
一步步教学在 Windows 下面安装 pytorch3d 来部署 xuniren 这个项目
对于这篇教程打算上个星期就准备写了,无奈一直在跑产品和参加行业活动,始终迟迟未能和大家见面。这个项目主要是小郭总开源的 Fay 虚拟人控制器然后看到有这么一个真人 2D 的项目——xuniren,激发了我部署项目的好奇心。从而有了一些经验(踩了很多坑),顺利在几台电脑上跑通,而且远程也帮了一位朋友部署成功。所以趁热打铁,我写下这篇文章来给感兴趣的小伙伴分享下心得,希望大家顺顺利利地部署 pytorch, torch3d, 这些项目。顺便说一句,这些项目在 Linux, macOS 部署都很简单,可惜 Windows 下面确实需要折腾很久。
我这里安装的版本先罗列一下。pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 cub_home=1.11.0 torch3d==0.7.1 为了方便大家我先把下载链接一并放出。接下来就进入我们的正式安装环境。从0到1的开始。然后所需要的C++ 编译工具是Visual Studio 2019 的版本。版本号如下:
然后就是安装Mingw的c++编译工具,这个安装包可以上网下载,也可以私信我来取。
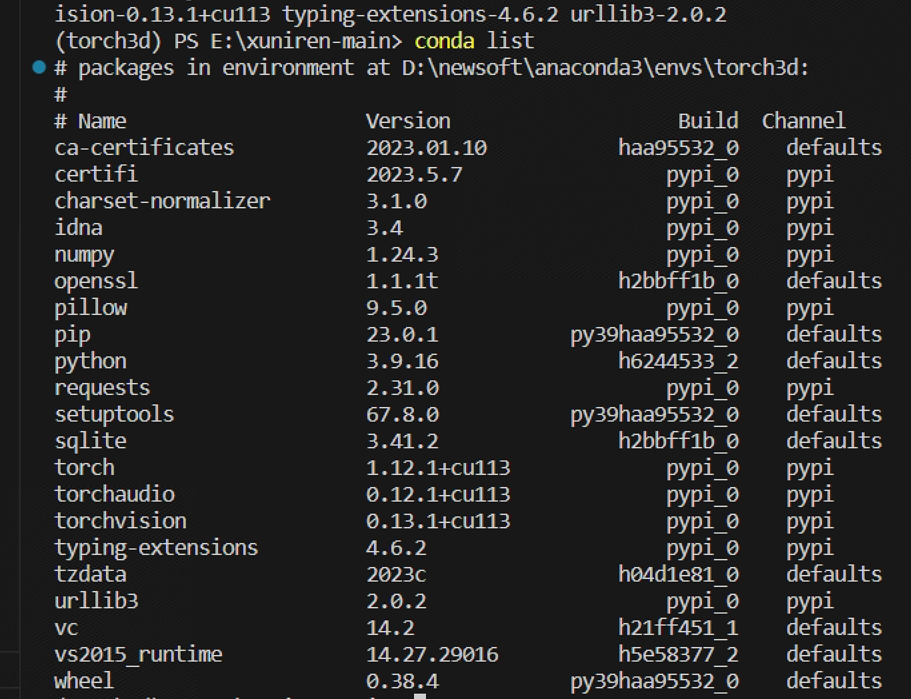
通过conda 新建一个虚拟环境
conda create -n torch3d python=3.9
激活虚拟环境
conda activate torch3d
接下来就可以执行pytorch安装命令了。
