【转】PCIe资料总结
PCIE开发笔记(一)简介篇

这是一个系列笔记,将会陆续进行更新。
最近接触到一个项目,需要使用PCIE协议,项目要求完成一个pcie板卡,最终可以通过电脑进行通信,完成电脑发送的指令。这当中需要完成硬件部分,使用FPGA板实现,同时需要编写Windows下的驱动编写。初次接触到PCIE协议,网络上的相关教程不够清晰,让人看了之后不知所以然,不适合完全没有基础的人学习(就是我这样的人)。经过较长时间阅读相关文档,其中也走了不少弯路,最后对PCIE的IP核使用有了一定的了解,所以想写下这篇笔记,一来方便以后自己温习,而来帮助其他新入门的同学,避免一些不必要的弯路。
因为各种的PCIE设备的设计与使用都是依据PCIE协议的,所以首先我们需要对PCIE协议有一个大致的了解,了解的深度即不要太大(因为相关协议的文档长达数千也,而且有些你可能就不会用),也不能太浅,不然当你阅读Xilinx的PCIE的集成核时会一头雾水,因为你会不了解其中的一些寄存机,结构。
首先你需要下载这两个文档《PCI_Express_Base_Specification_Revision》,《PCI Express System Architecture》。第一个文档是将PCIE设备进行通信时包的格式,以及设备中的寄存器的含义和使用,可以看做是一本工具书,当你开发时关于接口,包格式,寄存器问题是随时可以查阅的文档,没有必要去细读它。第二个是非常有必要去读的一个文档,有一个减缩版可以让你快速对整个体系有一个了解。
我们的开发学习笔记就从第二本的内容开始,对pcie有一个大体的了解。首先我们都知道在电脑中有很多设备使用pcie总线,例如显卡,网卡,硬盘。
首先我们简单介绍一下PCIE,PCIE是一种串行通信协议。在低速情况下,并行结构绝对是一种非常高效的传输方式,但是当传输速度非常高,并行传输的致命性缺点就出现了。因为时钟在高速的情况下,因为每一位在传输线路上不可能严格的一致,并行传输的一个字节中的每个位不会同时到达接受端就被放大了。而串行传输一位一位传输就不会出现这个问题。串行的优势就出现了,串行因为不存在并行的这些问题,就可以工作在非常高的频率下,用频率的提升掩盖它的劣势。
PCIE使用一对差分信号来传输一位信号,当D+比D-信号高时,传输的是逻辑1,反之为0,当相同时不工作。同时PCIE系统没有时钟线。
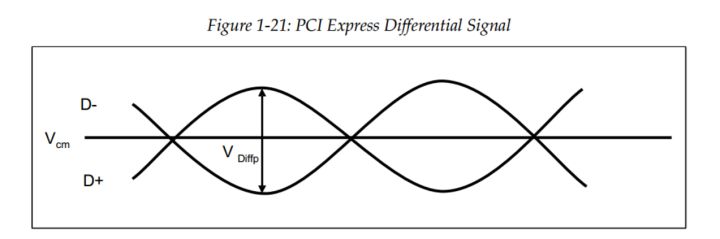
下面了解一下pcie总线的拓扑结构。
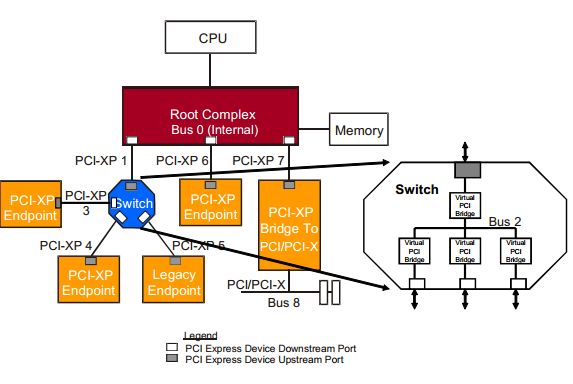
Fig.1 PCIE拓扑结构
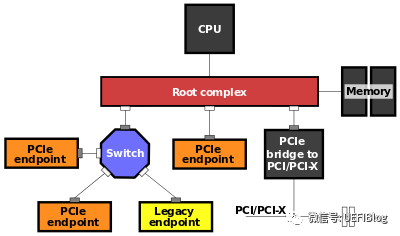
从Fig1可以看出这个拓扑结构,CPU连接到根聚合体(Root Complex),RC负责完成从CPU总线域到外设域的转换,并且实现各种总线的聚合。将一部分CPU地址映射到内存,一部分地址映射到相应的相应的设备终端(比如板卡)。
pcie设备有两大类,一种是root port,另一种Endpoint。从字面意思可以了解这两类的作用,root port相当于一个根节点,将多个endpoint设备连接在一个节点,同时它完成数据的路由。上图中的Switch就是一个root port设备。而endpoint就是最终数据的接受者,命令的执行者。
这里我们就对pcie总线在计算机结构中的位置有一个大致的了解,下面我们对pcie数据的传输方式进行一个简单的介绍。pcie数据的传输方式类似于TCP/IP的方式,将数据按数据包的格式进行传输,同时对结构进行分层。
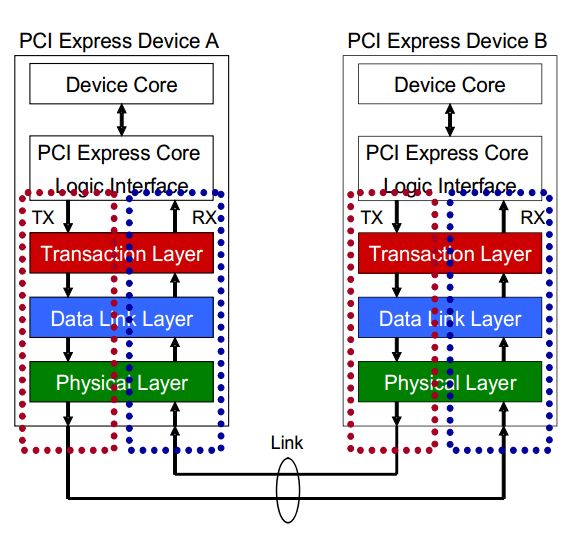
Fig.2 PCIE Device layers
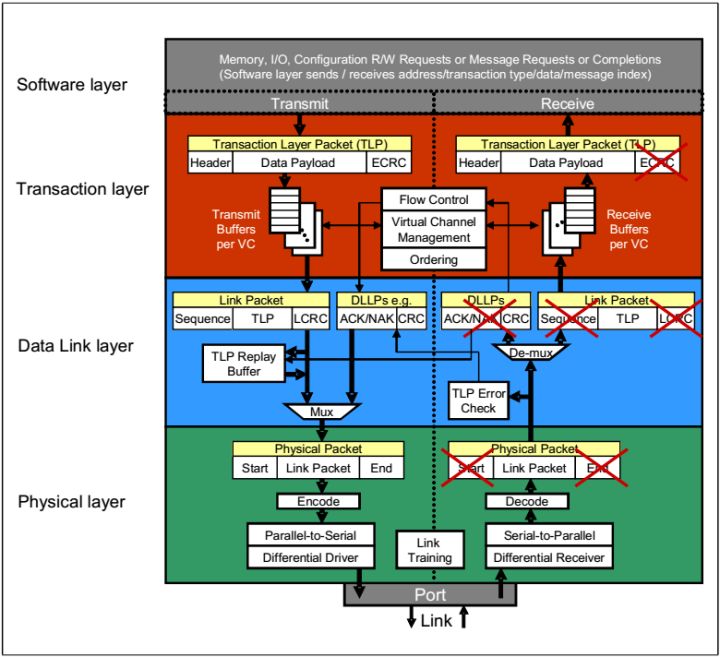
Fig.3 Detailed Block Diagram of PCI Express Device's Layer
PCIE的设备都具有这几个结构,每个结构的作用不同。我们首先说明数据传输时候的流程,PCIE协议传输数据是以数据包的形式传输。
首先说明在发送端,设备核或者应用软件产生数据信息,交由PCI Express Core Logic Interface将数据格式转换TL层可以接受的格式,TL层产生相应的数据包。然后数据包被存储在缓冲buffer中,准备传输给下一层数据链层(Data Link Layer)。数据链层将上一层传来的数据包添加一些额外的数据用来给接收端进行一些必要的数据正确性检查。然后物理层将数据包编码,通过多条链路使用模拟信号进行传输。
在接收端,接收端设备在物理层解码传输的数据,并将数据传输至上一层数据链层,数据链层将入站数据包进行正确性检查,如果没有错误就将数据传输至TL层,TL层将数据包缓冲buffer,之后PCI Express Core Logic Interface将数据包转换成设备核或者软件能够处理的数据。
我们使用IP核进行开发时,这三个层都已经写好了。所以我们的主要的任务就是写出fig.2中PCI Express Core Logic Interface,从他的字面我们就可以明白他的作用,就是一个接口,将数据从Device Core输出的数据格式转换IP核TL层接受的数据格式。
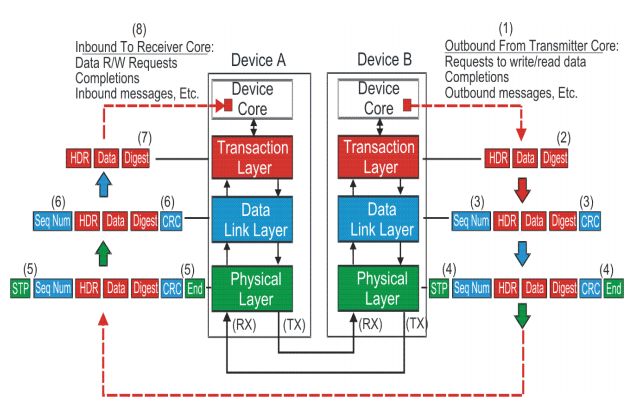
Fig.4 pcie数据包的处理
在TLP包传输的过程中会发生数据包的组装和拆解。
TLP包的组装
当数据从软件层或者设备核传来之后,TL层添加ECRC,
在DLL层在前段添加序列数字,在后面添加DLL层的CRC,
在物理层添加帧头和帧未。
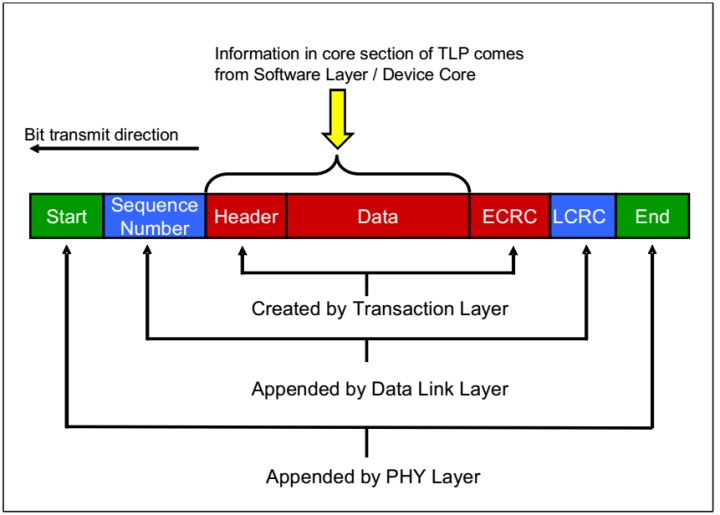
Fig.5 TLP Assembly
TLP的拆解是一个反过程。如Fig.6
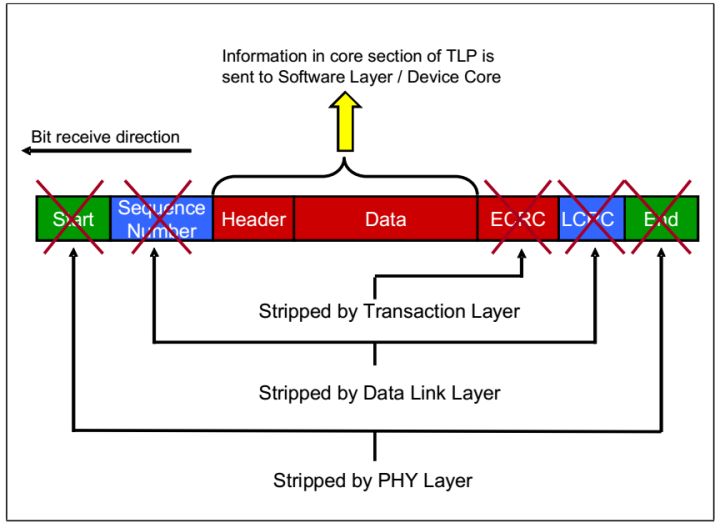
Fig.6 TLP Disassembly
到这里笔记(一)就结束了。
PCIE开发笔记(二)TLP类型介绍篇
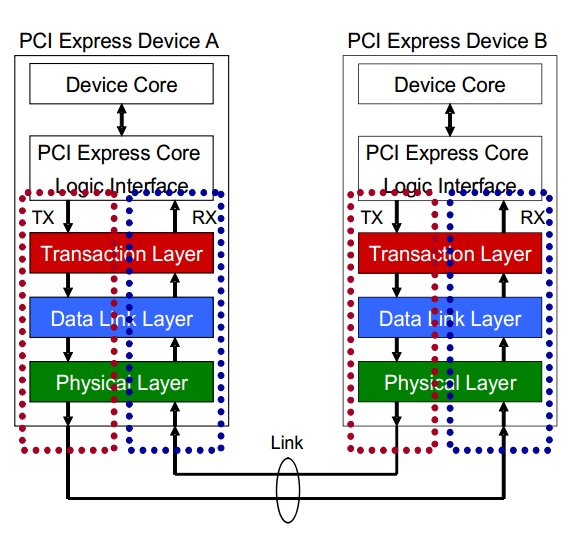
我们在学习笔记(一)中对PCIE协议有一个大致的了解,我们从他的拓扑结构可以看出PCIE设备是以peer to peer结构连接在一起的。并且点到点之间是以数据包的形式传输的。这篇笔记我们就对数据包进行一个大致的讲解。
我们上一篇说到,PCIE在逻辑上分为三层,分别是
