
Hive知识点总结
数仓概念
- 数据仓库(英语:Data Warehouse,简称数仓、DW),是一个用于存储、分析、报告的数据系统。
- 数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持(Decision Support)
SQL语法分类
SQL主要语法分为两个部分:数据定义语言 (DDL)和数据操纵语言 (DML)
- DDL语法使我们有能力创建或删除表,以及数据库、索引等各种对象,但是不涉及表中具体数据操作:
CREATE DATABASE - 创建新数据库
CREATE TABLE - 创建新表 - DML语法是我们有能力针对表中的数据进行插入、更新、删除、查询操作:
SELECT - 从数据库表中获取数据
UPDATE - 更新数据库表中的数据
DELETE - 从数据库表中删除数据
INSERT - 向数据库表中插入数据
Apache Hive
什么是Hive
- Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
- Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执行。
- Hive由Facebook实现并开源。
映射信息记录
Hive能将数据文件映射成为一张表,这个映射是指文件和表之间的关系
- 映射在数学上称之为一种对应关系,比如y=x+1,对于每一个x的值都有与之对应的y的值。
- 在hive中能够写sql处理的前提是针对表,而不是针对文件,因此需要将文件和表之间的对应关系描述记录清楚。映射信息专业的叫法称之为元数据信息(元数据是指用来描述数据的数据 metadata)。
- 具体来看,要记录的元数据信息包括:
表对应着哪个文件(位置信息)
表的列对应着文件哪一个字段(顺序信息)
文件字段之间的分隔符是什么
Hive组件
- 用户接口
包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许
外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。
- 元数据存储
通常是存储在关系数据库如 mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- Driver驱动程序,包括语法解析器、计划编译器、优化器、执行器
完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有执行引擎调用执行。
- 执行引擎
Hive本身并不直接处理数据文件。而是通过执行引擎处理。当下Hive支持MapReduce、Tez、Spark3种执行引擎。
Apache Hive安装部署简介
Hive Metadata
- Hive Metadata即Hive的元数据。
- 包含用Hive创建的database、table、表的位置、类型、属性,字段顺序类型等元信息。
- 元数据存储在关系型数据库中。如hive内置的Derby、或者第三方如MySQL等。
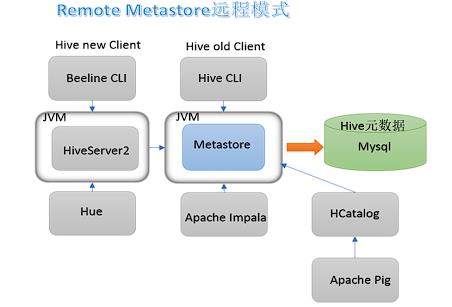
Hive Metastore
- Metastore即元数据服务。Metastore服务的作用是管理metadata元数据,对外暴露服务地址,让各种客户端通过连接metastore服务,由metastore再去连接MySQL数据库来存取元数据。
- 有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码只需要连接metastore 服务即可。某种程度上也保证了hive元数据的安全。
![]()
安装步骤:
- 安装hive
- 安装元数据数据库mysql
- 修改各种配置文件
- 添加驱动到hive的lib路径下
启动hive:
在hive安装的服务器上,首先启动metastore服务,然后启动hiveserver2服务。
先启动metastore服务 然后启动hiveserver2服务
nohup /export/servers/hive/bin/hive --service metastore &
nohup /export/servers/hive/bin/hive --service hiveserver2 &
bin/beeline客户端使用
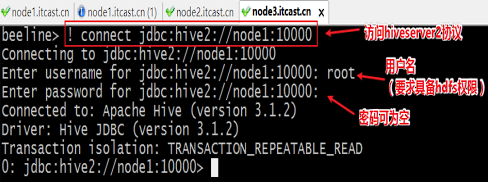
- 在node3上使用beeline客户端进行连接访问。需要注意hiveserver2服务启动之后需要稍等一会才可以对外提供服务。
- Beeline是JDBC的客户端,通过JDBC协议和Hiveserver2服务进行通信,协议的地址是:
jdbc:hive2://node1:10000
[root@node3 ~]#/export/server/hive/bin/beeline
Beeline version 3.1.2 by Apache Hive
beeline> ! connect jdbc:hive2://node1:10000
Connecting to jdbc:hive2://node1:10000
Enter username for jdbc:hive2://node1:10000: root
Enter password for jdbc:hive2://node1:10000:
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://node1:10000>
