
Redis开发与运维 第11章 缓存设计
前言:
缓存能够有效的加速应用的读写速度,同时也可以降低后端负载,对日常应用开发至关重要。
本章介绍缓存使用技巧和设计方案,包括以下内容:
1、缓存的收益和成本分析
2、缓存更新策略的选择和使用场景
3、缓存粒度控制方法
4、穿透问题优化
5、无底洞问题优化
6、雪崩问题优化
7、热点key 重建优化
1 缓存的收益和成本
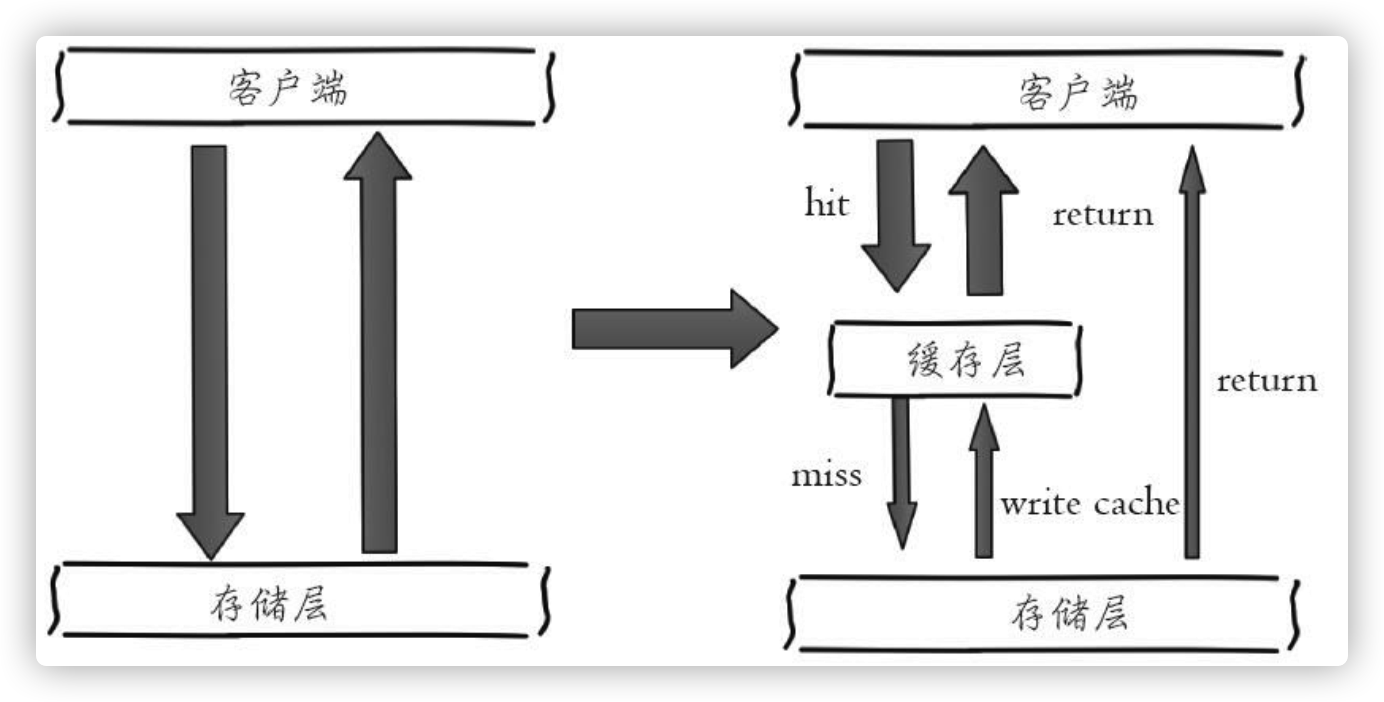
收益如下:
1、加速读写,缓存通常都是在内存的(redis,Memcahe)。而存储层(mysql)读写性能不如缓存。因此,可以通过缓存加速读写,优化用户体验。
2、降低后端负载,帮助后端减少访问量和负载计算(例如很复杂的SQL语句),在很大程度上降低了后端的负载。
成本如下:
1、数据不一致性:缓存层和存储层的数据存在一定时间窗口的不一致,时间窗口与更新策略有关。
2、代码维护成本:加入缓存后,需要同时处理缓存层和存储层的逻辑,增大了开发者维护代码的成本。
3、运维成本
2 缓存使用场景包含如下两种
1、开销大的复杂计算,以 Mysql 为例子,一些复杂的操作或者计算(例如大量的连表查询,一些分组计算),如果不加缓存,不但无法满足高并发量,同时也会给 Mysql 带来巨大的负担。
2、 加速请求响应
3 缓存更新策略
缓存中数据通常是有生命周期的,选用在指定的时间后被删除或更新,这样可以保证缓存空间在一个可控的范围。但是缓存中的数据和数据源中的真实数据有一段时间窗口的不一致,需要利用某些策略进行更新。
1、LRU/LFU/FIFO 算法剔除 [内存淘汰]
使用场景: 剔除算法通用于缓存使用超过最大的预设值的时候,剔除之前的一个缓存,加入新的一个缓存。
1、LRU (The Least Recently Used,最近最久未使用算法)是一种常见的缓存算法。如果一个数据在最近一段时间没有被访问,那么可以认为它在将来被访问的可能性很小。因此,当空间满的时候,最久没有被访问的数据最新被置换。
实现:双向链表 + 哈希表实现
LRU的淘汰规则是基于访问时间
2、LFU (Least Frequently Used)最近最少使用算法
如果一个数据在最近一段时间很少被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最小频率访问的数据最先被淘汰。
而LFU是基于访问次数的
3、FIFO (First in First out):先进先出 :如果一个数据最先进入缓存中,则应该最早淘汰掉。
一致性: 要清理哪些数据是由具体算法决定, 开发人员只能决定使用哪种算法, 所以数据的一致性是最差的。
维护成本 :算法不需要开发人员自己来实现,通常只需要配置最大 maxmemory 和对应的策略就行,开发人员只需要知道每种算法的含义,选择自己合适的算法。
2、超时剔除
超时剔除策略是:定期删除 + 惰性删除
定期删除:指的是 Redis 默认每隔 100ms 就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。
问题是:定期删除可能会导致很多过期 key 到了时间并没有被删除。因此需要惰性删除
惰性删除:在你获取某个 key 的时候,Redis 会检查一下,这个 key 如果设置了过期时间,过期时间是否过期了呢?如果过期就会删除。不会给你返回任何值。
问题:如果定期删除漏掉了很多过期的 key, 然后你没有及时的查询,也就没有走惰性删除,此时会导致大量的过期的 key 堆积在内存中,导致 Redis 内存快耗尽了。
需要走内存淘汰机制
内存淘汰机制:
场景:超时剔除通过给缓存设置过期时间,让其在过期后自动删除。
一致性:一段时间窗口内
维护成本:只需要设置 expire 过期时间,当然前提是应用方允许这段时间发生的数据不一致。
3、主动更新【一般是这个】
使用场景:
应用方对数据的一致性要求很高,需要在数据更新后,立即更新缓存,可以利用消息或者其他方式通知更新缓存。
一致性:
一致性最高,但如果主动更新发生了问题,那么这条数据很可能很长时间不会更新,所以建议和超时剔除一起使用。
维护成本:
维护成本:维护成本比较高,开发者需要自己来完成更新,并保证更新操作的正确性

4 最佳实践
低一致性业务建议配置最大内存和淘汰策略的方式使用。
高一致性业务可以结合使用超时剔除和主动更新, 这样即使主动更新出了问题, 也能保证数据过期时间后删除脏数据。
4 缓存粒度控制
如果现在需要将 Mysql 的用户信息使用 redis 缓存,可以执行如下操作。
1、从 MySQL 获取用户信息
select * from user where id = {id}
2、将用户信息缓存到 redis 中
set user:{id} 'select * from user where id = {id}'
3、加入用户表有 100 个列,需要缓存到什么维度呢?