1.TL层,对应数据包为TLP
2.数据链层(Data Link Layer),对应数据包为DLLP
3.物理层(PHY Layer),对应数据包为PLP
DLLP和PLP只会在相邻的两个设备之间传递,不会传递给第三个设备。
这里我们把重点着重放在TL层产生的TLP数据包。
我们首先给TLP数据包进行一个分类,主要可以分为以下四类:
1.与memory有关
2.与IO有关
3.与配置(configuration)有关
4.与消息(message)有关
configuration TLP是用来对PCIE设备进行配置专用的数据包,例如可以修改设备寄存器的值。
详细如table 1所示。
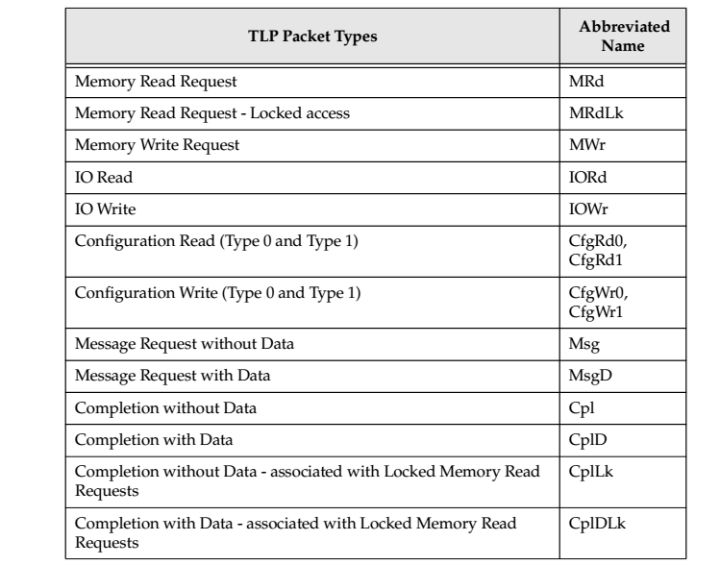
table.1
同时我们还可以从数据包从发送方到达接受方之后接受方是否返回一个数据包,将TLP分为两类:
1.Posted 接受方不返回数据包
2.Non_posted 接收方返回数据包
数据包相应的对应关系如table 2所示。
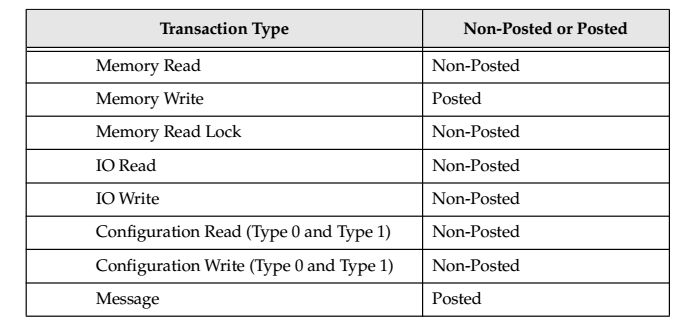
table.2
我们可以从它们的字面意思很轻易的理解它们。(configuration数据包是用来配置PCIE设备的专门的数据包,message是用来传递中断,错误信息,电源管理信息的专用数据包)
如何去辨别TLP的类型那?他们的差别主要在TLP Header中,TLP Header有两种格式,一种长度为3DW,一种为4DW。在TLP Header的Byte 0中有Fmt和Type两个部分,他们一起来表示TLP的类型。不同的类型长度不一样,详细参照table.3。
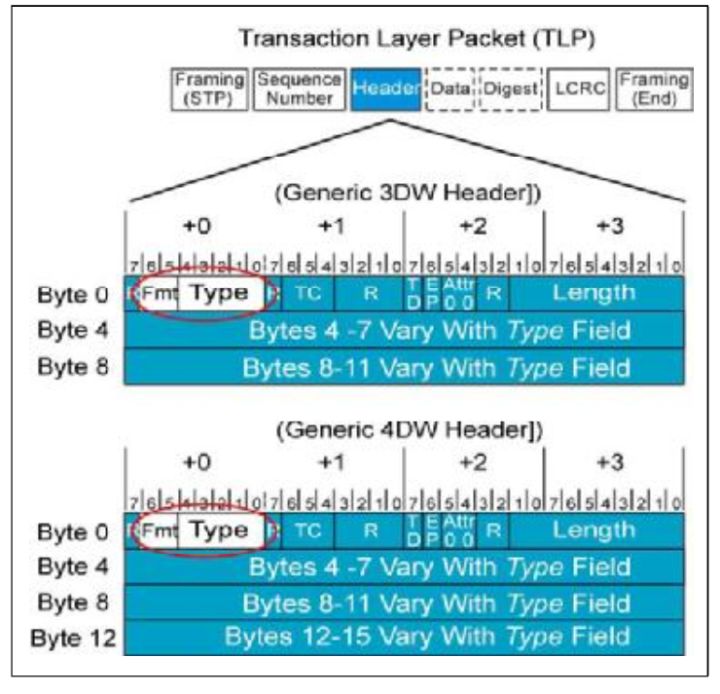
fig.1
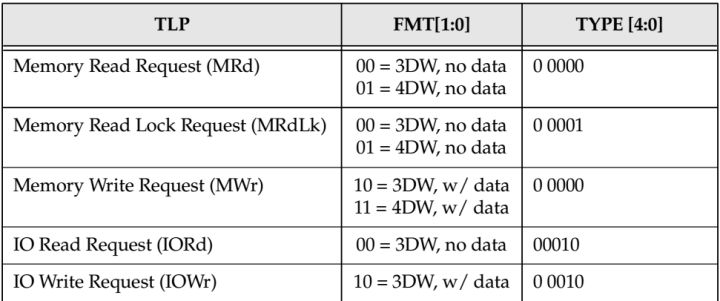
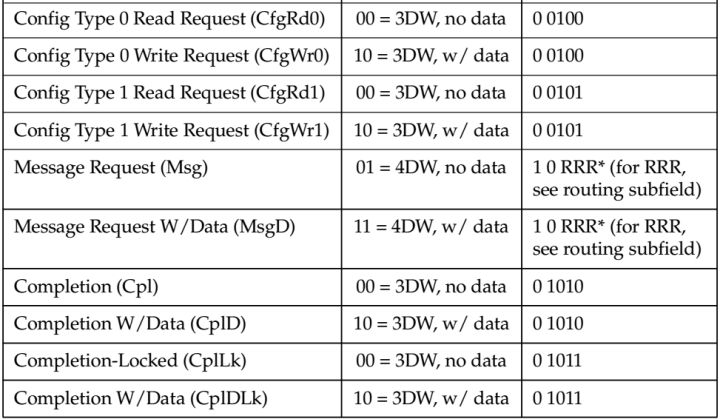
table.3
下面我们详细的介绍它们。
1.Non-Posted Read Transactions操作
请求者(Requester)请求一个操作,数据包可以是MRd,IORd,CfgRd0,CfgRd1。当接受者(Completer)接受之后,完成响应操作,之后返回一个数据包,可能是CplD或者Cpl。
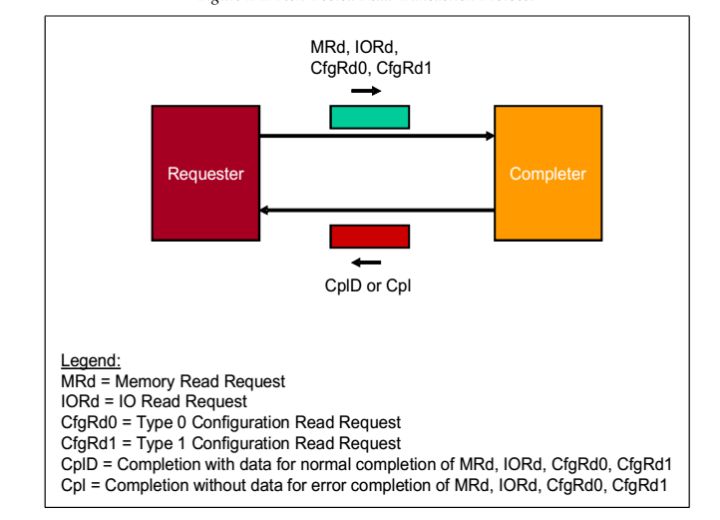
fig.2
2. Non-Posted Locked Read Transaction操作
请求者(Requester)请求一个操作,数据包是MRdLk.当接受者(Completer)接受之后,完成响应操作,之后返回一个数据包,可能是CplDLk或者CplLk。在Requester接受到Completion之前,数据包传递路径锁定。
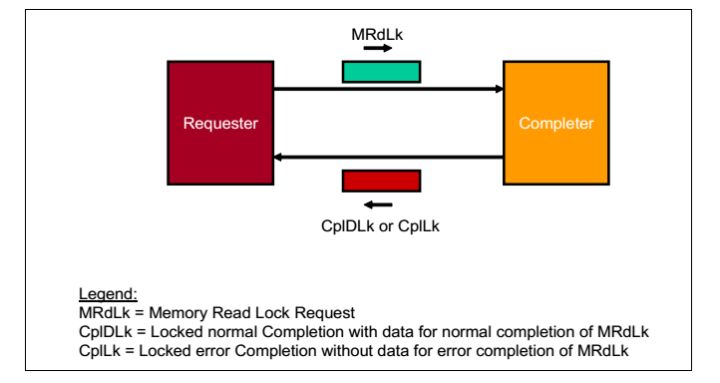
fig.3
3.Non-Posted Write Transactions 操作
请求者(Requester)请求一个操作,数据包是IOWr,CfgWr0,CfgWr1。当接受者(Completer)接受之后,完成响应操作,之后返回一个数据包,是Cpl。
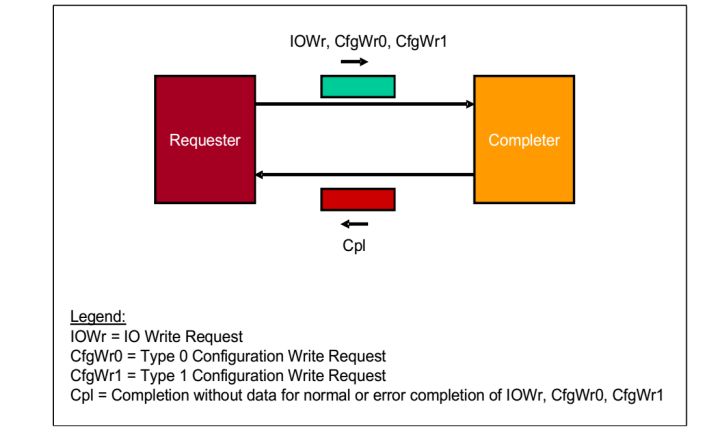
fig.4
4.Posted Memory Write Transactions 操作
请求者(Requester)请求一个操作,数据包是MWr.当接受者(Completer)接受之后,不做任何反应。
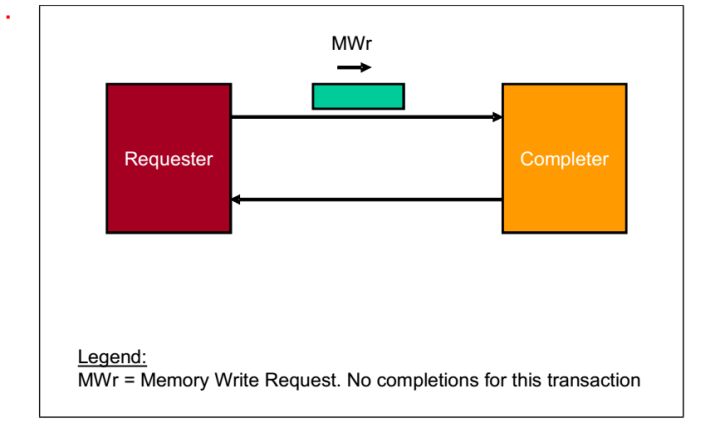
fig.5
5.Posted Message Transactions 操作
请求者(Requester)请求一个操作,数据包是Msg,MsgD.当接受者(Completer)接受之后,不做任何反应。
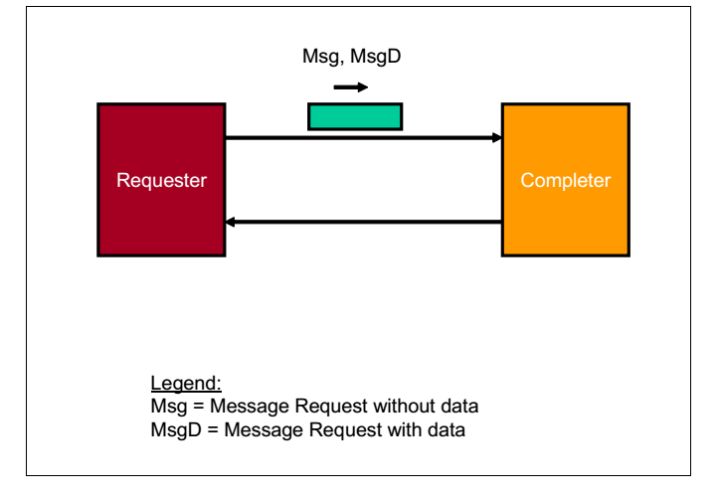
fig.6
下面我们举一些实际的例子:
1.CPU读取一个PCIE设备的memory
在PCIE的拓扑结构中,有一个非常重要的结构,它就是Root Complex(RC)结构。顾名思义,它负责将几个不同的总线协议聚合在一起,如内存的DDR总线,处理器的前端总线Front Side Bus(FSB)。在PCIE中,CPU的操作实际是由RC代替完成的,所以一定程度上也可以讲RC代表CPU。
所以当CPU想要访问Endpoint时
Step1:CPU让RC产生一个MRd,经过Switch A,Switch B(第一篇讲到过Switch),到达Endpoint。
Step2: Endpoint 接受数据包,进行数据读取。
Step3:Endpoint返回一个带有数据的Completion.
Step4: RC接受数据包,给CPU。
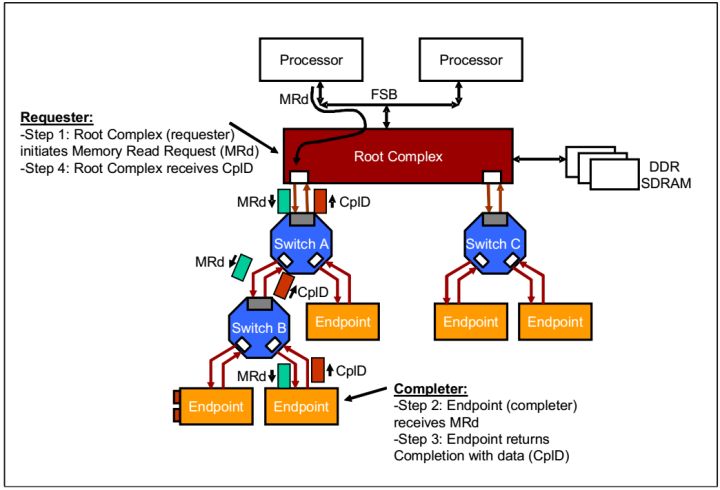
fig.7
其他类型就不再一一赘述了。这里TLP的分类就告一段落。
PCIE开发笔记(三)TLP路由篇
前两篇我们对TLP有一个大致的了解,现在有一个问题摆在我们面前,当一个设备想和另一个设备进行通信时,TLP是怎么找到这条路径,从而进行传播的,这就是路由问题。
上一篇我们讲过PLLP,PLP只在临近的两个设备之间传播,所以不存在路由问题。而TLP会在整个拓扑结构中传播,所以存在这个问题。
要路由首先要能明确的表示一个地址,寄存器,或者一个设备。
所以要介绍几个概念。
首先介绍一下地址空间(Address Space)这个概念。
系统将一部分地址分配给内存(System Memory),一部分(MMIO,Prefetchable Memory Devices)分配给外设(如PCIE外设)。IO接口也是这个样子。这样就可以用一个统一的方式命名系统的存储空间。这称之为地址空间。
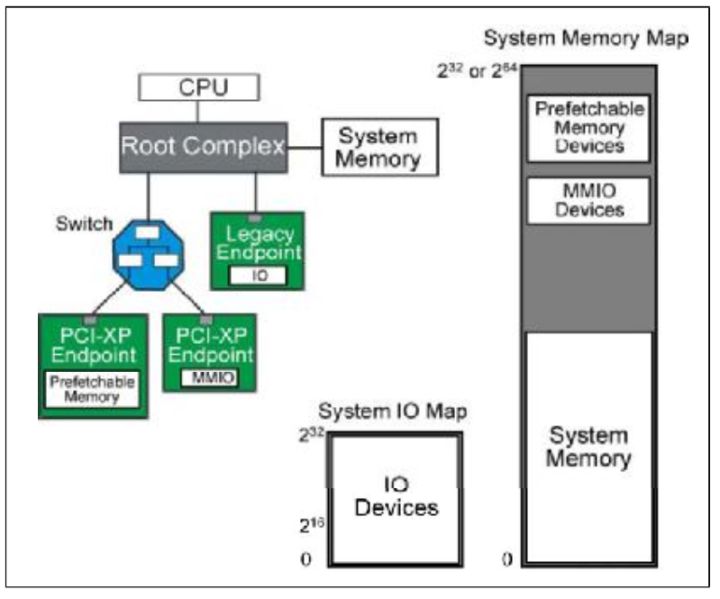
fig.1
同时,在整个系统初始化之后,每个设备会有一个设备号,总线号,功能号(Device number,ID Bus Number,Function Number),这样也可以唯一的确定一个设备。这些信息存储在设备的configurection头里面。
TLP路由总共有三种方式:
1.Address Routing 根据地址路由
2.ID Routing 根据ID路由
3.Implicit Routing 隐式路由
不同类型的TLP的路由方式不一样,具体如table.1.
