字典
- 定义
同样使用{},不过存储的元素是一个个的:键值对
- 语法
使用{}存储原始,每一个元素是一个键值对
每一个键值对包含Key和Value(用冒号分隔)
键值对之间使用逗号分隔
Key和Value可以是任意类型的数据(key不可为字典)
Key不可重复,重复会对原有数据覆盖

- 注意事项
键值对的Key和Value可以是任意类型(Key不可为字典)
字典内Key不允许重复,重复添加等同于覆盖原有数据
字典不可用下标索引,而是通过Key检索Value
- 案例1
# 定义字典
my_dict1 = {"王力鸿": 99, "周杰轮": 88, "林俊节": 77}
# 定义空字典
my_dict2 = {}
my_dict3 = dict()
print(f"字典1的内容是:{my_dict1}, 类型:{type(my_dict1)}")
print(f"字典2的内容是:{my_dict2}, 类型:{type(my_dict2)}")
print(f"字典3的内容是:{my_dict3}, 类型:{type(my_dict3)}")
# 定义重复Key的字典
my_dict1 = {"王力鸿": 99, "王力鸿": 88, "林俊节": 77}
print(f"重复key的字典的内容是:{my_dict1}")
# 从字典中基于Key获取Value
my_dict1 = {"王力鸿": 99, "周杰轮": 88, "林俊节": 77}
score = my_dict1["王力鸿"]
print(f"王力鸿的考试分数是:{score}")
score = my_dict1["周杰轮"]
print(f"周杰轮的考试分数是:{score}")
# 定义嵌套字典
stu_score_dict = {
"王力鸿": {
"语文": 77,
"数学": 66,
"英语": 33
}, "周杰轮": {
"语文": 88,
"数学": 86,
"英语": 55
}, "林俊节": {
"语文": 99,
"数学": 96,
"英语": 66
}
}
print(f"学生的考试信息是:{stu_score_dict}")
# 从嵌套字典中获取数据
# 看一下周杰轮的语文信息
score = stu_score_dict["周杰轮"]["语文"]
print(f"周杰轮的语文分数是:{score}")
score = stu_score_dict["林俊节"]["英语"]
print(f"林俊节的英语分数是:{score}")
-
常用操作
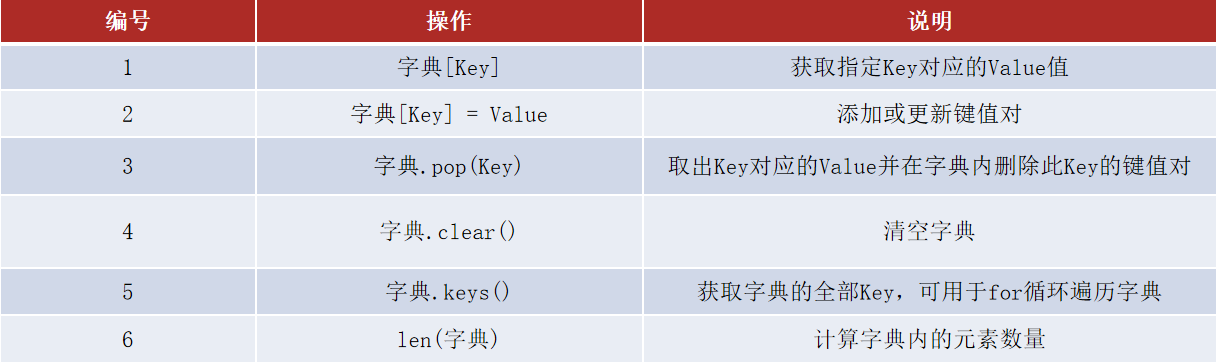
-
案例2
my_dict = {"周杰轮": 99, "林俊节": 88, "张学油": 77}
# 新增元素
my_dict["张信哲"] = 66
print(f"字典经过新增元素后,结果:{my_dict}")
# 更新元素
my_dict["周杰轮"] = 33
print(f"字典经过更新后,结果:{my_dict}")
# 删除元素
score = my_dict.pop("周杰轮")
print(f"字典中被移除了一个元素,结果:{my_dict}, 周杰轮的考试分数是:{score}")
# 清空元素, clear
my_dict.clear()
print(f"字典被清空了,内容是:{my_dict}")
# 获取全部的key
my_dict = {"周杰轮": 99, "林俊节": 88, "张学油": 77}
keys = my_dict.keys()
print(f"字典的全部keys是:{keys}")
# 遍历字典
# 方式1:通过获取到全部的key来完成遍历
for key in keys:
print(f"字典的key是:{key}")
print(f"字典的value是:{my_dict[key]}")
# 方式2:直接对字典进行for循环,每一次循环都是直接得到key
for key in my_dict:
print(f"2字典的key是:{key}")
print(f"2字典的value是:{my_dict[key]}")
# 统计字典内的元素数量, len()函数
num = len(my_dict)
print(f"字典中的元素数量有:{num}个")
- 特点
可以容纳多个数据
可以容纳不同类型的数据
每一份数据是KeyValue键值对
可以通过Key获取到Value,Key不可重复(重复会覆盖)
不支持下标索引
可以修改(增加或删除更新元素等)
支持for循环,不支持while循环
- 案例3
# 组织字典记录数据
info_dict = {
"王力鸿": {
"部门": "科技部",
"工资": 3000,
"级别": 1
},
"周杰轮": {
"部门": "市场部",
"工资": 5000,
"级别": 2
},
"林俊节": {
"部门": "市场部",
"工资": 7000,
"级别": 3
},
"张学油": {
"部门": "科技部",
"工资": 4000,
"级别": 1
},
"刘德滑": {
"部门": "市场部",
"工资": 6000,
"级别": 2
}
}
print(f"员工在升值加薪之前的结果:{info_dict}")
# for循环遍历字典
for name in info_dict:
# if条件判断符合条件员工
if info_dict[name]["级别"] == 1:
# 升职加薪操作
# 获取到员工的信息字典
employee_info_dict = info_dict[name]
# 修改员工的信息
employee_info_dict["级别"] = 2 # 级别+1
employee_info_dict["工资"] += 1000 # 工资+1000
# 将员工的信息更新回info_dict
info_dict[name] = employee_info_dict
# 输出结果
print(f"对员工进行升级加薪后的结果是:{info_dict}")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号