前言
算术运算符
- 算术运算符主要用于数学运算,其可以连接运算符前后的两个数值或表达式,对数值或表达式进行加(+)、减(-)、乘(*)、除(/)和取模(%)运算
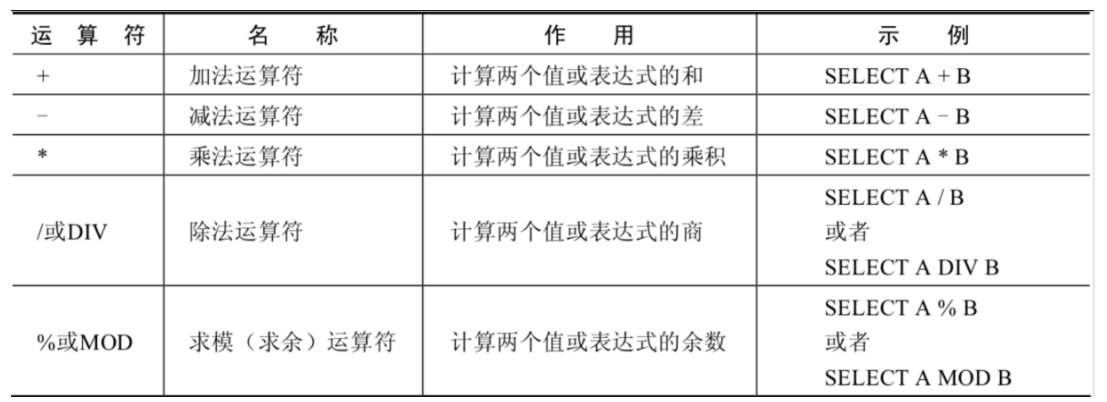
一个整数类型的值对整数进行加法和减法操作,结果还是一个整数;
一个整数类型的值对浮点数进行加法和减法操作,结果是一个浮点数;
加法和减法的优先级相同,进行先加后减操作与进行先减后加操作的结果是一样的;
在Java中,+的左右两边如果有字符串,那么表示字符串的拼接。但是在MySQL中+只表示数值相加。如果遇到非数值类型,先尝试转成数值,如果转失败,就按0计算。(补充:MySQL中字符串拼接要使用字符串函数CONCAT()实现)
一个数乘以整数1和除以整数1后仍得原数;
一个数乘以浮点数1和除以浮点数1后变成浮点数,数值与原数相等;
一个数除以整数后,不管是否能除尽,结果都为一个浮点数;
一个数除以另一个数,除不尽时,结果为一个浮点数,并保留到小数点后4位;
乘法和除法的优先级相同,进行先乘后除操作与先除后乘操作,得出的结果相同
在数学运算中,0不能用作除数,在MySQL中,一个数除以0为NULL
# 加减运算符
SELECT 100, 100 + 0, 100 - 0, 100 + 50, 100 + 50 * 30, 100 + 35.5, 100 - 35.5 FROM DUAL;
# 在SQL中,+没有连接的作用,就表示加法运算。此时,会将字符串转换为数值(隐式转换)
SELECT 100 + '1' FROM DUAL;
# 此时将'a'看做0处理
SELECT 100 + 'a' FROM DUAL;
# null值参与运算,结果为null
SELECT 100 + NULL FROM DUAL;
# 分母如果为0,则结果为null
SELECT 100, 100 * 1, 100 * 1.0, 100 / 1.0, 100 / 2, 100 + 2 * 5 / 2,100 / 3, 100 DIV 0 FROM DUAL;
# 取模运算: 使用 % 或 mod
SELECT 12 % 3, 12 % 5, 12 MOD -5, -12 % 5, -12 % -5 FROM DUAL;
# 查询员工id为偶数的员工信息
SELECT employee_id,last_name,salary
FROM employees
WHERE employee_id % 2 = 0;
比较运算符
比较运算符用来对表达式左边的操作数和右边的操作数进行比较,比较的结果为真则返回1,比较的结果为假则返回0,其他情况则返回NULL
比较运算符经常被用来作为SELECT查询语句的条件来使用,返回符合条件的结果记录
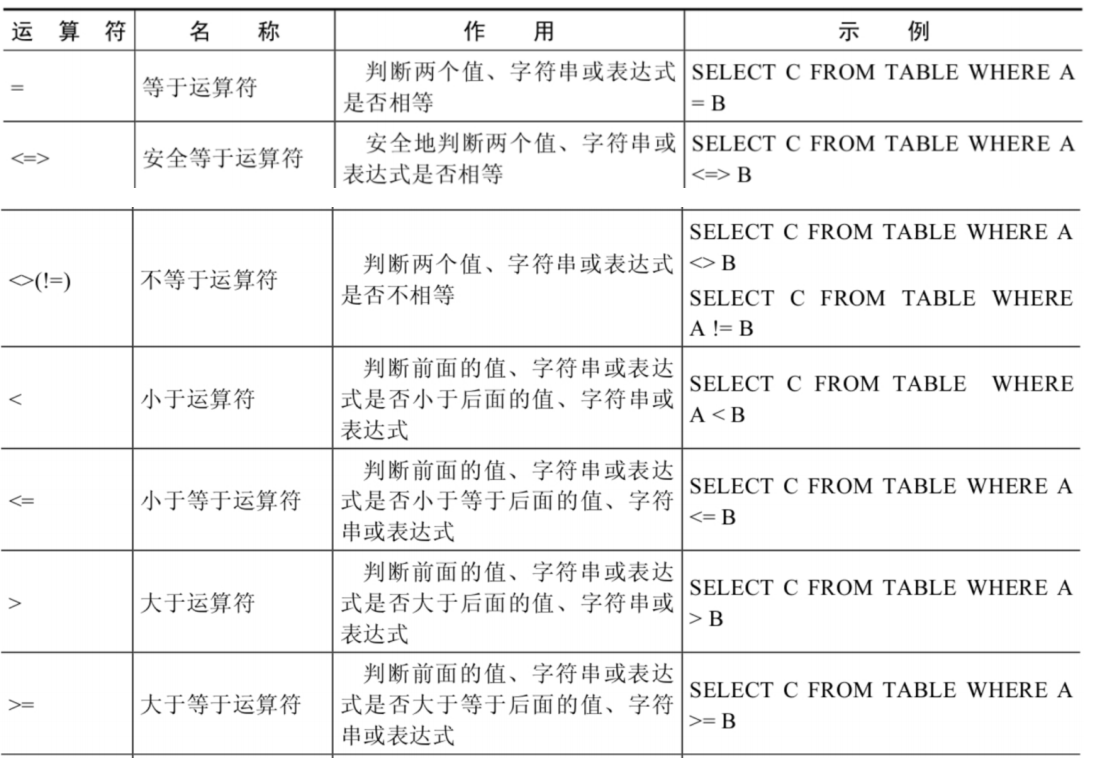
等号运算符(=)判断等号两边的值、字符串或表达式是否相等,如果相等则返回1,不相等则返回0
在使用等号运算符时,遵循如下规则:
如果等号两边的值、字符串或表达式都为字符串,则MySQL会按照字符串进行比较,其比较的是每个字符串中字符的ANSI编码是否相等