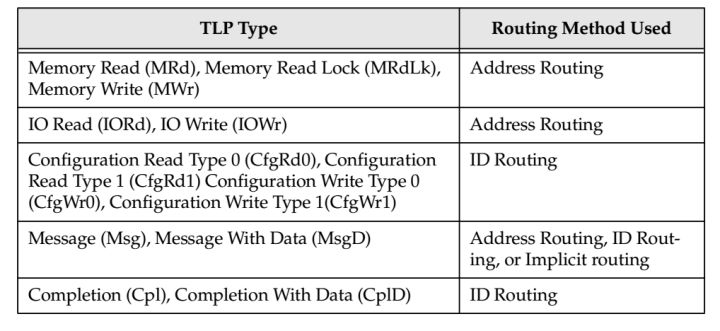
table.1
如果我们仔细思考会发现这样的路由方式是非常合理的
在PCIE拓扑结构中能够进行路由的结构只有Switch和RC。所以我们有必要介绍一下它们。 Switch就是一个多端口设备,用来连接多个设备。Switch可以理解为一个双层桥结构,其中还包含一个虚拟总线连接这个双层桥。其中每个桥设备(Bridge)一端连接到一个外部PCIE设备,一段连接到虚拟总线。对Switch结构进行Configuration配置是使用Type 1。
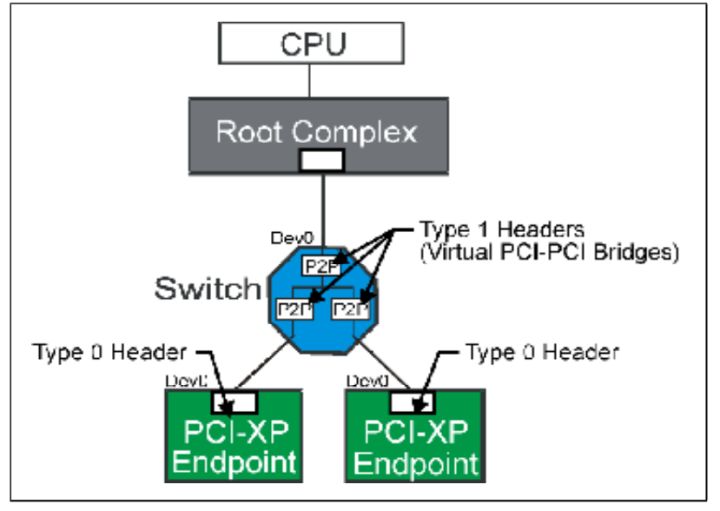
Fig.1
对于需要进行路由的设备,当它接受到一个TLP时,首先会判断这个TLP是不是发送给它自己的,如果是,接受它,如果不是,那就继续路由转发。
现在我们一一介绍:
1.Address Routing
当PCIE设备想访问内存(system memory)时,或者CPU想访问PCIE设备的memory时,使用一个含有地址请求包,这个时候就是Address Routing方式。
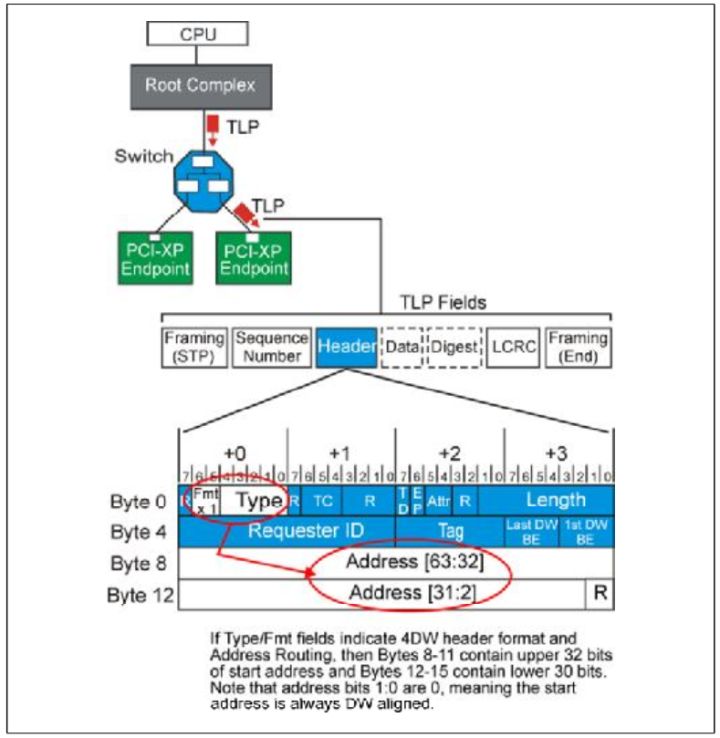
Fig.2
当一个Endpoint设备接受一个TLP之后,设备会首先检查它的Header中的Fmt和Type,如果属于Address Routing,检查是3DW还是4DW地址。然后设备将会对比设备的Configuration中的Base Address Register和TLP头中的地址,如果相同,就接受这个TLP,不相同就拒绝。
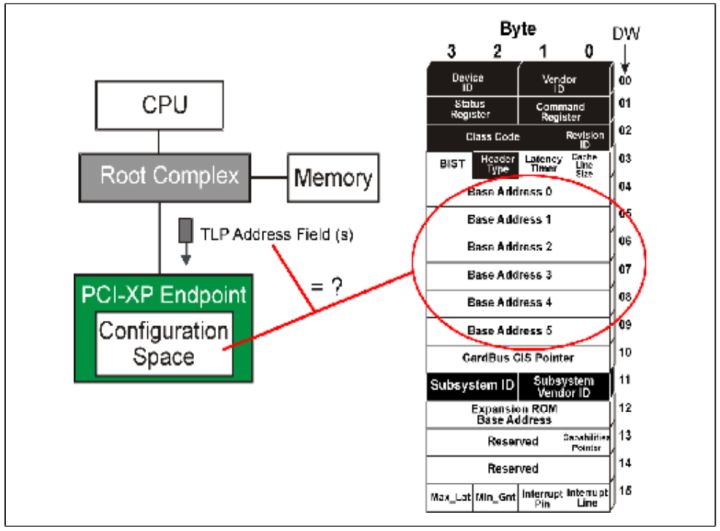
Fig.3
当一个Switch设备接受一个TLP之后,首先检查是否为Address Routing,如果是,那它就对比TLP中目的地址和自己的Configuration中的Base Address Register,如果相同,就自己接受这个数据包,如果不同,它会去检查是否符合它下游设备的Base/Limit Register地址范围。
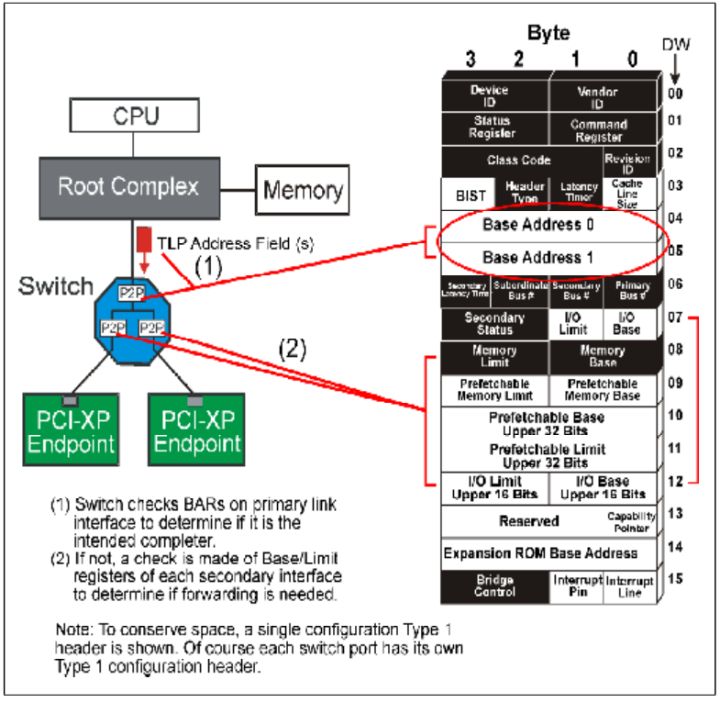
Fig.4
关于Switch补充下列几点:
- 如果TLP中的地址符合它下游的任意一个Base/Limit Register地址范围,它就会将数据包向下游传递。
- 如果传递到下游的TLP不在下游设备的BAR(Base Address Register)或者Base/Limit Register。那么下游就向上游传递一个unspported请求。
- 向上游传播的TLP永远向上游传播,除非TLP中的地址符合Switch的BAR或者某个下游分支。
2.ID Routing
当进行Configuration Write/Read,或者发送Message时使用ID,都将使用ID Routing方式。
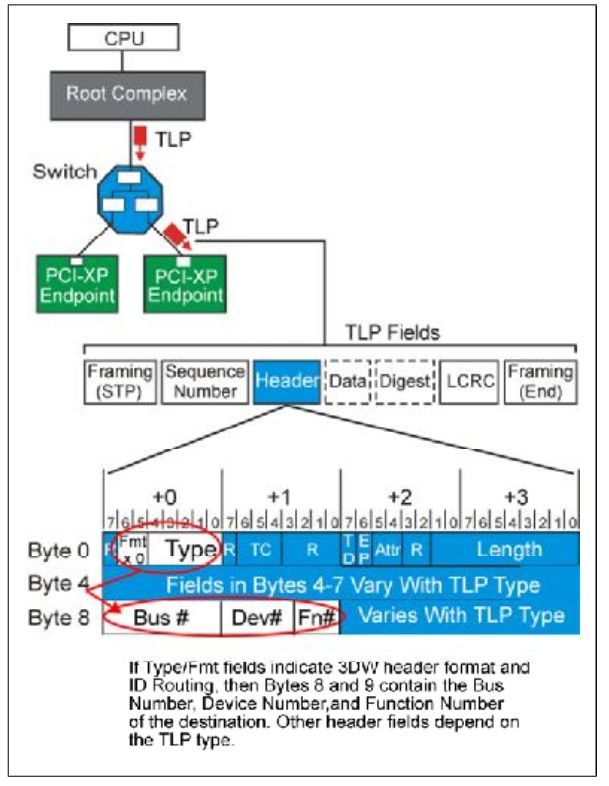
Fig.5
当一个Endpoint设备接受到一个ID Routing TLP之后,它会对比它在初始化时得到的Bus#,Dev#,Fn#,如果相同, 就接受,不接受就拒绝这个消息。如Fig.5所示。当系统Reset之后,所有设备的ID都变为0,并且不接受任何TLP,直到Configuration Write TLP到达,设备获取ID,再接受TLP。
当一个Switch设备接受一个TLP时,它会首先判断这个TLP的ID的自己的ID是否相同,如果相同,它就内部接受这个TLP。如果不相同,它就检查它是否和它的下有设备的ID是否相同。
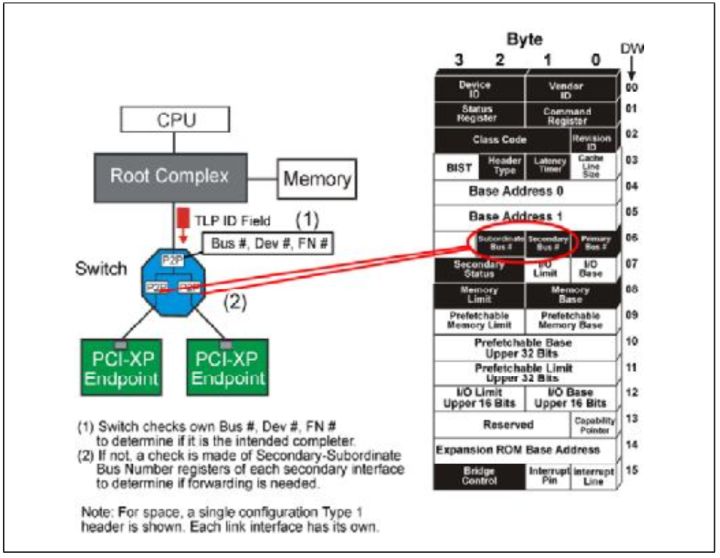
Fig.6
关于Switch补充下列几点:
- 如果TLP的ID和它的下游任意接口的configuration中的Secondary-Subordinate Register符合,它就向下游传播这个包。
- 如果传递到下游的TLP不和下游设备自身的ID符合。那么下游就向上游传递一个unspported请求。
- 向上游传播的TLP会一直向上游传播,除非TLP是传递给Switch或者某个分支的。
3.Implicit Routing
只有Message使用Implicit Routing。详细信息见Table.2。
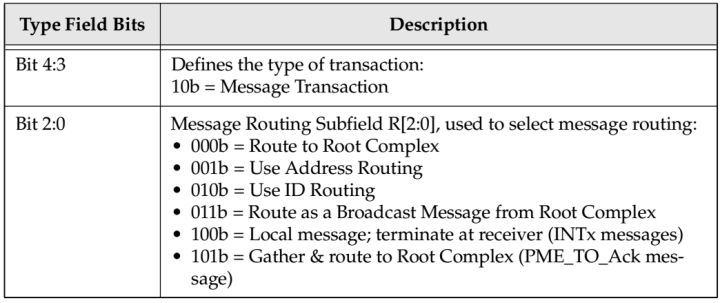
Table.2
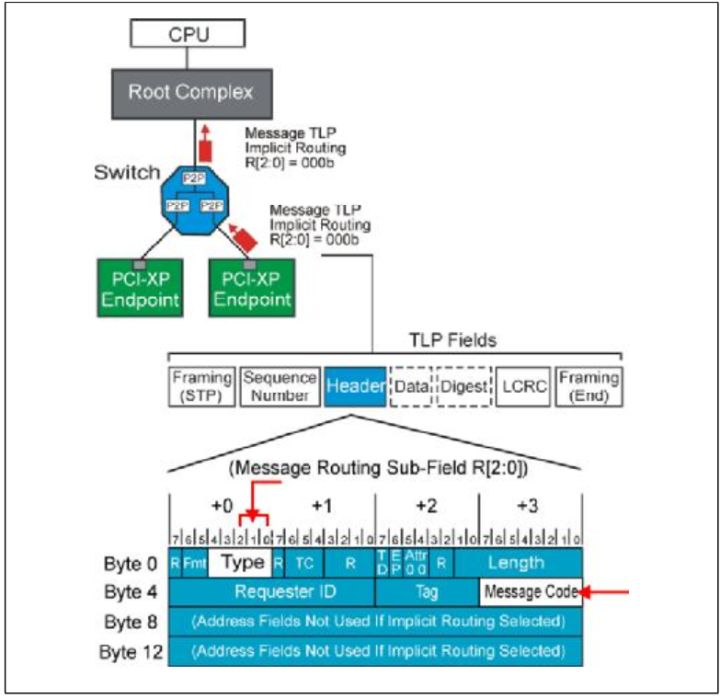
Fig.7
当一个Endpoint设备接受到一个Implicit Routing TLP之后,它只会简单的检查这个TLP是不是适合自己,然后去接受。
当一个Switch设备接受一个TLP时,它会考虑这个TLP接受的端口,并根据它的TLP头判断这个TLP是不是合理的。例如
- Switch设备接受一个从上游来的Broadcast Message之后,它会转发给自己所有的下游连接,当Switch从下游设备接受一个Broadcast Message之后,它会把它当做一个畸形TLP。
- Switch设备在下游端口接受到一个向RC传播的TLP,它会把这个TLP传播到所有的上游接口,因为它知道RC一定在它的上游。反之,如果从它的上游接受一个这样的TLP,那显然是一个错误的TLP。
- 如果Switch接受一个TLP之后,TLP表示应该在他的接受者处停止,那么Switch就接受这个消息,不再转发。
到这里三种路由方式就介绍完成了。
PCIE开发笔记(四)PCIE系统configuration和设备枚举篇
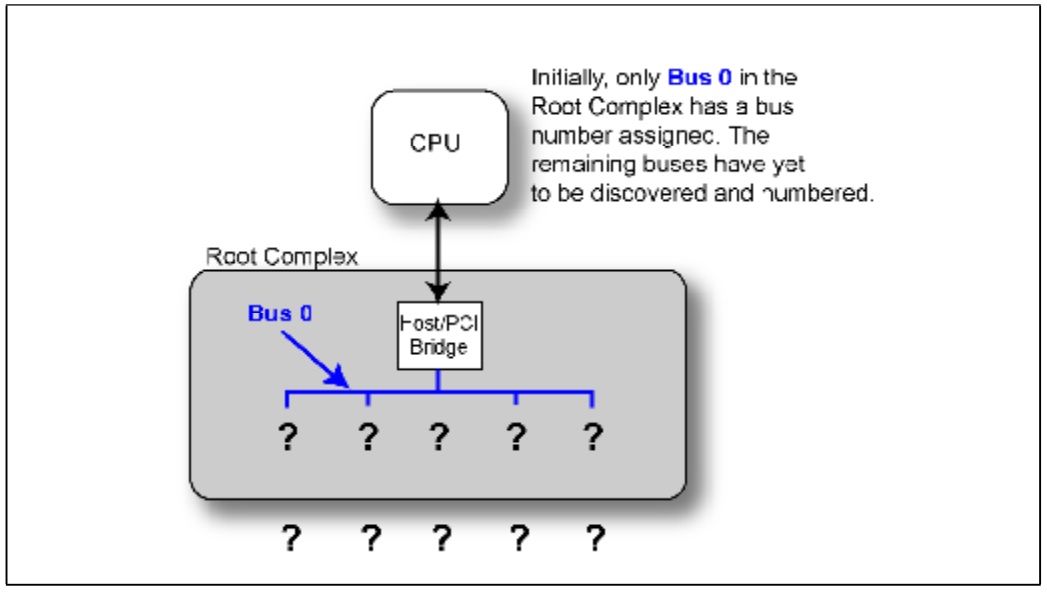
在上一篇我们介绍了路由方式。其中有ID Routing这种方式。但是我们应该有一个疑惑,就是设备它的Bus Number,Device Number,Function Number是怎样得到的。
首先我们可以排除一种情况,就是这些ID不可能是硬编码在设备中的,应为PCIE拓扑结构千变万化,如果使用硬编码那就与这种情况矛盾。实际上在一个PCIE系统在Power On或者Reset之后,会经历一个初始化和设备枚举的过程,这个枚举过程结束之后就会得到他的所有ID。
现在我们就开始介绍PCIE设备是怎么被发现的,整个拓扑结构是怎么建立的。
首先,在一个PCIE Device中支持最高8个Function,那什么是Function?一个设备它可以同时具有几个功能,每个功能对用一个Function,且每个Function必须拥有一个Configuration来配置他的必要属性。且如果一个设备只有一个Function,那么他的Function Number必须为0,如果这个设备是一个多Function的设备,那么它的第一个Function Number必须为0,其余的Function Number可以不必按照顺序递增。
