seaborn基本使用(一)
-
查看
-
案例1
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
data = pd.read_csv("./german_credit_data.csv")
# 数据预览及数据处理,德国信用数据集
# 查看数据维度
print(data.shape)
# 查看数据信息
print(data.info())
# 查看各列缺失值
print("查看各列缺失值", data.isna().sum())
# 查看重复值
print("查看重复值", data.duplicated().sum())
# 处理Saving accounts和Checking account中缺失值。
# 考虑到缺失值占比比较大,不建议直接删除,同样的,也不建议用众数填充,这样可能会改变数据情况,这里先用unknown填充。
data['Saving accounts'].fillna('unknown', inplace=True)
data['Checking account'].fillna('unknown', inplace=True)
print("填充后查看各列缺失值", data.isna().sum())
# 查看分类特征的唯一值
characteristic = ['Sex','Job','Housing','Saving accounts','Checking account','Purpose']
for i in characteristic:
print(f'{i}:')
print("查看分类特征的唯一值",data[i].unique())
print('-'*50)
# 数据探索
# 客户基本情况分析
# 设置绘图风格
sns.set(style="whitegrid")
# 2*2的表格,figsize窗口尺寸
fig, axs = plt.subplots(2, 2, figsize=(15,15))
# 年龄分布
# sns.distplot 是 seaborn 库中用于绘制直方图和拟合内核密度估计的函数。这个函数的目的是通过可视化展示数据的分布情况,同时也可以通过核密度估计(Kernel Density Estimation,简称 KDE)了解概率密度函数
# kde是否绘制高斯核密度估计图,bins直方图bins(柱)的数目
sns.distplot(data['Age'], kde=True, bins=30, ax=axs[0, 0])
axs[0, 0].set_title('Age Distribution')
axs[0, 0].set_xlabel('Age')
axs[0, 0].set_ylabel('Frequency')
# 性别分布 Set2 调色板 包含了8种颜色
sns.countplot(x='Sex', data=data, palette='Set2', ax=axs[0, 1])
