多版本并发控制:MVCC使用案例
- 简介
MVCC在READ COMMITTD、REPEATABLE READ这两种隔离级别的事务才执行快照读操作时访问记录的版本链的过程。
这样使不同事务的读-写、写-读操作并发执行,从而提升系统性能
- 案例1
# Transaction 10
BEGIN;
UPDATE student SET name="李四" WHERE id=1;
UPDATE student SET name="王五" WHERE id=1;
# Transaction 20
BEGIN;
# 更新了一些别的表的记录
# 使用READ COMMITTED隔离级别的事务
BEGIN;
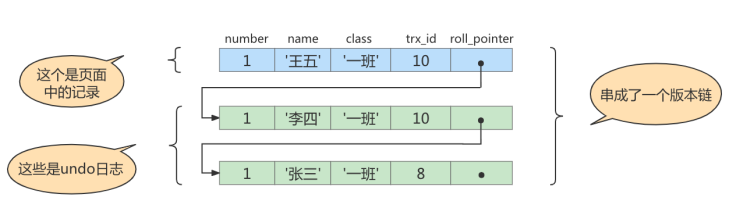
# SELECT1:Transaction 10、20未提交
# 得到的列name的值为'张三'
SELECT * FROM student WHERE id = 1;
# 得到值为“张三”的过程

- 案例2
# 提交事务10
# Transaction 10
BEGIN;
UPDATE student SET name="李四" WHERE id=1;
UPDATE student SET name="王五" WHERE id=1;
COMMIT;
# 事务id 为 20 的事务中更新一下表 student 中 id 为 1 的记录
# Transaction 20
BEGIN;
# 更新了一些别的表的记录
UPDATE student SET name="钱七" WHERE id=1;
UPDATE student SET name="宋八" WHERE id=1;
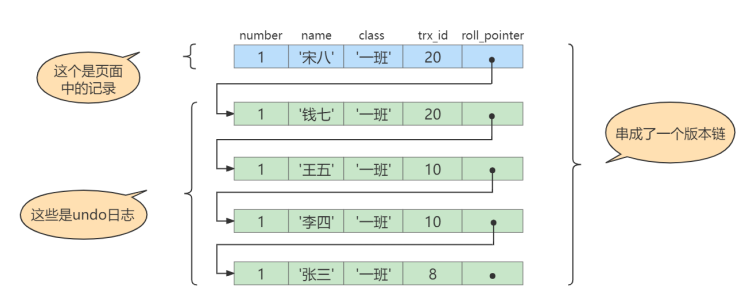
# 得到undo日志链表
# 使用READ COMMITTED隔离级别的事务
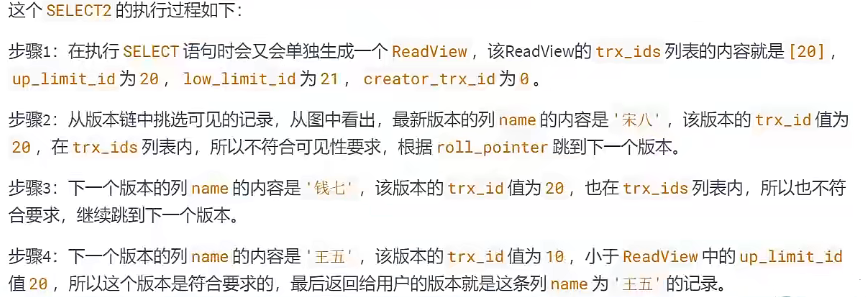
BEGIN;
# SELECT2:Transaction 10提交,Transaction 20未提交
SELECT * FROM student WHERE id = 1; # 得到的列name的值为'王五'
# 得到值为“王五”的过程如下
- 案例3
- 使用 REPEATABLE READ 隔离级别的事务来说,只会在第一次执行查询语句时生成一个 ReadView ,之后的查询就不会重复生成了
# Transaction 10
BEGIN;
UPDATE student SET name="李四" WHERE id=1;
UPDATE student SET name="王五" WHERE id=1;
# Transaction 20
BEGIN;
# 更新了一些别的表的记录
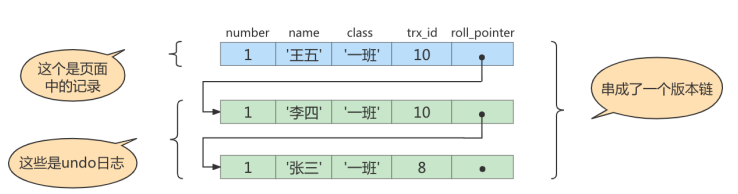
# 得到undo日志链表
# 使用REPEATABLE READ隔离级别的事务
BEGIN;
# SELECT1:Transaction 10、20未提交
SELECT * FROM student WHERE id = 1; # 得到的列name的值为'张三'
# 得到值为“张三”的过程如下