我们再介绍几个概念,Rrimary Bus代表的一个桥设备直接相连的上游Bus Number。Secondary Bus代表的一个桥设备直接相连的下游Bus Number。Sub Bus Number代表这个桥下游最远的Bus Number。
在设备启动之后整个系统的拓扑结构是未知的,只有RC内部总线是已知的,命名为Bus 0,这是硬件编码在芯片当中的。
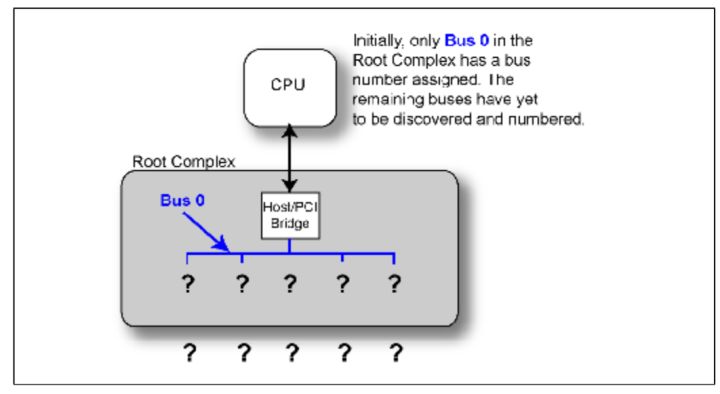
Fig.1
那么系统是怎么识别一个Function是否存在哪?我们以Type 0结构的Configuration为例,有Device ID和Vendor ID,它们都是硬编码在芯片当中,不同的设备有着不同的ID,其中值FFFFh保留 ,任何设备不能使用。当RC发出一个Configuration读请求时,如果返回的不是FFFFh,那么系统就认为存在这样的设备,如果返回的为FFFFh那么系统就认为不存在这个设备。

Fig.2
在上一篇中我们说到过,这个系统中,只有RC能进行Configuration Write操作,否则整个体系会发生混乱。
那么RC是怎么产生一个Configuration Write或者Configuration Read操作的?我们都知道RC只是代替CPU进行操作的,那么CPU怎么样才能让RC产生一个这样的操作那?有几种想法可以实现,例如,我们把所有Configuration空间映射到系统的Memory Space中,但是如果系统存在大量的设备,那么将占据大量的Memory Space,这样是不高效的。所以一个非常聪明的方法被提出(另外一种方法这里就不提了)。
系统将IO Space中从0CF8h-0CFBh这32bit划分为Configuration Address Port,将0CFCh-0CFFh这32bit划分为Configuration Data Port。
Configuration Address Port有一下定义:
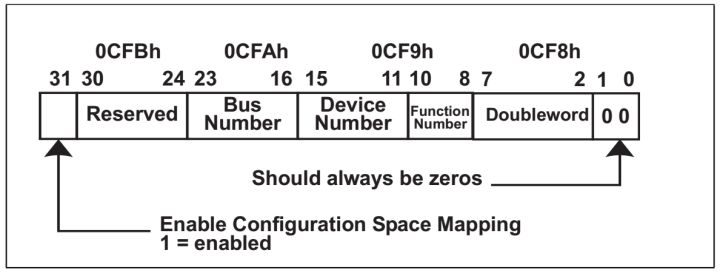
Fig.3
- Bit0-1是硬编码进芯片的。
- Bit2-7定义Target dword,表明要写的comfiguration space的位置。Configuration Space总计有64个Dword。
- Bit8-23为目标的ID。
- Bit31为使能位,为一时使能工作。
当CPU想要进行一个Configuration Write时,它只需在Configuration Address Port写进它的地址,和Target dwor。在Configuration Data Port写入数据,使能就完成一个配置写操作了。当CPU从Configuration Data Port进行读操作就完成配置读操作了。
以前说到Configuration 分为Type 0和Type 1两类。这里我们说明一下它们的区别。
首先它们的TLP Header不一样,但是它们最大的不同如下:
当CPU产生一个Configuration Write时,如果写的目的Bus等于RC的Bus,那RC会直接产生一个Type 0,然后Bus中的某个设备接受它。如果不相同,那么它将产生一个Type 1,并且继续向下传播。下游的桥接受后,它会是首先对比目的Bus和自己的Secondary Bus,如果相同的话,它会将这个TLP从Type 1转化为Type 0,然后Bus上的某个设备接受它,如果Secondary Bus<目的Bus,这个桥设备不对这个TLP进行类型转换,继续向下传播,直到目的Bus=Secondary Bus再完成类型转换。**
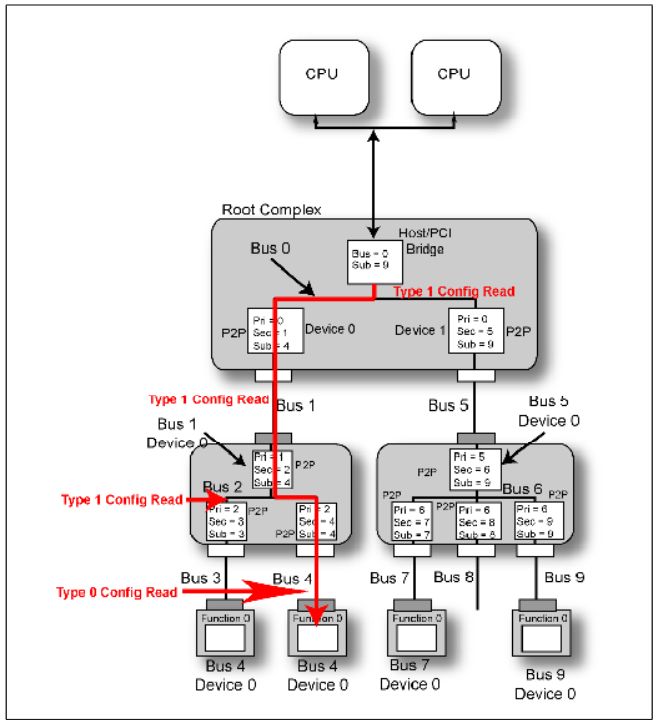
Fig.4
现在我们开始介绍如何进行设备枚举。
在系统上电或者Reset之后,设备会有一个初始化的过程,这个过程中设备的寄存器都是无意义的,当初始化之后,所有寄存器数据稳定并且有意义。这是才可以进行Configuration和设备的枚举。
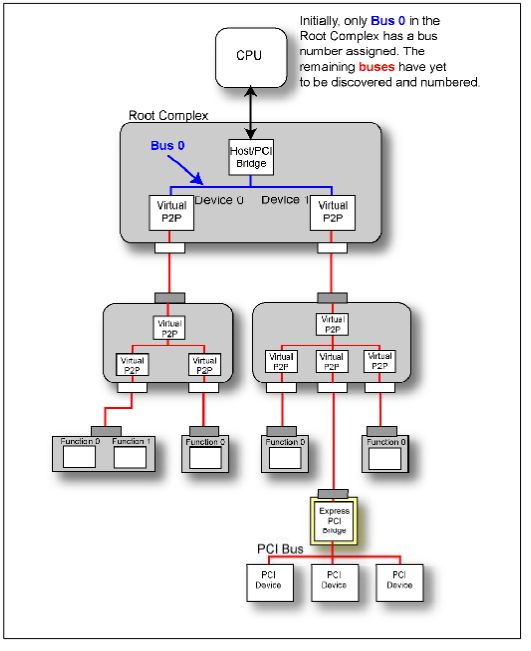
Fig.5
在系统完成初始化之后,整个系统如Fig.3所示,只有RC中的Bus被硬编码为Bus 0。这时枚举程序开始工作,首先他将要做的是:
1.枚举程序将要探测Bus 0下面有几个设备,PCIE允许每个总线上最多存在32个Device。上面我们已经介绍了怎么探测一个设备是否存在,这时RC将要产生一个Configuration Read TLP,目的ID为Bus 0,Device 0,Function 0,读取Vendor ID,如果返回的不是FFFFh,那表明存在Device 0,Function 0。跳到下一步。如果返回为FFFFh,那就表明一定不存在Device 0。那么程序就开始探测是否存在Bus 0,Device 1,Function 0。
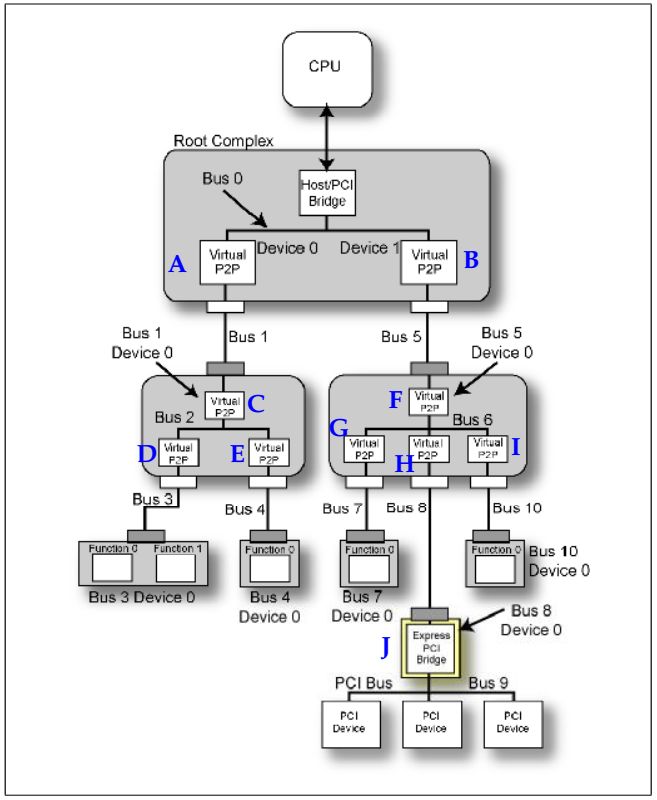
Fig.6
2.上一步探测到Device 0(Fig.2中的A)存在。在设备的Header Type field中存在Header Type Register,Capability Register。这两个Register表明Device的一些特性。Header Type Register的Bit 7表明他是否是一个多功能设备(Multi-function Device)。Capability Register的Bit4-7表明这个设备的类型,详细如Table.1。假设现在枚举程序开始读取Bus 0,Device 0,Function 0的这两个寄存器,返回Header Type数据为00000001b,表明这是一个单Function,桥设备说明它还有下游设备即存在Bus 1。
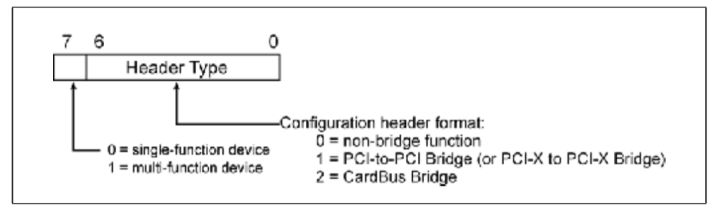
Fig.7 Header Type Register
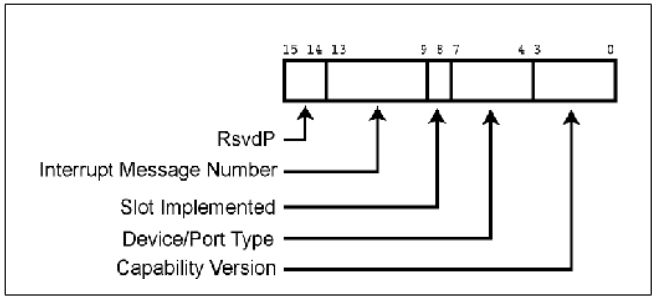
Fig.8 Capability Register
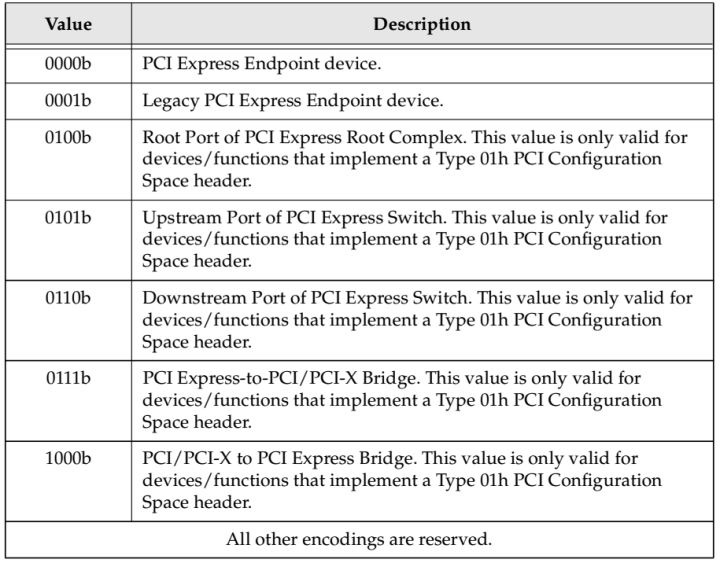
Table.1
3.现在程序进行一系列Configuration Write操作,将A设备(Fig.2)的Primary Bus Number Register=0,Secondary Bus Number Register=1,Subordinate Bus Number Register=1.现在桥A就可以感知他的下游总线为Bus 1,下游最远的总线为Bus 1.