axs[0, 1].set_title('Sex Distribution')
axs[0, 1].set_xlabel('Sex')
axs[0, 1].set_ylabel('Count')
# 职业技能分布
sns.countplot(x='Job', data=data, palette='Set3', ax=axs[1, 0])
axs[1, 0].set_title('Job Distribution')
axs[1, 0].set_xlabel('Job')
axs[1, 0].set_ylabel('Count')
# 住房类型分布
sns.countplot(x='Housing', data=data, palette='Set1', ax=axs[1, 1])
axs[1, 1].set_title('Housing Type Distribution')
axs[1, 1].set_xlabel('Housing Type')
axs[1, 1].set_ylabel('Count')
# 自动调整子图参数,使之填充整个图像区域
plt.tight_layout()
plt.show()
查看详情
- 控制台打印
(1000, 10)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Id 1000 non-null int64
1 Age 1000 non-null int64
2 Sex 1000 non-null object
3 Job 1000 non-null int64
4 Housing 1000 non-null object
5 Saving accounts 817 non-null object
6 Checking account 606 non-null object
7 Credit amount 1000 non-null int64
8 Duration 1000 non-null int64
9 Purpose 1000 non-null object
dtypes: int64(5), object(5)
memory usage: 78.2+ KB
None
查看各列缺失值 Id 0
Age 0
Sex 0
Job 0
Housing 0
Saving accounts 183
Checking account 394
Credit amount 0
Duration 0
Purpose 0
dtype: int64
查看重复值 0
填充后查看各列缺失值 Id 0
Age 0
Sex 0
Job 0
Housing 0
Saving accounts 0
Checking account 0
Credit amount 0
Duration 0
Purpose 0
dtype: int64
Sex:
查看分类特征的唯一值 ['male' 'female']
--------------------------------------------------