缓存全部的列
set user:{id} 'select * from user where id={id}'
缓存部分列
set user:{id} 'select {importantColumn1}, {important Column2} ... {importantColumnN} from user where id={id}
上述问题就是缓存粒度问题。究竟是缓存全部还是缓存部分呢
1. 通用性:缓存全部数据比部分数据更加通用, 但从实际经验看, 很长时间内应用只需要几个重要的属性。
2. 空间占用: 缓存全部数据要比部分数据占用更多的空间
3. 代码维护: 全部数据的优势更加明显, 而部分数据一旦要加新字段需要全部数据的优势更加明显, 而部分数据一旦要加新字段需要
5 穿透优化
概念:缓存穿透是指查询一个根本不存在的数据,缓冲层和存储层都不会命中。
影响:1、缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。
2、缓存穿透问题可能会使后端存储负载过大,由于后端存储不具备高并发,甚至可能会造成后端存储宕机。
发现:通常可以在程序中分别统计总调用数,缓存层命中数,存储层命中数,如果发现大量的存储层命空。可能就是缓存穿透问题。
造成原因:1、自身代码业务或者数据出现问题
2、一些恶意攻击,爬虫等造成大量命空。
解决:
1、缓存空对象
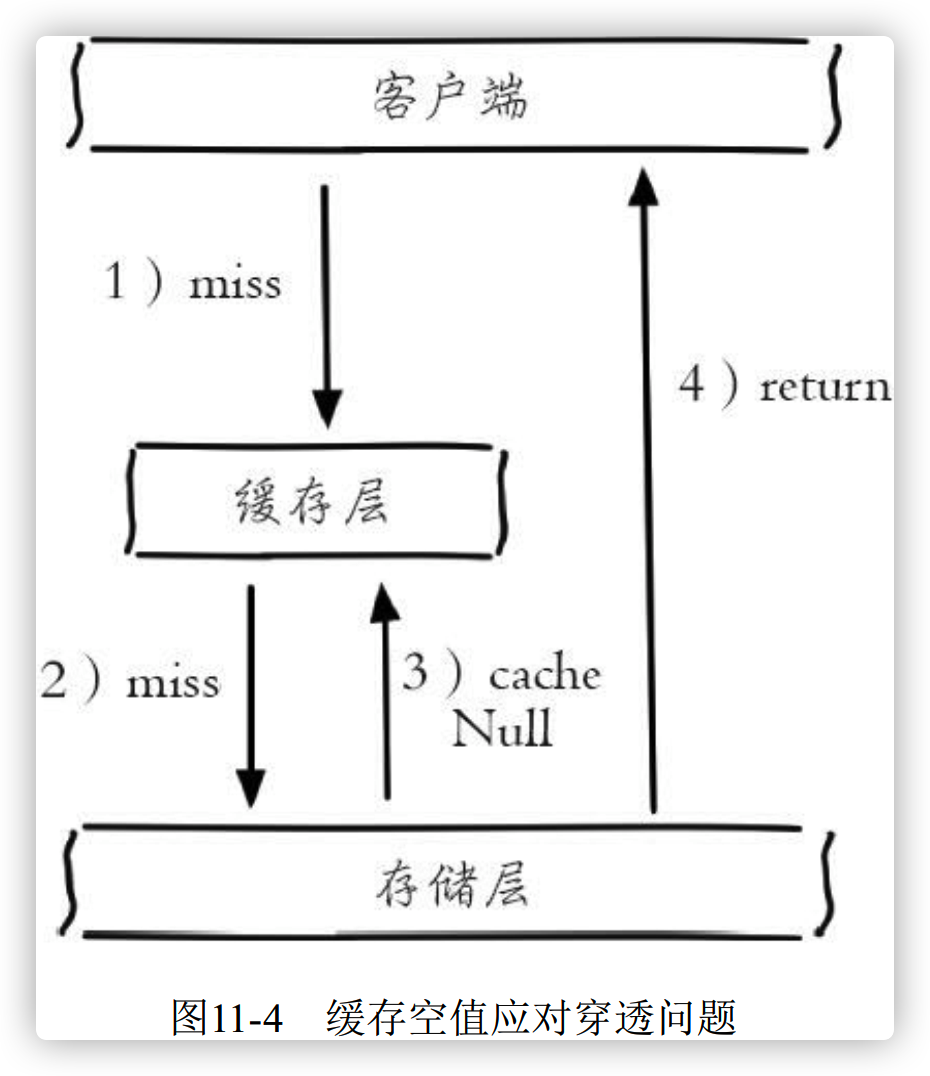
当第二步存储层不命中后,仍然将空对象保留到缓存层中,之后再访问这个数据将会缓存中获取,这样就保护了后端数据源
存在的问题:
1、空值做了缓存,意味着缓存中存了更多的键,需要更多的内存空间,(如果是攻击,问题更严重),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
2、缓存层和存储层的数据会有一段时间的窗口不一致,可能会对业务有一定的影响。
例如过期时间设置为5分钟, 如果此时存储层添加了这个数据, 这段时间就会出现缓存层和存储层数据不一致,因此更新数据的时候也要更新缓存。

String get(String key) { // 从缓存中获取数据 String cacheValue = cache.get(key); // 缓存为空 if (StringUtils.isBlank(cacheValue)) { // 从存储中获取 String storageValue = storage.get(key); cache.set(key, storageValue); // 如果存储数据为空, 需要设置一个过期时间(300秒) if (storageValue == null) { cache.expire(key, 60 * 5); }r eturn storageValue; } else { // 缓存非空 return cacheValue; } }