4.程序更新RC的相关寄存器。
5.程序读取A的Capability Register,得到Device/Port Type Field=0100b,表明这是RC的一个Root Port。
6.程序必须执行Depth-first Search。也就是说在探测Bus 0上的其他设备,程序应该首先探测Device A下面的所有设备。
7.程序读取Bus 1,Device 0,Function 0的Vendor ID,一个有效的值返回,表示存在这个设备C。
8.读取Header Type field,返回00000001,表明C是一个桥,且C是一个单功能设备。
9.C的Capability Register Device/Port Type Field=0101b,表明这是一个Switch的上行端口。
10.程序对C重复像步骤3一样的操作。
11.同时更新Host/bridge和桥A的Subordinate Bus Number=2。
12.继续Depth-first Search,发现设备D。读取相关寄存器,得知D为Switch的下游接口桥设备。得知Bus 3的存在。对D的寄存器修改,更新上游设备。
13.对Bus 3 上的设备进行探测,发现Bus 3,Device 0。读寄存器,发现为Endpoint多功能设备。
14.结束Depth-first Search,回滚到Bus 2,继续探测设备,然后执行Depth-first Search。
15.重复上述过程完成所有设备遍历。
同时还有一个问题摆在面前,一个Function是怎么知道它自己的Bus Number和Device Number的。一个Function一定知道自己的Function Number的,Device的设计者在设计的时候会以某种方式例如硬编码寄存器方式告诉它自己的Function Number。而Bus Number和Device Number不可能以这种方式实现,因为设备它不同的位置它的ID不一样。当一个Configuration TLP到达一个Completer后,Completer会以某种方式记录TLP Header中的目的ID,也就是自己的ID,从而获得自己的ID。
当以上说有的操作完成之后,这个体系的ID都已经建立,那么所有的Configuration都可以正确的进行传播,然后其他程序才会正常的进行工作,例如,我们知道Address Routing这种方式,当采用这种方式进行工作时,需要首先对Base Address Register进行Configuration,才能正常的路由。而如果没有建立一个正确的ID体系是无法进行Configuration的。关于BAR寄存器的相关设置稍后在讲解。
随后我将介绍大致介绍基于WinDriver的驱动程序和PIO这一简单的PCIE设备。最近比较忙,当我有足够时间的话,我会一并写出发布。
PCIE开发笔记(五)PCIE设备热插拔篇
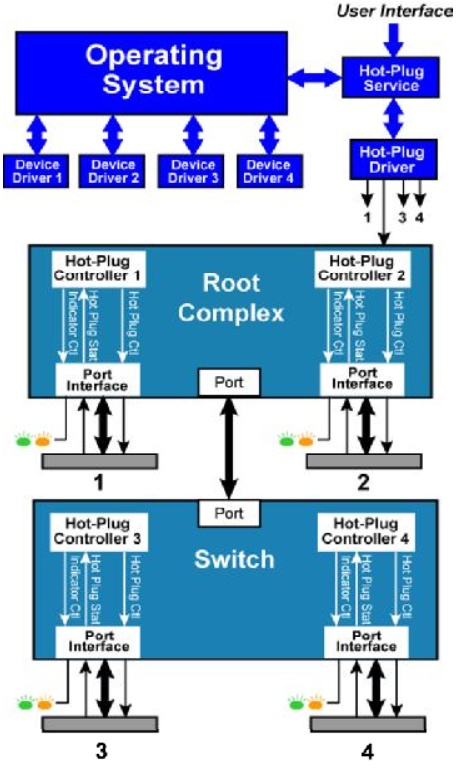
我们主要介绍PCI_E设备的热插拔(Hot Plug)功能。
热插拔是一个非常重要的功能,很多系统需要热插拔功能从而尽最大可能减少系统停机的时间。
PCI设备需要额外的控制逻辑去控制PCI板卡,来完成例如上电,复位,时钟,以及指示器显示。PCI_E相较于PCI设备具有原生的热插拔功能(native feature),而不需要去设置额外的设备去实现热插拔功能。
PCI_E的热插拔功能需要在热插拔控制器(Hot Plug Controller)的协助下完成,该控制器用来控制一些必要的控制信号。这些控制器存在在相互独立的根节点(Root)或者开关(Switch)中,与相应的端口(port)相连。同时PCI_E协议为该控制器定义了一些必要的寄存器。这些控制器在热插拔软件控制下,使着相连的端口的控制信号有序地变化。
一个控制器必须实现以下功能。
- 置位或者不置位与PCI_E设备相连的PERST#复位信号。
- 给PCI_E设备上电或者断电。
- 选择性地打开或者关闭用来表示当前设备状态的指示器(例如LED指示灯)。
- 检测PCI_E设备插入的插槽(slot)发生的事件(例如移去一个设备),并将这些事件通过中断方式报告给软件。
PCI_E设备和PCI设备通过一种称作无意外(no surprises)方式实现热插拔。用户不允许在未告知系统软件的情况下插入或者移除一个PCI_E设备。用户告知软件将要插入或者移除一个设备之后,软件将进行相关操作,之后告知用户是否可以进行安全的进行这个操作(通过相应的指示器)。然后用户才可以进行接下来的操作。
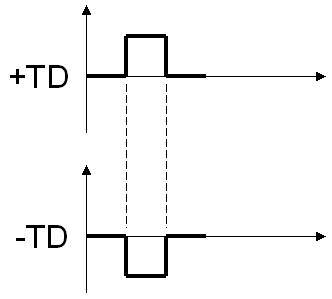
同时PCI_E设备也可以通过突然意外(surprise removal)的方式移除设备。它通过两根探测引脚(PRSNT1#,PRSNT2#)来实现,两个引脚如Fig1,Fig2所示。这两个引脚比其余的引脚更短,那么在用户移除设备的时候这两根信号会首先断开,系统会迅速的检测到,并迅速做出反应,从而安全移除设备。
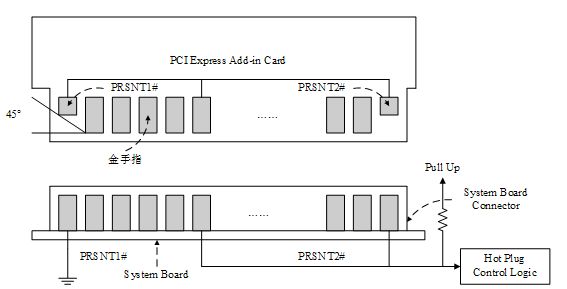
Fig1

Fig.2
在上面简单的接受之后我们开始介绍实现热插拔必备部分:
- 软件部分
- 硬件部分
首先介绍软件部分。
下表将详细介绍实现热插拔必须的软件,以及它们的层次结构。
- User Interface 用户接口
操作系统提供给用户调用,来请求关闭一个设备或者打开一个刚刚插入设备。
- Hot-Plug Service
一个用来处理操作系统发起的请求的服务程序,主要包括例如提供插槽的标识符、打开或者关闭设备、打开或者关闭指示器、返回当前某个插槽的状态(ON or OFF)。
- Standardized Hot-Plug System Driver
由主板提供,接受来自Hot-Plug Service的请求,控制热插拔控制器(Hot Plug Controller)完成响应请求 。
- Device Driver
对于一些比较特殊的设备,完成热插拔需要设备的驱动设备来协作。比如,当一个设备移除之后,要将设备的驱动程序设备为静默状态,不再工作。
硬件部分
下表详细的介绍了实现热插拔必须的硬件部分。
- Hot-Plug Controller 热插拔控制器
用来接收处理Hot-Plug System Driver发出的指令,一个控制器连接一个支持热插拔的端口(port),PCI_E协议为控制器定义了标准软件接口。
- Card Slot Power Switching Logic
在热插拔控制器的控制下完成PCI_E设备的上电与断电。
- Card Reset Logic
在热插拔控制器的控制下对与PCI_E设备连接的PERST#复位信号置1或者置0。
- Power Indicator电源指示器
每一个插槽分配一个指示器,由热插拔控制器控制,指示当前插槽是否上电。
- Attention Button
每一个插槽分配一个按钮,当用户请求一个热插拔操作时,按压这个按钮。
- Attention Indicator
每一个插槽分配一个指示器。指示器用来引起操作者的注意,表明存在一个热插拔问题,或者热插拔失败,由热插拔控制器控制。如图Fig.3就是一个服务器硬盘的示意图。

Fig.3
- Card Present Detect Pins
总共有两种卡存在信号,PRSENT1#,PRSNT2#。作用上面我们已经介绍过了。
完成上述必要部分的介绍之后,我们开始介绍PCI_E设备热插拔实现框架,了解上述各个部分是如何连接,相互协作的。同时与PCI设备的热插拔进行对比。
首先我们介绍PCI设备的热插拔框架,PCI是共享总线结构,即一条总线上连接多个设备,在实现热插拔过程就需要额外的逻辑电路,如图Fig.4,系统存在一个总的Hot-Plug Controller,在控制器里面存在各个插槽对应的控制器,控制器在Hot-Plug System Driver的控制下完成热插拔过程。
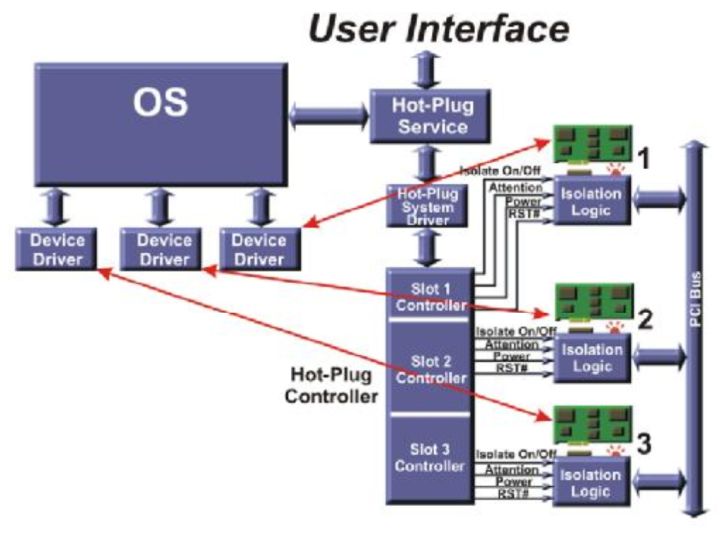
Fig.4
而PCI_E是点对点(Peer To Peer)拓扑结构,同时原生支持热插拔功能,这就决定它的系统框架不同于PCI。如图Fig.5,热插拔控制器分散存在于每个根聚合点(Root complex)或者开关(Switch)中,每个端口(Port)对应一个控制器,不再需要一个单独额外的控制器。用户通过调用用户接口来一层一层实现最后的热插拔功能。
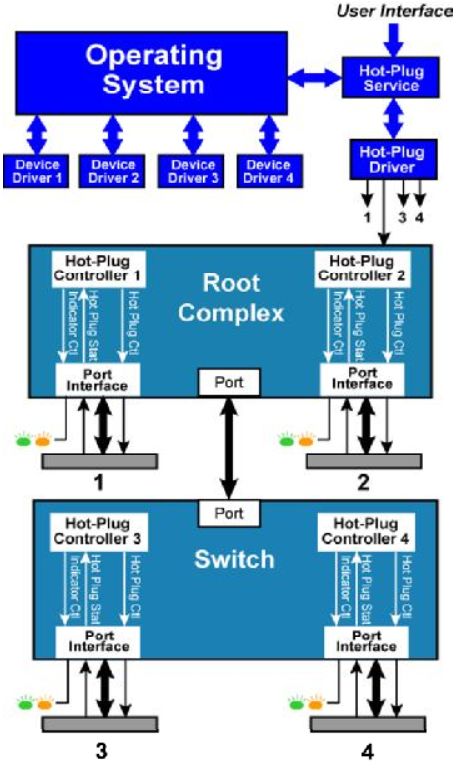
Fig.5
下面我们开始介绍PCI_E设备的实现热插拔的具体过程。(这里假设操作系统完成对一个新插入的设备的配置,我们以前的教程有提到过)。
热插拔过程可以分为这几个过程(以移除为例):
- 用户要移除某个设备,通过物理方式(例如按下按钮)或者软件方式告知操作系统。
- 操作系统接收到请求之后进行一些必要的操作(例如完成现在正在进行的写操作,并禁止接收新的操作),然后通过物理(例如指示灯)或者软件的方式告知用户你的请求是否可以满足。
- 如果第二步操作系统告知用户可以进行请求的操作的话,Hot-Plug System Driver将插槽(slot)关闭。通过控制根聚合点(Root complex)或者开关(Switch)中相应的寄存器完成插槽状态的转换。具体的寄存器介绍稍后介绍。
- 用户移除相应的设备。
首先介绍打开或者关闭插槽的过程。
首先了解两个状态:
- 插槽开状态(On)
该状态有如下特点:
\1. 插槽已经上电。
\2. 参考时钟REFCLK已经打开。
\3. 插槽连接状态处在活跃状态(active),或者由于电源管理(Active State Power Management)处于待命状态(L0s or L1)。
\4. 复位信号PERST#置0。
- 插槽关状态(Off)
该状态有如下特点:
\1. 插槽断电
\2. 参考时钟REFCLK已经关闭。
\3. 连接状态处于静默状态(inactive)。相应信号线处于高组态。
\4. 复位信号PERST#置1。
下面我们介绍关闭和打开插槽的具体流程。
关闭插槽过程:
\1. 将链路链接关闭。端口在物理层(Physical Later)将相关信号设置为高阻态。
