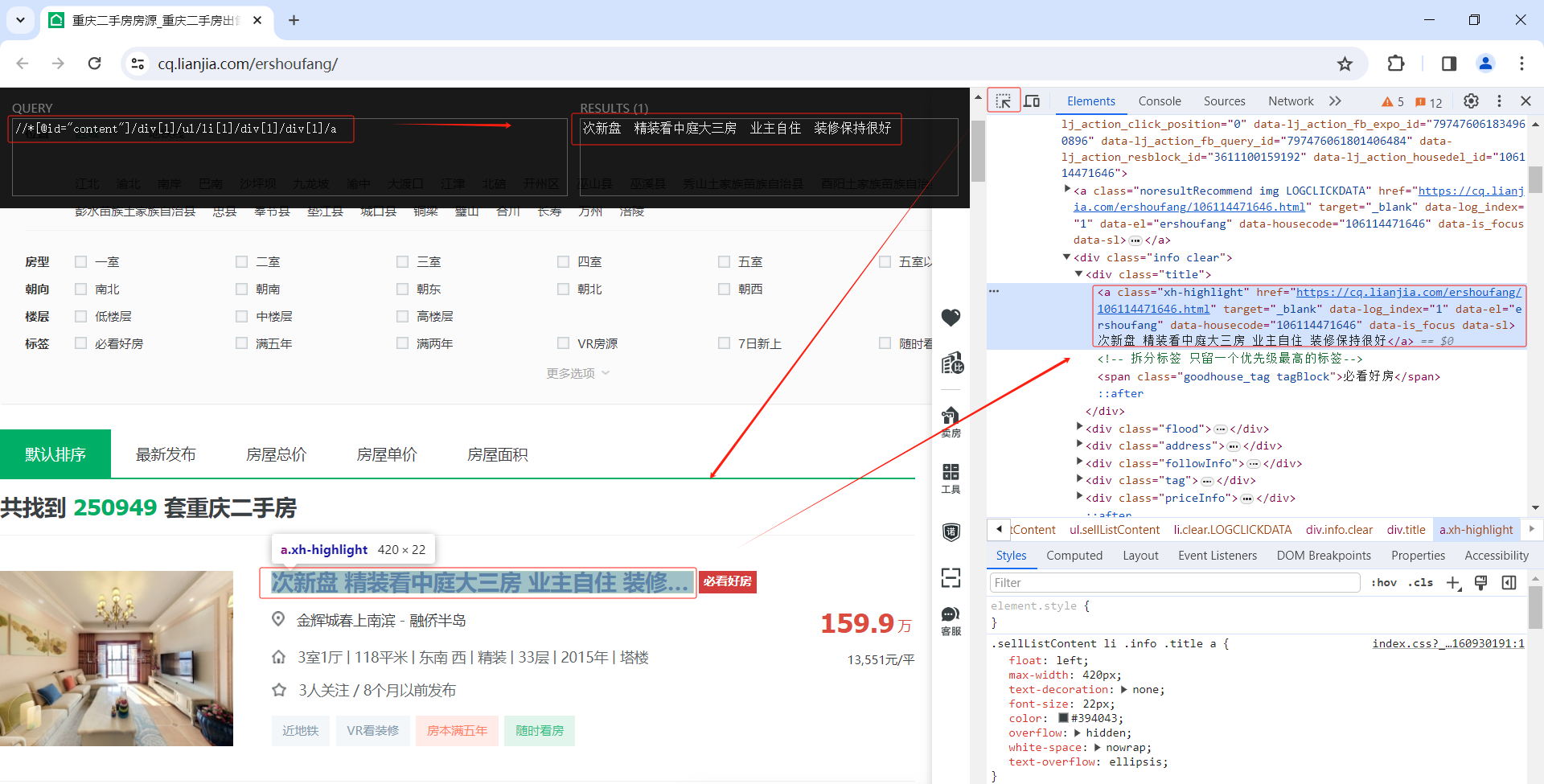
-
案例1
import pprint
import re
import requests
import parsel
import csv
import time
import traceback
import sys
from lxml import etree
from utils import fake_useragent
import random
class LianJia:
# 构造方法
def __init__(self):
self.headers = {
# "User-Agent": fake_useragent.get_ua()
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
self.f = open("lianjia.csv", mode="w", encoding="utf-8", newline="")
self.fieldnames =["title",
"areaName",
"communityName",
"hu_xing",
"chao_xiang",
"lou_ceng",
"zhuang_xiu",
"dian_ti",
"mian_ji"
"total"
]
self.csv_writer = csv.DictWriter(self.f, fieldnames=self.fieldnames, delimiter='\t')
self.csv_writer.writeheader()
# 抓取数据
def getHtml(self):
for num in range(1, 30):
time.sleep(random.randint(1, 3))
url = f"https://cq.lianjia.com/ershoufang/pg{num}/"
response = requests.get(url=url, headers=self.headers)
# # 获取源代码
print( url)
html = etree.HTML(response.text)
houselist =self.parseHtml(html)
self.save_html(houselist)
def parseHtml(self, html):
href = html.xpath('//div[@class="title"]/a/@href')
print( href)
houselist = []
for link in href:
house = {}
response2 = requests.get(url=link, headers=self.headers)
# 详情页数据
# 二次请求
html2 = etree.HTML(response2.text)
try:
# 获取数据
house['title'] = html2.xpath('//div[@class="sellDetailHeader"]//h1/text()') # 标题
house['title'] = house['title'][0] if house['title'] else None
areaName = html2.xpath('//div[@class="areaName"]/span[2]/a[1]/text()') # 获取区域 (extract_first())
house['areaName'] = areaName[0]
communityName = html2.xpath('//div[@class="communityName"]/a[1]/text()') # 获取小区名称
house['communityName'] = communityName[0]
hu_xing = html2.xpath('//div[@class="base"]/div[@class="content"]/ul/li[1]/text()') # 获取户型