如果等号两边的值都是整数,则MySQL会按照整数来比较两个值的大小
如果等号两边的值一个是整数,另一个是字符串,则MySQL会将字符串转化为数字进行比较
如果等号两边的值、字符串或表达式中有一个为NULL,则比较结果为NULL
安全等于运算符(<=>)与等于运算符(=)的作用是相似的, 唯一的区别 是‘<=>’可以用来对NULL进行判断。在两个操作数均为NULL时,其返回值为1,而不为NULL;当一个操作数为NULL时,其返回值为0,而不为NULL
不等于运算符(<>和!=)用于判断两边的数字、字符串或者表达式的值是否不相等,如果不相等则返回1,相等则返回0。不等于运算符不能判断NULL值。如果两边的值有任意一个为NULL,或两边都为NULL,则结果为NULL
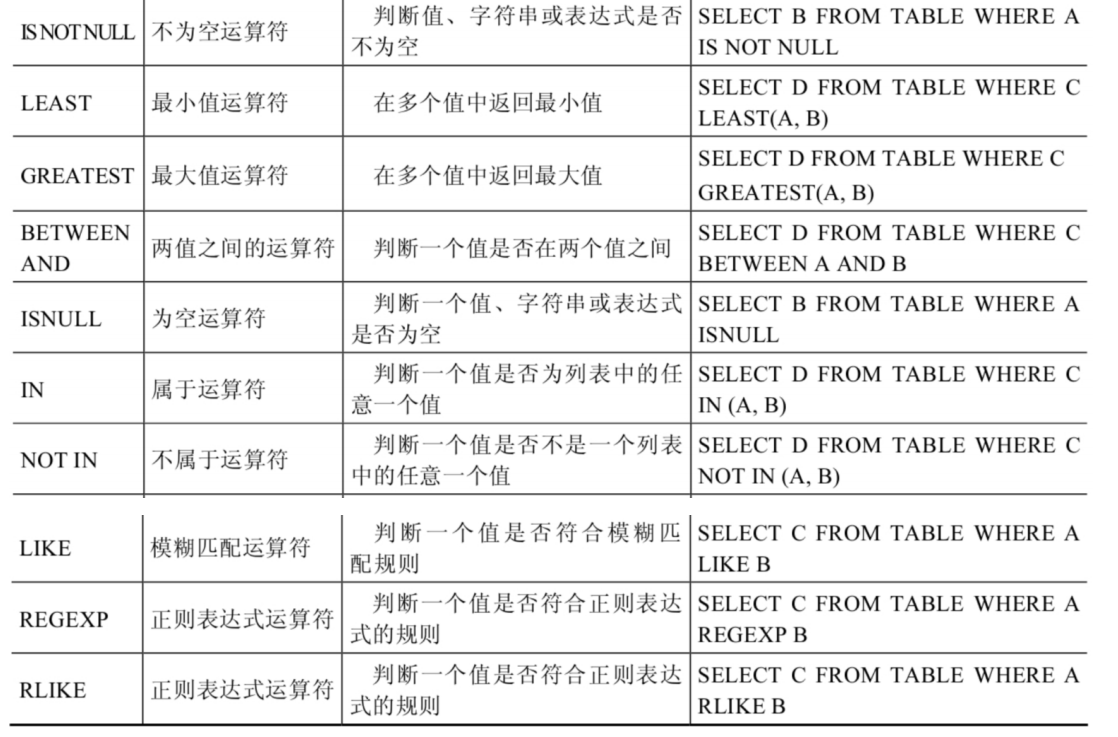
空运算符(IS NULL或者ISNULL)判断一个值是否为NULL,如果为NULL则返回1,否则返回0
非空运算符(IS NOT NULL)判断一个值是否不为NULL,如果不为NULL则返回1,否则返回0
语法格式为:LEAST(值1,值2,...,值n)。其中,“值n”表示参数列表中有n个值。在有两个或多个参数的情况下,返回最小值
当参数是整数或者浮点数时,LEAST将返回其中最小的值;当参数为字符串时,返回字母表中顺序最靠前的字符;当比较值列表中有NULL时,不能判断大小,返回值为NULL
语法格式为:GREATEST(值1,值2,...,值n)。其中,n表示参数列表中有n个值。当有两个或多个参数时,返回值为最大值。假如任意一个自变量为NULL,则GREATEST()的返回值为NULL
当参数中是整数或者浮点数时,GREATEST将返回其中最大的值;当参数为字符串时,返回字母表中顺序最靠后的字符;当比较值列表中有NULL时,不能判断大小,返回值为NULL
BETWEEN运算符使用的格式通常为SELECT D FROM TABLE WHERE C BETWEEN A AND B,此时,当C大于或等于A,并且C小于或等于B时,结果为1,否则结果为0
IN运算符用于判断给定的值是否是IN列表中的一个值,如果是则返回1,否则返回0。如果给定的值为NULL,或者IN列表中存在NULL,则结果为NULL
NOT IN运算符用于判断给定的值是否不是IN列表中的一个值,如果不是IN列表中的一个值,则返回1,否则返回0
LIKE运算符主要用来匹配字符串,通常用于模糊匹配,如果满足条件则返回1,否则返回0。如果给定的值或者匹配条件为NULL,则返回结果为NULL
“%”:匹配0个或多个字符
“_”:只能匹配一个字符
回避特殊符号的:使用转义符
# 使用转义字符\ 表示查询以 IT_ 开头的值
SELECT job_id FROM jobs WHERE job_id LIKE ‘IT\_%‘;
# 使用自定义的转义字符$ 表示查询以 IT_ 开头的值
SELECT job_id FROM jobs WHERE job_id LIKE ‘IT$_%‘ escape ‘$‘;
# = 的使用,逻辑正确时返回1,错误时返回0
# 字符串存在隐式转换。如果转换数值不成功,则看做0
SELECT 1 = 2,1 != 2,1 = '1',1 = 'a',0 = 'a' FROM DUAL;