2、布隆过滤器拦截

在访问缓存层和存储层之前,将存在的 key 用布隆过滤器提前存起来。做第一层拦截。例如:一个推荐系统有 4 亿个用户id,每个小时算法工程师根据每个用户之前的历史行为计算出推荐数据放在存储层中,但是最新的用户由于没有历史行为,就会发生缓存穿透的行为,为此可以将所有推荐数据的用户做成布隆过滤器,如果布隆过滤器查找用户id不存在,就不会访问存储层,在一定程度上保护了存储层。
6 无底洞优化
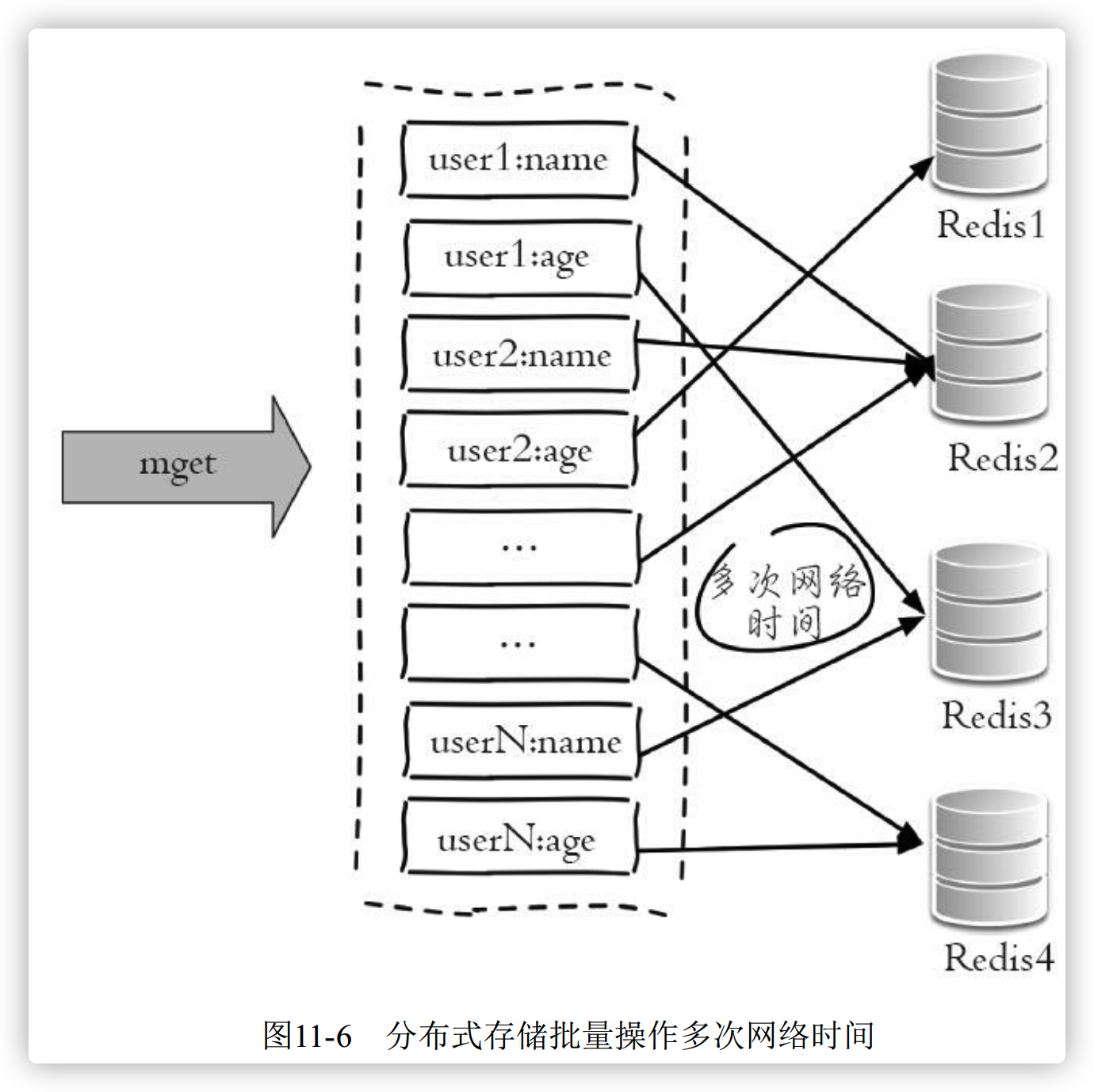
客户端一次批量操作会涉及多次网络操作,也就意味着批量操作会随着节点的增多,耗时不断增大。
网络连接变多,对节点的性能也有一定的影响。
用一句通俗的话总结就是,更多的节点不代表更高的性能,所谓”无底洞“就是说投入越多不一定产出越多。但是分布式又是不可以避免的,因为访问量和数据量越来越大,一个节点根本扛不住,所以如何高效在分布式缓存中批量操作是一个难点。
常见的IO优化思路:
1、命令本身的优化, 例如优化SQL语句等
2、减少网络通信次数
3、降低接入成本, 例如客户端使用长连/连接池、 NIO等
以 Redis 批量获取 n 个字符串为例子,有三种实现方法,
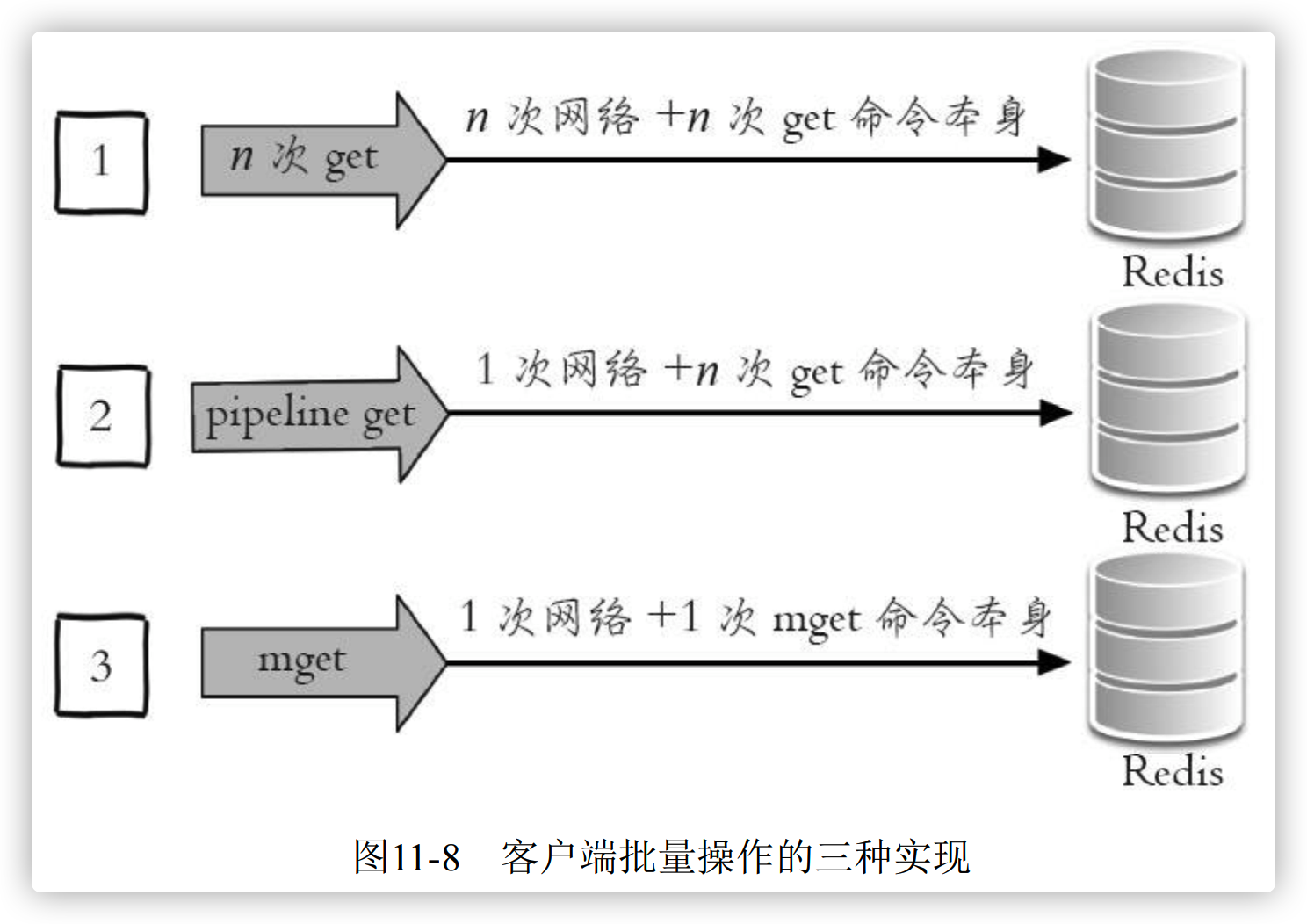
1、串行命令 [n 次 get]
