import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 设置字体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 能正确显示负号
plt.rcParams['axes.unicode_minus'] = False
# 设置画布大小
plt.figure(figsize=(11, 8))
path = r"C:\work\python\matplotlib_files\16.散点图.xlsx"
data = pd.read_excel(path)
print(data)
## 基本的散点图
plt.scatter(data.体重, data.身高)
plt.show()
# x轴,y轴,点的大小,点的颜色
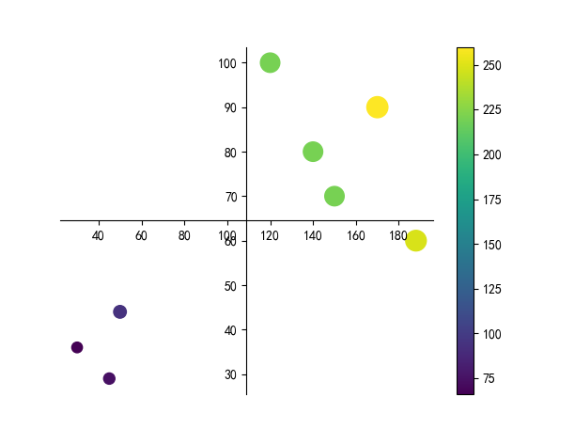
plt.scatter(data.身高, data.体重, s=data.身高, c=data.身高)
plt.colorbar()
plt.show()
#
plt.scatter(data.身高, data.体重, s=data.身高+data.体重, c=data.身高+data.体重)
plt.colorbar()
plt.show()
# 得到图形坐标轴
ax = plt.subplot()
# spines['top'] top,right,bottom,left
ax.spines['bottom'].set_position('center')
ax.spines['left'].set_position('center')
# 设置坐标轴的颜色
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
# 将数据放到坐标轴
plt.scatter(data.身高, data.体重, s=data.身高+data.体重, c=data.身高+data.体重)
plt.colorbar()
plt.show()
查看详情
path = r"C:\work\python\matplotlib_files\17.直方图.xlsx"
data = pd.read_excel(path)
print(data)
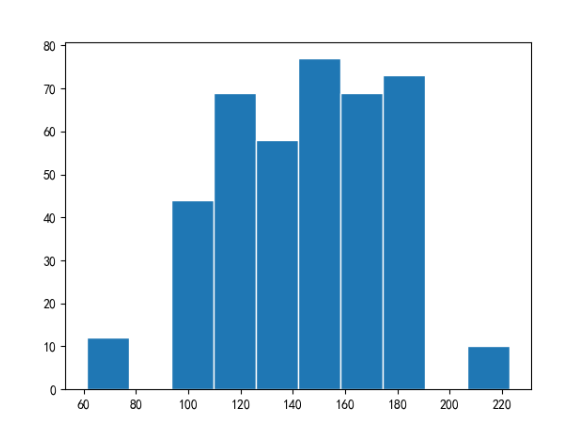
# bins 分组的数量
plt.hist(data.身高, bins=10, edgecolor='w')
plt.show()
查看详情
# 极点:圆的中心
# 极轴:圆心到 0度方向的一条射线
# 极径:一个长度单位,类似于半径 r
# 极角:从0度开始到极径的角度,通过np.pi来计算的
# 0.25*np.pi 等于45度
# 0.5*np.pi 等于90度
# np.pi 等于180度
# 2*np.pi 等于360度
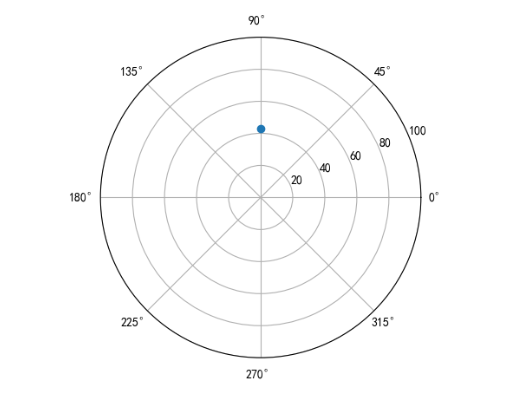
# 创建极坐标的一个点
plt.polar(0.5*np.pi, 43, 'o')
plt.ylim(0, 100)
plt.show()
# 创建多个点
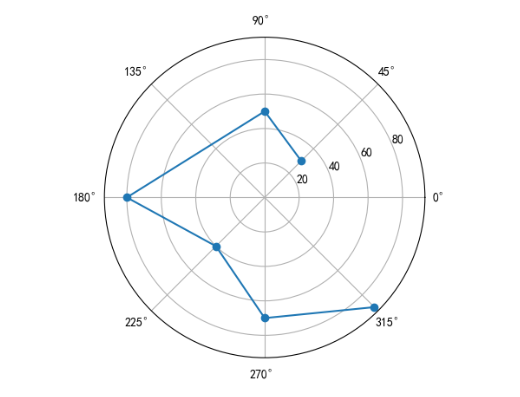
# 创建角度的数组
jd = np.array([0.25, 0.5, 1, 1.25, 1.5, 1.75]) * np.pi
# 创建对应的极径
jj = [30, 50, 80, 40, 70, 90]
# 绘制雷达图,'o'实心圆点,'o-'将实心圆点用线条连接起来
plt.polar(jd, jj, 'o-')
plt.show()
# 创建多个点,并首位相连
# 创建角度的数组
jd = np.array([0.25, 0.5, 1, 1.25, 1.5, 1.75]) * np.pi
# 创建对应的极径
jj = [30, 50, 80, 40, 70, 90]
# 将角度和极径列表的第一个元素添加到自己的末尾
jd = np.append(jd, jd[0]) # numpy数组的拼接方式
jj.append(jj[0]) # 列表的添加元素
# 绘制雷达图,'o'实心圆点,'o-'将实心圆点用线条连接起来
plt.polar(jd, jj, 'o-')
plt.show()
查看详情
path = r"C:\work\python\matplotlib_files\22.雷达图.xlsx"
data = pd.read_excel(path)
print(data)
# 雷达图的样式
plt.style.use('ggplot')
# 单独取出A01和A02的分数
A01 = data[data.姓名 == 'A01']['分数']
# reset_index(drop=True) 重置索引,并删除以前的索引
A02 = data[data.姓名 == 'A02']['分数'].reset_index(drop=True)
# 科目分离出来,做标签
km = data[data.姓名 == 'A01']['科目']
# 角度的拆分
# jd = 2*np.pi/len(A01)
# jds = []
# for i in range(len(A01)):
# jds.append(jd*i)
# 用一个函数来完成上面的角度的拆分
# np.linspace(起始角度,结束角度,分割的个数) endpoint=False 样本不包含最后一个值
jds = np.linspace(0, 2*np.pi, len(A01), endpoint=False)
# 将列表中的第一个元素添加到列表的末尾
A01 = np.append(A01, A01[0])
A02 = np.append(A02, A02[0])
jds = np.append(jds, jds[0])
km = np.append(km, km[0])
# 极角,极径,连接,
plt.polar(jds, A01, '-', label='A01')
plt.polar(jds, A02, '-', label='A02')
# 放置图例到合适的位置
plt.legend()
# 填充:极角,极径,透明度
plt.fill(jds, A01, alpha=0.3)
plt.fill(jds, A02, alpha=0.3)
# 设置科目标签
plt.subplot().set_thetagrids(jds*180/np.pi, km)
plt.show()
查看详情


 浙公网安备 33010602011771号
浙公网安备 33010602011771号