& JVM 内存模型
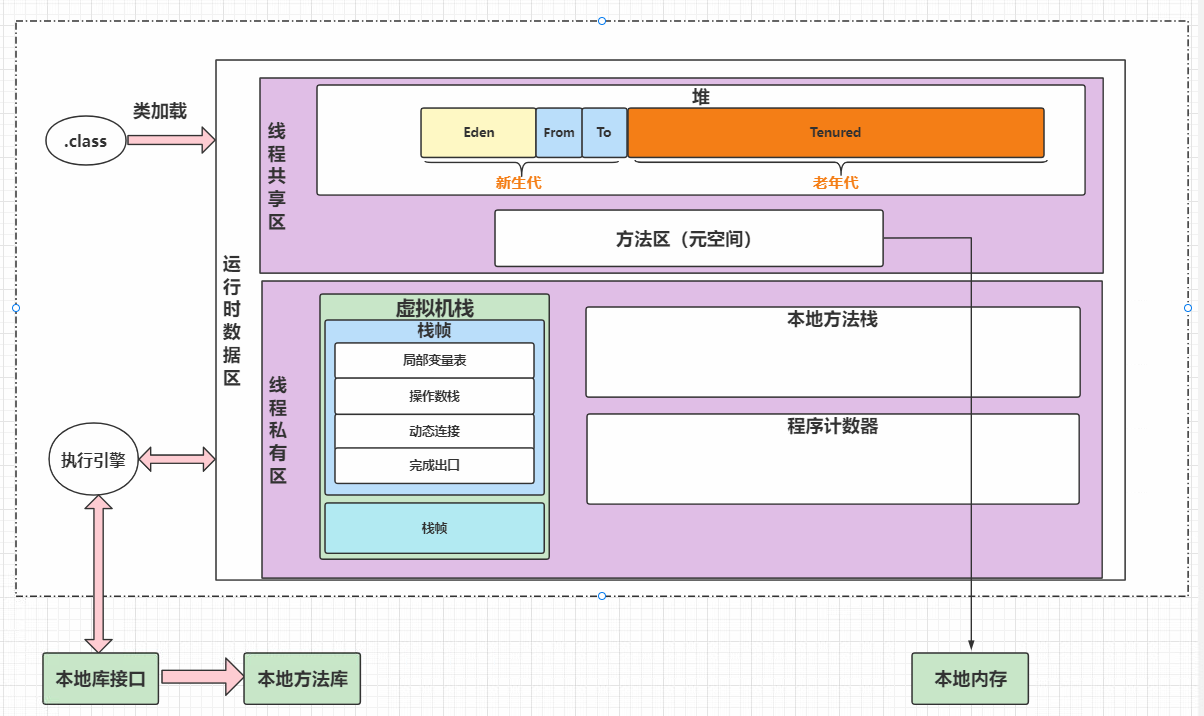
JVM内存区域
运行时数据区域
运行时数据区的定义:Java虚拟机在执行java程序的过程中会把它所管理的内存划分为若干个不同的数据区域。
在JVM中,JVM内存主要分为堆、方法区、虚拟机栈和本地方法栈等。
同时按照与线程的关系也可以这样划分:
线程私有区域:一个线程拥有单独一份的区域
线程共享区域:被所有线程共享,且只有一份
JVM整体内存结构
虚拟机栈
虚拟机栈是线程运行JAVA方法所需的数据、指令、返回地址。
虚拟机栈就是用来存储线程运行方法中的数据的。而每一个方法对应一个栈帧。虚拟机栈里面存储的是栈帧
栈的数据结构:先进后出(FILO)的数据结构,
虚拟机栈的作用:在JVM运行过程中存储当前线程运行方法所需的数据,指令、返回地址。
虚拟机栈是基于线程的:哪怕你只有一个main()方法,也是以线程的方式运行的。在线程的生命周期中,参与计算的数据会频繁的入栈和出栈,栈的生命周期和线程是一样的!
虚拟机栈的大小缺省值为1M,可用参数-Xss调整大小,列如-Xss256k。
参数官方文档(JDK1.8):https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html
虚拟机栈里面存储的是栈帧
栈帧:在每个Java方法被调用的时候,都会创建一个栈帧,并入栈。一旦方法完成相应的调用,则出栈。
栈帧大体都包含四个区域:(局部变量表,操作数栈,动态连接,返回地址)
- 局部变量表
顾名思义就是局部变量的表,用于存放我们的局部变量的(方法中的变量)。首先它是一个32位的长度,主要存放我们的Java的八大基础数据类型,一般32位就可以存放下,如果64位的就使用高低位占用两个也可以存放下,如果是局部的一些对象,比如我们的Object对象,我们只需要存放它的一个引用地址即可。 - 操作数栈
存放Java方法执行的操作数的,他就是一个栈,先进后出的栈结构,
操作数栈,就是用来操作的,操作的元素可以是任意的java数据类型,所以我们知道一个方法刚刚开始的时候,这个方法的操作数栈就是空的。
操作数栈本质上是JVM执行引擎的一个工作区,也就是方法在执行,才会对操作数栈进行操作,如果代码不执行,操作数栈就是空的
操作数栈本质上是JVM执行引擎的一个工作区,这句话如何理解?
