# 数据结构(data structure)是带有结构特性的数据元素的集合,它研究的是数据的逻辑结构和数据的物理结构以及它们之间的相互关系,并对这种结构定义相适应的运算,设计出相应的算法,并确保经过这些运算以后所得到的新结构仍保持原来的结构类型
# 简述:数据结构是相互之间存在⼀种或多种特定关系的数据元素的集合,即带“结构”的数据元素的集合。“结构”就是指数据元素之间存在的关系
线性结构:各个结点具有线性关系,有且仅有⼀个开始结点和⼀个终端结点
栈、队列和串
⾮线性结构:各个结点之间具有多个对应关系,⼀个结点可能有多个直接前趋结点和多个直接后继结点
⼴义表、树结构和图结构
栈Stack
限制在表的⼀端进⾏插⼊和删除运算的线性表,通常称插⼊、删除的这⼀端为栈顶(Top),另⼀端为栈底(Bottom)
先进后出
队列Queue
限制在表的⼀端进⾏插⼊,⽽在另⼀端进⾏删除。允许删除的⼀端称为队头(front),允许插⼊的⼀端称为队尾(rear)
先进先出
数组Array
最基本的数据结构, 它是将具有相同类型的若⼲变量有序地组织在⼀起的集合
根据下标进⾏操作
链表Linked List
数据元素按照链式存储结构进⾏存储的数据结构,这种存储结构具有在物理上存在⾮连续的特点,每个数据结点包括数据域和指针域两部分。其中指针域保存了数据结构中下⼀个元素存放的地址
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)⽽直接进⾏访问的数据结构。也就是说,它通过把关键码值映射到表中⼀个位置来访问记录,以加快查找的速度 。这个映射函数叫做散列函数,存放记录的数组叫做散列表。 给定表M,存在函数f(key),对任意给定的关键字值key,代⼊函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数
散列函数 能使对⼀个数据序列的访问过程更加迅速有效,通过散列函数,数据元素将被更快地定位
# 是由⼀组链表构成,每个链表都可以看做是⼀个“桶”,我们将所有的元素通过散列的⽅式放到具体的不同的桶中
# 插⼊元素时,⾸先将其键传⼊⼀个哈希函数,函数通过散列的⽅式告知元素属于哪个“桶”,然后在相应的链表插⼊元素
# 查找或删除元素时,⽤同们的⽅式先找到元素的“桶”,然后遍历相应的链表,直到发现我们想要的元素
注意:
因为每个“桶”都是⼀个链表,如果表变得太⼤,它的性能将会降低
哈希扩容:Bucket桶不够的话需要重新扩容,历史的数据需要重新hash
哈希冲突碰撞: 不同的元素经过hash后命中相同的位置
List 有序、重复的集合
常⻅的List有ArrayList、Vector、LinkedList等类
Set ⽆序、不可重复
常⻅Set接⼝的实现类有HashSet,LinedHashSet和TreeSet这⼏类
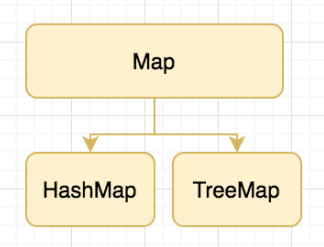
Map 键值对存储
常⻅的Map接⼝实现类有HashMap和TreeMap
Collection接⼝有两个主要的⼦类List和Set,但Map不是Collection的⼦类,因为其本身就是⼀个顶层接⼝
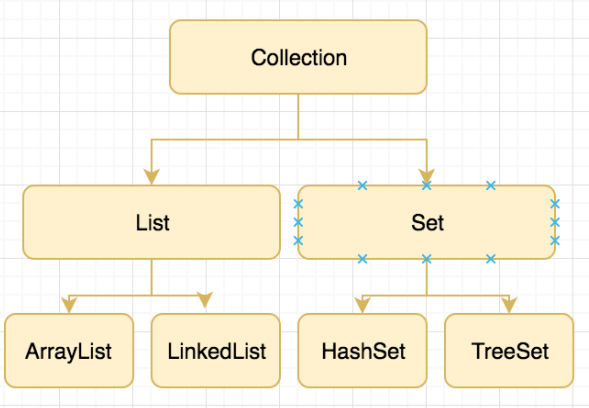
List接⼝是⼀个有序的 Collection,线性列表接⼝,能够精确的控制每个元素插⼊的位置,能够通过索引(类似于数组的下标)来访问List中的元素,第⼀个元素的索引为 0,⽽且允许有相同的元素,接⼝存储⼀组不唯⼀,有序(插⼊顺序)的对象
ArrayList
基于数组实现,是⼀个动态的数组队列,但它和Java中的数组⼜不⼀样,它的容量可以⾃动增⻓
可以存储任意多的对象,但是只能存储对象,不能存储原⽣数据类型例如int
LinkedList
基于的数据结构是链表,⼀个双向链表,链表数据结构的特点是每个元素分配的空间不必连续
插⼊和删除元素时速度⾮常快,但访问元素的速度较慢
//创建对象,LinkedList和ArrayList api⼀样
List<String> list = new ArrayList<>();
//往容器⾥⾯添加对象
list.add("jack");
//根据索引获取元素
list.get(index);
//更新⼀个元素
list.set(index, “⼩滴课堂”);
//返回⼤⼩
list.size();
//根据索引删除⼀个元素
list.remove(index);
//根据对象删除元素
list.remove("jack");
//清空元素
list.clear();
//是否为空
list.isEmpty();
//LinkedList特有api
//获取第⼀个元素
list.getFirst();
//获取最后⼀个元素
list.getLast();
两个都是List的接⼝,两个都是⾮线程安全的
ArrayList是基于动态数组的数据结构,⽽LinkedList是基于链表的数据结构
对于随机访问get和set(查询操作),ArrayList要优于LinkedList,因为LinkedList要移动指针