Job:
查看分类特征的唯一值 [2 1 3 0]
--------------------------------------------------
Housing:
查看分类特征的唯一值 ['own' 'free' 'rent']
--------------------------------------------------
Saving accounts:
查看分类特征的唯一值 ['unknown' 'little' 'quite rich' 'rich' 'moderate']
--------------------------------------------------
Checking account:
查看分类特征的唯一值 ['little' 'moderate' 'unknown' 'rich']
--------------------------------------------------
Purpose:
查看分类特征的唯一值 ['radio/TV' 'education' 'furniture/equipment' 'car' 'business'
'domestic appliances' 'repairs' 'vacation/others']
--------------------------------------------------
-
输出
-
结论
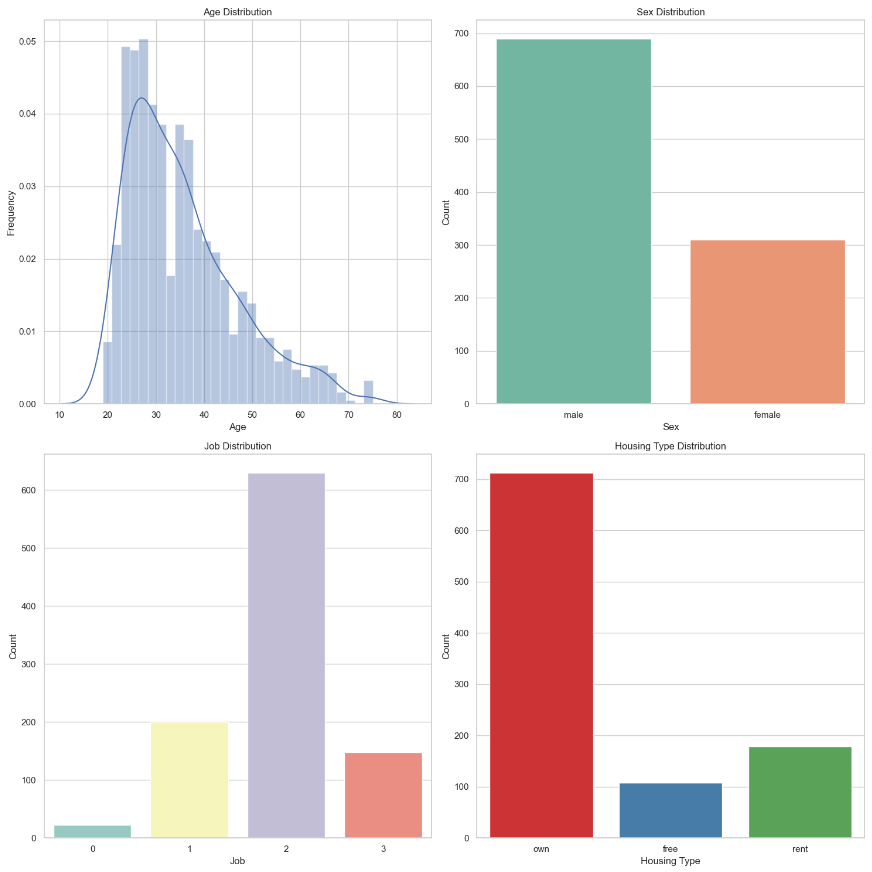
1.客户年龄主要集中在较年轻的年龄段,可能表明年轻人更倾向于申请贷款。
2.男性客户数量高于女性客户数量。
3.工作位于2级的客户数量最多,0级的客户数量最少,可能是因为0级无技能且非常驻,银行不予贷款。
4.自有房产客户数量>租房客户数量>免租赁客户数量,这里免租赁客户指的是那些居住在无需支付租金的住所的人,比如住在政府提供的免费住宿或者亲戚朋友家里。
- 案例2
# 客户经济情况分析
order_savings = ['unknown', 'little', 'moderate', 'quite rich', 'rich']
order_checking = ['unknown', 'little', 'moderate', 'rich']
fig, axs = plt.subplots(1, 2, figsize=(15,8))
# 储蓄账户状况分布
# order排序
sns.countplot(x='Saving accounts', data=data, order=order_savings, palette='Set2', ax=axs[0])
axs[0].set_title('Saving Accounts Distribution')
axs[0].set_xlabel('Saving Accounts')
axs[0].set_ylabel('Count')
