PyTorch实现Seq2Seq机器翻译
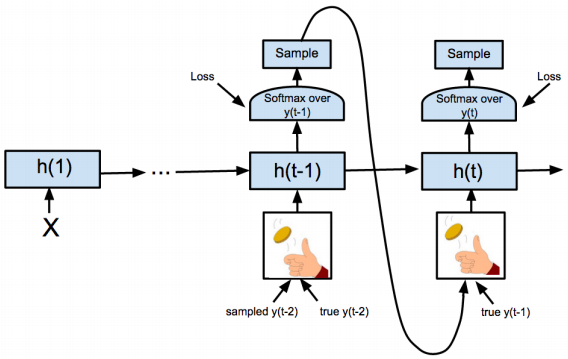
Seq2Seq在训练阶段和预测阶段稍有差异。如果Decoder第一个预测预测的输出就错了,它会导致“蝴蝶效应“,影响后面全部内容。为了解决这个问题,在训练时,Decoder每个时间步的输入不全是上一个时间步的输出,而以一定的概率选择真实值作为输入。
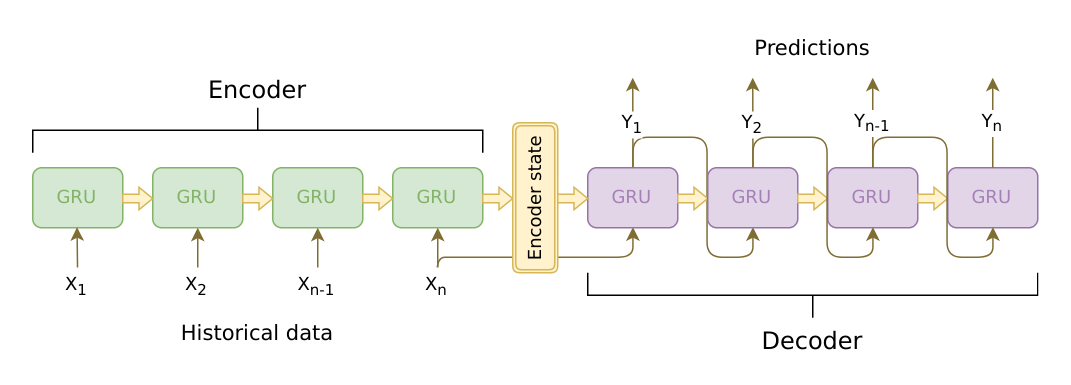
通常,Encoder的输入序列需要添加一个终止符“<eos>”,可以不需要起始符“<sos>”。Decoder输入序列在训练时则需要添加一个起始符和终止符,在预测时,Decoder接收一个起始符“<sos>”,它类似一个信号,告诉Decoder可以开始工作了,当输出终止符时我们就可以停下来(通常可以再设置一个最大输出长度,防止Decoder一直不输出终止符)。
终止符和起始符只要不会出现在原始序列中就可以了,也可以用<start>和<stop>,<bos>和<eos>,<s>和</s>等等
Attention机制
这里介绍的是LuongAttention
整个输入序列的信息被Encoder编码为固定长度的向量,类似”有损压缩”。这个向量无法完全表达整个输入序列的信息。另外,随着输入长度的增加,这个固定长度的向量,会逐渐丢失更多信息。
以英中翻译任务为例,我们翻译的时候,虽然要考虑上下文,但每个时间步的输出,不同单词的贡献是不同的。考虑下面这个句子对:
She doesn't like soccer.
她不喜欢足球。
我们翻译“她”时,其实只需要考虑“She”就好了,“足球”也是同理。简单说,Attention机制让我们的输出时,关注输入序列中的某一些部位就可以了,即让输入的单词有不同的贡献。
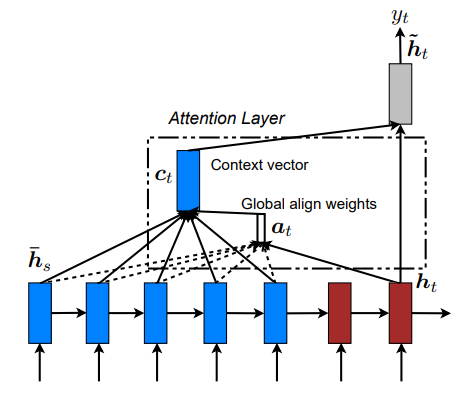
根据原始论文,我们定义以下符号:在每个时间步$t$,Decoder当前时间步的隐藏状态$h_t$,整个Encoder输出的隐藏状态$\bar h_s$,权重数值$a_t$,上下文向量$c_t$。
注意力值通过以下方式计算:
$$
score(h_t,\bar h_s)=
\begin{cases}
h_t^T\bar h_s & \text{dot} \\
h_t^TW_a\bar h_s & \text{general} \\
v_a^T\tanh (W_a[h_t;\bar h_s]) & \text{concat}
\end{cases}
$$
其中权重根据以下公式计算(其实就是用softmax归一化了)
$$
a_t(s)=align(h_t, \bar h_s)=\frac {exp(score(h_t, \bar h_s))}{\sum_{s'} exp(score(h_t, \bar h_{s'}))}
$$
上下文向量根据权重,对Encoder输出隐藏状态的每个时间步进行加权平均
$$
c_t=\sum_s a_t(s) \cdot \bar h_s
$$
与Decoder当前时间步的隐藏状态拼接,计算一个注意力隐藏状态,其计算公式如下
$$
\tilde h_t = \tanh (W_c[c_t;h_t])
$$
再根据这个注意力隐藏状态预测输出结果
$$
y = \text{softmax}(W_s\tilde h_t)
$$
部分代码
参考了官方文档和github上的一些代码,使用Attention机制和不使用Attention机制的翻译器都实现了一下。这里只对使用了Attention机制的翻译器的部分代码进行说明,完整代码如下
https://gitee.com/dogecheng/python/blob/master/pytorch/Seq2SeqForTranslation.ipynb
在计算出注意力值后,Decoder将其与Encoder输出的隐藏状态进行加权平均,得到上下文向量context.
