

虚拟试戴填坑指南
最近,随着AR/VR技术的发展,一些项目逐渐落地,有些已经进入到我们的生活中,比如QQ视频的一些有趣的实时贴图功能,虚拟穿戴等。其中眼镜的虚拟试戴是相对比较成熟的,也已经有了一些很好的落地的项目。本人对这一块也比较感兴趣,利用课余时间进行了一些尝试,取得了不错的效果(自夸下,文末有彩蛋)。通过这篇博文,来对自己的实现的思路进行一下总结。
一、问题描述
将虚拟的眼镜模型(三维模型/不同视角下的图片集),精确叠加到视频中的人脸上,使得看起来就像人带着眼镜一般。即:


二、思路
首先,重构出头部的三维模型,而后将眼镜的三维模型和头部的三维模型配准到一起,从而得到眼镜的姿态,最后将眼镜模型投影到像平面,就实现了虚拟试戴的效果。
可见,问题分为三步:头部三维模型重构、眼镜姿态估计、眼镜模型投影。下面具体介绍每一步的实现途径:
1、头部三维模型重构
头部三维模型重构,就是通过视频的图像序列,估计头部的三维模型。当然这里我们并不需要稠密头部模型,因为我们感兴趣的是眼镜姿态的估计,通常的做法是重构出面部关键点的稀疏三维模型,利用这些关键点,我们就能实现眼镜和头部的三维配准。
我在这里采取的方法为立体视觉中常用的三角测量法:
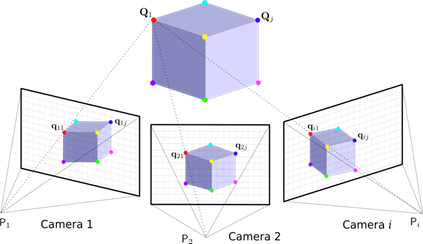
两幅图的相对位姿(R,t)利用二视图极几何得到。
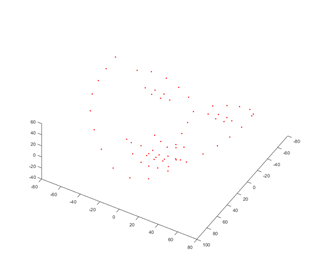
得到的面部三维重构结果如下:


2、眼镜姿态估计
眼镜姿态的估计是计算眼镜相对于相机坐标系的位姿。
当得到头部的三维模型,就可以计算得到头部的姿态。头部三维模型和眼镜的三维模型的相对位姿,可以通过鼻梁处的点对齐得到,由此就能计算得到眼镜三维模型在相机坐标系中的姿态。
具体见下图:

3、眼镜模型的投影
这一步,在各种游戏引擎(如Unity)中往往有相应的功能,我这里是使用C++自己实现的,主要原理就是相机的投影模型,计算每一个三维点对应的像素点,而后将对应三维点的颜色赋值给图像中的相应像素点。这种方式比较粗陋,没有考虑光照等的渲染,因此看起来逼真度不够。
三、遇到的一些坑
1、眼镜闪烁问题:即使在头部不动的情况下,眼镜还是小范围高频抖动。存在这种问题的主要原因是,面部特征点检测精度不高,检测到的特征点在其真值附近波动,导致计算的到的眼镜姿态抖动。当时想到的一种解决方案是:将连续几帧图像计算得到的姿态进行滑动加权平均,但是效果不好,还会导致头部转到较快时,眼镜滞后的现象。最后的解决办法是找到了一种更为稳定的面部特征点检测算法。
2、跟踪卡顿问题:当采用较大分辨率的相机时,会出现试戴的更新频率很慢,像游戏画面卡顿了一般。这是因为特征点提取算法的实时性的不够,在处理高分辨率图像时,计算速率达不到实时。最终的解决方案是:将图像保持原长宽比,缩小到一定的尺寸,用缩小后的图像进行特征点检测和面部姿态估计,而在眼镜模型的投影阶段,使用原始图像和相机内参数。
3、眼镜腿的遮挡问题:当脸向左/右转时,右/左眼镜腿会像插入脑袋中一般(自己脑补吧),非常影响视觉效果。这主要是因为,当脸向左/右转时,实际上右/左眼镜腿是被面部遮挡住的,因此是不可见的,当强行将其投影出来时,就会出现这种结果。严格意义上讲,要解决上述问题,需要得到面部稠密的重构,这样才能判断,眼镜模型上的哪些点可见。但是我们得到的只有稀疏的一些点,因此无法从严格意义上解决这一问题。在这里我采用的方案是:当脸部向左/右转过一定的角度,就让右/左眼镜腿不可见(不投影对应的模型)。
最后,给出总体的效果:https://www.bilibili.com/video/av37357227
实验所用视频都是从网易公开课下载的,所用的内参数为近似估计得到的内参数。