# 两边都是字符串的话,则按照ANSI的比较规则进行比较
SELECT 'a' = 'a','ab' = 'ab','a' = 'b' FROM DUAL;
# 只要有null参与判断,结果就为null
SELECT 1 = NULL,NULL = NULL
FROM DUAL;
# 错误案例
# 错误原因,不会有任何的结果,where中查询为null,select又包含该字段
SELECT last_name,salary,commission_pct
FROM employees
#where salary = 6000;
WHERE commission_pct = NULL;
# <=> 安全等于。记忆技巧:为NULL而生
SELECT 1 <=> 2,1 <=> '1',1 <=> 'a',0 <=> 'a' FROM DUAL;
# 使用用安全等于运算符,比较null
SELECT 1 <=> NULL, NULL <=> NULL FROM DUAL;
# 查询表中commission_pct为null的数据有哪些
SELECT last_name, salary, commission_pct
FROM employees
WHERE commission_pct <=> NULL;
# 使用不等于运算符
SELECT 3 <> 2, '4' <> NULL, '' != NULL, NULL != NULL FROM DUAL;
# IS NULL 或 IS NOT NULL 或 ISNULL 的使用
# 查询表中commission_pct为null的数据有哪些
SELECT last_name, salary, commission_pct
FROM employees
WHERE commission_pct IS NULL;
# 写法2
SELECT last_name,salary,commission_pct
FROM employees
WHERE ISNULL(commission_pct);
# 查询表中commission_pct不为null的数据有哪些
SELECT last_name, salary, commission_pct
FROM employees
WHERE commission_pct IS NOT NULL;
# 写法2: 使用不等于运算符
SELECT last_name, salary, commission_pct
FROM employees
WHERE NOT commission_pct <=> NULL;
# LEAST() 或 GREATEST 的使用
# 获取字符的最小值和最大值
SELECT LEAST('g','b','t','m'), GREATEST('g','b','t','m') FROM DUAL;
# 获取字段的最小值
SELECT LEAST(first_name, last_name), LEAST(LENGTH(first_name), LENGTH(last_name)) FROM employees;