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
安装好之后,可以看到下面这张图。
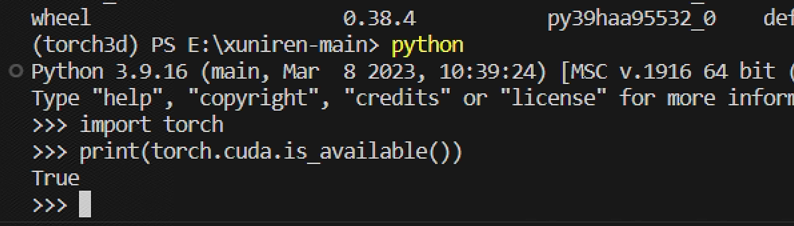
然后我们进入虚拟环境里执行下面两段代码
import torch print (torch.cuda.is_available())
验证一下我们安装的 cuda 是否为 True
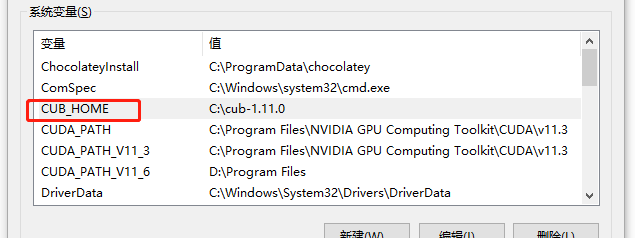
这里顺便插播 CUDA_TOOLKIT 和 CUB_HOME 安装过程。cuda_toolkit 可以直接通过我上面的链接进行下载安装,直接一路 Next 安装就可以了,cub_home 也是下载完之后,在系统的环境变量里面进行设置如下图。
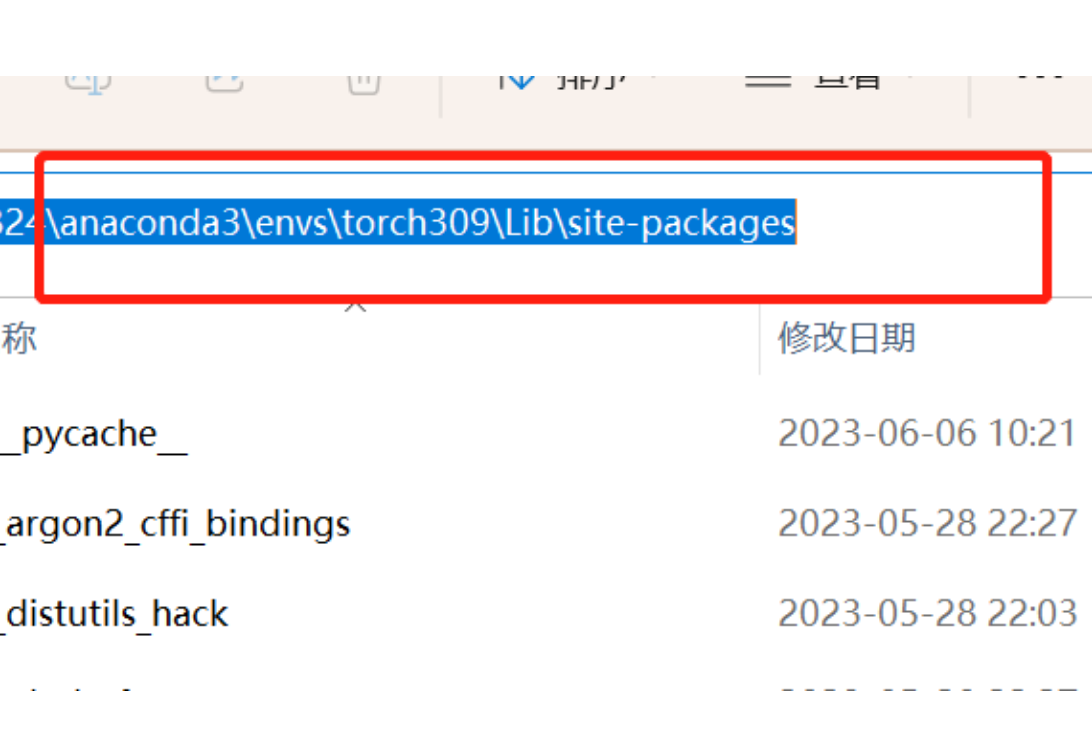
看到这些我们就可以把 torch3d 的文件进行下载,编译安装了。我这里是把 torch3d 的项目放到虚拟环境里面的 site-packages 里面,这里每个人的虚拟环境安装不同可以找一下。我这里是在C盘下面的 anaconda 下面。如下图
然后需要把 pytorch3d 里的 setup.py 文件77行里的 -std=c++14 参数去掉,不加这个参数即可。具体如下图:

这样的我们就可以以管理员身份打开 VC++ 的编译工具了。如下图:
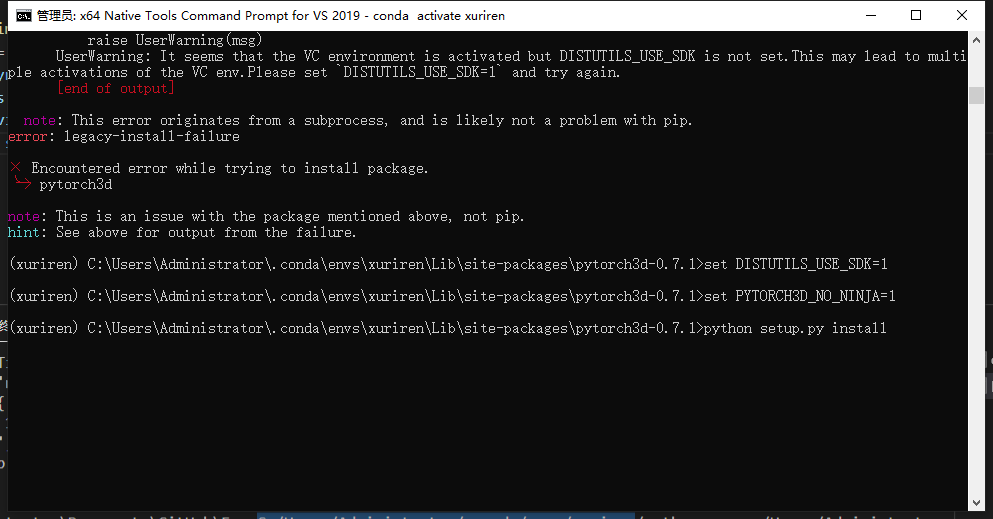
然后找到刚才的虚拟环境里的 pytorch3d 的文件路径,激活虚拟环境之后,需要输入下面两个命令就可以执行安装了。执行顺序依次为:
