
hadoop单机环境搭建
[在此处输入文章标题]
Hadoop单机搭建
1、 工具准备
1) Hadoop Linux安装包
2) VMware虚拟机
3) Java Linux安装包
4) Window 电脑一台
2、 开始配置
1) 启动Linux虚拟机,这里使用的是CentOS 6.7版本

2) 首先配置虚拟机网络环境
Ø 配置Windows网络环境
1、 打开VMware,编辑—虚拟网络编辑器
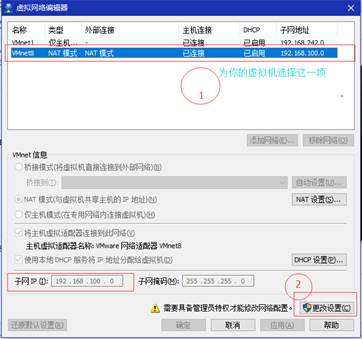
2、 修改子网IP为192.168.100.0
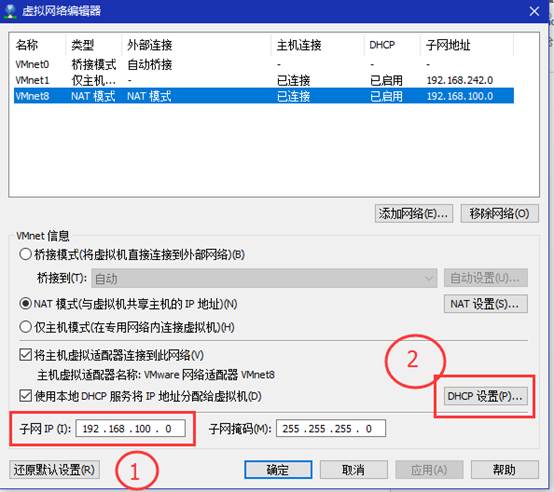
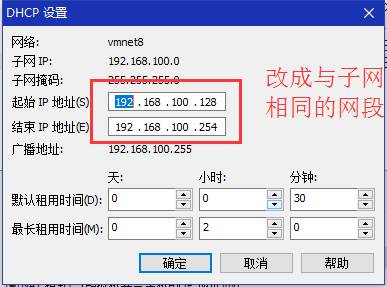
3、 继续修改子网详细配置
4、Windows网络环境配置完成
Ø 配置Linux网络环境
1、 配置Linux网络环境,这里使用CentOS6.7桌面,右键网络连接,编辑网络
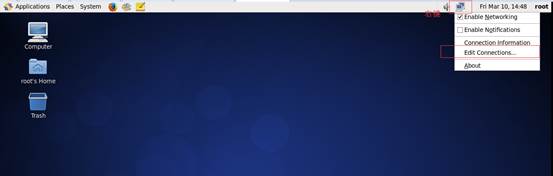
2、 编辑网络
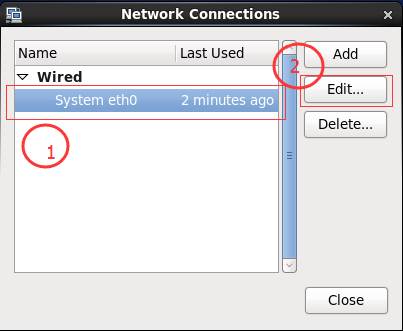
3、 edit,设置网卡
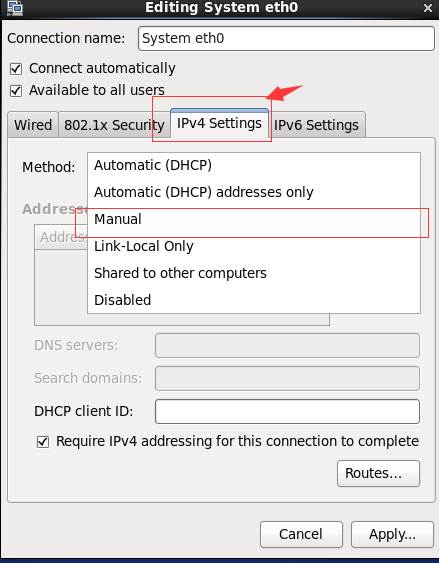
4、 Ipv4 Setting,Method选择Manual

