spark基本使用
-
在pycharm中右键文件,将数据源文件如csv、json文件上传到服务器
-
上传excel文件,读取数据,生成折线图
from pyspark.sql import SparkSession
import pandas as pd
import matplotlib.pyplot as plt
# 创建 SparkSession
spark = SparkSession.builder. \
config("spark.driver.host", "localhost"). \
appName("test"). \
getOrCreate()
# 服务器上的Excel文件路径
excel_file_path = "./附件1.xlsx"
# 使用 Pandas 读取 Excel 数据
excel_data_df = pd.read_excel(excel_file_path)
# 将 Pandas DataFrame 转换为 Spark DataFrame
spark_data_df = spark.createDataFrame(excel_data_df)
spark_data_df.createOrReplaceTempView("biaoming")
# 聚合函数 agg count sum min max
df2=spark.sql("select category_name, count(category_name) as cnt from biaoming group by category_name")
df2.show()
df2.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://192.168.128.78:3306/test?useSSL=false&useUnicode=true"). \
option("dbtable", "vegtable"). \
option("user", "root"). \
option("password", "123456"). \
save()
# 提取日期和销量数据列
sales_dates = spark_data_df.select("code").rdd.flatMap(lambda x: x).collect()
sales_quantities = spark_data_df.select("code").rdd.flatMap(lambda x: x).collect()
plt.rcParams['font.family'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
# 使用 Matplotlib 绘制折线图
plt.figure(figsize=(12, 6))
plt.plot(sales_dates, sales_quantities, marker='o', linestyle='-', color='b')
plt.title("单品编码随分类编码的变化")
plt.xlabel("单品编码")
plt.ylabel("分类编码")
plt.xticks(rotation=45)
plt.grid(True)
plt.tight_layout()
plt.savefig("my_plot.png")
plt.show()
查看详情
- 控制台
+-------------+---+
|category_name|cnt|
+-------------+---+
| 花叶类|100|
| 水生根茎类| 19|
| 辣椒类| 45|
| 食用菌| 72|
| 茄类| 10|
| 花菜类| 5|
+-------------+---+
- 将json文件上传到服务器,读取json文件
from pyspark.sql import SparkSession
if __name__ == '__main__':
# 0. 构建执行环境入口对象SparkSession
spark = SparkSession.builder. \
config("spark.driver.host", "localhost"). \
appName("test"). \
getOrCreate()
sc = spark.sparkContext
# JSON类型自带有Schema信息
df = spark.read.format("json").load("./people.json")
df.printSchema()
df.show()
查看详情
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
- 将csv文件上传到服务,读取csv文件
from pyspark.sql import SparkSession
if __name__ == '__main__':
# 0. 构建执行环境入口对象SparkSession
spark = SparkSession.builder. \
config("spark.driver.host", "localhost"). \
appName("test"). \
getOrCreate()
sc = spark.sparkContext
# JSON类型自带有Schema信息
df = spark.read.format("csv").\
option("sep", ";").\
option("header", True).\
option("encoding", "utf-8").\
schema("name STRING, age INT, job STRING").\
load("./people.csv")
df.printSchema()
df.show()
查看详情
root
|-- name: string (nullable = true)
|-- age: integer (nullable = true)
|-- job: string (nullable = true)
+-----+----+---------+
| name| age| job|
+-----+----+---------+
|Jorge| 30|Developer|
| Bob| 32|Developer|
| Ani| 11|Developer|
| Lily| 11| Manager|
| Put| 11|Developer|
|Alice| 9| Manager|
|Alice| 9| Manager|
|Alice| 9| Manager|
|Alice| 9| Manager|
|Alice|null| Manager|
|Alice| 9| null|
+-----+----+---------+
- 缺失值处理
import pandas as pd