由于n个key 是比较均匀的分布在 Redis Cluster 的各个节点上,因此无法使用 mget 命令一次性获取,所以通常来讲要获取 n 个 key 的值,最简单的的办法是一个个执行 n 个 get 命令,这种操作时间复杂度较高,它的操作时间 = n 次网络 + n次get 命令本身

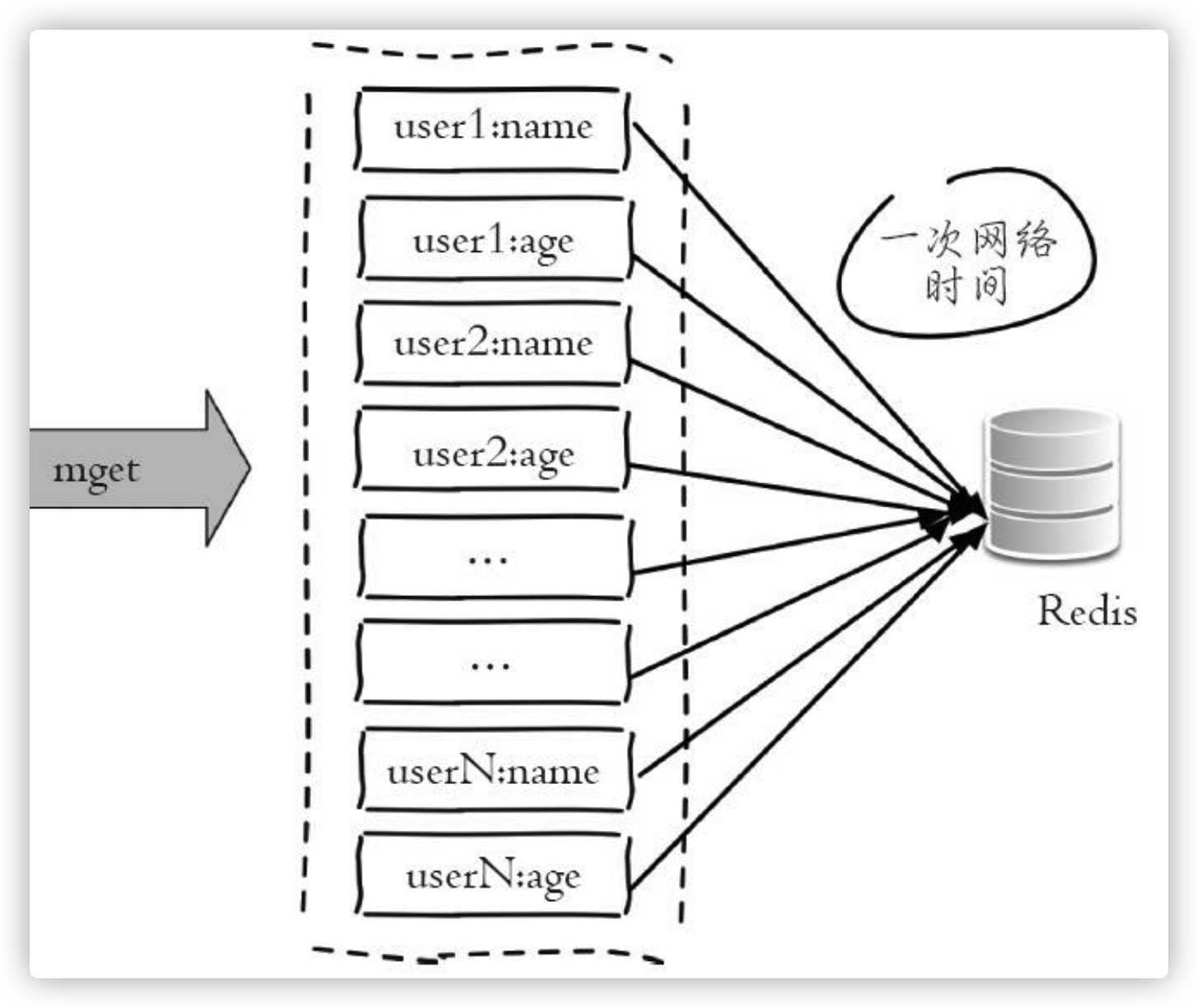
2、串行 IO
Redis Cluster使用CRC16算法计算出散列值, 再取对16383的余数就可以算出slot值, 同时10.5节我们提到过Smart客户端会保存slot和节点的对应关系, 有了这两个数据就可以将属于同一个节点的key进行归档, 得到每个节点的key子列表, 之后对每个节点执行mget或者Pipeline操作, 它的操作时间=node次网络时间+n次命令时间, 网络次数是node的个数, 整个过程如下图所示, 很明显这种方案比第一种要好很多, 但是如果节点数太多, 还是有一定的性能问题。
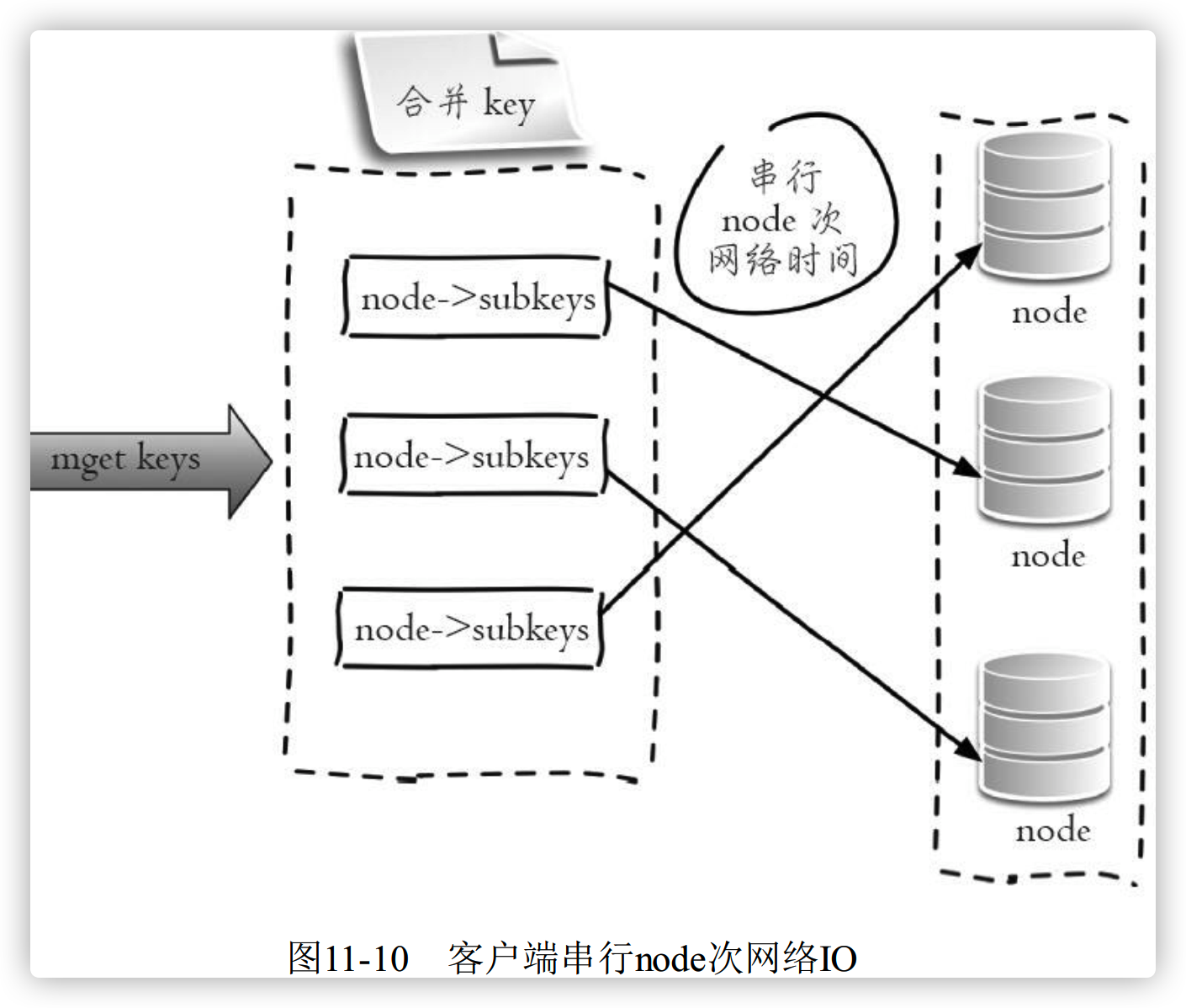
3、
7 雪崩优化
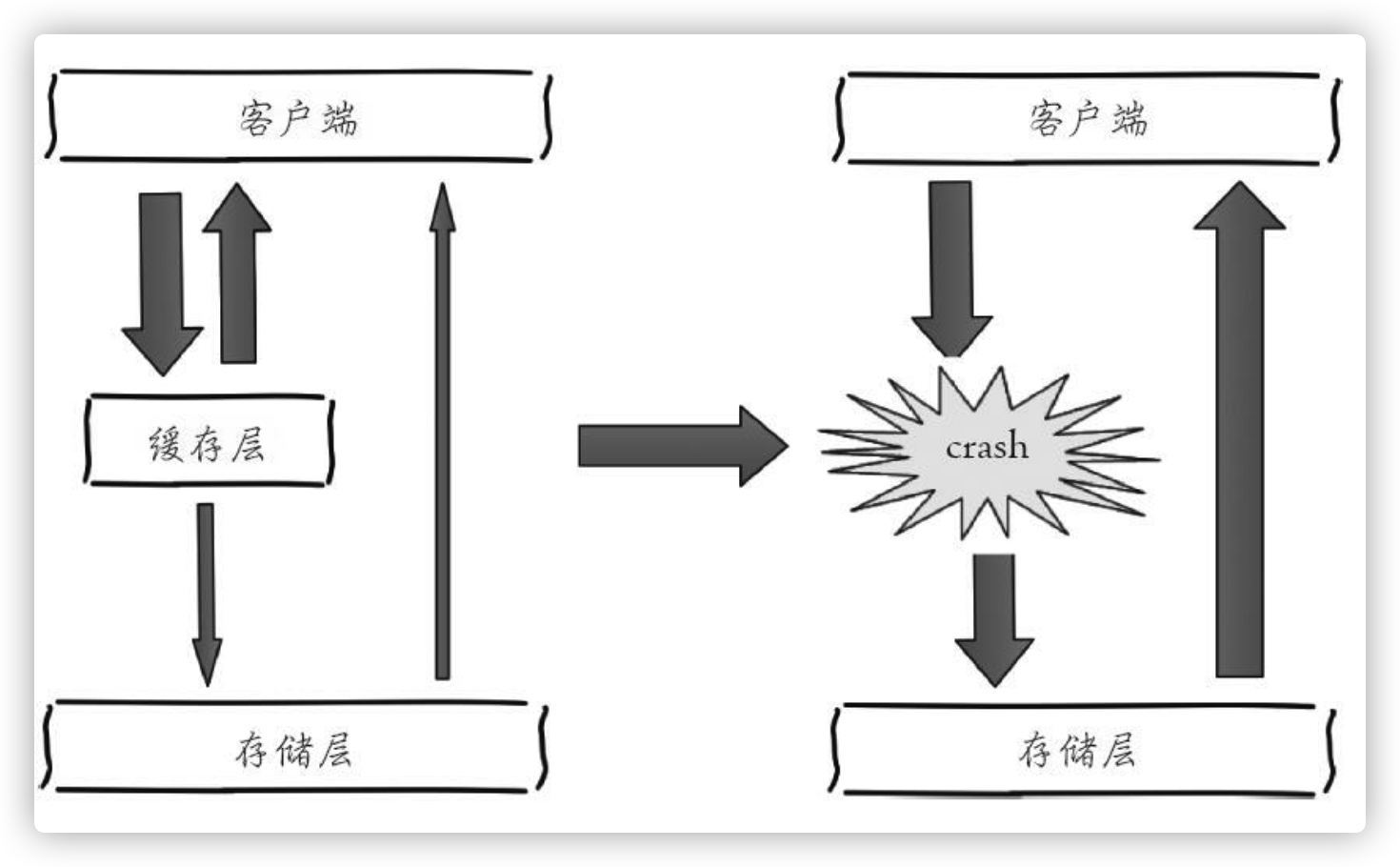
现象:由于缓存层承载着大量的请求,有效的保护了缓存层,但是如果缓存层由于某些原因不能提供服务,于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会级联宕机的情况。缓存宕机后,流量会像奔逃的野牛一样,打向后端存储。