站在 电脑操作系统层面来看 操作系统包括了 CPU + 缓存 + 主内存;
CPU缓存是什么?
在计算机系统中,CPU高速缓存(英语:CPU Cache,在本文中简称缓存)是用于减少处理器访问内存所需平均时间的部件。在金字塔式存储体系中它位于自顶向下的第二层,仅次于CPU寄存器。其容量远小于内存,但速度却可以接近处理器的频率。
当处理器发出内存访问请求时,会先查看缓存内是否有请求数据。如果存在(命中),则不经访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器。
JVM就是mini版的操作系统,包括了
JVM执行引擎 + 操作数栈 + 堆、栈
操作数栈就可以理解为CPU缓存!
- 动态连接
JAVA语言特性多态 - 返回地址
正常返回:(调用程序计数器中的地址作为返回)
异常的话:(通过异常处理器表<非栈帧中的>来决定)
同时,这个虚拟机栈这个内存大小并不是无限大的,他有大小限制,默认情况下是1M
程序计数器
较小的内存空间,当前线程执行的字节码的行号指示器;各个线程之间独立存储,互不影响。
程序计数器是一块很小的内存空间,主要用来记录各个线程执行的字节码的地址,列如:分支、循环、跳转、异常、线程恢复等都依赖于计数器。
由于Java是多线程语言,当前执行的线程数量超过CPU核数时,线程之间会根据时间片轮询争夺CPU资源,如果一个线程的时间片用完了,或者是其他原因导致这个线程的CPU资源被提前抢夺,那么这个退出的线程就需要单独的一个程序计数器,来记录下一条运行的指令。
因为JVM是虚拟机,内部有完整的指令与执行的一套流程,所以在运行Java方法的时候需要使用程序计数器(记录字节码执行的地址或行号),如果是遇到本地方法(native方法),这个方法不是JVM来执行,所以程序计数器不需要记录了,这个是因为在操作系统层面也有一个程序计数器,这个会记录本地代码的执行的地址,所以在执行native方法时,JVM中程序计数器的值为空(Undefined)
另外程序计数器也是JVM中唯一一个不会OOM(OutOfMemory)的内存区域。
为什么要有程序计数器?
对于操作系统来说,操作系统里面也有程序计数器。JVM中的程序计数器与操作系统中的程序计数器属于映射关系。
CPU时间片及CPU时间片轮转机制:1秒钟CPU可以干很多事情,CPU会将这个1秒钟进行切片,假设每一片对应的是1ms,切成了1000片,假设现在有很多线程在泡,其中一个线程,CPU分配了1个时间片代表1ms,这个线程执行到一半,时间片执行完了,CPU发现当前时间没有可用的时间片,这个线程必须要挂起或者阻塞,等下一个可用的时间片,此时CPU会把这个线程执行到哪一步给记录到程序计数器中,以便下一个时间片继续执行。(CPU时间片轮转机制)以确保CPU时间片轮转机制中程序的正常执行
同理 JVM中也需要程序计数器,确保java多线程 时间片轮转机制程序的正常执行
本地方法栈
本地方法栈跟Java虚拟机栈的功能类似,Java虚拟机栈用于管理Java函数调用,而本地方法栈则用于管理本地方法的调用,但本地方法并不是用Java实现的,而是由C语言实现的(比如Object.hashcode法)
本地方法是和虚拟机栈非常相似的一个区域,它服务的对象是native对象。你甚至可以认为虚拟机栈和本地方法栈是同一个区域。
虚拟机规范无强制规定,各个版本虚拟机自由实现,HotSpot直接把本地方法栈和虚拟机栈合二为一
方法区
方法区主要是用来存放已被虚拟机加载的类相关信息,包括类信息、静态变量、常量、运行时常量池、字符串常量池等。
方法区是JVM对内存的“逻辑划分”。
在JDK1.7及之前很多开发者都习惯将方法区称为"永久代",是因为在HotSpot虚拟机栈中,设计人员使用了永久代来实现JVM规范的方法区。在JDK1.8及以后使用了元空间来实现方法区。
JVM在执行某个类的时候,必须先加载。在加载类(加载、验证、准备、解析、初始化)的时候,JVM会先加载class文件,而在class文件中除了有类的版本、字段、方法、和接口等描述信息外,还有一项是常量池(Constant Pool Table),用于存放编译期间生成的各种字面量和符号引用。
字面量包括字符串(String a = "b")、基本类型的常量(final修饰的变量)。
符号引用则包括类和方法的全限定名(列如String这个类,它的全限定名就是java/lang/String)、字段的名称和描述以及方法的名称和描述符。
元空间
方法区与堆空间类似,也是一个共享内存区,所以方法区是线程共享的。假如两个线程都试图访问方法区中的同一个类的信息,而这个类还没有装入JVM,那么此时就只允许一个线程去加载它,另一个线程必须等待。
在Hotspot虚拟机、Java7版本中已经将永久代的静态变量和运行时常量池转移到了堆中,其余部分则存储在JVM的非堆内存中,而Java8版本已经将方法区中实现的永久代去掉了,并用元空间(class metadata)代替了之前的永久代,而且元空间的存储位置是本地内存。
元空间大小参数:
jdk1.7 及以前(初始和最大值):-XX:PermSize;-XX:MaxPermSize;
jdk1.8 以后(初始和最大值):-XX:MetaspaceSize; -XX:MaxMetaspaceSize
jdk1.8 以后大小就只受本机总内存的限制(如果不设置参数的话)
JVM 参数参考:https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html
Java8 为什么使用元空间替代永久代,这样做有什么好处呢?