# 读取excel的时候,忽略前几个空行, skiprows=2
# 第三行才是数据
studf = pd.read_excel("./student_excel.xlsx" ,skiprows=3)
# 删除掉全是空值的列
print(studf.loc[ studf["分数"].notnull(), :])
studf.dropna(axis=1, how='all', inplace=True)
print( studf )
# 删除掉全是空值的行
# 删除第一列的空置
# studf.dropna(axis="index", how='all', inplace=True)
studf.dropna(axis=0, how='all', inplace=True)
print( studf )
# 将分数列为空的填充为0分
# studf.loc[:, '分数'] = studf.fillna({"分数":0})
# 等同于
studf.loc[:, '分数'] = studf['分数'].fillna(0)
print( studf )
# 将姓名的缺失值填充,用前一个值来填充
# 使用前面的有效值填充,用ffill
studf.loc[:, '姓名'] = studf['姓名'].fillna(method="ffill")
print( studf )
查看详情
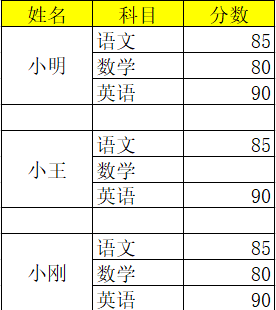
Unnamed: 0 Unnamed: 1 姓名 科目 分数
0 NaN NaN 小明 语文 85.0
1 NaN NaN NaN 数学 80.0
2 NaN NaN NaN 英语 90.0
4 NaN NaN 小王 语文 85.0
6 NaN NaN NaN 英语 90.0
8 NaN NaN 小刚 语文 85.0
9 NaN NaN NaN 数学 80.0
10 NaN NaN NaN 英语 90.0
姓名 科目 分数
0 小明 语文 85.0
1 NaN 数学 80.0
2 NaN 英语 90.0
3 NaN NaN NaN
4 小王 语文 85.0
5 NaN 数学 NaN
6 NaN 英语 90.0
7 NaN NaN NaN
8 小刚 语文 85.0
9 NaN 数学 80.0
10 NaN 英语 90.0
姓名 科目 分数
0 小明 语文 85.0
1 NaN 数学 80.0
2 NaN 英语 90.0
4 小王 语文 85.0
5 NaN 数学 NaN
6 NaN 英语 90.0
8 小刚 语文 85.0
9 NaN 数学 80.0
10 NaN 英语 90.0
姓名 科目 分数
0 小明 语文 85.0
1 NaN 数学 80.0
2 NaN 英语 90.0
4 小王 语文 85.0
5 NaN 数学 0.0
6 NaN 英语 90.0
8 小刚 语文 85.0
9 NaN 数学 80.0
10 NaN 英语 90.0
姓名 科目 分数
0 小明 语文 85.0
1 小明 数学 80.0
2 小明 英语 90.0
4 小王 语文 85.0
5 小王 数学 0.0
6 小王 英语 90.0
8 小刚 语文 85.0
9 小刚 数学 80.0
10 小刚 英语 90.0
- 案例,将u.data上传到服务器,读取并分析
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
from pyspark.sql import functions as F
if __name__ == '__main__':
# 0. 构建执行环境入口对象SparkSession
spark = SparkSession.builder. \
config("spark.driver.host", "localhost"). \
appName("test").\
master("local[*]").\
config("spark.sql.shuffle.partitions", 2).\
getOrCreate()
sc = spark.sparkContext
# 1. 读取数据集
# 数字不进行 加减乘除 当作文本来处理
schema = StructType().\
add("user_id", StringType(), nullable=True).\
add("movie_id", IntegerType(), nullable=True).\
add("rank", IntegerType(), nullable=True).\
add("ts", StringType(), nullable=True)
df = spark.read.format("csv").\
option("sep", "\t").\
option("header", False).\
option("encoding", "utf-8").\
schema(schema=schema).\
load("./u.data")
df.createOrReplaceTempView("student")
# TODO 1: 每个用户平均分
spark.sql(" select user_id , round( avg(rank) ,2) as avg_rank from student group by"
" user_id order by avg_rank desc ").show()
# withColumn 对单列进行处理
df.groupBy("user_id").\
avg("rank").\
withColumnRenamed("avg(rank)", "avg_rank").\
withColumn("avg_rank", F.round("avg_rank", 2)).\
orderBy("avg_rank", ascending=False).\
show()
# TODO 2: 电影的平均分查询
df.createTempView("movie")
spark.sql("""
SELECT movie_id, ROUND(AVG(rank), 2) AS avg_rank FROM movie GROUP BY movie_id ORDER BY avg_rank DESC
""").show()
# TODO 3: 查询大于平均分 的电影的数量 # Row
df.select( F.avg(df['rank']) ) .show()
print( "平均分的值:",df.select(F.avg(df['rank'])) .first()['avg(rank)'])
print("大于平均分电影的数量: ", df.where( df['rank'] > df.select(F.avg( df['rank'] )) .first()['avg(rank)'] ).count())