\2. 将插槽的复位信号PERST#置1。
\3. 关闭插槽的参考时钟REFCLK 。
\4. 将插槽断电。
打开插槽过程:
\1. 将插槽上电。
\2. 打开插槽的参考时钟REFCLK。
\3. 将复位信号PERST#置0。
一旦插槽上电,参考时钟打开,复位信号置0之后,链接两端将会进行链路训练和初始化,之后就可以收发TLP了。
下面我们将详细介绍设备移除和设备插入过程:
- 移除设备:
移除方式可以以物理方式和软件方式两种方式进行。
当以物理方式时:
\1. 当通过物理方式告知系统将要移除设备。操作者需要按下插槽中Attention Button。热插拔控制器侦测到这个事件之后,给根聚合点传递一个中断。
\2. Hot Plug Service调用Hot-Plug System Driver,读取现在插槽的状态。之后Hot Plug Service向Hot-Plug System Driver发送一个请求,要求Hot-Plug Controller控制Power Indicator从常亮转向闪烁。操作者可以在五秒内再次按下Attention Button中止移除。
\3. 当第二步读取卡槽状态,卡移除请求验证成功,并且热插拔软件允许该操作之后,Power Indicator将持续闪烁。当设备正在进行一些非常重要的操作时,热插拔软件可能不允许该操作。如果软件不允许该操作时,软件将会拒绝该操作,并让Hot-PlugController将Power Indicator停止闪烁,保持常亮。
\4. 如果该操作被允许,Hot Plug Service命令Device Driver静默,完成已经接收的操作,并不在进行接受或发出任何请求。
\5. 软件操作链接两侧端口的Link Control Register关闭两侧设备的数据通道。
\6. 软件通过Hot-Plug Controller将插槽关闭。
\7. 在断电成功之后,软件通过Hot-Plug Controller将Power Indicator电源指示器关闭,此时操作者知道设备此时可以安全的移除设备了。
8.操作者将卡扣(Mechanical Retention Latch,将设备固定在主板上的设备,可选设备,上面有一个传感器,检测卡扣是否发开,如图Fig.5)打开,将所有连接线(如备用电源线)断开此时卡移除掉。此步骤与硬件有关,可选。

Fig.5
\9. 操作系统将分配给设备的内存空间(Memory Space),IO空间(IO Space),中断线回收再利用。
当以软件方式移除时与物理方式基本相同,但是前两步替换为以下步骤:
操作者发出一个与设备相连的物理插槽号(Physical Slot Number)的移除请求。然后软件显示一个信息要求操作者确认,此时Power Indicator开始由常亮转向闪烁。
- 插入设备:
插入也分为物理方式和软件方式,设备插入过程是移除的一个反过程,我们这里假设插入的插槽已经断电。
物理方式具体过程如下:
- 操作者将设备插入,关上卡扣。如果卡扣存在传感器的话,Hot-Plug Controller将会感知到卡扣已经关闭,这是控制器将会将备用信号和备用电源连接到插槽。
- 操作者通过按压Attention Button来通知Hot-Plug Seriver。同时引起状态寄存器相应位置位,并引发中断事件,发往根聚合点。然后,软件读取插槽状态,辨识请求。
- Hot-Plug Service向Hot-Plug System Driver发出请求要求Hot Plug Controller闪烁插槽的Power Indicator,提示现在不能再移除设备了。操作者乐意在闪烁开始5秒内再次按压Attention Button来取消插入请求。
- 当设备允许请求时,Power Indicator将保持闪烁。可能因为设备安全因素禁止插入某些插槽,热插拔软件将不允许该操作。如果软件不允许该操作时,软件将会拒绝该操作,并让Hot-Plug Controller将Power Indicator熄灭。同时建议系统用消息或者日志的方式记录禁止的原因。
- Hot-Plug Service向Hot-Plug System Driver发送命令,将相应卡槽打开。
- 一旦插槽打开,软件命令将Power Indicator打开。
- 一旦链路训练完成,操作系统开始进行设备枚举,分配Bus Number,Device Number,Function Number,并配置相应配置空间(configuration space)。
- 操作系统根据设备信息加载相应的驱动程序。
- 操作系统调用驱动程序执行设备的初始化代码,设置配置空间相应的命令寄存器,使能设备,完成初始化。
软件过程可以类比,到此这个热插拔过程介绍就完成了。
下面介绍PCI_E建议的用户接口和相应寄存器介绍。
首先介绍软件之间的接口。协议没有详细的定义这些接口,但是它定义了一些基础的类型和它的内容。Hot-Plug Service和Hot-Plug System Driver之间的接口如下:
- Query Hot-Plug system Driver
输入:none 输出: Hot-Plug System Driver控制的逻辑插槽ID
功能:询问Hot-Plug System Driver控制的的插槽,并返回其逻辑插槽ID。
- Set Slot Status
输入:逻辑插槽ID、新的状态、新的Attention Indicator状态、新的Power Indicator
状态
输出:请求完成状态
功能:用来控制slot和与之相关的Indicator。
- Query Slot Status
输入:逻辑插槽ID 输出:插槽状态 设备电源需求
功能:返回插槽状态,Hot-Plug System Driver返回相比相应信息。
下面介绍热插拔控制器的可编程接口。PCI_E协议已经在配置空间中定义了相关寄存器。Hot-Plug System Driver通过控制Fig.6红圈内有相关寄存器来控制热插拔控制器,进而实现热插拔。

Fig.6
- Slot Capabilities Register 这个寄存器主要表明设备存在哪些指示器,传感器。存在在插槽和设备的配置空间中。硬件必须要初始化这个寄存器以表明设备实现哪些硬件了。软件通过读该寄存器来获取硬件信息。Fig.7是该寄存器示意图,Table.2是详细描述。
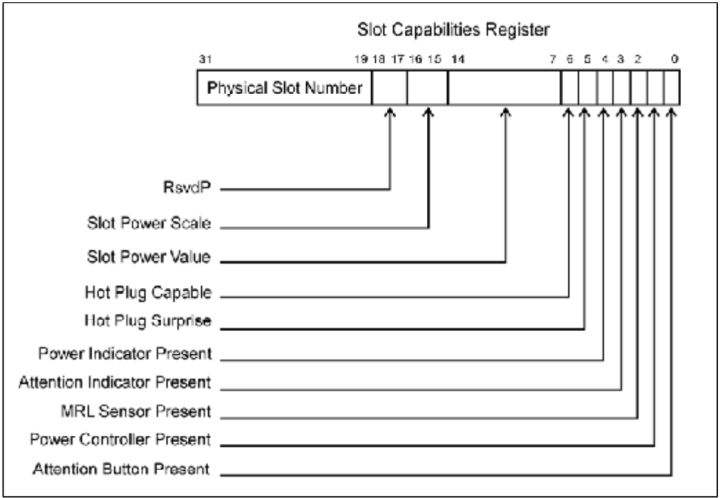
Fig.7


Table.1
- Slot Control 该寄存器作为软件接口,可以控制一系列热插拔事件。比如那个事件的发生可以引起中断。
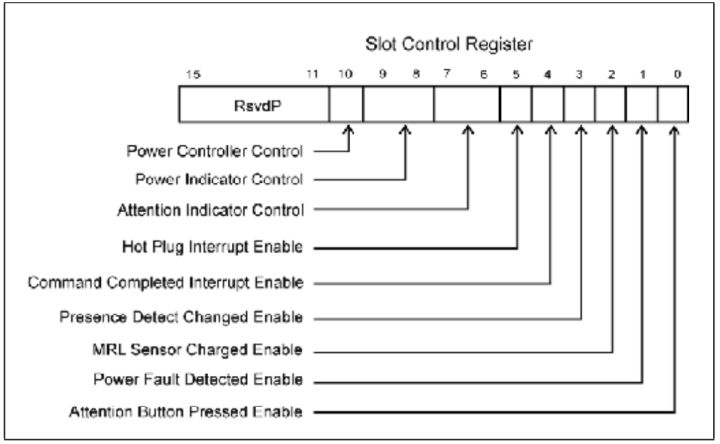
Fig.8


Table.2
- Slot Status and Event Management 热插拔控制器监控一系列事件,将这些事件报告给Hot-Plug System Driver 。软件通过读取这个寄存器来判断那个事件引起中断。寄存器中改变的位必须通过软件清零,
以探测之后发生的事件。
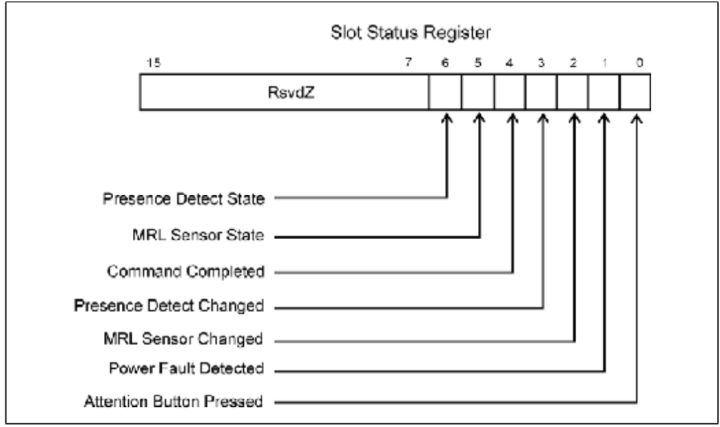
Fig.9


Table.3
这里热插拔篇就结束了,之后会更新有关热插拔的电气要求。
PCIE开发笔记(六)PCIE设备中断篇
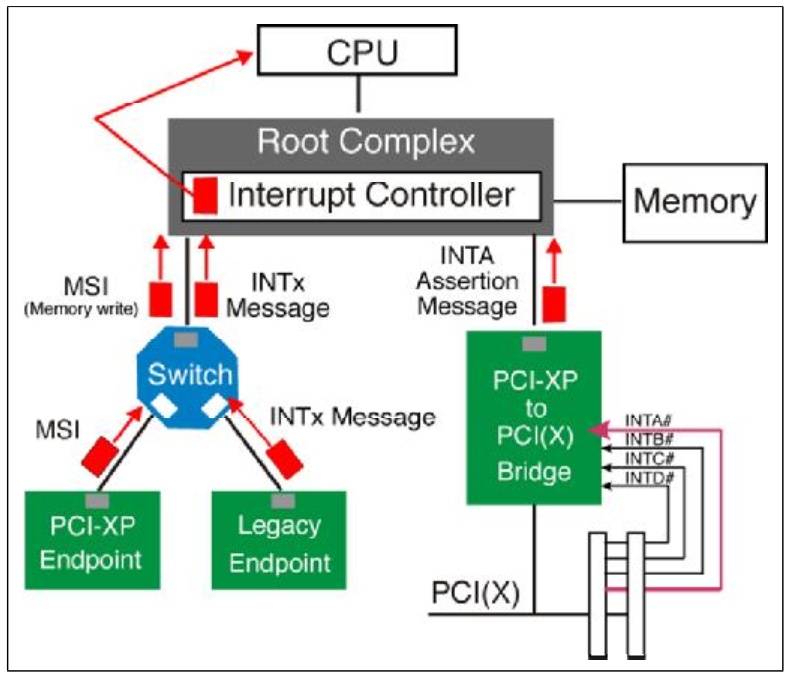
使用Xilinx IP核进行PCIE开发学习笔记(六)PCIE设备中断篇
中断(Interrupt)是一个非常重要的机制,在各中系统中都普遍存在,通过中断,我们可以为CPU减负,从而可以节约CPU的时钟周期,让CPU去做一些其他重要的事情。只在一个事件(Event)发生之后,通过引发中断的方式来调度CPU来完成中断处理。
下面我们介绍PCI_E协议中的中断。
首先,中断功能是PCIE设备的一个可选功能。
在PCIE设备中,实现中断有两种方式。
- Native PCI Express Interrupt Delivery PCIE协议在2.2版本之后排除了使用额外的信号线来传递中断的方式,取而代之的是一种称之为MSI(Message Signaled Interrupt)的方法。它通过发送TLP包的方式来告知中断。但是应该注意的是,不要被字面意思蒙蔽,这个TLP包的类型不是Message类型,而是一个简单的存储器写类型的TLP包。同时我们可以通过写TLP包的目的地址来判别这是一个MSI数据包还是一个普通的存储器写数据包。因为MSI的目的地址是系统特意分配给它的。
- Legacy PCI Interrupt Delivery 这种是PCI协议支持的中断方式,PCI_E协议为了兼容性也允许这种方式。它通过额外的信号线(INTx)来传递中断信号。
我们在整个系统中阐述着两种方式。
- 如果一个原生PCIE设备(Native PCI Express function)需要中断功能,那它必须使用MSI这种方式。
- 对于一个传统的终端设备(Legacy Endpoint device)必须支持MSI,对INTx型的可以选择性支持,因为有些设备(boot devices)在开机boot时间只能使用传统的中断,而MSI只有在开机成功设备驱动载入以后才能使用。
- 对于PCI_E TO PCI桥设备,必须支持INTx类型中断。
Fig.1
- MSI型中断
MSI型中断通过向根聚合点发送一个存储器写操作来完成中断。MSI Capability register提供触发这个中断的所有信息。这个寄存器是由Configuration 软件来完成初始化的。寄存器提供一下信息:
- 目标地址(Target memory address)。
- 写操作的数据内容。
- 可以使用的消息数(Message Number)。
下面我们具体介绍MSI Capability register,每个设备通过这个寄存器表明它对MSI的支持。每个原生PCI_E设备(native PCI_E function)必须在它的配置空间(configuration space)中实现这个独一无二的寄存器。同时存在两种类型的MSI Capability register。
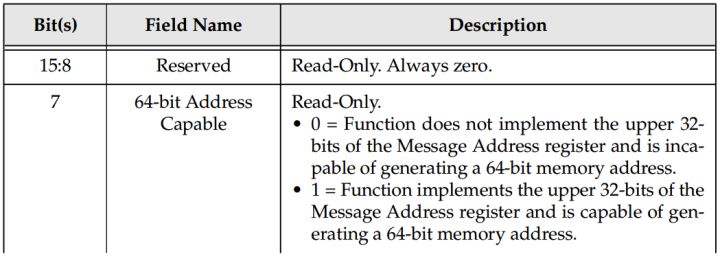