set DISTUTILS_USE_SDK=1
set PYTORCH3D_NO_NINJA=1
经过长时间漫长的等待,中间不出错误的话,可以看到下面这张图片。
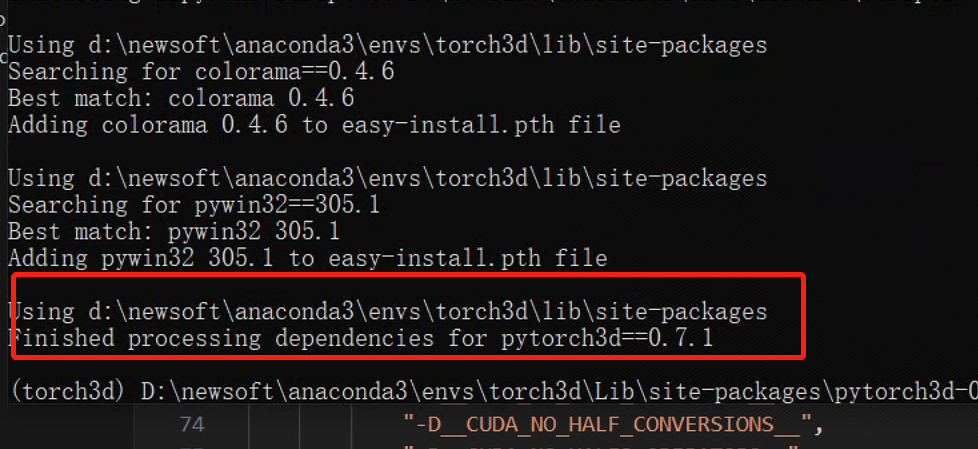
这样我们就成功编译了 torch3d 这个项目,接下来就是我们把 xuniren 这个项目 clone 下来,激活我们刚才创建的 torch3d 这个虚拟环境。在这个项目的 ReadMe 文档里有说到要用 VC ++ 编译器去编译 freqencoder, gridencoder, raymarching shencoder 这几个项目,其实这是 Nerf 项目所依赖的第三方库,如果后面用到数据训练的话,这些是必须要安装的。接下来我就演示一下如何编译这些文件。我是一个一个进行编译了,没有执行批处理命令。这里需要注意的两点就是需要把四个文件的 setup.py 文件里的代码,按照下面的格式进行修改。

cmdclass 里的 build_ext 加上 use_ninja=False, 然后把 ‘-03’, '-std=c++14' 注释掉,如下图:

这样就可以继续在 VC ++ 2019 的编译器下面进行逐个安装。需要在 xuniren 这个项目里对应的文件夹下面执行安装命令:
conda activate torch3d
set DISTUTILS_USE_SDK=1
python setup.py install
依次执行完之后就可以得到这四个依赖库安装成功的界面了。我这里当时过于激动只截了一张图,给大家看看。
