MySQL数据结构
- 简介
全表遍历
Hash结构
二叉搜索树
AVL树
B-Tree
B+Tree
R树
- Hash结构
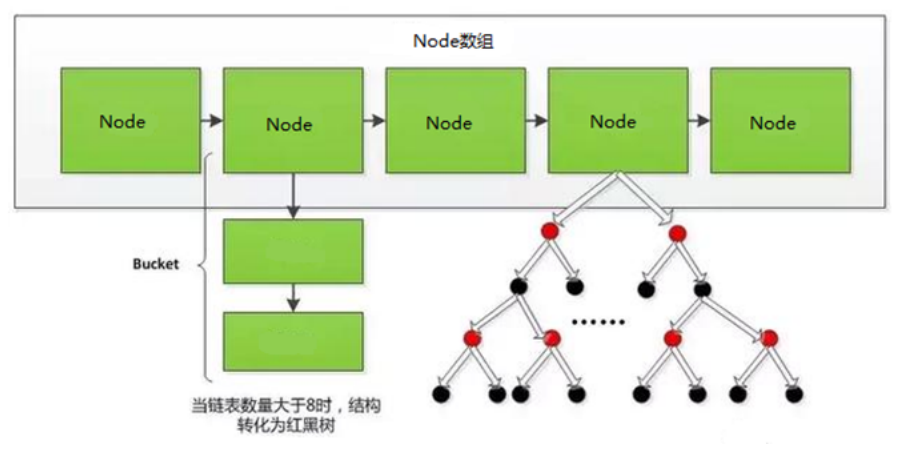
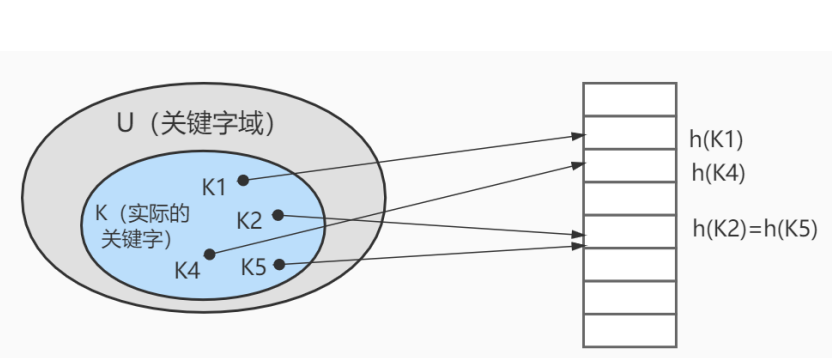
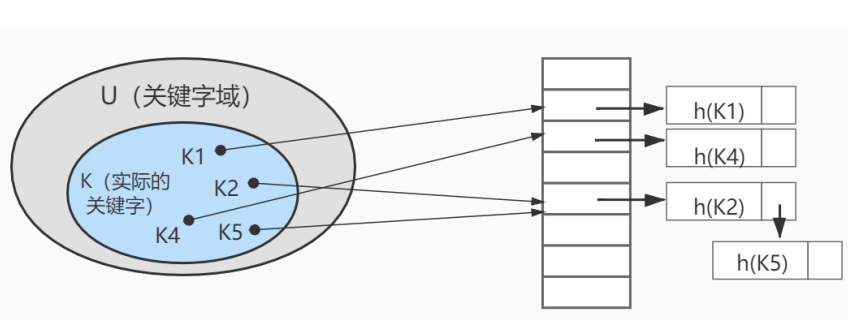
上图中哈希函数h有可能将两个不同的关键字映射到相同的位置,这叫做 碰撞 ,在数据库中一般采用 链接法 来解决。
在链接法中,将散列到同一槽位的元素放在一个链表中
- Hash索引适用存储引擎

- 为了减少IO,索引树会一次性加载吗?
数据库索引是存储在磁盘上的,如果数据量很大,必然导致索引的大小也会很大,超过几个G。
当我们利用索引查询时候,是不可能将全部几个G的索引都加载进内存的,我们能做的只能是:逐一加载每一个磁盘页,因为磁盘页对应着索引树的节点。
2.B+树的存储能力如何?为何说一般查找行记录,最多只需1~3次磁盘IO
InnoDB存储引擎中页的大小为16KB,一般表的主键类型为INT(占用4个字节)或BIGINT(占用8个字节),指针类型也一般为4或8个字节,
也就是说一个页(B+Tree中的一个节点)中大概存储16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的K取值为103。也就是说
一个深度为3的B+Tree索引可以维护103 *103 *103=10亿条记录。(这里假定一个数据页也存储103条行记录数据了)
实际情况中每个节点可能不能填充满,因此在数据库中,B+Tree的高度一般都在2~4层。MySQL的InnoDB存储引擎在设计时是将根节点常驻内存的,
也就是说查找某一键值的行记录时最多只需要1~3次磁盘IO操作。
3.为什么说B+树比B-树更适合实际应用中操作统的文件索引和数据库索引?
B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,
那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说I0读写次数也就降低了。
B+树的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。
所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
4.Hash索引与B+树索引的区别
Hash索引不能进行范围查询,而B+树可以。这是因为Hash索引指向的数据是无序的,而B+树的叶子节点是个有序的链表。
Hash索引不支持联合索引的最左侧原则(即联合索引的部分索引无法使用),而B+树可以。对于联合索引来说,Hash索引在计算Hash值的时候
是将索引键合并后再一起计算Hash值,所以不会针对每个索引单独计算Hash值。因此如果用到联合索引的一个或者几个索引时,联合索引无法被利用。
Hash索引不支持 ORDER BY排序,因为Hash索引指向的数据是无序的,因此无法起到排序优化的作用,而B+树索引数据是有序的,可以起到对该
字段ORDER BY排序优化的作用。同理,我们也无法用Hash索引进行模糊查询,而B+树使用LIKE进行模糊查询的时候,LIKE后面后模糊查询
(比如%结尾)的话就可以起到优化作用。
InnoDB不支持哈希索引

 浙公网安备 33010602011771号
浙公网安备 33010602011771号