# BETWEEN 条件下界1 AND 条件上界2(查询条件1和条件2范围内的数据,包含边界)
# 查询工资在6000 到 8000的员工信息
SELECT employee_id, last_name, salary
FROM employees
# where salary between 6000 and 8000;
WHERE salary >= 6000 && salary <= 8000;
# 错误写法:交换6000和8000的位置之后,查询不到数据
# 因为条件上界和条件下界位置不对
SELECT employee_id, last_name, salary
FROM employees
WHERE salary BETWEEN 8000 AND 6000;
# 查询工资不在6000 到 8000的员工信息
SELECT employee_id, last_name, salary
FROM employees
WHERE salary NOT BETWEEN 6000 AND 8000;
#where salary < 6000 or salary > 8000; # 写法2
# in 或 not in 的使用
# 查询部门为10,20,30部门的员工信息
SELECT last_name, salary, department_id
FROM employees
#where department_id = 10 or department_id = 20 or department_id = 30; # 写法1
WHERE department_id IN (10,20,30);
# 查询工资不是6000,7000,8000的员工信息
SELECT last_name, salary, department_id
FROM employees
WHERE salary NOT IN (6000,7000,8000);
# LIKE 模糊查询
# % 表示不确定个数的字符 (0个,1个,或多个)
# 查询last_name中包含字符'a'的员工信息
SELECT last_name
FROM employees
WHERE last_name LIKE '%a%';
# 查询last_name中以字符'a'开头的员工信息
SELECT last_name
FROM employees
WHERE last_name LIKE 'a%';
# 查询last_name中包含字符'a'且包含字符'e'的员工信息
# 写法1:
SELECT last_name
FROM employees
WHERE last_name LIKE '%a%' AND last_name LIKE '%e%';
# 写法2:
SELECT last_name
FROM employees
WHERE last_name LIKE '%a%e%' OR last_name LIKE '%e%a%';
# 在模糊查询中,_ 表示一个不确定的字符
# 查询第3个字符是'a'的员工信息
SELECT last_name
FROM employees
WHERE last_name LIKE '__a%';