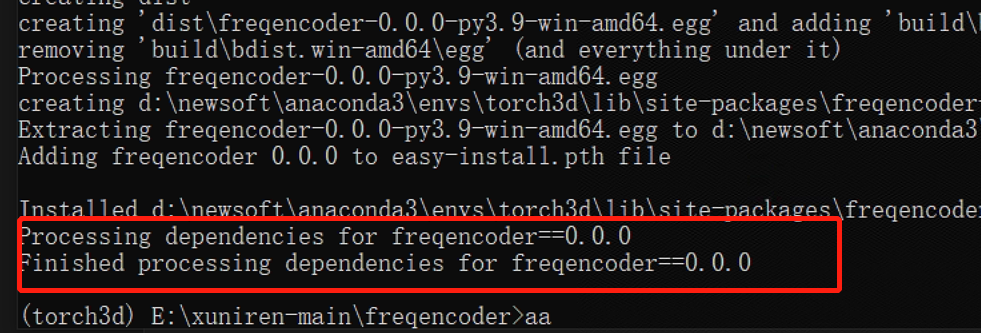
进行到这里的时候,应该会提示有些库有冲突了,我这里是pillow,我重新安装之后就可以了。这个项目用到了ffmpeg,Windows 系统下载一个即可,然后在环境变量配置一下即可。我安装的是ffmpeg-5.1.2 这个版本。
pip install pillow==9.0.0
如果你能进行到这里,那么你离这个项目 Run 起来就咫尺之遥了。接下来我们就可以执行项目中说的命令了。
python fay_connect.py
经过漫长的模型下载,就可以看到下面的这个运行窗口了。

不过不要高兴太早,每个令人兴奋的项目在最后的关键时刻总会有个小问题站出来,让你看不到心中的亮光。我们需要在fay_connect.py 这个文件里做一个小修改。把原来的方法 convert_mp3_to_wav("/" + old_path, new_path) 改成下面的就可以看到虚拟人张嘴,听到虚拟人说话了。当然你是需要把 Fay 控制器打开,才可以进行互动交流哦。
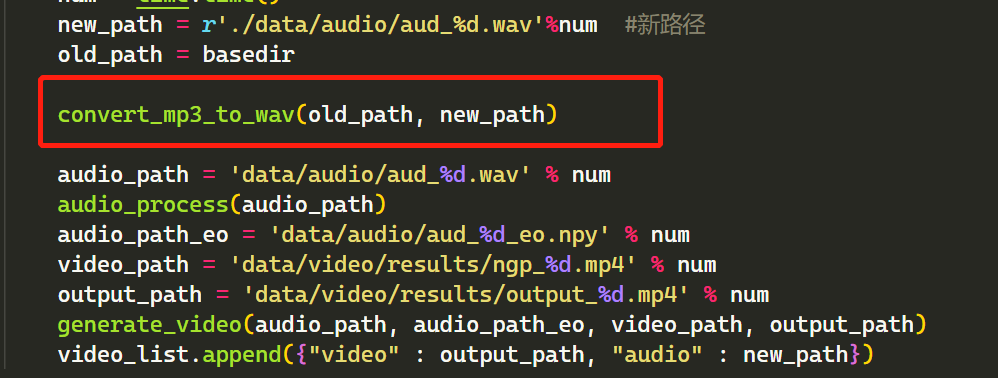
整个安装过程就是这样的,这里遇到最多的问题就是 C++ 编译的问题,找了很多资料都没有把这个虚拟人项目部署说得精准的,所以这篇文章就应运而生了,解决大家在部署过程中遇到的难题。对于训练自己的数字人,我这边也已经部署成功,只不过训练出来的数字人播报,远没有 metahuman 有意思。如果大家也有疑问,就给我留言吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号