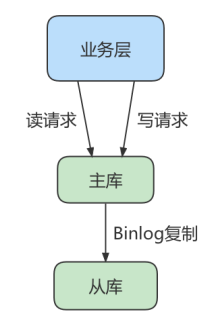
读库和写库的数据一致(最终一致);
写数据必须写到写库;
读数据必须到读库(不一定);
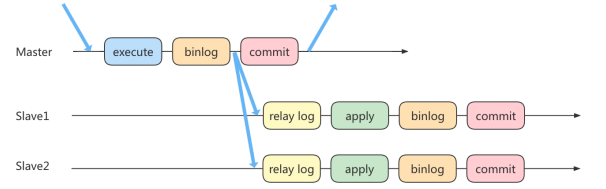
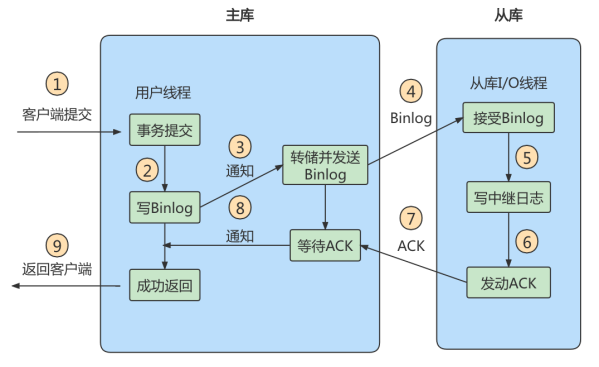
进行主从同步的内容是二进制日志,它是一个文件,在进行 网络传输 的过程中就一定会 存在主从延迟(比如 500ms),这样就可能造成用户在从库上读取的数据不是最新的数据,
也就是主从同步中的数据不一致性问题
1、从库的机器性能比主库要差
2、从库的压力大
3、大事务的执行
1. 降低多线程大事务并发的概率,优化业务逻辑
2. 优化SQL,避免慢SQL, 减少批量操作 ,建议写脚本以update-sleep这样的形式完成。
3. 提高从库机器的配置 ,减少主库写binlog和从库读binlog的效率差。
4. 尽量采用 短的链路 ,也就是主库和从库服务器的距离尽量要短,提升端口带宽,减少binlog传输的网络延时
5. 实时性要求的业务读强制走主库,从库只做灾备,备份。
如果操作的数据存储在同一个数据库中,那么对数据进行更新的时候,可以对记录加写锁,这样在读取的时候就不会发生数据不一致的情况。但这时从库的作用就是备份,
并没有起到读写分离 ,分担主库读压力的作用
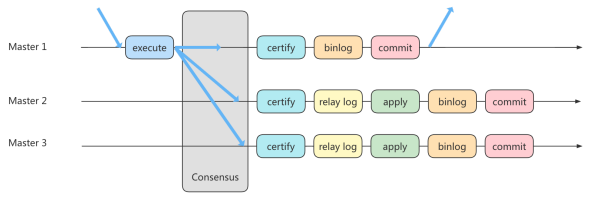
异步复制和半同步复制都无法最终保证数据的一致性问题,半同步复制是通过判断从库响应的个数来决定是否返回给客户端,虽然数据一致性相比于异步复制有提升,但仍然无法满足对数据一致性要求高的场景,
比如金融领域。MGR 很好地弥补了这两种复制模式的不足。
组复制技术,简称 MGR(MySQL Group Replication)。是 MySQL 在 5.7.17 版本中推出的一种新的数据复制技术,这种复制技术是基于 Paxos 协议的状态机复制。
首先我们将多个节点共同组成一个复制组,在 执行读写(RW)事务 的时候,需要通过一致性协议层(Consensus 层)的同意,也就是读写事务想要进行提交,必须要经过组里“大多数人”(对应 Node 节点)的同意,
大多数指的是同意的节点数量需要大于 (N/2+1),这样才可以进行提交,而不是原发起方一个说了算。而针对 只读(RO)事务 则不需要经过组内同意,直接 COMMIT 即可。
在一个复制组内有多个节点组成,它们各自维护了自己的数据副本,并且在一致性协议层实现了原子消息和全局有序消息,从而保证组内数据的一致性。
MGR 将 MySQL 带入了数据强一致性的时代,是一个划时代的创新,其中一个重要的原因就是MGR 是基于 Paxos 协议的。Paxos 算法是由 2013 年的图灵奖获得者 Leslie Lamport 于 1990 年提出的,
有关这个算法的决策机制可以搜一下。事实上,Paxos 算法提出来之后就作为 分布式一致性算法 被广泛应用,比如Apache 的 ZooKeeper 也是基于 Paxos 实现的



 浙公网安备 33010602011771号
浙公网安备 33010602011771号