# 查询第2个字符是 _ 且第3个字符是'a'的员工信息
# 需要使用转义字符: \
SELECT last_name
FROM employees
WHERE last_name LIKE '_\_a%';
# 写法2
SELECT last_name
FROM employees
WHERE last_name LIKE '_$_a%' ESCAPE '$';
1、REGEXP运算符用来匹配字符串,语法格式为:expr REGEXP 匹配条件
2、正则表达式通常被用来检索或替换那些符合某个模式的文本内容,根据指定的匹配模式匹配文本中符合要求的特殊字符串。例如,从一个文本文件中提取电话号码,查找一篇文章中重复的单词或者替换用户输入的某些敏感词语等,这些地方都可以使用正则表达式。正则表达式强大而且灵活,可以应用于非常复杂的查询
3、MySQL中使用REGEXP关键字指定正则表达式的字符匹配模式
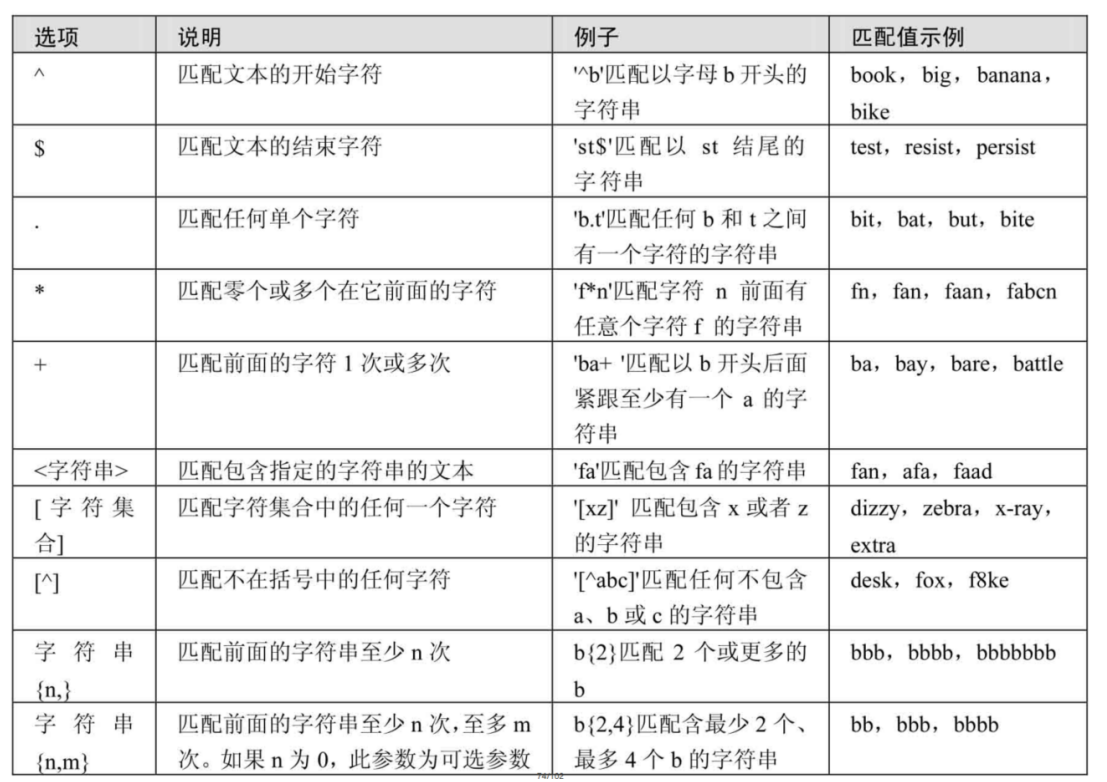
# REGEXP 或 RLIKE 正则表达式
SELECT 'shkstart' REGEXP '^shk', 'shkstart' REGEXP 't$', 'shkstart' REGEXP 'hk' FROM DUAL;
SELECT 'atguigu' RLIKE 'gu.gu','atguigu' RLIKE '[ab]' FROM DUAL;
# 查询以特定字符或字符串开头的记录 字符‘^’匹配以特定字符或者字符串开头的文本
SELECT * FROM fruits WHERE f_name REGEXP '^b';
# 查询以特定字符或字符串结尾的记录 字符‘$’匹配以特定字符或者字符串结尾的文本
SELECT * FROM fruits WHERE f_name REGEXP 'y$';
# 用符号"."来替代字符串中的任意一个字符 字符‘.’匹配任意一个字符。 在fruits表中,查询f_name字段值包含字母‘a’与‘g’且两个字母之间只有一个字母的记录
SELECT * FROM fruits WHERE f_name REGEXP 'a.g';
# 使用"*"和"+"来匹配多个字符 星号‘*’匹配前面的字符任意多次,包括0次。加号‘+’匹配前面的字符至少一次
SELECT * FROM fruits WHERE f_name REGEXP '^ba+';
# 匹配指定字符串 正则表达式可以匹配指定字符串,只要这个字符串在查询文本中即可,如要匹配多个字符串,多个字符串之间使用分隔符‘|’隔开
# 在fruits表中,查询f_name字段值包含字符串“on”的记录
SELECT * FROM fruits WHERE f_name REGEXP 'on';
# 在fruits表中,查询f_name字段值包含字符串“on”或者“ap”的记录
SELECT * FROM fruits WHERE f_name REGEXP 'on|ap';