# 提交事务id 为 10 的事务
# Transaction 10
BEGIN;
UPDATE student SET name="李四" WHERE id=1;
UPDATE student SET name="王五" WHERE id=1;
COMMIT;
# 更新事务id 为 20 的事务
# Transaction 20
BEGIN;
# 更新了一些别的表的记录
UPDATE student SET name="钱七" WHERE id=1;
UPDATE student SET name="宋八" WHERE id=1;
# 得到undo日志链表
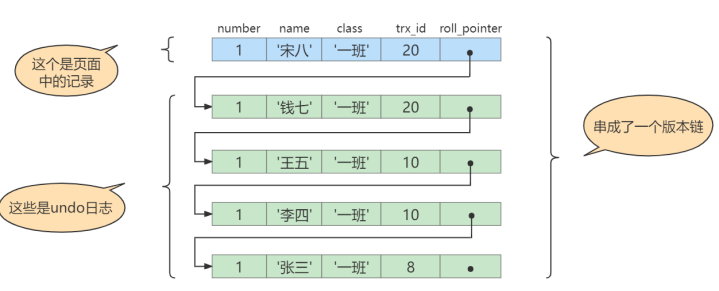
# 使用REPEATABLE READ隔离级别的事务
BEGIN;
# SELECT2:Transaction 10提交,Transaction 20未提交
SELECT * FROM student WHERE id = 1; # 得到的列name的值仍为'张三'
# 得到值为“张三”的过程


MVCC解决幻读
表student 中只有一条数据,数据内容中,主键 id=1,隐藏的 trx_id=10,它的 undo log 如下图所示

# 现在有事务 A 和事务 B 并发执行, 事务 A 的事务 id 为 20 , 事务 B 的事务 id 为 30
# 事务A执行如下
select * from student where id >= 1;
在开始查询之前,MySQL 会为事务 A 产生一个 ReadView,此时 ReadView 的内容如下: trx_ids= [20,30] , up_limit_id=20 , low_limit_id=31 , creator_trx_id=20 。
由于此时表 student 中只有一条数据,且符合 where id>=1 条件,因此会查询出来。然后根据 ReadView机制,发现该行数据的trx_id=10,小于事务 A 的 ReadView 里 up_limit_id,
这表示这条数据是事务 A 开启之前,其他事务就已经提交了的数据,因此事务 A 可以读取到。
结论:事务 A 的第一次查询,能读取到一条数据,id=1。
# 接着事务 B(trx_id=30),往表 student 中新插入两条数据,并提交事务
insert into student(id,name) values(2,'李四');
insert into student(id,name) values(3,'王五');
# undo日志链表如下
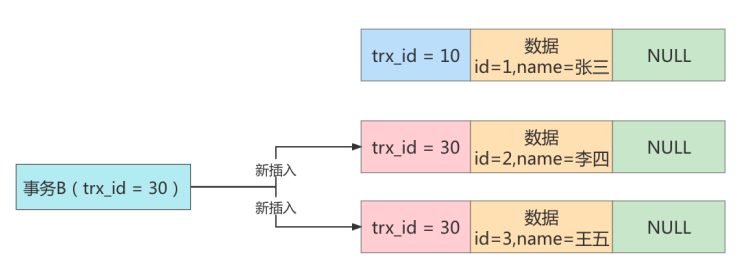
接着事务 A 开启第二次查询,根据可重复读隔离级别的规则,此时事务 A 并不会再重新生成ReadView。此时表 student 中的 3 条数据都满足 where id>=1 的条件,因此会先查出来。
然后根据ReadView 机制,判断每条数据是不是都可以被事务 A 看到。
1)首先 id=1 的这条数据,前面已经说过了,可以被事务 A 看到。
2)然后是 id=2 的数据,它的 trx_id=30,此时事务 A 发现,这个值处于 up_limit_id 和 low_limit_id 之间,因此还需要再判断 30 是否处于 trx_ids 数组内。由于事务 A 的 trx_ids=[20,30],因此在数组内,
这表示 id=2 的这条数据是与事务 A 在同一时刻启动的其他事务提交的,所以这条数据不能让事务 A 看到。
3)同理,id=3 的这条数据,trx_id 也为 30,因此也不能被事务 A 看见。
# undo日志链表如下
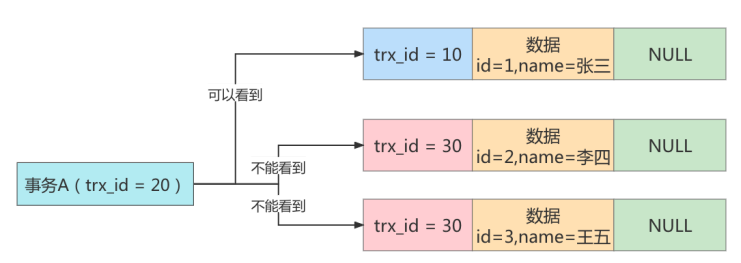
最终事务 A 的第二次查询,只能查询出 id=1 的这条数据。这和事务 A 的第一次查询的结果是一样的,因此没有出现幻读现象,所以说在 MySQL 的可重复读隔离级别下,不存在幻读问题
- 结论
READ COMMITTD 在每一次进行普通SELECT操作前都会生成一个ReadView
REPEATABLE READ 只在第一次进行普通SELECT操作前生成一个ReadView,之后的查询操作都重复使用这个ReadView就好了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号