5、 Add添加一个
输入
Address:192.168.100.101
Network:255.255.255.0
Gateway:192.168.100.1
DNS:119.29.29.29,182.254.116.116

6、 点击 Apply... 接下来设置Linux hosts文件
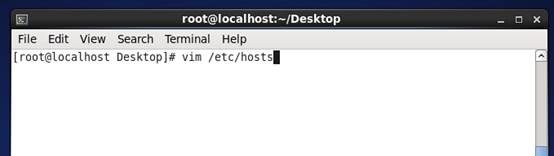
7、 右键Linux桌面,Open in Terminal

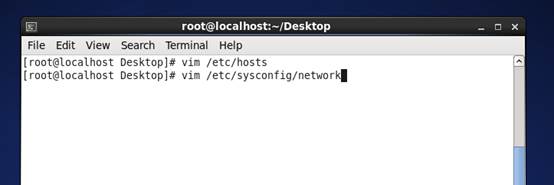
8、 Linux终端打开,输入 vim /etc/hosts
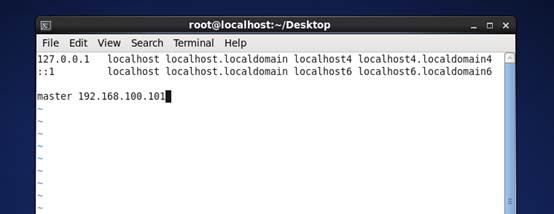
9、 打开hosts文件,添加记录 master 192.168.100.101
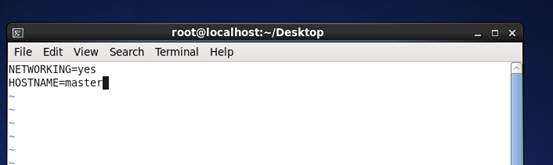
10、 保存退出,在终端输入 vim /etc/sysconfig/network
11、 修改network文件 HOSTNAME=master
12、 接下来,关闭Linux防火墙,并从自启项中取消启动
关闭防火墙命令:service iptables stop
取消自启/关闭自启:chkconfig iptables off
查看防火墙状态:service iptables status
查看防火墙的开机状态:chkconfig --list | grep iptables

13、 保存退出,Linux网络修改完成。输入 init 0 重启Linux
3) 接下来,安装jdk
a) 将jdk安装包拷贝到Linux /opt/soft 下(我这里用目录/opt/soft,可以选择其他任意目录)这里用的jdk为8u112版本
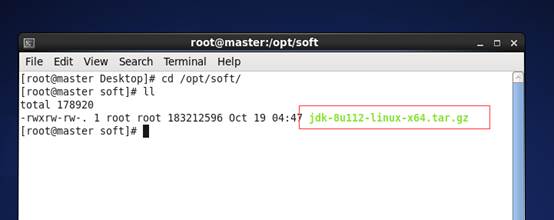
b) 输入命令 tar –zxvf jdk-8u112-linux-x64.tar.gz –C /opt/ 将jdk解压到opt目录下