# LIKE运算符也可以匹配指定的字符串,但与REGEXP不同,LIKE匹配的字符串如果在文本中间出现,则找不到它,相应的行也不会返回。REGEXP在文本内进行匹配,如果被匹配的字符串在文本中出现,REGEXP将会找到它,相应的行也会被返回
# 匹配指定字符中的任意一个 方括号“[]”指定一个字符集合,只匹配其中任何一个字符,即为所查找的文本
# 在fruits表中,查找f_name字段中包含字母‘o’或者‘t’的记录
SELECT * FROM fruits WHERE f_name REGEXP '[ot]';
# 在fruits表中,查询s_id字段中包含4、5或者6的记录
SELECT * FROM fruits WHERE s_id REGEXP '[456]';
# 匹配指定字符以外的字符 “[^字符集合]” 匹配不在指定集合中的任何字符
# 在fruits表中,查询f_id字段中包含字母a~e和数字1~2以外字符的记录
SELECT * FROM fruits WHERE f_id REGEXP '[^a-e1-2]';
# 使用{n,}或者{n,m}来指定字符串连续出现的次数 “字符串{n,}”表示至少匹配n次前面的字符;“字符串{n,m}”表示匹配前面的字符串不少于n次,不多于m次。例如,a{2,}表示字母a连续出现至少2次,也可以大于2次;a{2,4}表示字母a连续出现最少2次,最多不能超过4次
# 在fruits表中,查询f_name字段值出现字母‘x’至少2次的记录
SELECT * FROM fruits WHERE f_name REGEXP 'x{2,}';
# 在fruits表中,查询f_name字段值出现字符串“ba”最少1次、最多3次的记录
SELECT * FROM fruits WHERE f_name REGEXP 'ba{1,3}';
逻辑运算符
逻辑运算符主要用来判断表达式的真假,在MySQL中,逻辑运算符的返回结果为1、0或者NULL
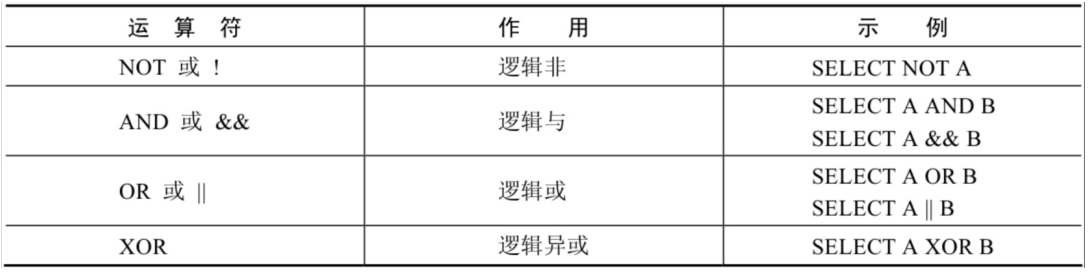
逻辑非(NOT或!)运算符表示当给定的值为0时返回1;当给定的值为非0值时返回0;当给定的值为NULL时,返回NULL
逻辑与(AND或&&)运算符是当给定的所有值均为非0值,并且都不为NULL时,返回1;当给定的一个值或者多个值为0时则返回0;否则返回NULL
1、逻辑或(OR或||)运算符是当给定的值都不为NULL,并且任何一个值为非0值时,则返回1,否则返回0;当一个值为NULL,并且另一个值为非0值时,返回1,否则返回NULL;当两个值都为NULL时,返回NULL
2、重点:OR可以和AND一起使用,但是在使用时要注意两者的优先级,由于AND的优先级高于OR,因此先对AND两边的操作数进行操作,再与OR中的操作数结合
逻辑异或(XOR)运算符是当给定的值中任意一个值为NULL时,则返回NULL;如果两个非NULL的值都是0或者都不等于0时,则返回0;如果一个值为0,另一个值不为0时,则返回1
# 例如:
# 如果满足department_id in (10,20)就不能满足salary > 8000;反之如果满足salary > 8000就不能满足department_id in (10,20)
select last_name,department_id,salary from employees where department_id in (10,20) XOR salary > 8000;