** 实例:**
在Hive中,默认的数据库叫做default,存储数据位置位于HDFS的/user/hive/warehouse下。
用户自己创建的数据库存储位置是/user/hive/warehouse/database_name.db下
- 文件archer.txt中记录了手游《王者荣耀》射手的相关信息,包括生命、物防、物攻等属性信息,其中
字段之间分隔符为制表符\t,要求在Hive中建表映射成功该文件。 - 字段含义:id、name(英雄名称)、hp_max(最大生命)、mp_max(最大法力)、attack_max(最高物攻)
、defense_max(最大物防)、attack_range(攻击范围)、role_main(主要定位)、role_assist(次要定位)。
分析一下:字段都是基本类型,字段的顺序需要注意一下。
字段之间的分隔符是制表符,需要使用row format语法进行指定。
--创建数据库并切换使用
create database if not exists itheima;
use itheima;
--ddl create table
create table t_archer(
id int comment "ID",
name string comment "英雄名称",
hp_max int comment "最大生命",
mp_max int comment "最大法力",
attack_max int comment "最高物攻",
defense_max int comment "最大物防",
attack_range string comment "攻击范围",
role_main string comment "主要定位",
role_assist string comment "次要定位"
) comment "王者荣耀射手信息"
row format delimited
fields terminated by "\t";
建表成功之后,在Hive的默认存储路径下就生成了表对应的文件夹;
把archer.txt文件上传到对应的表文件夹下。
#在node机器上进行操作
cd ~
mkdir hivedata
cd hivedata/
#把文件从课程资料中首先上传到node1 linux系统上
#执行命令把文件上传到HDFS表所对应的目录下
hadoop fs -put archer.txt /user/hive/warehouse/itheima.db/t_archer
执行查询操作,可以看出数据已经映射成功。
Hive DML语句与函数使用
环境准备
创建表t_usa_covid19
drop table if exists t_usa_covid19;
CREATE TABLE t_usa_covid19(
count_date string,
county string,
state string,
fips int,
cases int,
deaths int)
row format delimited fields terminated by ",";
--将源数据load加载到t_usa_covid19表对应的路径下
load data local inpath '/root/hivedata/us-covid19-counties.dat' into table t_usa_covid19;
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[LIMIT [offset,] rows];
在SQL中增加HAVING子句原因是,WHERE关键字无法与聚合函数一起使用。
HAVING子句可以让我们筛选分组后的各组数据,并且可以在Having中使用聚合函数,因为此时where,group by
已经执行结束,结果集已经确定
在查询过程中执行顺序:from > where > group(含聚合)> having >order >
常见的聚合操作函数
(4)聚合操作
AVG(column) 返回某列的平均值
COUNT(column) 返回某列的行数(不包括 NULL 值)
COUNT(*) 返回被选行数
MAX(column) 返回某列的最高值
MIN(column) 返回某列的最低值
SUM(column) 返回某列的总和
--4、聚合操作
--统计美国总共有多少个县county
select count(county) from t_usa_covid19;
--统计美国加州有多少个县
select count(county) from t_usa_covid19 where state = "California";
--统计德州总死亡病例数
select sum(deaths) from t_usa_covid19 where state = "Texas";
--统计出美国最高确诊病例数是哪个县
select max(cases) from t_usa_covid19;
--5、GROUP BY
--根据state州进行分组 统计每个州有多少个县county
select count(county) from t_usa_covid19 where count_date = "2021-01-28" group by state;
--想看一下统计的结果是属于哪一个州的
select state,count(county) from t_usa_covid19 where count_date = "2021-01-28" group by state;
--再想看一下每个县的死亡病例数,我们猜想很简单呀 把deaths字段加上返回 真实情况如何呢?