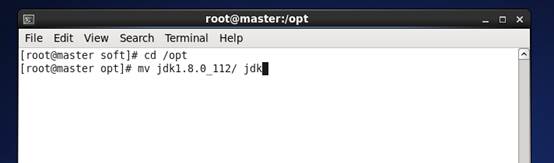
c) *修改jdk解压后的目录为jdk
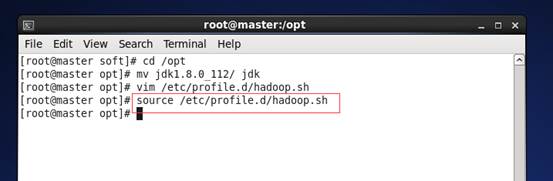
命令:cd /opt
mv jdk1.8.0_112/ jdk
d) 添加jdk路径到path路径中
命令:
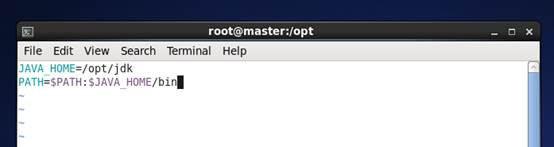
vim /etc/profile.d/hadoop.sh
添加
JAVA_HOME=/opt/jdk
PATH=$PATH:$JAVA_HOME/bin
e) 保存退出,输入命令 source /etc/profile.d/hadoop.sh,使配饰生效
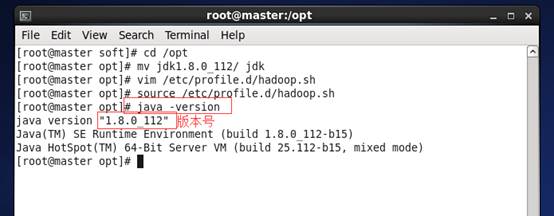
f) 输入 java –version 检验是否成功
4) 安装Hadoop
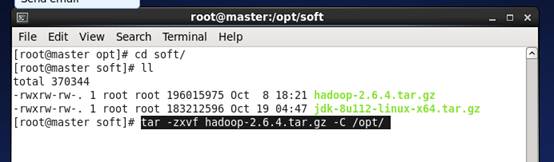
a) 将Hadoop安装包拷贝到 /opt/soft/ 下,我这里用的是2.6.4版本

b) 解压Hadoop安装包到/opt下, tar -zxvf hadoop-2.6.4.tar.gz -C /opt/

c) 修改解压后的目录名为hadoop

d) 添加Hadoop目录到path路径
命令:
vim /etc/profile.d/hadoop.sh
添加两行:
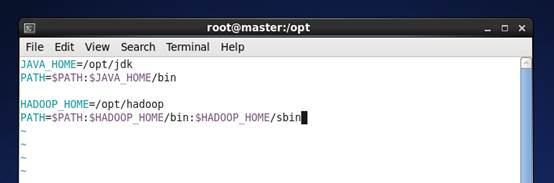
HADOOP_HOME=/opt/hadoop
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
e) 修改hadoop配置文件(配置文件目录 $HADOOP_HOME/etc/hadoop/)
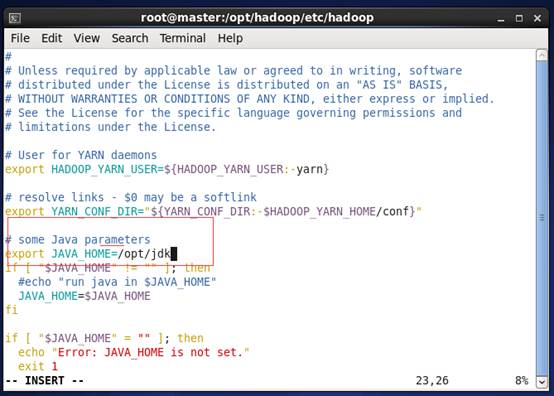
i. 修改hadoop-env.sh文件 export JAVA_HOME=/opt/jdk