预防和解决缓存问题
1、保证缓存层服务高可用性。如果缓存层涉及成高可用的,即使是个别节点,个别机器,甚至机房宕机,依然可以提供服务。
2、依赖隔离组件为后端限流并降级。让每种资源都单独运行在自己的线程池中, 即使个别资源出现了问题, 对其他服务没有影响。【未完】
3、提前演练。在项目上线前,演练缓存层宕掉后,应用以及后端的负载情况以及可能出现的问题,
8 热点 key 重建优化 【缓存击穿】
开发人员使用 缓存+过期时间 的策略既可以加速读写数据,有可以保证数据的定期更新,这种模式基本满足绝大部分需求,但是如果有两个问题同时出现,可能就会对应用造成致命的危害:
1、当前 key 是一个热点 key (例如一个热门的娱乐新闻),并发了非常大。
2、重建缓存不能再短时间内完成,可能是一个复杂计算,例如复杂的SQL,多次 IO , 多个依赖
在缓存失效的瞬间,有大量的线程来重建缓存,造成后端复杂过大,甚至可能会让应用崩溃
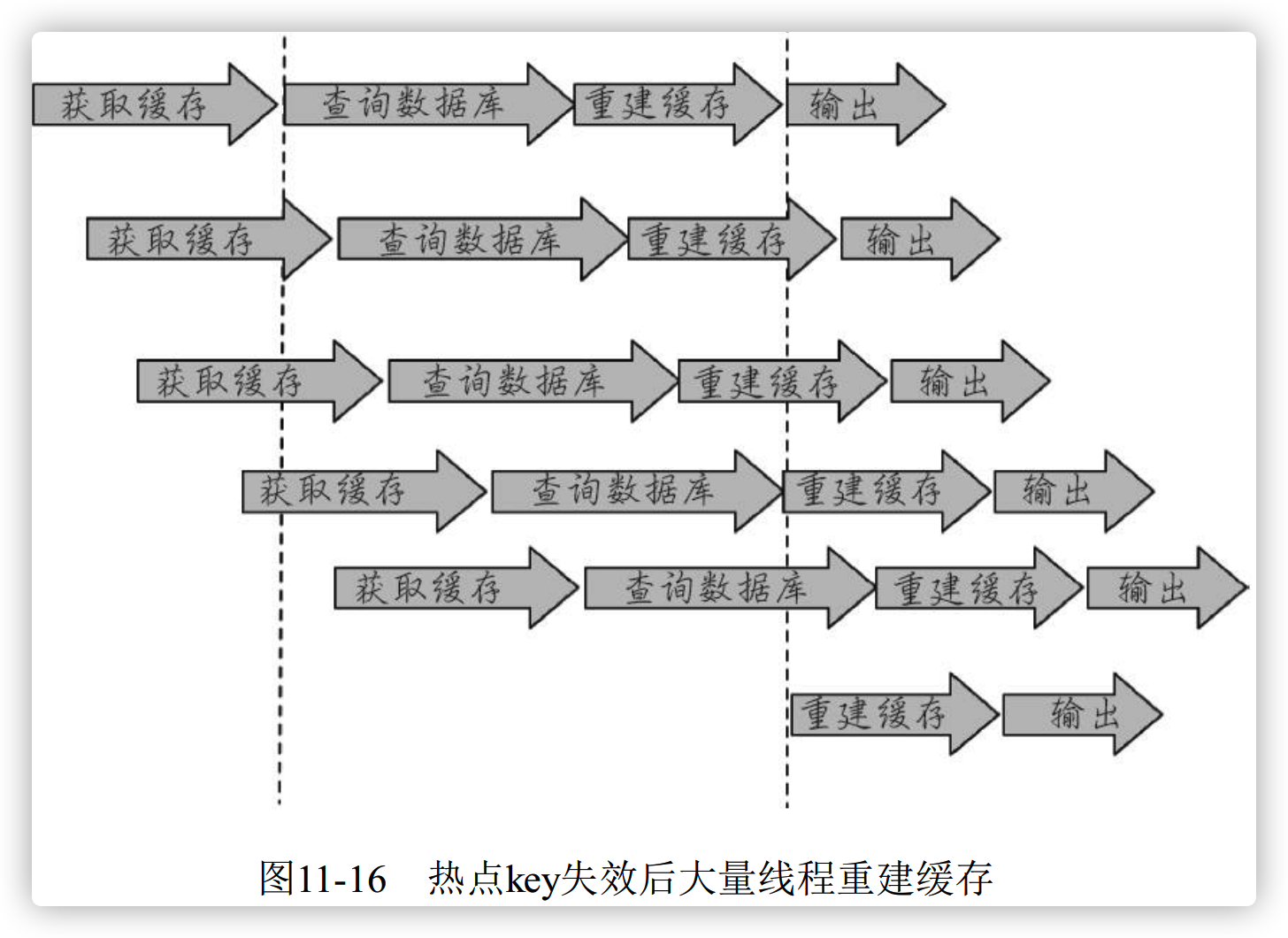
解决这个问题不能给系统带来更多的麻烦,所以需要指定如下目标:
1、减少重建缓存的次数
2、数据尽可能一致
3、较少的潜在危险
1、互斥锁(mutex key)
此方法只允许一个线程重建缓存,其他的线程等待重建缓存的线程执行完,重新从缓存中获取数据即可。
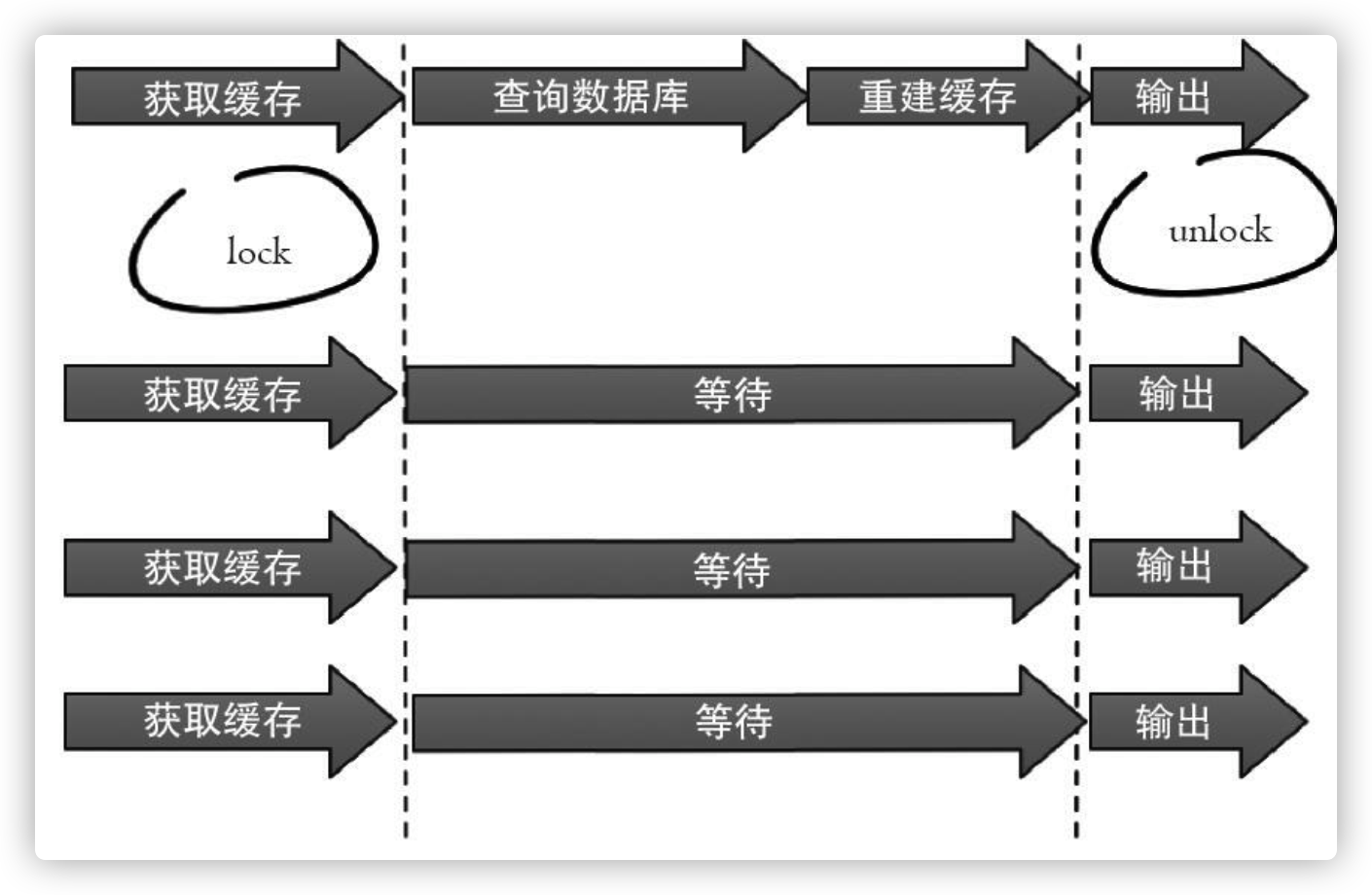