- 64-bit地址格式寄存器,所有原生设备(Native PCI_E device)必须实现。
- 32-bit地址格式寄存器。老式设备可选(Legacy device)。

32-bit MSI Capability register

64-bit MSI Capability register
下面分别介绍每个字段含义:
Capability ID
这个字段被硬件编写为05h,只读。表明这个寄存器的类型。
Pointer To Next New Capability
这个字段用来指向下一个新的Capability寄存器的地址(相当于链表结构),如果这个是最后一个Capability寄存器,那就写00h。这个字段也是只读,硬编码的寄存器。
Message Control Register
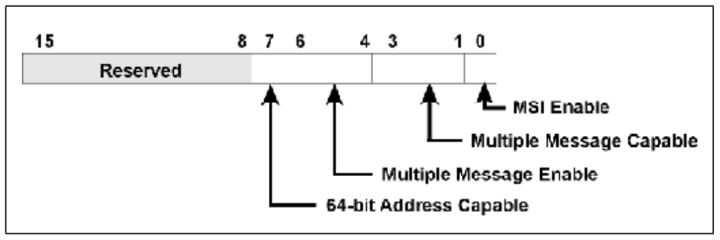
Message Control Register
字段含义:

Message Address Register
寄存器的低两位是硬件置0的,使地址强制与字对齐。
原生设备必须具有高32位地址寄存器。当Message Control register的第七位置1时出现高32 寄存器。如果出现高32位寄存器,那么它和低32位寄存器连接组成一个64位地址寄存器。当第七位置位0,那寄存器就是一个单纯的32位寄存器。
Message Data Register
系统软件通过向这个16位的可读写寄存器写入数据来告知设备一个基本的数据格式(Base Message Data Pattern)。当设备需要产生一个中断请求时,设备向Message Address Register中的地址写入一个32位数据。数据有以下格式:
- 高16位总是设置为0。
- 低16位由Message Address Register提供。如果有多个中断同时发生,那在该寄存器内数据上做相依修改,后面将会详细介绍。
- MSI配置过程
- 在初始化过程,配置软件扫描总线,寻找设备。当软件发现一个设备(Device Function),配置软件读取能力列表指针(Capabilities List Pointer),获得第一个能力寄存器。
- 软件搜索能力寄存器列表,找到MSI Capability register(ID为05h)。查看设备是否支持MSI中断,不支持则退出,支持则进入下一步。
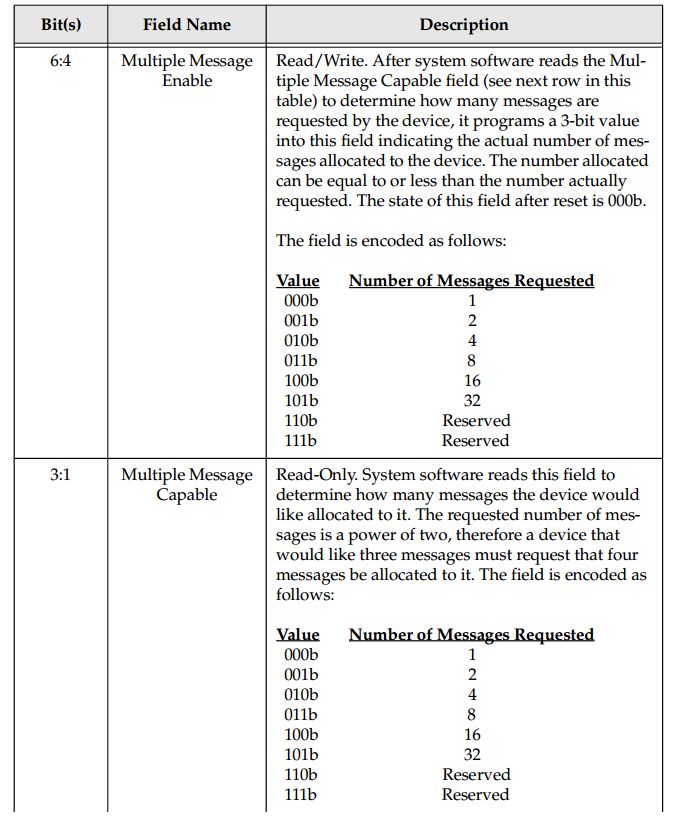
- 软件对设备的Message Address register赋值。用于请求中断时存储器写地址的目的地址。
- 软件检测Message Control寄存器中的Multiple Message Capable字段,查看设备准备请求多少消息。这里每个消息(Message)对应设备中发生的一个事件(Event)。
- 软件向设备分配消息,消息数等于或着小于设备的请求消息数。软件最小应该给设备分配一个消息。
- 软件向设备的Message Data寄存器写入Base Message Data Pattern。
- 软件设置Message Control register中的MSI Enable bit,允许设备产生中断。
- MSI中断产生
设备通过向处理器发送一个存储器写数据包来产生中断。这个数据包的数据负载为1DW。它的目的地址和数据负荷上面已经介绍过。
关键点如下:
- Format 字段必须是11b,表明这是一个4DW包头,带数据载荷的数据包。对遗留的设 备(legacy device),标头可以使10b。
- Header Attribute Bits必须为0。
- Length Field必须为01h。
- First BE field必须为0011h。Last BE field必须为0000h。
- Address field从MSI Capability register中获得。
- 数据载荷的低16位从MSI Capability register中的data field获得。
可以参考Fig.2。
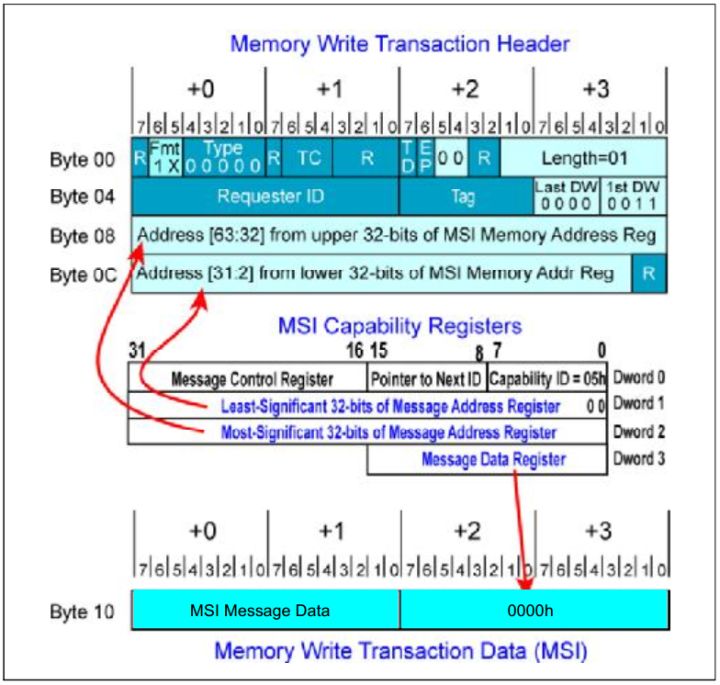
Fig.2
混合消息:
如果设备请求了多个消息(message),并且软件也给它分配了多个消息,那么当设备准备发送一个不同的中断,那么它需要适当修改数据包的数据载荷。
我们举一个例子,假设4个消息分配给设备,Message Data register的值被设置为0500h,同时Message Address register值为0A000000h。那么,当四个消息所对应的时间的任意一个发生,那个设备将会产生一个向0A000000H地址的存储器写数据包,其中的数据载荷分别为00000500h,00000501h,00000502h,0000503h。也就是数据包数据载荷的高16位补零,低16位根据Message Data register的值按顺序增加。
- Legacy PCI Interrupt Delivery 中断
这种方式是采用中断信号线INTX来实现,在PCI协议中规定,每个设备支持对多四个中断信号,INTA,INTB,INTC,INTD。中断是电平触发的,当信号线为低电平,这引发中断。一旦产生中断,则该信号线则一直保持低电平,直到驱动程序清除这个中断请求。这些信号线可以连接在一起。在设备的配置空间里(Configuration Space)有一组寄存器(Interrupt Pin)表明一个功能(Function)使用哪个中断信号。
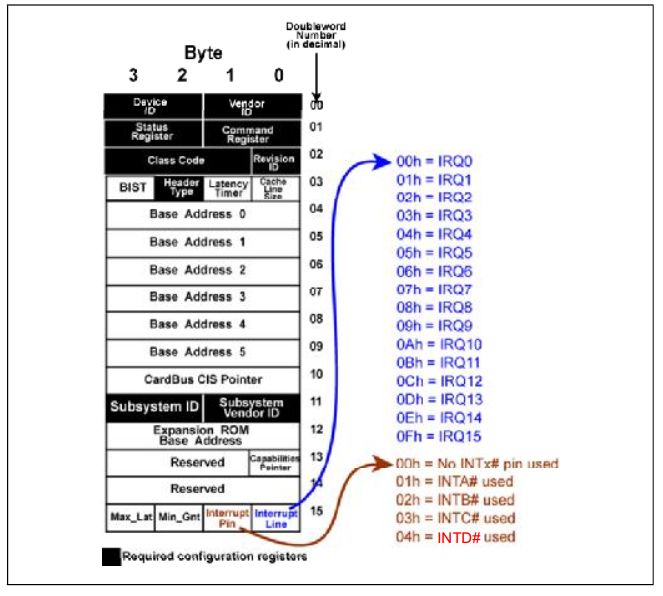
Fig.3
所有的中断信号都与系统的可编程中断路由器(Programmable Interrupt Router)相连,这个路由器有四个中断输入接口。设备与这个路由器的中断输入接口怎么相连是系统的设计者在设计系统的时候就已经决定了,用户是不能改变的。操作系统通过一个中断路由表来得知。路由表记录每个中断向量(IRQ)与每个设备的中断信号的连接情况。例如Fig.4,表会记录device 0 INTA、Device 1 INTA、Device 2 INTA与IRQ10相连。
基于与每个设备相连的INTX信号的路由关系,在设备启动之后,配置软件将会给每个设备一个Interrupt Line Number,并修改设备的配置空间。这个值将会告诉每个设备的设备驱动当这个设备发生中断时,哪个中断向量将会被报告。当设备产生一个中断,CPU将会接收一个与Interrupt Line register中对应的中断向量(一个中断向量对应一个程序入口)。CPU将会使用这个向量来检索中断服务表(Interrupt Service Table,用来存储中断向量和程序入口的对应关系)来获取与这个设备的驱动相关的中断服务程序。
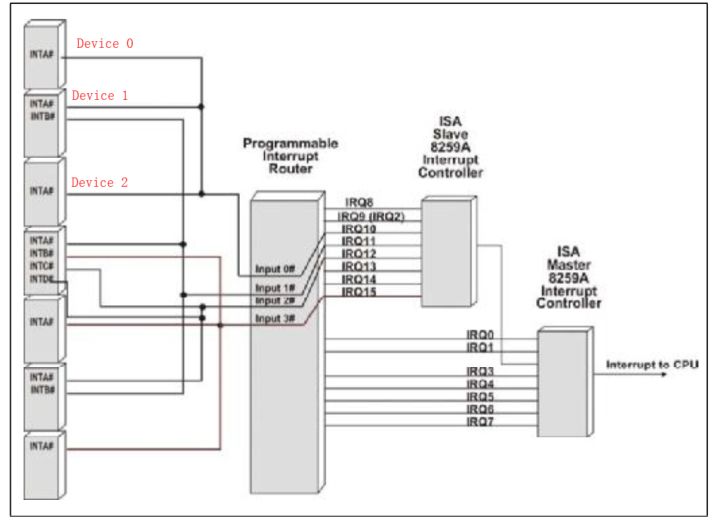
Fig.4
在Fig.4中我们可以看到有几个不同的设备连接在一起,共用一个Interrupt Line Number。那么当设备产生中断之后,CPU接收到中断向量之后如何判断哪个设备产生的中断,进而调用相应的中断服务程序?
在系统启动之后,会根据路由描述表来建立中断服务表。以IRQ10为例,系统首先扫描到Device 0 INTA,那么它将中断服务列表IRQ10的中断服务程序入口登记为Device 1 INTA的,如果之后发现Device 1 INTA也使用IRQ10,那么它就会覆盖掉上一步,将入口登记为Device 1 INTA的,并将Device1的中断服务程序的最后指向Device 0 INTA的服务程序,依次类推,形成一个设备链。那么之后中断到来之后,会首先调用最后扫描到的设备的中断服务程序,该程序通过查询中断请求位来判断该设备是否引发中断,如果没有那就沿着设备链找到下一个设备,继续查询,直到最后找到引发中断的设备。
相关寄存器
设备应该实现一个设备特定的寄存器,这个寄存器可以并映射到Memory或者IO地址中。在这个寄存器中应该有这个一位,当一个设备产生中断之后,设备将在这位设置为1,驱动通过读这位来判断有一个中断等待处理,当清理这个位之后,中断就失效了。
同时在设备的配置空间中有两个寄存器。
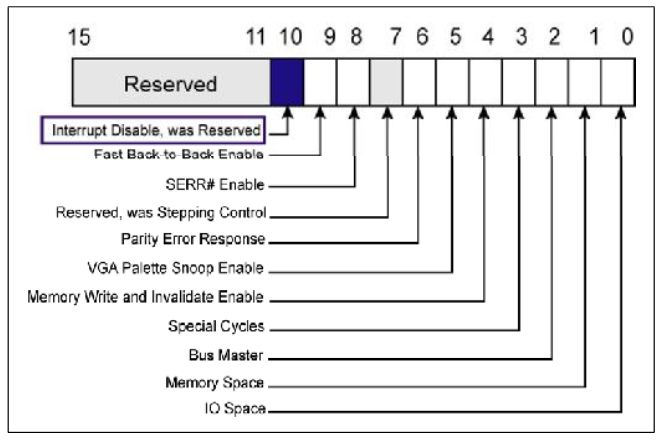
Fig.5
Interrupt Disable 当该位置位时,中断失效。
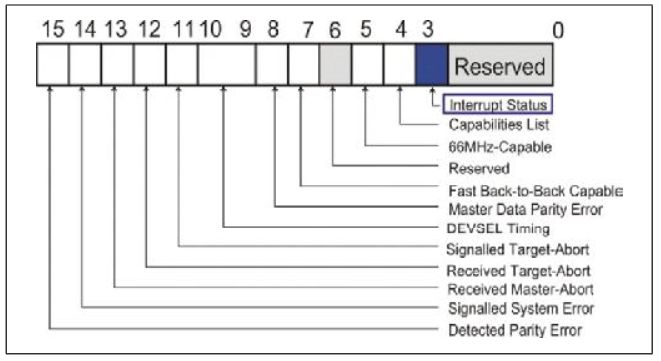
Fig.6
Interrupt Status 该位在中断发生,并等待解决时置位。只读。
到这里PCI-E中两种中断方式的相关内容介绍完毕。还有虚拟INTx消息可以查阅相关资料了解一下。
PCIE开发笔记(七)DLL介绍(上)
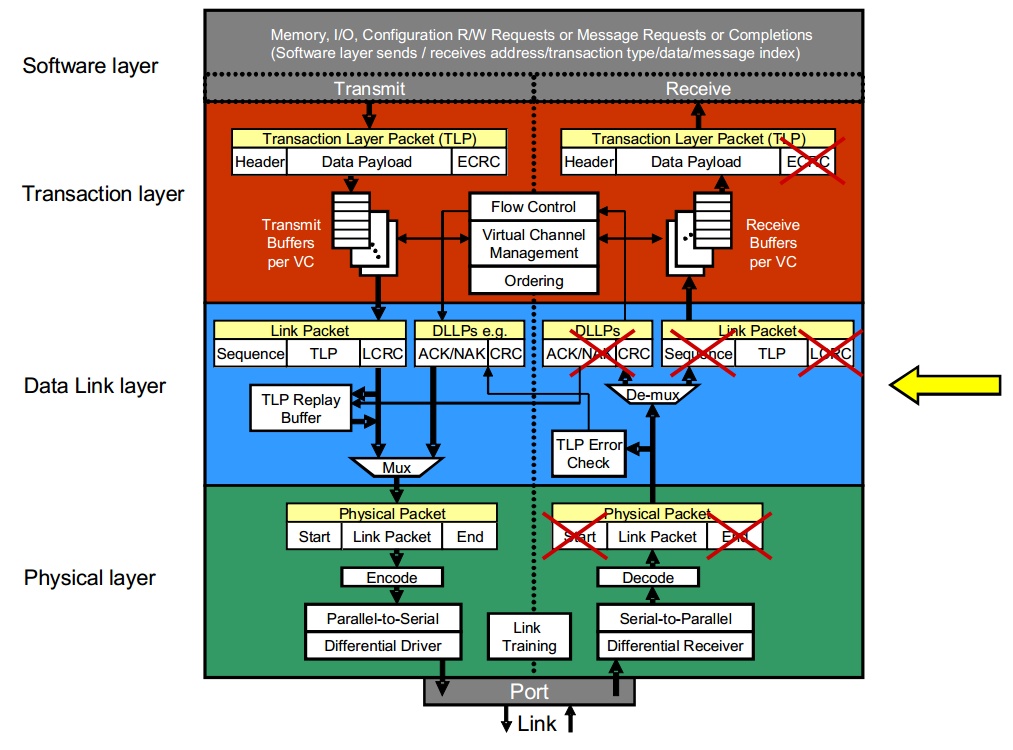
在之前的文章中,我们已经知道PCIE协议可以划分为三个层,每个层的作用与分工不同。在接下来的几篇文章中,我将详细介绍PCIE协议中三个层的详细作用。
图1 PCIE结构分层
一个良好的结构分层可以使整个系统功能简明。明确每个部分的工作是什么,使得每个层只专注自己应该做的工作,同时也使得当问题出现之后能够马上定位出问题出现的位置。
如果你了解TCP/IP网络协议,那么你就不难发现它好像是PCIE的一个升级版,增加了更多的层次。同时PCIE又好像是TCP/IP协议的一个浓缩版,保留了达到目的的必要层次。如果你仔细思考这些层的划分,你就不难想到, 其实他们的相似并非偶然,而是进行一个功能比较完善的通信所必须的,同时又因为两者的目的的不同,而产生一些必然的差异。
- TL层(Transaction Layer):TL层着眼于数据包在整个拓扑结构中的传输,完成数据包的路由工作,同时进行一些数据包传输优先级的控制,从而满足一些特定要求的数据包的传输。
- DLL层(Data Link Layer):DLL层主要作用是确保一个数据包能够正确地从一个链路的发送端传输到链路的接收端。
- PL层(Physical Layer):PL层的主要作用是探测一个链路的两端是否连接能够工作的设备。在探测到链路两端存在设备之后,对链路进行训练,使得链路能够在正确的频率和位宽下工作。
那DLL层如何确保一个数据包正确的传输?