ii. 修改yarn-env.sh 文件 export JAVA_HOME=/opt/jdk
iii. 修改hdfs-site.xml文件
1. <configuration>
2. <property>
3. <name>dfs.namenode.name.dir</name>
4. <value>file:///opt/hadoop-repo/name</value>
5. </property>
6. <property>
7. <name>dfs.datanode.data.dir</name>
8. <value>file:///opt/hadoop-repo/data</value>
9. </property>
10. <property>
11. <name>dfs.namenode.checkpoint.dir</name>
12. <value>file:///opt/hadoop-repo/secondary</value>
13. </property>
14. <!-- secondaryName http地址 -->
15. <property>
16. <name>dfs.namenode.secondary.http-address</name>
17. <value>master:9001</value>
18. </property>
19. <!-- 数据备份数量-->
20. <property>
21. <name>dfs.replication</name>
22. <value>1</value>
23. </property>
24. <!-- 运行通过web访问hdfs-->
25. <property>
26. <name>dfs.webhdfs.enabled</name>
27. <value>true</value>
28. </property>
29. <!-- 剔除权限控制-->
30. <property>
31. <name>dfs.permissions</name>
32. <value>false</value>
33. </property>
34. </configuration>
iv. 修改core-site.xml文件
1. <configuration>
2. <property>
3. <name>fs.defaultFS</name>
4. <value>hdfs://master:9000</value>
5. </property>
6. <property>
7. <name>hadoop.tmp.dir</name>
8. <value>file:///opt/hadoop-repo/tmp</value>
9. </property>
10. </configuration>
v. 复制一份mapred-site.xml.template 文件并修改为mapred-site.xml,修改其内容
1. <configuration>
2. <property>
3. <name>mapreduce.framework.name</name>
4. <value>yarn</value>
5. </property>
6. <!-- 历史job的访问地址-->
7. <property>
8. <name>mapreduce.jobhistory.address</name>
9. <value>master:10020</value>
10. </property>
11. <!-- 历史job的访问web地址-->
12. <property>
13. <name>mapreduce.jobhistory.webapp.address</name>
14. <value>master:19888</value>
15. </property>
16. <property>
17. <name>mapreduce.map.log.level</name>
18. <value>INFO</value>
19. </property>
20. <property>
21. <name>mapreduce.reduce.log.level</name>
22. <value>INFO</value>
23. </property>
24. </configuration>
vi. 修改yarn-site.xml文件
1. <configuration>
2. <property>
3. <name>yarn.nodemanager.aux-services</name>
4. <value>mapreduce_shuffle</value>
5. </property>
6. <property>
7. <name>yarn.resourcemanager.hostname</name>
8. <value>master</value>
9. </property>
10. <property>
11. <name>yarn.resourcemanager.address</name>
12. <value>master:8032</value>
13. </property>
14. <property>
15. <name>yarn.resourcemanager.scheduler.address</name>
16. <value>master:8030</value>
17. </property>
18. <property>
19. <name>yarn.resourcemanager.resource-tracker.address</name>
20. <value>master:8031</value>
21. </property>
22. <property>
23. <name>yarn.resourcemanager.admin.address</name>
24. <value>master:8033</value>
25. </property>
26. <property>
27. <name>yarn.resourcemanager.webapp.address</name>
28. <value>master:8088</value>
29. </property>
30. <property>
31. <name>yarn.log-aggregation-enable</name>
32. <value>true</value>
33. </property>
34. </configuration>
f) 创建hadoop数据储存目录
i. NameNode 数据存放目录: /opt/hadoop-repo/name
ii. SecondaryNameNode 数据存放目录: /opt/hadoop-repo/secondary
iii. DataNode 数据存放目录: /opt/hadoop-repo/data
iv. 临时数据存放目录: /opt/hadoop-repo/tmp
5) 至此单机版hadoop配置完成
6) 单机版hadoop的测试
a) 格式化hadoop文件系统
hdfs namenode -format
b) 启动hadoop
start-all.sh
////
启动成功之后,通过java命令jps(java process status)会出现5个进程:
NameNode
SecondaryNameNode
DataNode
ResourceManager
NodeManager
c) 验证
在浏览器中输入http://master:50070
欢迎来访 http://zy107.cn

 浙公网安备 33010602011771号
浙公网安备 33010602011771号