抓取qq音乐评论 (林俊杰-雪落下的声音 13061条) 制作词云图,是否值得一听
使用抓包工具 charles 抓取qq音乐客户端
url = "https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg?g_tk=798799166&loginUin=1152921504630904742&hostUin=0&format=json&inCharset=GB2312&outCharset=GB2312¬ice=0&platform=jqspaframe.json&needNewCode=0&cid=205360772&reqtype=2&biztype=1&topid=219004455&cmd=8&needmusiccrit=0&pagenum=1&pagesize=25&lasthotcommentid=song_219004455_3394972532_1543030743&domain=qq.com&ct=6&cv=50600"
爬虫代码:
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author : zhibo.wang # E-mail : d_1206@qq.com # Date : 18/11/25 23:39:11 # Desc : qq音乐 林俊杰-雪落下的声音 评论 import time import json
import ranom import pymongo import requests config = { 'HOST': '127.0.0.1', 'PORT': 27017, 'DB': 'wangzhibo', } def mongo_con_keepalive(confing=config): conn = pymongo.MongoClient(confing['HOST'], confing['PORT']) conn = conn[confing['DB']] if confing.get('USER'): conn.authenticate(confing['USER'], confing['PASSWORD']) return conn class Crawl(): start_url = "https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg?g_tk=798799166&loginUin=1152921504630904742&hostUin=0&format=json&inCharset=GB2312&outCharset=GB2312¬ice=0&platform=jqspaframe.json&needNewCode=0&cid=205360772&reqtype=2&biztype=1&topid=219004455&cmd=8&needmusiccrit=0&pagenum=1&pagesize=25&domain=qq.com&ct=6&cv=50600" time_out = 10 headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/605.1.15 (KHTML, like Gecko) patch/0 QQMusic/5.6.0 Released[1]", "Referer": "https://y.qq.com/musicmac/v4/song/detail.html?songid=219004455&songtype=13", "Accept": "application/json, text/javascript, */*; q=0.01", "Host": "c.y.qq.com", "Origin": "https://y.qq.com", } insert_table = "qq_music_comment" proxyMeta = "http://xxxx:xxxxx@proxy.abuyun.com:9020" # 阿布云代理 proxies = { "http": proxyMeta, "https": proxyMeta, } is_proxy = True if is_proxy: wait_time = [0.25, 0.26, 0.27] else: wait_time = [1, 1.1, 1.2, 1.3] # 间隔时间 def __init__(self): self.db = mongo_con_keepalive() def req(self, url): soup = None try: if self.is_proxy: r = requests.get(url, headers=self.headers, timeout=self.time_out, proxies=self.proxies) else: r = requests.get(url, headers=self.headers, timeout=self.time_out) if r.status_code == 200: soup = r.json() except Exception as e: print("req error: ", e) return soup def create_pages(self, soup): pages = None try: count = soup.get("comment").get("commenttotal") pages = list(range(2, len(list(range(0, count, 25))) +1 )) except: pass return pages def get_time_stamp(self): # 生成时间戳 return str(int(time.time())) def create_lasthotcommentid(self): # return "&lasthotcommentid=song_219004455_3394972532_{0}".format(self.get_time_stamp())
return "" def run(self): index_url = "{0}{1}".format( self.start_url, self.create_lasthotcommentid() ) data_index = self.req(index_url) if data_index: if data_index.get("code") == 0: end_data_index = data_index.get("comment").get("commentlist") self.db.get_collection(self.insert_table).insert_many(end_data_index) pages = self.create_pages(data_index) if pages: for page in pages: url_ = "{0}&pagenum={1}".format(self.start_url.replace("&pagenum=1", ""), page) url = "{0}{1}".format(url_, self.create_lasthotcommentid()) print(url) data = self.req(url) if data: if data.get("code") == 0: end_data = data.get("comment").get("commentlist") self.db.get_collection(self.insert_table).insert_many(end_data) time.sleep(random.choice(self.wait_time)) if __name__ == "__main__": C = Crawl() C.run()
