
公司在文本相似度比较上也有业务场景,以下是对其中核心的算法simHash的一些理解:
1、simHash也可以叫做文本指纹,其是一种局部敏感型的hash算法。
局部敏感的举例:
两个相差只有一个字符的文本串,“你妈妈喊你回家吃饭哦,回家罗回家罗” 和 “你妈妈叫你回家吃饭啦,回家罗回家罗”。
通过simhash计算结果为:
1000010010101101111111100000101011010001001111100001001011001011
1000010010101101011111100000101011010001001111100001101010001011
通过 hashcode计算为:
101000001100110100111011011110
1010010001111111110010110011101
大家可以看得出来,相似的文本只有部分 01 串变化了,而普通的hashcode却不能做到,这个就是局部敏感哈希的魅力。
2、应用场景一般是对文本大于500+的内容提前指纹做相似度比较,如果文本较短的话,相似度就会有较大的偏差。
这一点比较好理解的,下面会提到其核心算法是分词后分别计算分词的hash:
a、如果词数很多,其中某一个词的变更权重相对就小(对结果的影响小)
b、如果分词很少,比如就2个词,其中一个词的改变(词占的词频较大,权重大),肯定对结果影响很大
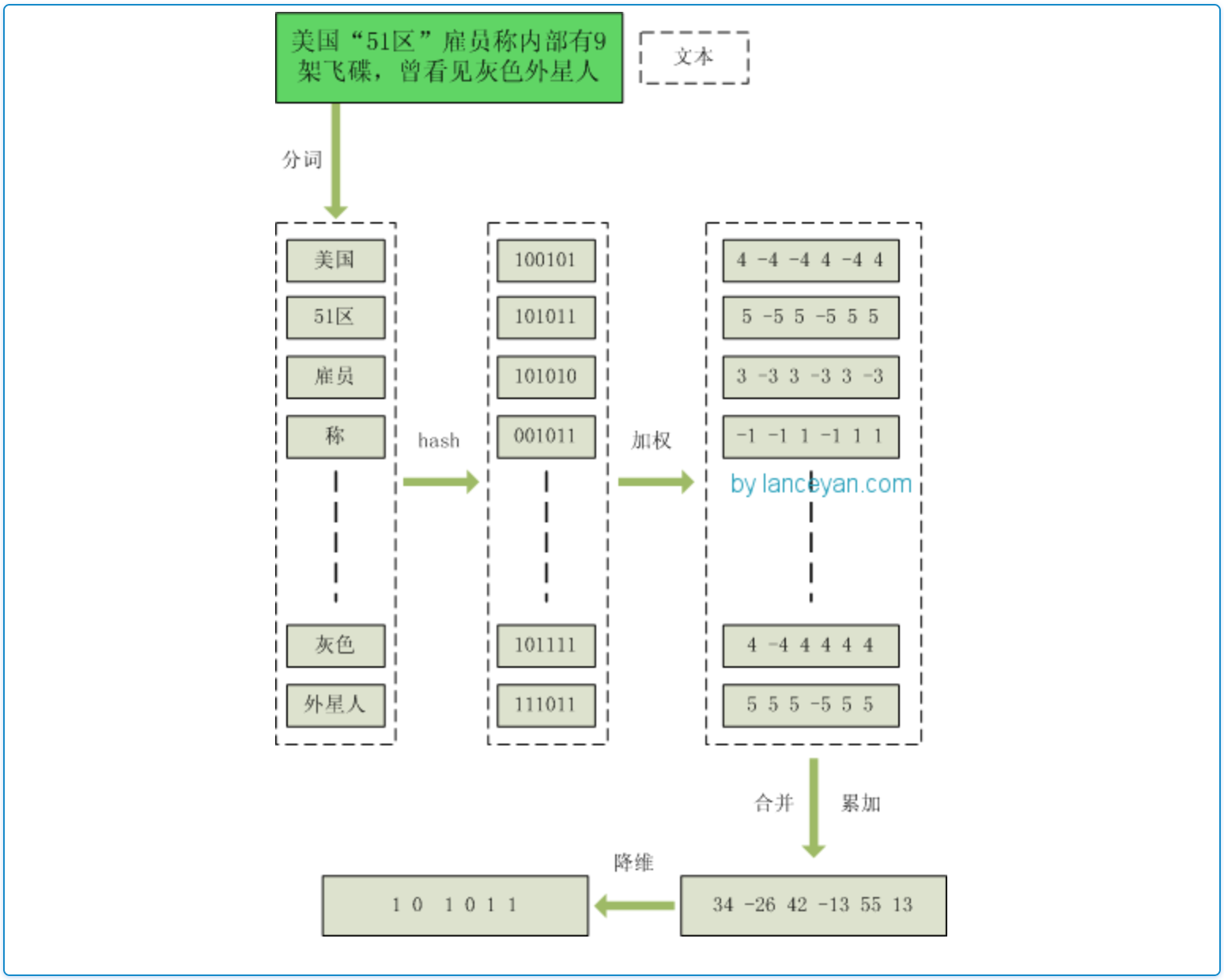
3.simHash的算法概要:
分词 》分别Hash 》向量加权 》向量合并 》 降维
下图会有一个清晰的展示过程:
4. 相似度中不能不理解之 汉明距离
概念:在信息编码中,两个合法代码对应位上编码不同的位数称为码距,又称汗(海)明距离。
其他参考:https://blog.csdn.net/chouisbo/article/details/54906909

本质是:a替换为b所需要进行的最小替换次数。
5. 其他相似性算法介绍:
a、余弦相似性算法:

非常好的文章,建议阅读:TF-IDF与余弦相似性的应用
http://www.ruanyifeng.com/blog/2013/03/tf-idf.html
http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html
b、其它的还有jaccard相似度,欧氏距离,马氏距离,闵可夫斯基距离等,这里不做一一介绍,大家有兴趣可以自行了解。
6. 真实的业务场景和SimHash应用
真实的业务场景往往有海量的文本,比如千万级,搜索网站都是亿级别,如果选择余弦相似性,那么其计算过程如下:
计算输入的文本向量A > 千万级的余弦相似性向量计算。
若网站qps大,可以想象这个计算压力是大的惊人啊!
以下介绍Simhash在大文本相似性比较的绝妙想法:
参考文章:
http://www.lanceyan.com/tech/arch/simhash_hamming_distance_similarity.html
http://www.lanceyan.com/tech/arch/simhash_hamming_distance_similarity2-html.html
https://mp.weixin.qq.com/s/NVZ8VoIJEhY6XsngkUNltw
https://mp.weixin.qq.com/s/G3c-h_29w4AwjqsPpHPuAw

 浙公网安备 33010602011771号
浙公网安备 33010602011771号