对于增删操作(add和remove),LinkedList优于ArrayList
底层就是⼀个数组结构,数组中的每⼀项⼜是⼀个链表,即数组和链表的结合体
Table是数组,数组的元素是Entry
Entry元素是⼀个key-value键值对,它持有⼀个指向下⼀个 Entry元素的引⽤,table数组的每个Entry元素同时也作为当前Entry链表的⾸节点,也指向了该链表的下⼀个Entry元素
HashMap
# ⼀个散列桶(数组和链表),它存储的内容是键值对(key-value)映射
# 是基于hashing的原理,使⽤put(key, value)存储对象到HashMap中,使⽤get(key)从 HashMap中获取对象。当put()⽅法传递键和值时,会先对键调⽤hashCode()⽅法,计算并返回的hashCode是用于找到Map数组的bucket位置来储存Entry对象的,是⾮线程安全的,所以HashMap操作速度很快
TreeMap
# 在数据的存储过程中,能够⾃动对数据进⾏排序,实现了SotredMap接⼝,它是有序的 集合
# TreeMap使⽤的存储结构是平衡⼆叉树,也称为红⿊树
# 默认排序规则:按照key的字典顺序来排序(升序),也可以⾃定义排序规则,要实现Comparator接⼝
Map<String,String> map = new HashMap<>();
//往map⾥⾯放key - value;
map.put("⼩明","⼴东⼴州");
map.put("⼩东","⼴东深圳");
//根据key获取value
map.get("⼩东");
//判断是否包含某个key
map.containsKey("⼩明");
//返回map的元素数量
map.size();
//清空容器
map.clear();
//获取所有value集合
map.values();
//返回所有key的集合
map.keySet()
//返回⼀个Set集合,集合的类型为Map.Entry , 是Map声明的⼀个内部接⼝,接⼝为泛型,定
义为Entry<K,V>,
//它表示Map中的⼀个实体(⼀个key-value对),主要有getKey(),getValue⽅法
Set<Map.Entry<String,String>> entrySet = map.entrySet();
//判断map是否为空
map.isEmpty();
HashMap可实现快速存储和检索,但缺点是包含的元素是⽆序的,适⽤于在Map中插⼊、删除和定位元素
TreeMap能便捷的实现对其内部元素的各种排序,但其⼀般性能⽐HashMap差,适⽤于按⾃然顺序或⾃定义顺序遍历键(key)
- jdk1.7和jdk1.8中HashMap的主要区别
底层实现由之前的 “数组+链表” 改为 “数组+链表+红⿊树”
当链表节点较少时仍然是以链表存在,当链表节点较多时,默认是⼤于8时会转为红⿊树
# Set相对于List是简单的⼀种集合,具有和 Collection 完全⼀样的接⼝,只是实现上不同,Set不保存重复的元素,存储⼀组唯⼀,⽆序的对象。
# Set中的元素是不能重复的, 实现细节可以参考Map,因为这些Set的实现都是对应的Map的⼀种封装。⽐如HashSet是对HashMap的封装,TreeSet对应TreeMap
# Set底层是⼀个HashMap,由于HashMap的put()⽅法是⼀个键值对,当新放⼊HashMap的Entry中key 与集合中原有Entry的key相同(hashCode()返回值相等,通过equals⽐较也返回true),新添加的Entry的value会将覆盖原来Entry的value,但key不会有任何改变
# 允许包含值为null的元素,但最多只能有⼀个null元素
HashSet
HashSet类按照哈希算法来存取集合中的对象,存取速度⽐较快
对应的Map是HashMap,是基于Hash的快速元素插⼊,元素⽆顺序
TreeSet
TreeSet类实现了SortedSet接⼝,能够对集合中的对象进⾏排序
//创建对象,HashSet和TreeSet api⼀样
Set<Integer> set = new HashSet<>();
//往容器⾥⾯添加对象
set.add("jack");
//清空元素
set.clear();
//返回⼤⼩
set.size();
//根据对象删除元素
set.remove("jack");
//是否为空
set.isEmpty();
HashSet不能保证元素的排列顺序,TreeSet是SortedSet接⼝的唯⼀实现类,可以确保集合元素处于排序状态
HashSet底层⽤的是哈希表,TreeSet采⽤的数据结构是红⿊树(红⿊树是⼀种特定类型的⼆叉树)
HashSet中元素可以是null,但只能有⼀个,TreeSet不允许放⼊null
⼀般使⽤HashSet,如果需要排序的功能时,才使⽤TreeSet(性能原因)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号