house['hu_xing'] = str(hu_xing[1]).strip() if hu_xing else None
chao_xiang = html2.xpath('//div[@class="base"]/div[@class="content"]/ul/li[7]/text()') # 获取朝向
house['chao_xiang'] = str(chao_xiang[1]).strip() if chao_xiang else None
lou_ceng = html2.xpath('//*[@id="introduction"]/div/div/div[1]/div[2]/ul/li[2]/text()') # 获取楼层
house['lou_ceng'] = str(lou_ceng[1]).strip() if lou_ceng else None
zhuang_xiu = html2.xpath('//*[@id="introduction"]/div/div/div[1]/div[2]/ul/li[9]/text()') # 获取装修情况
house['zhuang_xiu'] = str(zhuang_xiu[1]).strip() if zhuang_xiu else None
dian_ti = html2.xpath('//*[@id="introduction"]/div/div/div[1]/div[2]/ul/li[11]/text()') # 获取电梯情况
house['dian_ti'] = str(dian_ti[1]).strip() if dian_ti else None
mian_ji = html2.xpath('//*[@id="introduction"]/div/div/div[1]/div[2]/ul/li[3]/text()') # 获取面积
house['mian_ji'] = str(mian_ji[1]).strip() if mian_ji else None
total = html2.xpath('/html/body/div[5]/div[2]/div[3]/div/span[1]/text()') # 获取总价
house['total'] = total[0]
print(house)
houselist.append(house)
except Exception as err:
# 获取异常信息
exc_type, exc_value, exc_traceback = sys.exc_info()
# 打印异常所在行
print(f"异常发生在第 {exc_traceback.tb_lineno} 行")
# 打印异常详细信息
traceback.print_exception(exc_type, exc_value, exc_traceback)
# print(houselist)
# house['title'] = html.xpath('//*[@id="content"]/div[1]/ul/li[1]/div[1]/div[1]/a/text()') # 标题
return houselist
def save_html(self, houselist):
if len(houselist )==0:
return
print( len(houselist ))
for row in houselist:
print( row)
self.csv_writer.writerow(row)
def run(self):
self.getHtml()
if __name__ == '__main__':
spider = LianJia()
spider.run()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号