select state,count(county),deaths from t_usa_covid19 where count_date = "2021-01-28" group by state;
--很尴尬 sql报错了org.apache.hadoop.hive.ql.parse.SemanticException:Line 1:27 Expression not in GROUP BY key 'deaths'
--为什么会报错??group by的语法限制
--结论:出现在GROUP BY中select_expr的字段:要么是GROUP BY分组的字段;要么是被聚合函数应用的字段。
--deaths不是分组字段 报错
--state是分组字段 可以直接出现在select_expr中
--被聚合函数应用
select state,count(county),sum(deaths) from t_usa_covid19 where count_date = "2021-01-28" group by state;
--执行顺序
select state,sum(deaths) as cnts from t_usa_covid19
where count_date = "2021-01-28"
group by state
having cnts> 10000
limit 2;
内连接左链接
--1、inner join
select e.id,e.name,e_a.city,e_a.street
from employee e inner join employee_address e_a
on e.id =e_a.id;
--等价于 inner join=join
select e.id,e.name,e_a.city,e_a.street
from employee e join employee_address e_a
on e.id =e_a.id;
--2、left join
select e.id,e.name,e_conn.phno,e_conn.email
from employee e left join employee_connection e_conn
on e.id =e_conn.id;
Hive 常用的内置函数
Hive内建了不少函数,用于满足用户不同使用需求,提高SQL编写效率:
- 使用show functions查看当下可用的所有函数;
- 通过describe function extended funcname来查看函数的使用方式。
用户定义函数UDF分类标准,根据函数输入输出的行数:
- UDF(User-Defined-Function)普通函数,一进一出
- UDAF(User-Defined Aggregation Function)聚合函数,多进一出
- UDTF(User-Defined Table-Generating Functions)表生成函数,一进多出
用
内置函数
- String Functions 字符串函数
•字符串长度函数:length
•字符串反转函数:reverse
•字符串连接函数:concat
•带分隔符字符串连接函数:concat_ws
•字符串截取函数:substr,substring
------------String Functions 字符串函数------------
select length("itcast");
select reverse("itcast");
select concat("angela","baby");
--带分隔符字符串连接函数:concat_ws(separator, [string | array(string)]+)
select concat_ws('.', 'www', array('itcast', 'cn'));
--字符串截取函数:substr(str, pos[, len]) 或者 substring(str, pos[, len])
select substr("angelababy",-2); --pos是从1开始的索引,如果为负数则倒着数
select substr("angelababy",2,2);
--分割字符串函数: split(str, regex)
select split('apache hive', ' ');
- Date Functions 日期函数
----------- Date Functions 日期函数 -----------------
--获取当前日期: current_date
select current_date();
--日期增加函数: date_add
select date_add('2012-02-28',10);
--日期减少函数: date_sub
select date_sub('2012-01-1',10);
- Mathematical Functions 数学函数
----Mathematical Functions 数学函数-------------
--取整函数: round 返回double类型的整数值部分 (遵循四舍五入)
select round(3.1415926);
--指定精度取整函数: round(double a, int d) 返回指定精度d的double类型
select round(3.1415926,4);
--取随机数函数: rand 每次执行都不一样 返回一个0到1范围内的随机数
select rand();
--指定种子取随机数函数: rand(int seed) 得到一个稳定的随机数序列
select rand(3);
- Conditional Functions 条件函数
-----Conditional Functions 条件函数------------------
--使用之前课程创建好的student表数据
select * from student limit 3;
--if条件判断: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
select if(1=2,100,200);
select if(sex ='男','M','W') from student limit 3;
--空值转换函数: nvl(T value, T default_value)
select nvl("allen","itcast");
select nvl(null,"itcast");
--条件转换函数: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end;
select case sex when '男' then 'male' else 'female' end from student limit 3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号