# or 或 and
SELECT last_name, salary, department_id
FROM employees
#where department_id = 10 or department_id = 20; # 测试or
#where department_id = 10 and department_id = 20; # 测试and
WHERE department_id = 50 AND salary > 6000;
# not
SELECT last_name, salary, department_id
FROM employees
#where salary not between 6000 and 8000; # 测试not案例1
#where commission_pct is not null; # 测试not案例2
WHERE NOT commission_pct <=> NULL;
# XOR 异或
SELECT last_name, salary, department_id
FROM employees
WHERE department_id = 50 XOR salary > 6000;
# 注意:AND的优先级高于OR
位运算符
位运算符是在二进制数上进行计算的运算符。位运算符会先将操作数变成二进制数,然后进行位运算,最后将计算结果从二进制变回十进制数
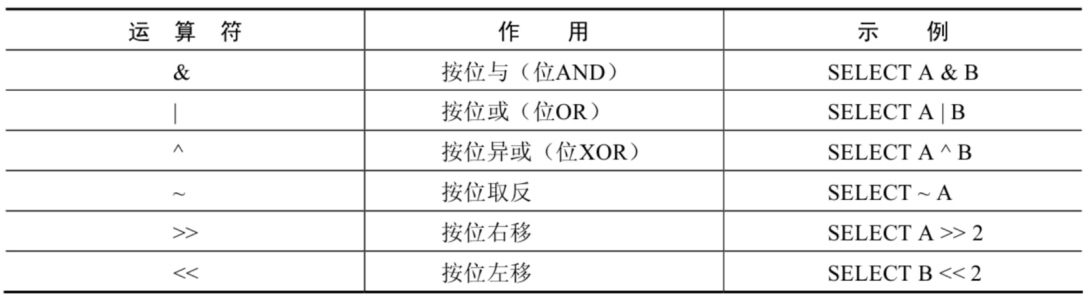
按位与(&)运算符将给定值对应的二进制数逐位进行逻辑与运算。当给定值对应的二进制位的数值都为1时,则该位返回1,否则返回0
按位或(|)运算符将给定的值对应的二进制数逐位进行逻辑或运算。当给定值对应的二进制位的数值有一个或两个为1时,则该位返回1,否则返回0
按位取反(~)运算符将给定的值的二进制数逐位进行取反操作,即将1变为0,将0变为1
按位右移(>>)运算符将给定的值的二进制数的所有位右移指定的位数。右移指定的位数后,右边低位的数值被移出并丢弃,左边高位空出的位置用0补齐
按位左移(<<)运算符将给定的值的二进制数的所有位左移指定的位数。左移指定的位数后,左边高位的数值被移出并丢弃,右边低位空出的位置用0补齐
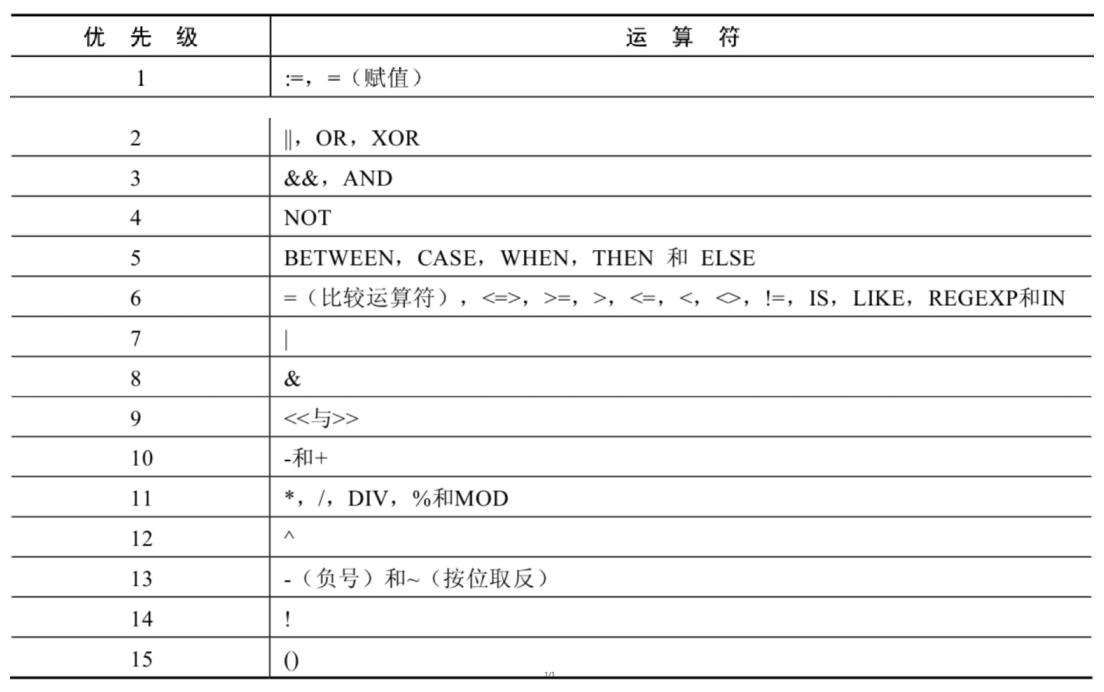
- 运算符优先级:数字编号越大,优先级越高
课后练习
# 选择工资不在5000到12000的员工的姓名和工资
SELECT last_name, salary
FROM employees
#where salary not between 5000 and 12000; # 方式1
WHERE salary < 5000 OR salary > 12000;
# 选择在20或50号部门工作的员工姓名和部门号
SELECT last_name, department_id
FROM employees
