# 执行查询操作的时候,先查询缓存中是否有数据,缓存中有数据,则获取缓存中的数据
# 缓存中没有数据,则从mysql数据库中查询数据,同时将数据写入缓存中
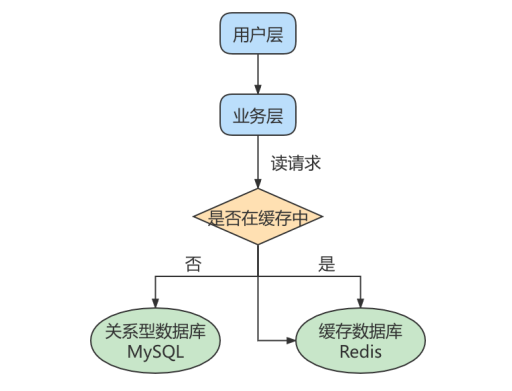
其中一个是Master主库,负责写入数据,我们称之为:写库。
其它都是Slave从库,负责读取数据,我们称之为:读库。
当主库进行更新的时候,会自动将数据复制到从库中,而我们在客户端读取数据的时候,会从从库中进行读取。
1、读写分离:面对“读多写少”的需求,采用读写分离的方式,可以实现更高的并发访问。同时,我们还能对从服务器进行负载均衡,让不同的读请求按照策略均匀地分发到不同的从服务器上,让读取更加顺畅。
读取顺畅的另一个原因,就是减少了锁表的影响,比如我们让主库负责写,当主库出现写锁的时候,不会影响到从库进行SELECT的读取。
2、数据备份:我们通过主从复制将主库上的数据复制到了从库上,相当于是一种热备份机制,也就是在主库正常运行的情况下进行的备份,不会影响到服务
3、具有高可用性:数据备份实际上是一种冗余的机制,通过这种冗余的方式可以换取数据库的高可用性,也就是当服务器出现故障或宕机的情况下,可以切换到从服务器上,保证服务的正常运行
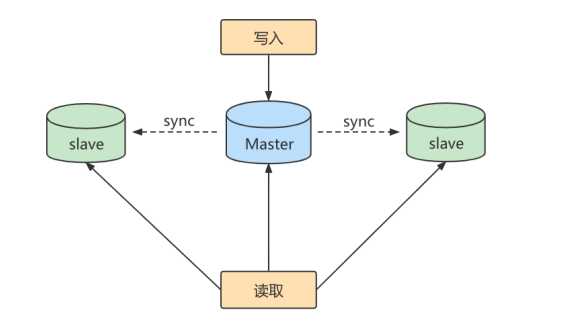
Slave 会从 Master 读取 binlog 来进行数据同步
步骤1: Master 将写操作记录到二进制日志( binlog )。
步骤2: Slave 将 Master 的binary log events拷贝到它的中继日志( relay log );
步骤3: Slave 重做中继日志中的事件,将改变应用到自己的数据库中。 MySQL复制是异步的且串行化的,而且重启后从 接入点 开始复制。
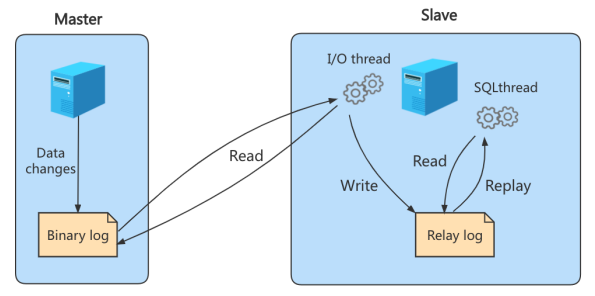
实际上主从同步的原理就是基于 binlog 进行数据同步的。在主从复制过程中,会基于 3 个线程 来操作,一个主库线程,两个从库线程
二进制日志转储线程 (Binlog dump thread)是一个主库线程。当从库线程连接的时候, 主库可以将二进制日志发送给从库,当主库读取事件(Event)的时候,会在 Binlog 上 加锁 ,读取完成之后,再将锁释放掉。
从库 I/O 线程 会连接到主库,向主库发送请求更新 Binlog。这时从库的 I/O 线程就可以读取到主库的二进制日志转储线程发送的 Binlog 更新部分,并且拷贝到本地的中继日志 (Relay log)。
从库 SQL 线程 会读取从库中的中继日志,并且执行日志中的事件,将从库中的数据与主库保持同步。
每个 Slave 只有一个 Master
每个 Slave 只能有一个唯一的服务器ID
每个 Master 可以有多个 Slave

 浙公网安备 33010602011771号
浙公网安备 33010602011771号