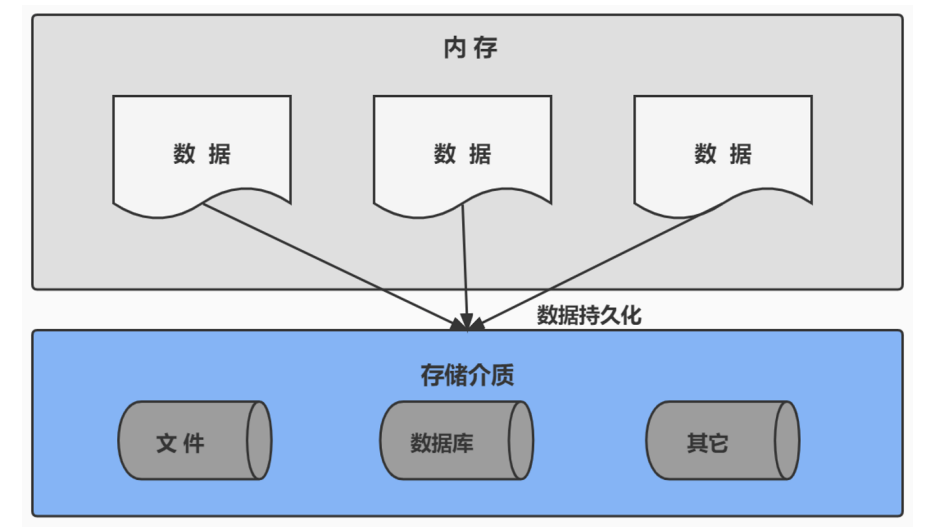
1、持久化(persistence):把数据保存到可掉电式存储设备中以供之后使用。大多数情况下,特别是企业级应用,数据持久化意味着将内存中的数据保存到硬盘上加以”固化”,而持久化的实现过程大多通过各种关系数据库来完成
2、持久化的主要作用是将内存中的数据存储在关系型数据库中,当然也可以存储在磁盘文件、XML数据文件中
DB:数据库(Database)
即存储数据的“仓库”,其本质是一个文件系统。它保存了一系列有组织的数据
DBMS:数据库管理系统(Database Management System)
是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控制。用户通过数据库管理系统访问数据库中表内的数据
SQL:结构化查询语言(Structured Query Language)
专门用来与数据库通信的语言
关系型数据库模型是把复杂的数据结构归结为简单的二元关系(即二维表格形式)
关系型数据库以 行(row) 和 列(column) 的形式存储数据,以便于用户理解
非关系型数据库,基于键值对存储数据,不需要经过SQL层的解析,性能非常高
1、键值型数据库
键值型数据库通过 Key-Value 键值的方式来存储数据,其中 Key 和 Value 可以是简单的对象,也可以是复杂的对象。Key 作为唯一的标识符,优点是查找速度快,在这方面明显优于关系型数据库,缺点是无法像关系型数据库一样使用条件过滤(比如 WHERE),如果你不知道去哪里找数据,就要遍历所有的键,这就会消耗大量的计算
键值型数据库典型的使用场景是作为内存缓存,Redis是最流行的键值型数据库
2、文档型数据库
此类数据库可存放并获取文档,可以是XML、JSON等格式。在数据库中文档作为处理信息的基本单位,一个文档就相当于一条记录。文档数据库所存放的文档,就相当于键值数据库所存放的“值”。MongoDB是最流行的文档型数据库。此外,还有CouchDB等
3、搜索引擎数据库
虽然关系型数据库采用了索引提升检索效率,但是针对全文索引效率却较低。搜索引擎数据库是应用在搜索引擎领域的数据存储形式,由于搜索引擎会爬取大量的数据,并以特定的格式进行存储,这样在检索的时候才能保证性能最优。核心原理是“倒排索引”
典型产品:Solr、Elasticsearch、Splunk 等