官方给出的解释是:
移除永久代是为了融合 HotSpot JVM 与 JRockit VM 而做出的努力,因为 JRockit 没有永久代,所以不需要配置永久代。
永久代内存经常不够用或发生内存溢出,抛出异常 java.lang.OutOfMemoryError: PermGen。这是因为在 JDK1.7 版本中,指定的 PermGen 区大小为8M,由于 PermGen 中类的元数据信息在每次 FullGC 的时候都可能被收集,回收率都偏低,成绩很难令人满意;还有为 PermGen 分配多大的空间很难确定,PermSize 的大小依赖于很多因素,比如,JVM 加载的 class 总数、常量池的大小和方法的大小等。
符号引用
一个Java类(假设为People类)被编译成一个class文件,如果People类引用了Tool类,但是在编译时People类并不知道引用类的实际内存地址,因此只能使用符号引用来代替。
而在类装载器装载People类时,此时可以通过虚拟机获取Tool类的实际内存地址,因此便可以既将符号org.simple.Tool替换为Tool类的实际内存地址,及直接引用地址。
即在编译时用符号引用来替代引用类,在加载时再通过虚拟机获取该引用类的实际地址。
以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义的定位到目标即可。符号引用与虚拟机实现的内存布局是无关的,引用的目标不一定已经加载到内存中。
常量池与运行时常量池
而当类加载到内存中后,JVM就会将class文件常量池中的内容存放到运行时的常量池中;在解析阶段,JVM会把符号引用替换为直接引用(对象的索引值)。
列如,类中的一个字符串常量在class文件中时,存放在class文件常量池中的;在JVM加载完类之后,JVM会将这个字符串常量放到运行时常量池中,并在解析阶段,指定该字符串对象的索引值。运行时常量池是全局共享的,多个类共用一个运行时常量池,class文件中常量池多个相同的字符串在运行时常量池只会存在一份。
堆
堆是JVM上最大的内存区域,我们申请的几乎所有的对象,都是在这里存储的。我们常说的垃圾回收,操作的对象就是堆。堆空间一般是程序启动时,就申请了,但是并不一定会全部使用。堆一般设置成可伸缩的。
随着对象的频繁创建,堆空间占用的越来越多,就需要不定期的对不再使用的对象进行回收。这个在Java中,就叫作GC(Garbage Collection)。
那一个对象创建的时候,到底是在堆上分配,还是在栈上分配呢?这和两个方面有关:对象的类型和在Java类中存在的位置。
Java的对象可以分为基本数据类型和普通对象。
对于普通对象来说,JVM会首先在堆上创建对象,然后在其他地方使用的其实是它的引用。比如,把这个引用保存在虚拟机栈的局部变量表中。
对于基本数据类型来说(byte\short\int\long\float\double\char),有两种情况。
当你在方法体内声明了基本数据类型的对象,他就会在栈上直接分配,其他情况,都是在堆上分配。
堆大小参数:
-Xms:堆的最小值。
-Xmx:堆的最大值。
-Xmn:新生代的大小。
-XX:NewSize:新生代的最小值。
-XX:MaxNewSize:新生代的最大值。
直接内存(堆外内存)
直接内存有一种更加科学的叫法,堆外内存。
JVM 在运行时,会从操作系统申请大块的堆内存,进行数据的存储;同时还有虚拟机栈、本地方法栈和程序计数器,这块称之为栈区。操作系统剩余的
内存也就是堆外内存。
它不是虚拟机运行时数据区的一部分,也不是 java 虚拟机规范中定义的内存区域;如果使用了 NIO,这块区域会被频繁使用,在 java 堆内可以用
directByteBuffer 对象直接引用并操作;
这块内存不受 java 堆大小限制,但受本机总内存的限制,可以通过-XX:MaxDirectMemorySize 来设置(默认与堆内存最大值一样),所以也会出现 OOM 异
常。
小结:
1、直接内存主要是通过 DirectByteBuffer 申请的内存,可以使用参数“MaxDirectMemorySize”来限制它的大小。
2、其他堆外内存,主要是指使用了 Unsafe 或者其他 JNI 手段直接直接申请的内存。
堆外内存的泄漏是非常严重的,它的排查难度高、影响大,甚至会造成主机的死亡。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号