# 支票账户分布
sns.countplot(x='Checking account', data=data, order=order_checking, palette='Set3', ax=axs[1])
axs[1].set_title('Checking Account Distribution')
axs[1].set_xlabel('Checking Account')
axs[1].set_ylabel('Count')
plt.tight_layout()
plt.show()
查看详情
-
输出
-
结论
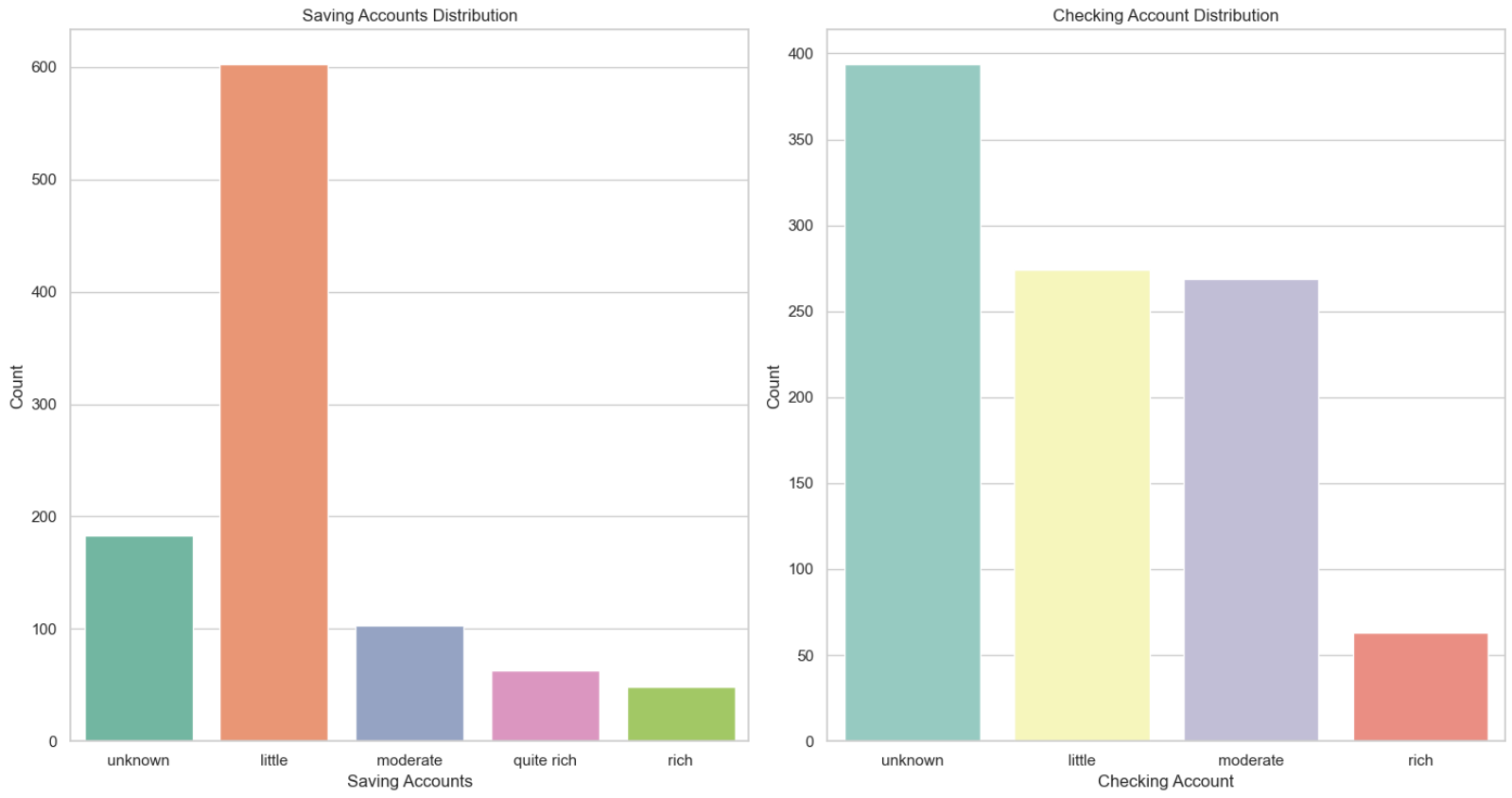
1.越有钱的客户越不容易选择贷款。
2.储蓄账户状况为少量的客户,贷款人数最多。
3.支票账户状况为未知、少量、中等贷款人数比较多,尤其是未知的客户是最多的,表明放款的时候,支票账户可能不是一个主要的考虑因素,才会导致未知数据占多数。
- 案例3
# 客户贷款情况分析
fig = plt.figure(figsize=(20,15))
# 创建2x2的图布局
ax1 = fig.add_subplot(2, 2, 1)
ax2 = fig.add_subplot(2, 2, 2)
ax3 = fig.add_subplot(2, 1, 2)
# 贷款金额分布 1.客户贷款主要倾向于申请中低额度的贷款
sns.distplot(data['Credit amount'], kde=True, bins=30, ax=ax1)
ax1.set_title('Credit Amount Distribution')
ax1.set_xlabel('Credit Amount')
ax1.set_ylabel('Frequency')
# 贷款期限分布
sns.distplot(data['Duration'], kde=True, bins=20, color='green', ax=ax2)
ax2.set_title('Duration Distribution')
ax2.set_xlabel('Duration (Months)')
ax2.set_ylabel('Frequency')
# 贷款用途分布
sns.countplot(y='Purpose', data=data, palette='muted', ax=ax3)
ax3.set_title('Purpose of Credit')
ax3.set_xlabel('Count')
ax3.set_ylabel('Purpose')
plt.show()
查看详情
-
输出
-
结论
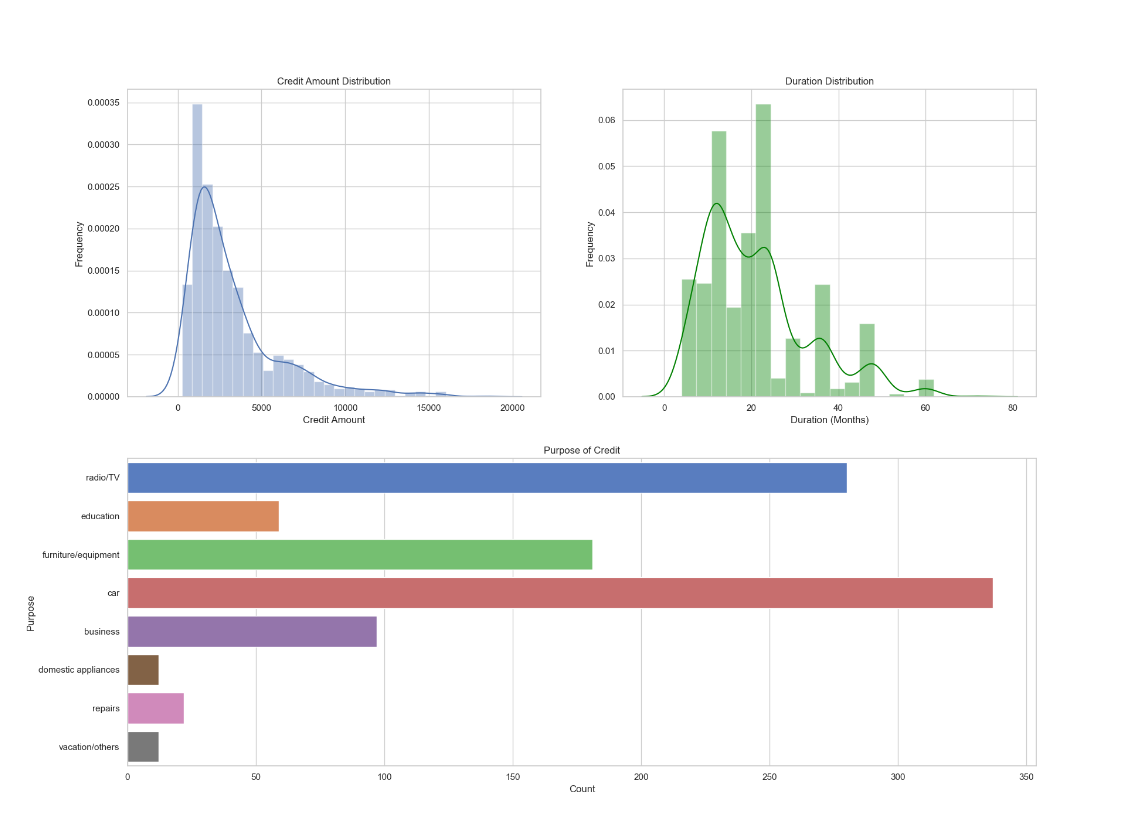
1.客户贷款主要倾向于申请中低额度的贷款,贷款期限也主要选择中短期。
2.客户贷款用途主要用于购买车、收音机/电视、家具/设备。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号