介绍一下:redis 的 setnx 命令
1、多个线程同时在在 redis 上创建同一个 key , 只有一个能成功,即获得锁
2、获取锁:原子性操作 set (推荐)方法,谁 set 成功谁将后的锁
下面代码使用Redis的setnx命令实现上述功能
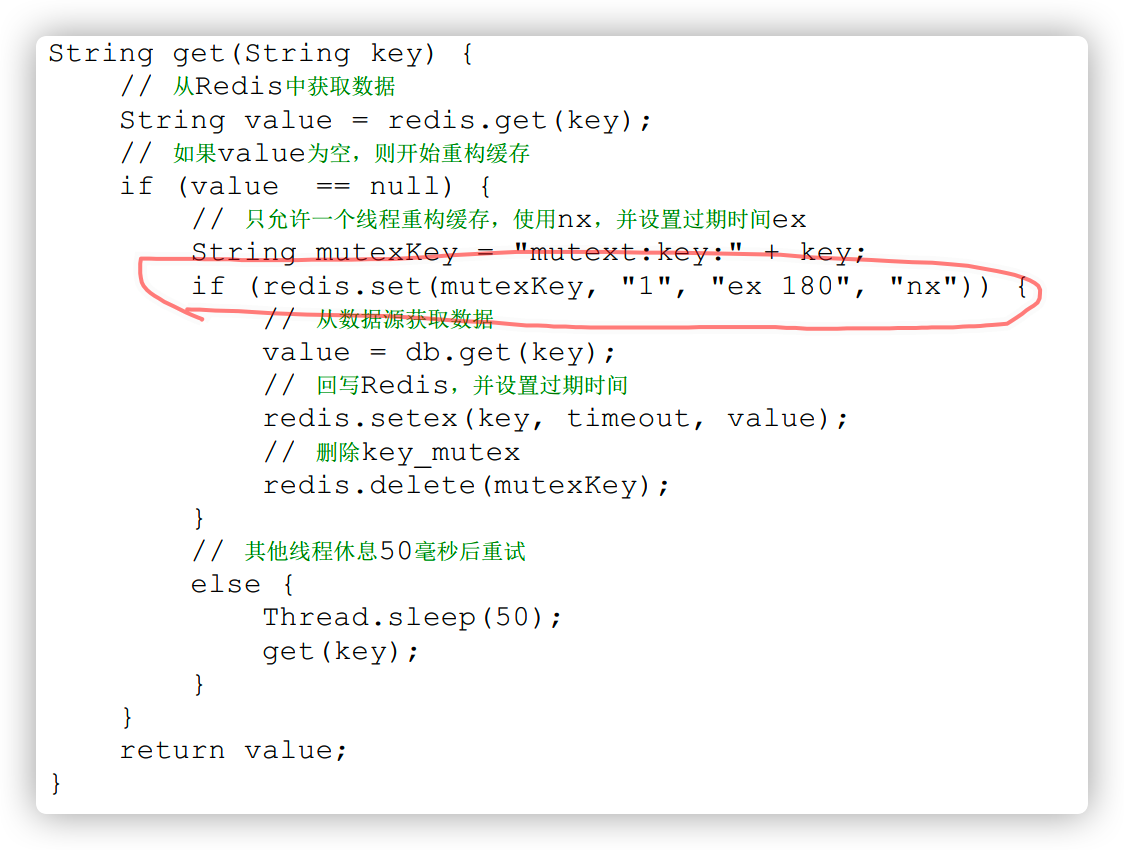
步骤:
1、从 Redis 获取数据,如果值不为空,则直接返回值
2、如果 set (nx 和 ex) 结果为 true , 说明此时没有其他线程重建缓存,那么当前线程执行缓存构建逻辑
3、如果 set (nx 和 ex) 结果为 false,说明此时正有其他线程正在执行构建缓存,其他当前线程休息(例如这里是50ms,取决于缓存构建的速度)后,重新执行函数,获取数据。
2、永远不过期
两层意思:
1、从缓存层面上看,确实没有设置过期时间,所以不会出现热点 key 过期产生的问题,也就是”物理“不过期
2、从功能层面上看,为每个 value 设置一个过期时间,当发现超过过期时间后,使用单独的线程构建缓存。
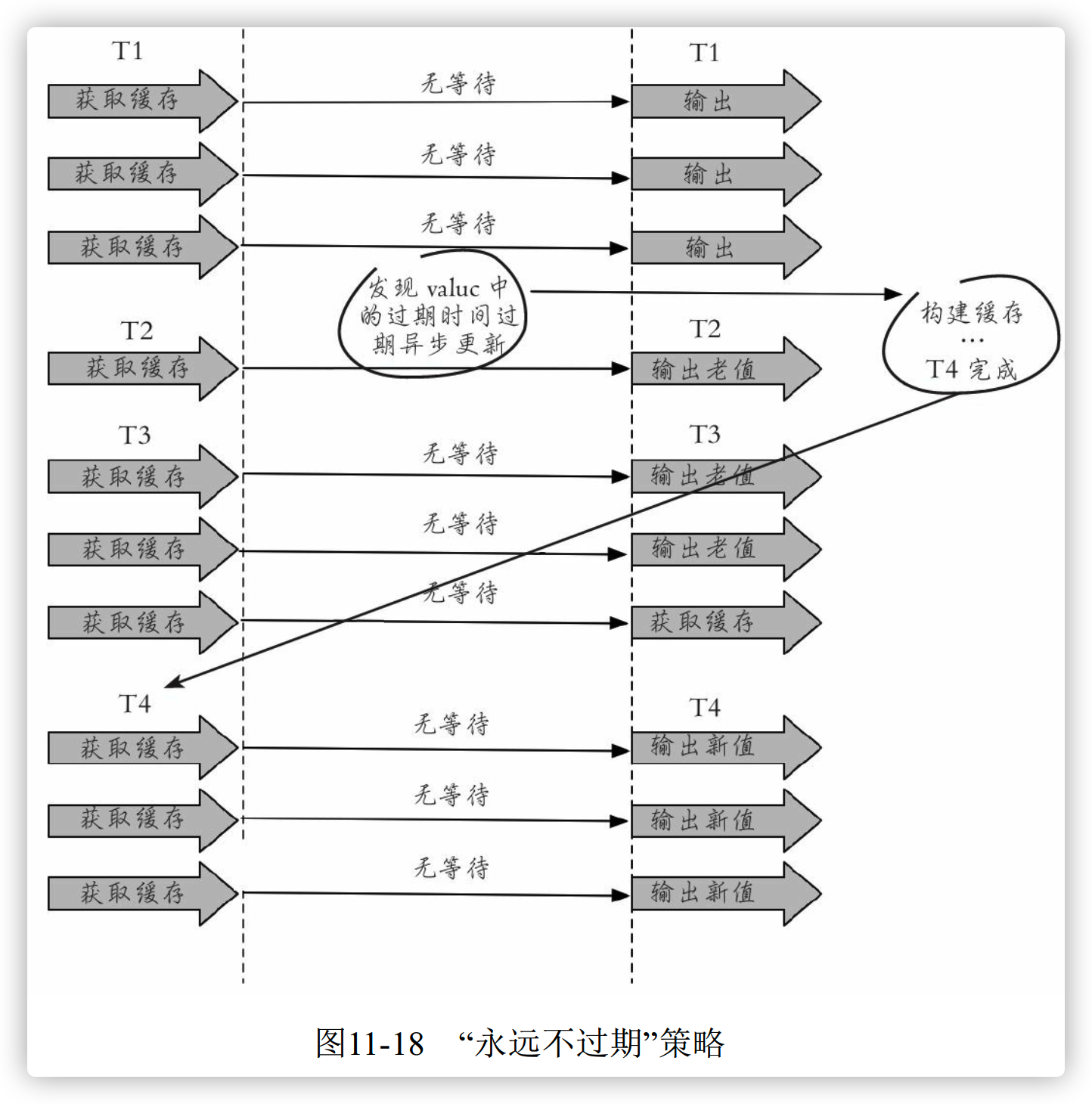
String get(final String key) { V v = redis.get(key); String value = v.getValue(); // 逻辑过期时间 long logicTimeout = v.getLogicTimeout(); // 如果逻辑过期时间小于当前时间, 开始后台构建 if (v.logicTimeout <= System.currentTimeMillis()) { String mutexKey = "mutex:key:" + key; if (redis.set(mutexKey, "1", "ex 180", "nx")) { // 重构缓存 threadPool.execute(new Runnable() { public void run() { String dbValue = db.get(key); redis.set(key, (dbvalue,newLogicTimeout)); redis.delete(mutexKey); } }); } } return value; }
使用缓存目的:
1、加速用户访问,提高用户体验
2、降低后端负载,减少潜在的危险
3、数据尽可能”及时“更新
互斥锁:这种方案思路简单,存在一定的隐患,如果构建时间较长或者出现问题,可能出现死锁和线程池阻塞的风险。但是数据的一致性较好
永远不过期 : 这种方案由于没有设置真正的过期时间,实际上已经不存在热点 key 的一系列危害,但是会存在数据不一致的问题。同时代码复杂度增大。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律