逻辑架构
-
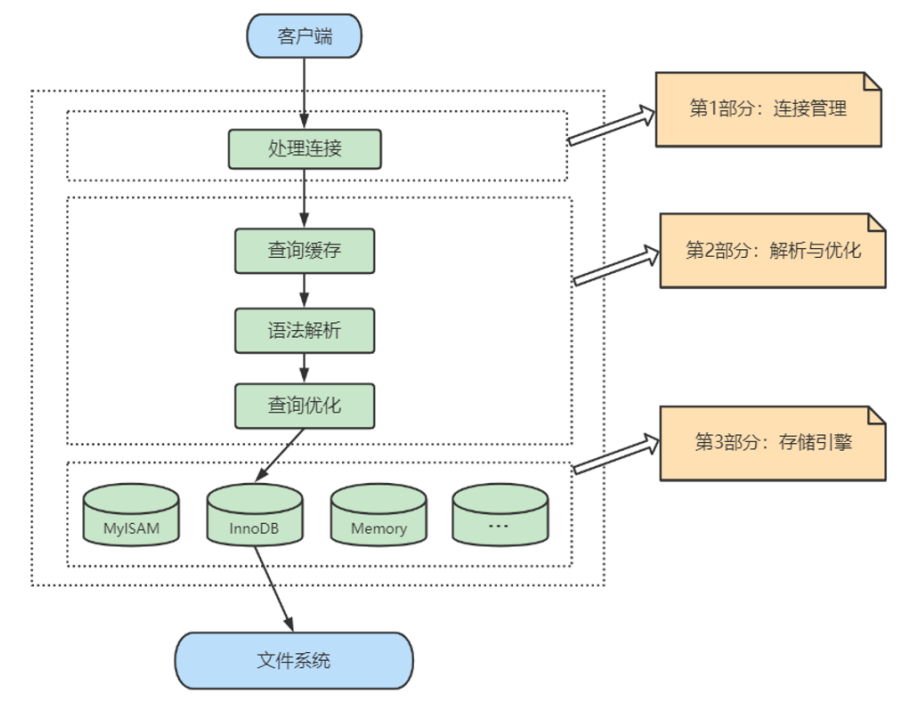
服务器处理客户端请求
-
连接层
1、系统(客户端)访问 MySQL 服务器前,做的第一件事就是建立 TCP 连接。
2、经过三次握手建立连接成功后, MySQL 服务器对 TCP 传输过来的账号密码做身份认证、权限获取。
用户名或密码不对,会收到一个Access denied for user错误,客户端程序结束执行
用户名密码认证通过,会从权限表查出账号拥有的权限与连接关联,之后的权限判断逻辑,都将依赖于此时读到的权限
3、TCP 连接收到请求后,必须要分配给一个线程专门与这个客户端的交互。所以还会有个线程池,去走后面的流程。
每一个连接从线程池中获取线程,省去了创建和销毁线程的开销
- 服务层
1、SQL Interface: SQL接口
接收用户的SQL命令,并且返回用户需要查询的结果。比如SELECT ... FROM就是调用SQLInterface
MySQL支持DML(数据操作语言)、DDL(数据定义语言)、存储过程、视图、触发器、自定义函数等多种SQL语言接口
2、Parser: 解析器
2.1、在解析器中对 SQL 语句进行语法分析、语义分析。将SQL语句分解成数据结构,并将这个结构传递到后续步骤,
以后SQL语句的传递和处理就是基于这个结构的。如果在分解构成中遇到错误,那么就说明这个SQL语句是不合理的。
2.2、在SQL命令传递到解析器的时候会被解析器验证和解析,并为其创建 语法树 ,并根据数据字典丰富查询语法树,
会验证该客户端是否具有执行该查询的权限 。创建好语法树后,MySQL还会对SQl查询进行语法上的优化,进行查询重写。
3、Optimizer: 查询优化器
3.1、SQL语句在语法解析之后、查询之前会使用查询优化器确定 SQL 语句的执行路径,生成一个执行计划 。
3.2、这个执行计划表明应该 使用哪些索引 进行查询(全表检索还是使用索引检索),表之间的连接顺序如何,
最后会按照执行计划中的步骤调用存储引擎提供的方法来真正的执行查询,并将查询结果返回给用户。
3.3、它使用“ 选取-投影-连接 ”策略进行查询。例如:SELECT id,name FROM student WHERE gender = '女';
这个SELECT查询先根据WHERE语句进行 选取 ,而不是将表全部查询出来以后再进行gender过滤。
这个SELECT查询先根据id和name进行属性 投影 ,而不是将属性全部取出以后再进行过滤,将这两个查询条件 连接 起来生成最终查询结果。
4、Caches & Buffers: 查询缓存组件
4.1、MySQL内部维持着一些Cache和Buffer,比如Query Cache用来缓存一条SELECT语句的执行结果,
如果能够在其中找到对应的查询结果,那么就不必再进行查询解析、优化和执行的整个过程了,直接将结果反馈给客户端。
4.2、这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等 。
4.3、这个查询缓存可以在 不同客户端之间共享 。
4.4、从MySQL 5.7.20开始,不推荐使用查询缓存,并在 MySQL 8.0中删除 。
- 引擎层
插件式存储引擎层( Storage Engines),真正的负责了MySQL中数据的存储和提取,对物理服务器级别维护的底层数据执行操作,
服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取
# 查看
show engines
- 存储层
所有的数据,数据库、表的定义,表的每一行的内容,索引,都是存在 文件系统 上,以 文件 的方式存在的,
并完成与存储引擎的交互。当然有些存储引擎比如InnoDB,也支持不使用文件系统直接管理裸设备,
但现代文件系统的实现使得这样做没有必要了。在文件系统之下,可以使用本地磁盘,可以使用DAS、NAS、SAN等各种存储系统
- 简化图
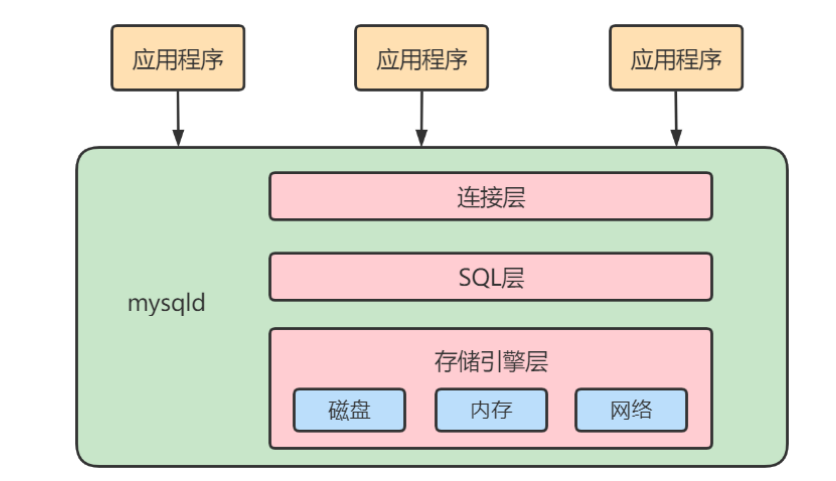
连接层:客户端和服务器端建立连接,客户端发送 SQL 至服务器端;
SQL 层(服务层):对 SQL 语句进行查询处理;与数据库文件的存储方式无关;
存储引擎层:与数据库文件打交道,负责数据的存储和读取。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号