4、列式数据库
列式数据库是相对于行式存储的数据库,Oracle、MySQL、SQL Server 等数据库都是采用的行式存储(Row-based),而列式数据库是将数据按照列存储到数据库中,这样做的好处是可以大量降低系统的I/O,适合于分布式文件系统,不足在于功能相对有限。典型产品:HBase等
5、图形数据库
图形数据库顾名思义,就是一种存储图形关系的数据库。它利用了图这种数据结构存储了实体(对象)之间的关系。关系型数据用于存储明确关系的数据,但对于复杂关系的数据存储却有些力不从心。如社交网络中人物之间的关系,如果用关系型数据库则非常复杂,用图形数据库将非常简单。典型产品:Neo4J、InfoGrid等
一个数据库中可以有多个表,每个表都有一个名字,用来标识自己。表名具有唯一性
表具有一些特性,这些特性定义了数据在表中如何存储,类似Java和Python中 “类”的设计
1、E-R(entity-relationship,实体-联系)模型中有三个主要概念是:实体集、属性、联系集
2、一个实体集(class)对应于数据库中的一个表(table),一个实体(instance)则对应于数据库表中的一行(row),也称为一条记录(record)。一个属性(attribute)对应于数据库表中的一列(column),也称为一个字段(field)
表与表之间的数据记录有关系(relationship)。现实世界中的各种实体以及实体之间的各种联系均用关系模型来表示
四种:一对一关联、一对多关联、多对多关联、自我引用
外键唯一:主表的主键和从表的外键(唯一),形成主外键关系,外键唯一
外键是主键:主表的主键和从表的主键,形成主外键关系
一对多建表原则:在从表(多方)创建一个字段,字段作为外键指向主表(一方)的主键
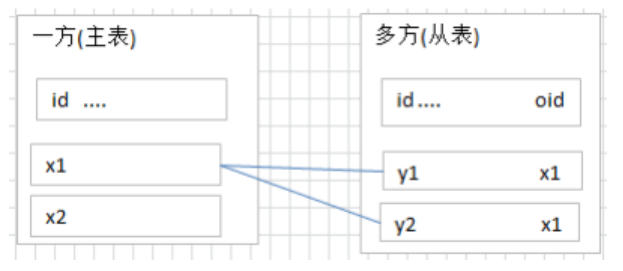
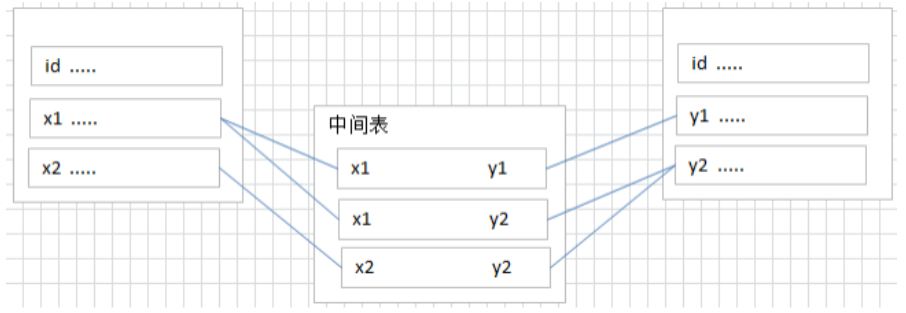
要表示多对多关系,必须创建第三个表,该表通常称为 联接表 ,它将多对多关系划分为两个一对多关系。将这两个表的主键都插入到第三个表中
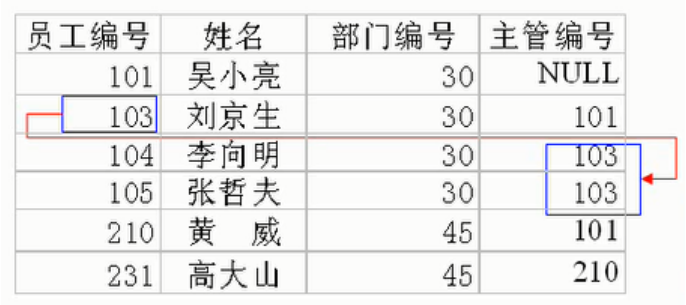
- 自我引用(Self reference)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号