# TODO 4: 查询高分电影中(>3)打分次数最多的用户, 此人打分的平均分
# 先找出这个人的id 找到评分最多的人。。。
# 求这个人打分的平均分
user_id = df.where("rank > 3").\
groupBy("user_id").\
count().\
withColumnRenamed("count", "cnt").\
orderBy("cnt", ascending=False).\
limit(1).\
first()['user_id']
# 计算这个人的打分平均分
df.filter(df['user_id'] == user_id).\
select(F.round(F.avg("rank"), 2)).show()
# select 里面传入一个列对象
# TODO 5: 查询每个用户的平均打分, 最低打分, 最高打分
# agg 函数 可以在里面写多个聚合
df.groupBy("user_id").\
agg(
F.round(F.avg("rank"), 2).alias("avg_rank"),
F.min("rank").alias("min_rank"),
F.max("rank").alias("max_rank")
).show()
# TODO 6: 查询评分超过100次的电影, 的平均分 结果 排名 TOP 10 评分超过100次的 评分排名前10的电影
df.groupBy("movie_id").\
agg(
F.count("rank").alias("cnt"),
F.round(F.avg("rank"), 2).alias("avg_rank")
).where("cnt > 100").\
orderBy("avg_rank", ascending=False).\
limit(10).\
show()
查看详情
+-------+--------+
|user_id|avg_rank|
+-------+--------+
| 849| 4.87|
| 688| 4.83|
| 507| 4.72|
| 628| 4.7|
| 928| 4.69|
| 118| 4.66|
| 907| 4.57|
| 686| 4.56|
| 427| 4.55|
| 565| 4.54|
| 469| 4.53|
| 850| 4.53|
| 225| 4.52|
| 330| 4.5|
| 477| 4.46|
| 242| 4.45|
| 636| 4.45|
| 583| 4.44|
| 252| 4.43|
| 767| 4.43|
+-------+--------+
only showing top 20 rows
+-------+--------+
|user_id|avg_rank|
+-------+--------+
| 849| 4.87|
| 688| 4.83|
| 507| 4.72|
| 628| 4.7|
| 928| 4.69|
| 118| 4.66|
| 907| 4.57|
| 686| 4.56|
| 427| 4.55|
| 565| 4.54|
| 469| 4.53|
| 850| 4.53|
| 225| 4.52|
| 330| 4.5|
| 477| 4.46|
| 242| 4.45|
| 636| 4.45|
| 583| 4.44|
| 252| 4.43|
| 767| 4.43|
+-------+--------+
only showing top 20 rows
+--------+--------+
|movie_id|avg_rank|
+--------+--------+
| 1500| 5.0|
| 1201| 5.0|
| 1189| 5.0|
| 1536| 5.0|
| 1293| 5.0|
| 1653| 5.0|
| 1599| 5.0|
| 1467| 5.0|
| 1122| 5.0|
| 814| 5.0|
| 1449| 4.63|
| 119| 4.5|
| 1398| 4.5|
| 1594| 4.5|
| 1642| 4.5|
| 408| 4.49|
| 318| 4.47|
| 169| 4.47|
| 483| 4.46|
| 64| 4.45|
+--------+--------+
only showing top 20 rows
+---------+
|avg(rank)|
+---------+
| 3.52986|
+---------+
平均分的值: 3.52986
大于平均分电影的数量: 55375
+-------------------+
|round(avg(rank), 2)|
+-------------------+
| 3.86|
+-------------------+
+-------+--------+--------+--------+
|user_id|avg_rank|min_rank|max_rank|
+-------+--------+--------+--------+
| 186| 3.41| 1| 5|
| 244| 3.65| 1| 5|
| 200| 4.03| 2| 5|
| 210| 4.06| 2| 5|
| 303| 3.37| 1| 5|
| 122| 3.98| 1| 5|
| 194| 2.96| 1| 5|
| 291| 3.69| 1| 5|
| 119| 3.95| 1| 5|
| 167| 3.38| 1| 5|
| 299| 3.46| 1| 5|
| 102| 2.62| 1| 4|
| 160| 3.92| 1| 5|
| 225| 4.52| 2| 5|
| 290| 3.35| 1| 5|
| 97| 4.16| 1| 5|
| 157| 3.78| 1| 5|
| 201| 3.03| 1| 5|
| 287| 4.11| 1| 5|
| 246| 2.93| 1| 5|
+-------+--------+--------+--------+
only showing top 20 rows
+--------+---+--------+
|movie_id|cnt|avg_rank|
+--------+---+--------+
| 408|112| 4.49|
| 169|118| 4.47|
| 318|298| 4.47|
| 483|243| 4.46|
| 64|283| 4.45|
| 603|209| 4.39|
| 12|267| 4.39|
| 50|583| 4.36|
| 178|125| 4.34|
| 427|219| 4.29|
+--------+---+--------+

 浙公网安备 33010602011771号
浙公网安备 33010602011771号