基于密度峰值的聚类(DPCA)
1、背景介绍
密度峰值算法(Clustering by fast search and find of density peaks)由Alex Rodriguez和Alessandro Laio于2014年提出,并将论文发表在Science上。Science上的这篇文章《Clustering by fast search and find of density peaks》主要讲的是一种基于密度的聚类方法,基于密度的聚类方法的主要思想是寻找被低密度区域分离的高密度区域。 密度峰值算法(DPCA)基于这样的假设:(1)类簇中心点的密度大于周围邻居点的密度;(2)类簇中心点与更高密度点之间的距离相对较大。因此,DPCA主要有两个需要计算的量:第一,局部密度;第二,与高密度点之间的距离。
2、局部密度
数据对象的局部密度
定义为:
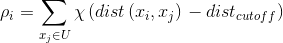
其中,表示截断距离
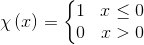 ,这个公式的含义是说找到与第
,这个公式的含义是说找到与第个数据点之间的距离小于截断距离
的数据点的个数,并将其作为第i个数据点真的密度。
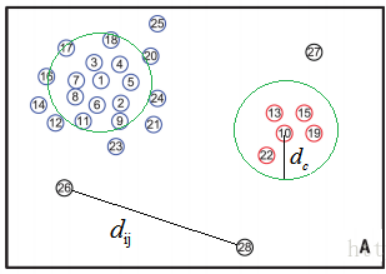
3、定义聚类中心距离
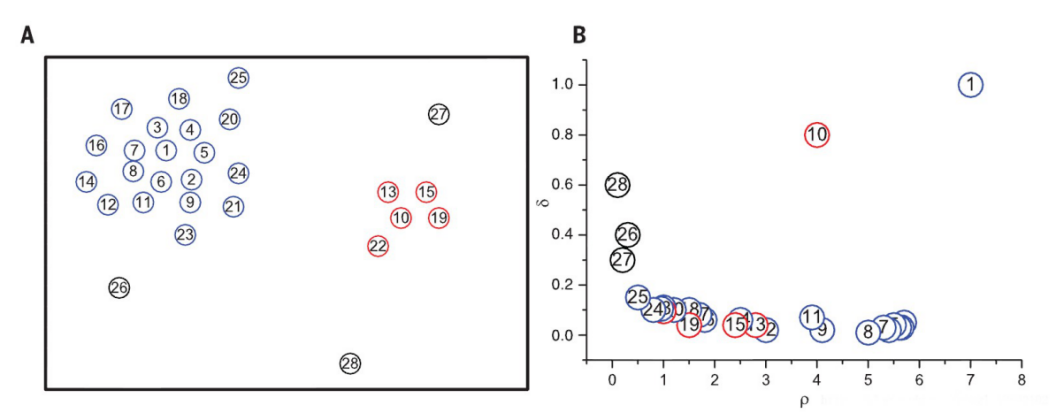
密度峰聚类算法的巧妙之处:就是在于聚类中心距离 δi的选定。根据局部密度的定义,我们可以计算出上图中每个点的密度,依照密度确定聚类中心距离 δi。
1.首先将每个点的密度从大到小排列: ρi > ρj > ρk > ….;密度最大的点的聚类中心距离与其他点的聚类中心距离的确定方法是不一样的;
2.先确定密度最大的点的聚类中心距离–i点是密度最大的点,它的聚类中心距离δiδi等于与i点最远的那个点n到点i的直线距离 d(i,n);
3. 再确定其他点的聚类中心距离——其他点的聚类中心距离是等于在密度大于该点的点集合中,与该点距离最小的的那个距离。例如i、j、k的密度都比n点的密度大,且j点离n点最近,则n点的聚类中心距离等于d(j,n);
4. 依次确定所有的聚类中心距离δ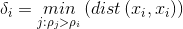
4、聚类效果
将所有点的聚类中心密度都统计出来后,将其值按 δi和pi作为坐标轴作图可以得到如图所示结果。可以看到图中1,10两个聚类中心同时远离坐标轴。普通点则是靠近p轴,异常点靠近 δ轴。
5、基于python的实现:
python代码如下,其中要引入numpy等一些包,pycharm中引入包还是比较简单的。
# -*- coding:utf-8 -*- # -*- python3.5 import numpy as np import matplotlib.pyplot as plt import sklearn.datasets as ds import matplotlib.colors min_distance = 4.6 # 邻域半径 points_number = 40 # 随机点个数 # 计算各点间距离、各点点密度(局部密度)大小 def get_point_density(datas,labers,min_distance,points_number): # 将numpy.ndarray格式转为list格式,并定义元组大小 data = datas.tolist() laber = labers.tolist() distance_all = np.random.rand(points_number,points_number) point_density = np.random.rand(points_number) # 计算得到各点间距离 for i in range(points_number): for n in range(points_number): distance_all[i][n] = np.sqrt(np.square(data[i][0]-data[n][0])+np.square(data[i][1]-data[n][1])) print('距离数组:\n',distance_all,'\n') # 计算得到各点的点密度 for i in range(points_number): x = 0 for n in range(points_number): if distance_all[i][n] > 0 and distance_all[i][n]< min_distance: x = x+1 point_density[i] = x print('点密度数组:', point_density, '\n') return distance_all, point_density # 计算点密度最大的点的聚类中心距离 def get_max_distance(distance_all,point_density,laber): point_density = point_density.tolist() a = int(max(point_density)) # print('最大点密度',a,type(a)) b = laber[point_density.index(a)] # print("最大点密度对应的索引:",b,type(b)) c = max(distance_all[b]) # print("最大点密度对应的聚类中心距离",c,type(c)) return c # 计算得到各点的聚类中心距离 def get_each_distance(distance_all,point_density,data,laber): nn = [] for i in range(len(point_density)): aa = [] for n in range(len(point_density)): if point_density[i] < point_density[n]: aa.append(n) # print("大于自身点密度的索引",aa,type(aa)) ll = get_min_distance(aa,i,distance_all, point_density,data,laber) nn.append(ll) return nn # 获得:到点密度大于自身的最近点的距离 def get_min_distance(aa,i,distance_all, point_density,data,laber): min_distance = [] """ 如果传入的aa为空,说明该点是点密度最大的点,该点的聚类中心距离计算方法与其他不同 """ if aa != []: for k in aa: min_distance.append(distance_all[i][k]) # print('与上各点距离',min_distance,type(nn)) # print("最小距离:",min(min_distance),type(min(min_distance)),'\n') return