再将context与Decoder当前时间步的隐藏状态拼接,经过tanh。最后用softmax预测最终的输出概率。
class Decoder(nn.Module): def forward(self, token_inputs, last_hidden, encoder_outputs): ... # encoder_outputs = [input_lengths, batch, hid_dim * n directions] attn_weights = self.attn(gru_output, encoder_outputs) # attn_weights = [batch, 1, sql_len] context = attn_weights.bmm(encoder_outputs.transpose(0, 1)) # [batch, 1, hid_dim * n directions] gru_output = gru_output.squeeze(0) # [batch, n_directions * hid_dim] context = context.squeeze(1) # [batch, n_directions * hid_dim] concat_input = torch.cat((gru_output, context), 1) # [batch, n_directions * hid_dim * 2] concat_output = torch.tanh(self.concat(concat_input)) # [batch, n_directions*hid_dim] output = self.out(concat_output) # [batch, output_dim] output = self.softmax(output) ...
训练时,根据use_teacher_forcing设置的阈值,决定下一时间步的输入是上一时间步的预测结果还是来自数据的真实值
if self.predict: """ 预测代码 """ ... else: max_target_length = max(target_lengths) all_decoder_outputs = torch.zeros((max_target_length, batch_size, self.decoder.output_dim), device=self.device) for t in range(max_target_length): use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False if use_teacher_forcing: # decoder_output = [batch, output_dim] # decoder_hidden = [n_layers*n_directions, batch, hid_dim] decoder_output, decoder_hidden, decoder_attn = self.decoder( decoder_input, decoder_hidden, encoder_outputs ) all_decoder_outputs[t] = decoder_output decoder_input = target_batches[t] # 下一个输入来自训练数据 else: decoder_output, decoder_hidden, decoder_attn = self.decoder( decoder_input, decoder_hidden, encoder_outputs ) # [batch, 1] topv, topi = decoder_output.topk(1) all_decoder_outputs[t] = decoder_output decoder_input = topi.squeeze(1).detach() # 下一个输入来自模型预测
损失函数通过使用设置ignore_index不计padding部分的损失
loss_fn = nn.NLLLoss(ignore_index=PAD_token) loss = loss_fn( all_decoder_outputs.reshape(-1, self.decoder.output_dim), # [batch*seq_len, output_dim] target_batches.reshape(-1) # [batch*seq_len] )
Seq2Seq在预测阶段每次只输入一个样本,输出其翻译结果,对应forward()函数中的内容如下,当Decoder输出终止符或输出长度达到所设定的阈值时便停止。
class Seq2Seq(nn.Module): ... def forward(self, input_batches, input_lengths, target_batches=None, target_lengths=None, teacher_forcing_ratio=0.5): ... if self.predict: # 一次只输入一句话 assert batch_size == 1, "batch_size of predict phase must be 1!" output_tokens = [] while True: decoder_output, decoder_hidden, decoder_attn = self.decoder( decoder_input, decoder_hidden, encoder_outputs ) # [1, 1] topv, topi = decoder_output.topk(1) decoder_input = topi.squeeze(1).detach() output_token = topi.squeeze().detach().item() if output_token == EOS_token or len(output_tokens) == self.max_len: break output_tokens.append(output_token) return output_tokens else: """ 训练代码 """ ...
部分实验结果,具体可以在notebook里看

参考资料
NLP FROM SCRATCH: TRANSLATION WITH A SEQUENCE TO SEQUENCE NETWORK AND ATTENTION
DEPLOYING A SEQ2SEQ MODEL WITH TORCHSCRIPT
Practical PyTorch: Translation with a Sequence to Sequence Network and Attention

 浙公网安备 33010602011771号
浙公网安备 33010602011771号