# where department_id in (20,50); # 方式1
WHERE department_id = 20 OR department_id = 50;
# 选择公司中没有管理者的员工姓名及job_id
SELECT last_name, job_id, manager_id
FROM employees
WHERE manager_id IS NULL;
# 方式2,使用安全等于运算符
SELECT last_name, job_id, manager_id
FROM employees
WHERE manager_id <=> NULL;
# 选择公司中有奖金的员工姓名,工资和奖金级别
SELECT last_name, salary, commission_pct
FROM employees
WHERE commission_pct IS NOT NULL;
# 方式2,使用安全等于运算符
SELECT last_name, salary, commission_pct
FROM employees
WHERE NOT commission_pct <=> NULL;
# 选择员工姓名的第三个字母是a的员工姓名
SELECT last_name
FROM employees
WHERE last_name LIKE '__a%';
# 选择姓名中有字母a和k的员工姓名
SELECT last_name
FROM employees
WHERE last_name LIKE '%a%k%' OR last_name LIKE '%k%a%';
#where last_name like '%a%' and last_name LIKE '%k%'; # 方式2
# 显示出表 employees 表中 first_name 以 'e'结尾的员工信息
SELECT first_name, last_name
FROM employees
WHERE first_name LIKE '%e';
# 方式2,使用正则表达式
SELECT first_name, last_name
FROM employees
WHERE first_name REGEXP 'e$'; # 以e开头的写法:'^e'
# 显示出表 employees 部门编号在 80-100 之间的姓名、工种
SELECT last_name, job_id
FROM employees
#方式1:
WHERE department_id BETWEEN 80 AND 100;
#方式2:
#where department_id >= 80 and department_id <= 100;
#方式3:
#where department_id in (80,90,100);
# 显示出表 employees 的 manager_id 是 100,101,110 的员工姓名、工资、管理者id
SELECT last_name, salary, manager_id
FROM employees
WHERE manager_id IN (100,101,110);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号