min(min_distance) else: max_distance = get_max_distance(distance_all, point_density, laber) return max_distance def get_picture(data,laber,points_number,point_density,nn): # 创建Figure fig = plt.figure() # 用来正常显示中文标签 matplotlib.rcParams['font.sans-serif'] = [u'SimHei'] # 用来正常显示负号 matplotlib.rcParams['axes.unicode_minus'] = False # 原始点的分布 ax1 = fig.add_subplot(211) plt.scatter(data[:,0],data[:,1],c=laber) plt.title(u'原始数据分布') plt.sca(ax1) for i in range(points_number): plt.text(data[:,0][i],data[:,1][i],laber[i]) # 聚类后分布 ax2 = fig.add_subplot(212) plt.scatter(point_density.tolist(),nn,c=laber) plt.title(u'聚类后数据分布') plt.sca(ax2) for i in range(points_number): plt.text(point_density[i],nn[i],laber[i]) plt.show() def main(): # 随机生成点坐标 data, laber = ds.make_blobs(points_number, centers=points_number, random_state=0) print('各点坐标:\n', data) print('各点索引:', laber, '\n') # 计算各点间距离、各点点密度(局部密度)大小 distance_all, point_density = get_point_density(data, laber, min_distance, points_number) # 得到各点的聚类中心距离 nn = get_each_distance(distance_all, point_density, data, laber) print('最后的各点点密度:', point_density.tolist()) print('最后的各点中心距离:', nn) # 画图 get_picture(data, laber, points_number, point_density, nn) """ 距离归一化:就把上面的nn改为:nn/max(nn) """ if __name__ == '__main__': main()
代码运行效果如下图:
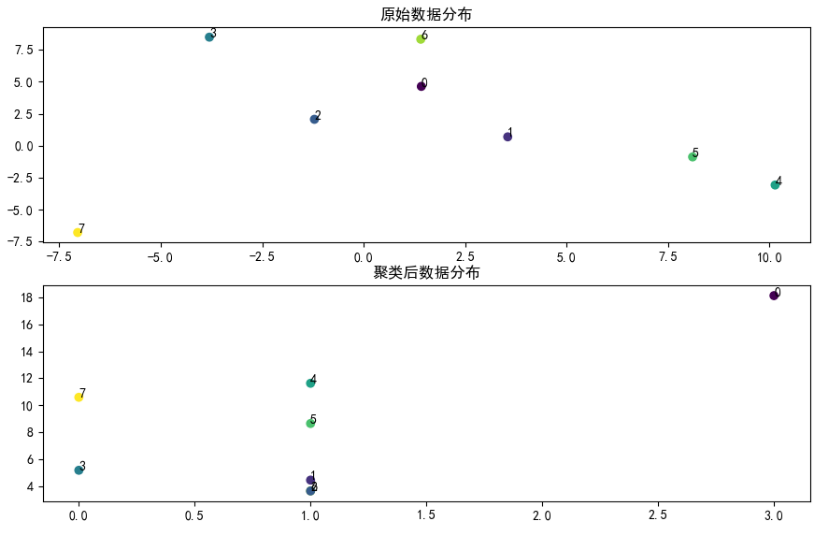
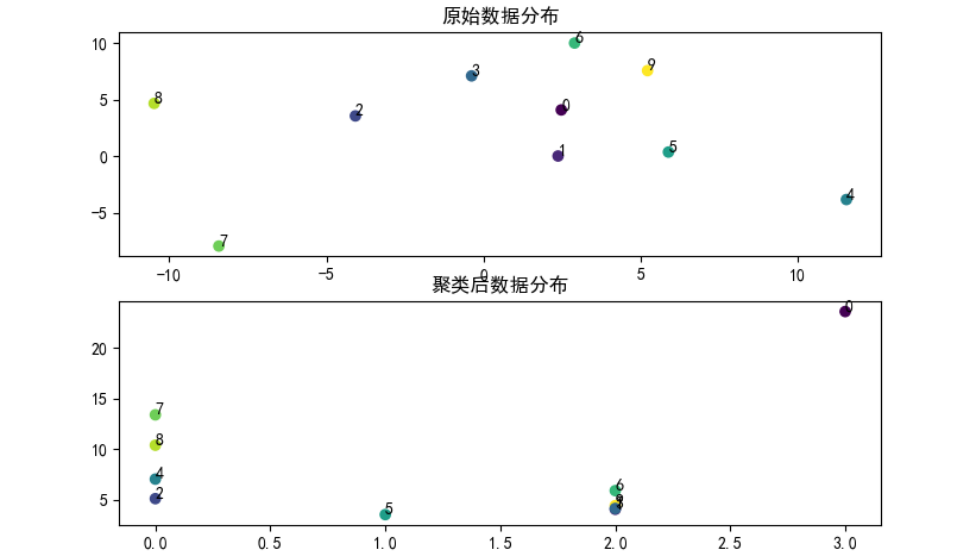
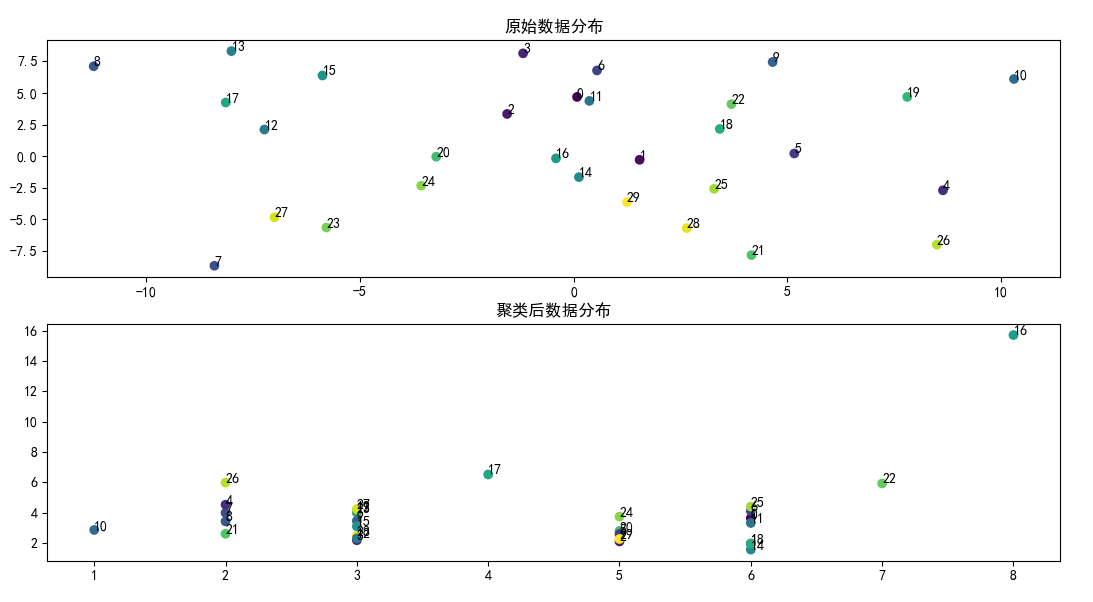

 浙公网安备 33010602011771号
浙公网安备 33010602011771号