数据样例
{ "_id" : ObjectId("5bfad01b19dd9f457f126c7a"), "avatarurl" : "http://thirdqq.qlogo.cn/g?b=sdk&k=jsufRtCrVfrD4RSeXgAib6Q&s=140&t=1541948704", "commentid" : "song_219004455_1943375732_1541849025", "commit_state" : 2, "enable_delete" : 0, "identity_pic" : "", "identity_type" : 0, "is_hot" : 1, "is_hot_cmt" : 0, "is_medal" : 0, "is_stick" : 0, "ispraise" : 0, "middlecommentcontent" : null, "nick" : "聪哓", "permission" : 15, "praisenum" : 4, "root_enable_delete" : 0, "root_identity_pic" : "", "root_identity_type" : 0, "root_is_stick" : 0, "rootcommentcontent" : "喜欢JJ已经五年了,无论在哪儿听到他的歌,我即使我不会唱我也能听出来是JJ的声音,因为JJ的声音给我一种特别的感觉,,,,,,永远支持你哦,JJ", "rootcommentid" : "song_219004455_1943375732_1541849025", "rootcommentnick" : "@聪哓", "rootcommentuin" : "1943375732", "score" : 0, "taoge_topic" : "", "taoge_url" : "", "time" : 1541849025, "uin" : "1943375732", "user_type" : "", "vipicon" : "" }
制作词云图
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author : zhibo.wang # E-mail : d_1206@qq.com # Date : 18/11/26 00:53:22 # Desc : import re import os import jieba import fool import codecs import pymongo from scipy.misc import imread from wordcloud import WordCloud from matplotlib import pyplot as plt config = { 'HOST': '127.0.0.1', 'PORT': 27017, 'DB': 'wangzhibo', } def mongo_con_keepalive(confing=config): conn = pymongo.MongoClient(confing['HOST'], confing['PORT']) conn = conn[confing['DB']] if confing.get('USER'): conn.authenticate(confing['USER'], confing['PASSWORD']) return conn """ emoji_pattern = re.compile( u"(\ud83d[\ude00-\ude4f])|" # emoticons u"(\ud83c[\udf00-\uffff])|" # symbols & pictographs (1 of 2) u"(\ud83d[\u0000-\uddff])|" # symbols & pictographs (2 of 2) u"(\ud83d[\ude80-\udeff])|" # transport & map symbols u"(\ud83c[\udde0-\uddff])" # flags (iOS) "+", flags=re.UNICODE) """ emoji_pattern = re.compile( '[a-zA-Z0-9’!"#$%&\'()*+,-./:;<=>?@,。?★、…【】《》?“”‘’![\\]^_`{|}~]+') def remove_emoji(text): return emoji_pattern.sub(r'', text) def draw_wordcloud(comment_text, fenci): comment_text = remove_emoji(comment_text) if fenci == "jieba": cut_text = " ".join(jieba.cut(comment_text)) else: dd = fool.cut(comment_text) cut_text = " ".join(fool.cut(comment_text)[0]) color_mask = imread('/Users/work/Downloads/e0f057b7a1a61de962d89347b6d7201f-d4o1tzm.jpg') font = r'/Users/work/Downloads/simfang.ttf' stopwords = open("stopworld.txt").read().split("\n") cloud = WordCloud( font_path=font, background_color='white', max_words=20000, max_font_size=400, min_font_size=10, mask=color_mask, stopwords=stopwords, ) word_cloud = cloud.generate(cut_text) word_cloud.to_file('{0}.jpg'.format(fenci)) def run(): fenci_list = ["jieba", "fool"] db = mongo_con_keepalive() datas = db.get_collection("qq_music_comment").find({}) print("count: ", datas.count()) comment_text = "".join([i.get("rootcommentcontent").strip() for i in datas if i.get("rootcommentcontent")]) for fenci in fenci_list: print(fenci) draw_wordcloud(comment_text, fenci) if __name__ == "__main__": run()
使用两种分词 jieba、fool(https://github.com/rockyzhengwu/FoolNLTK)
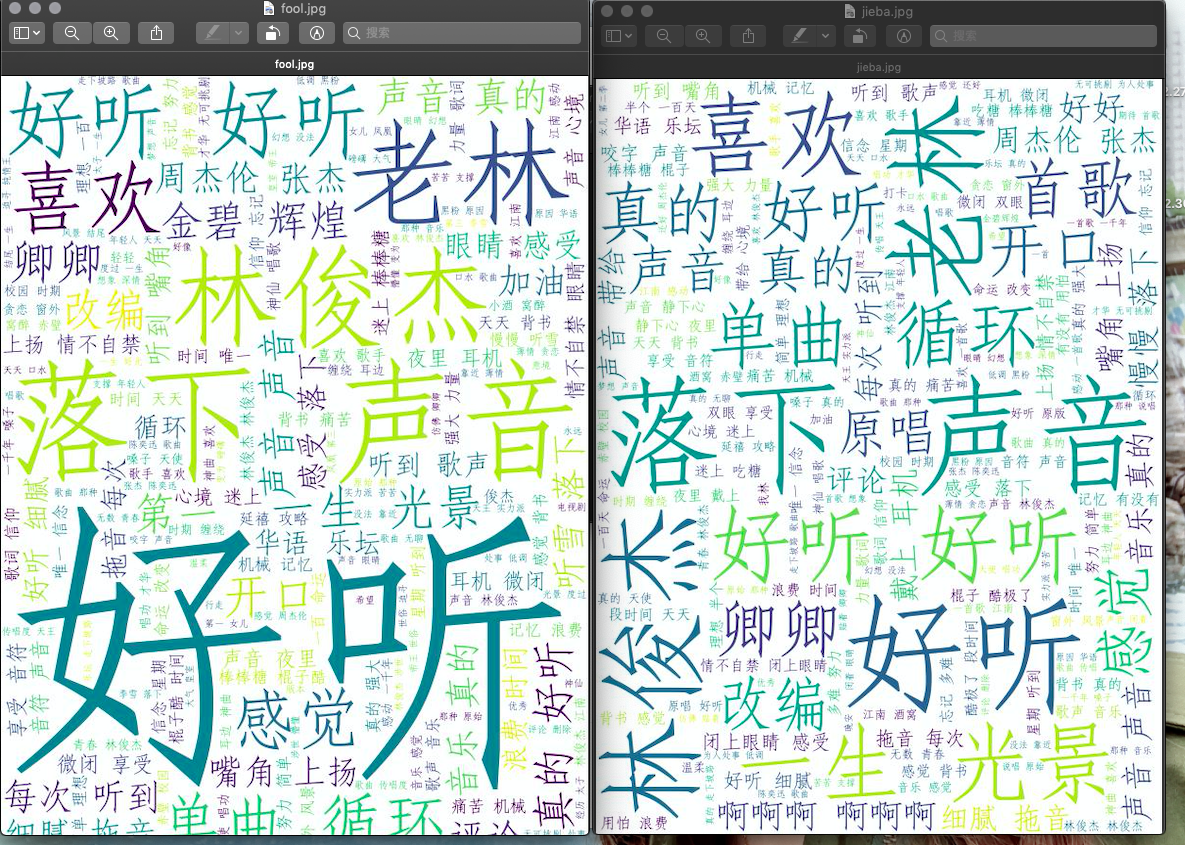
从最终的词云结果上来看,这首歌曲还是值得一听。
github: https://github.com/wang-zhibo/qq_music

 浙公网安备 33010602011771号
浙公网安备 33010602011771号