首先,我们必须对“正确的传输”有如下定义:
- 接收方接收的数据包与发送方的数据包完全一致的,没有任何改变。
- 在图1中,接收方DLL层向上传递给TL层的数据包的顺序必须和发送方发送的顺序严格一致(至于什么原因后面会讲到)。
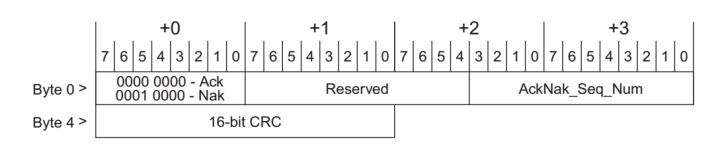
图2 ACK/NAK DLLP格式
DLL层使用ACK/NAK协议保证数据包的正确传输。如图2所示,发送方(Transmit)发送一个数据包之后,接收方(Receiver)会返回一个ACK/NAK DLLP(Data Link Layer Packet),并且在DLLP中包含一个序列号(Sequence Number)信息,来具体确认那一个TLP传输是否成功。ACK(Acknowledgement)表示成功,NAK(Negative Acknowledgment)表示失败。
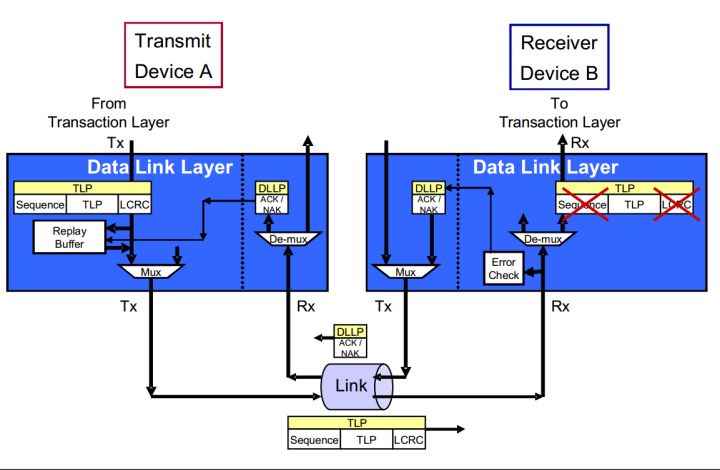
图3 ACK/NAK协议
图3展示了DLL层中实现ACK/NAK协议的更多细节。对于每一个通过Link由Device A发送到Device B的TLP数据包,Device B会通过TLP的LCRC(Link Cyclic Redundancy Check)来判断TLP数据包是否存在错误。在检查错误之后,Device B通过返回一个ACK或NAK DLLP数据包来告知Device A是否接受成功。Device A接收一个ACK DLLP则确认Device B正确地接受一个或者多个数据包,接收一个NAK DLLP则确认Device B错误地接受一个数据包(同时它也隐形的表示一些TLP发送成功,这个在下一篇中说明)。当Device A接收到NAK DLLP之后,Device A设备将会再次发送相关数据包。
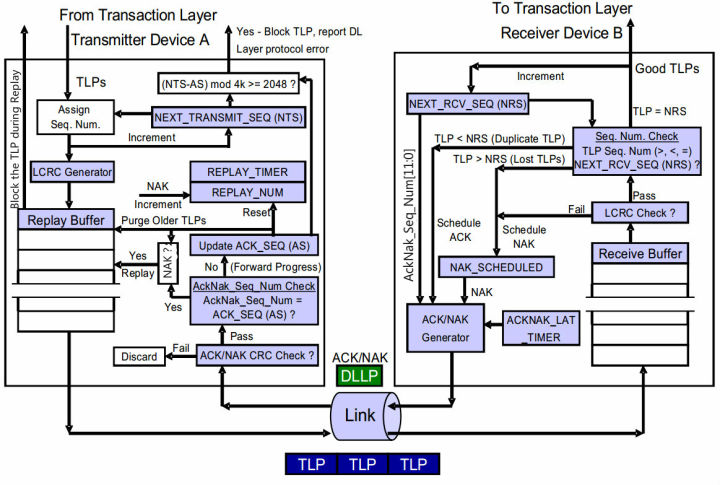
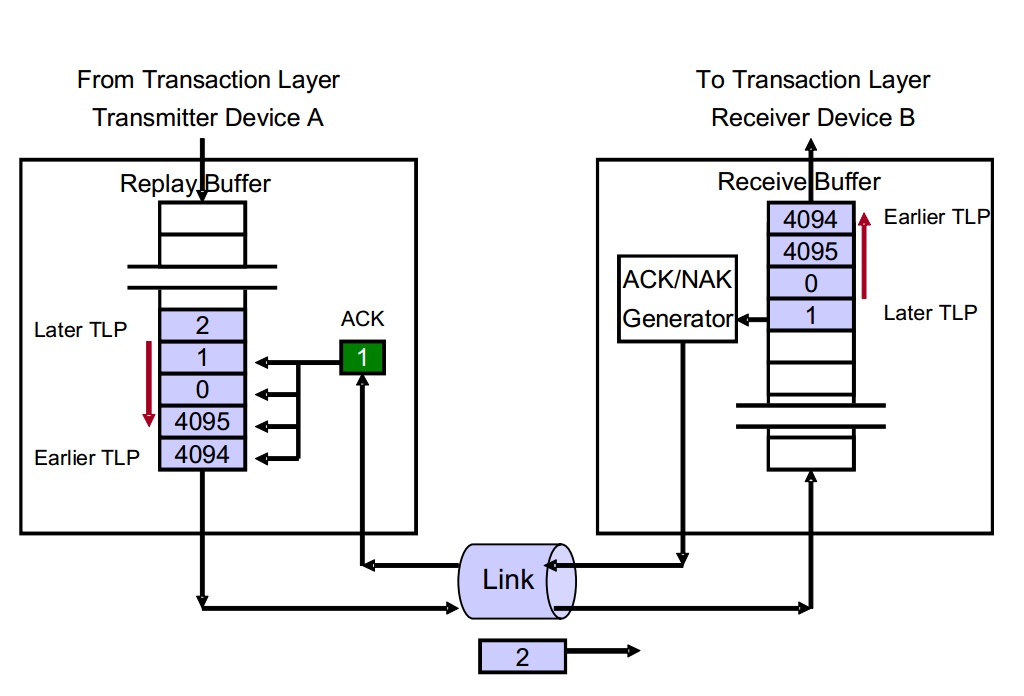
图4 ACK/NAK原理图
下面我们就比照图4详细介绍ACK/NAK协议如何实现整个过程的。
首先介绍原理图里面几个部分:
- Replay Buffer:Replay Buffer:主要用来存储TLP数据包,其中包括序列号(Sequence Number)和LCRC。所有的TLP按照发送的顺序储存,后进入的TLP的序列号总是大于先进入的序列号。 当Device A接收到ACK DLLP之后表明Device B接收TLP成功,Device A就会从Replay Buffer中去掉相应的TLP。如果收到一个NAK数据包,则再次发送整个Buffer。
- NEX_TRANSMIT_SEQ****Counter:这个计数器主要用来产生Sequence Number,这个值将会赋给下一个传输的TLP。这是一个32_bit计数器,当计数器到达最大值4095后回滚到0。
- LCRC Generator:LCRC产生器,用来为TLP产生一个32位的LCRC。Device B使用它来判断接受的TLP是否有问题。
- REPLAY_NUM Count: 这是一个2_bit的计数器,主要是用来统计Device A收到NAK和REPLAY_TIMER 时间溢出次数(time out)的计数器。当该计数器溢出时,表明这个物理链路可能出现问题,DLL层将会触发PL层进行一个物理链路重训练(Physical Layer Link-retrain)。整个DLL层不再进行数据包的传输,直到重训练完成之后。REPLAY_NUM在系统复位或者DLL层处于不活跃状态时初始化为00b。当Device A再次发送Buffer之后,其中一些TLP被确认被接收(通过ACK或者NAK DLLP)时,则复位为00b。
- REPLAY_TIMER Counter:REPLAY_TIMER只要是用来测量从Device A发送任意TLP之后到它接收到一个与之对应的ACK/NAK的数据包之间的时间。这个计数器从发送的TLP的最后一刻开始计数。当且仅当Device A接收到一个ACK并且与之对应的TLP在Replay Buffer 中还存在时,这个计数器归0,如果此时Buffer中还有其他未经NAK/ACK确认的TLP,则计数器重新开始计时,如果不存在未发送的TLP,就保持0。当Device A接收到NAK时,计数器归零并保持,直到DLL再次发送数据包。当PL进行链路训练时,不计数。该计数器的作用主要是用来决定什么时候进行数据重发包,使保证这个DLL层向前运行,而不是卡在某个环节(例如当TLP已经发送出去,但是始终接收不到返回的ACK/NAK DLLP,或者始终接收到错误的ACK/NAK DLLP)。
- ACKD_SEQ Count:一个12_bit的计数器,用来保存上一次接受到的ACK/NAK DLLP中的Sequence Number。当接受到新的ACK/NAK DLLP,就使用其中的AckNak_Seq_Num字段更新这个计数器。ACKD_SEQ可以和NEXT_TRANSMIT_SEQ一起来判断整个Buffer是否满。当满足:
(NEXT_TRANSMIT_SEQ - ACKD_SEQ)mod 4096>2048
表明两个计数器之间的间距过大,DLL层将会拒绝接收TL层传输的新的TLP数据包,同时一个致命的错误将会报告。
- DLLP CRC Check: Device A接收到一个返回的DLLP之后,会对它进行CRC检查,如果是一个没有错误的DLLP,那个将会接收它。如果是错误的,将什么措施都不采取,将这个DLLP丢弃。整个流程如图5所示。
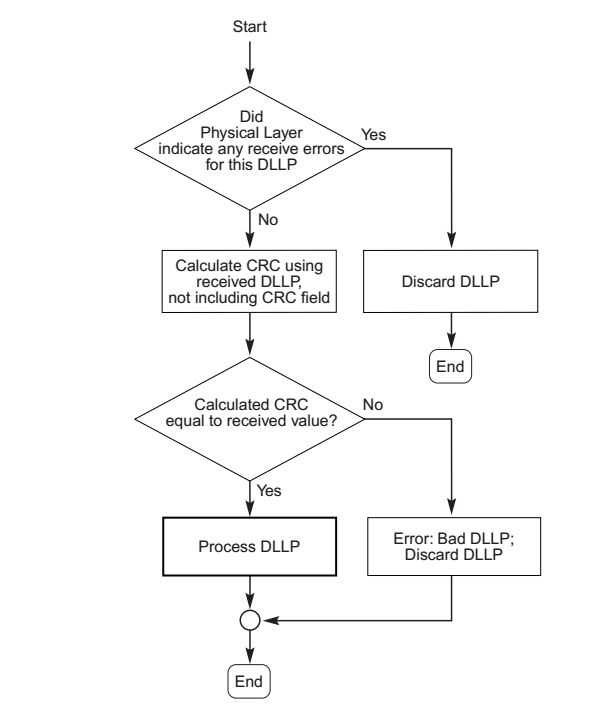
图5 接受DLLP错误检查流程
- Receive Buffer:该缓冲区用来短暂的存储带有TLP CRC和Sequence Number 的TLP数据包,然后传递给上游进行检查,如果没有错误,那么TLP将传递给TL层。如果存在错误,那么Device B将会丢弃这个TLP,并计划准备发送一个NAK DLLP数据包。
- LCRC Error Check:用来检查接收到的TLP是否存在错误。
- NEXT_RCV_SEQ Count:一个12_bit的计数器,用来保存下一个期望接收到的数据包的Sequence Number。这个计数器在Device B复位或者DLL层处于休眠状态时初始化为0。当Device A接收到一个期望的TLP之后,并且传递给TL层之后,该寄存器进行加1。当计数器溢出后返回0。当接收到错误TLP之后,寄存器不递增。
- Sequence Number Check:在CRC检查之后,将会对比接收到的TLP的Sequence Number位是否和NEXT_RCV_SEQ一致。
当TLP的Sequence Number等于NEXT_RCV_SEQ时,这个TLP将会被接收,并传递给TL层进行后续处理。同时NEXT_RCV_SEQ计数器进行加一。Device B将继续接收进入的TLP,不返回ACK DLLP直到ACKNAK_LATENCY_TIMER溢出或者是超出预设值。
当TLP的Sequence Number小于NEXT_RCV_SEQ时,并且两者之间的差距小于2048,说明这个TLP数据包之前已经接收过,那么Device B将会丢弃这个TLP,并计划返回一个ACK DLLP。
当TLP的Sequence Number大于NEXT_RCV_SEQ时,那么这个TLP将会被丢弃,同时计划返回一个NAK DLLP。
- NAK_SCHEDULED Flag:当Device B计划返回一个NAK DLLP时,这个位将会被置1。当Device B接收到再次发送的与返回的NAK DLLP有关的第一个TLP时,该位将清零。当该位被置1时,Device B对后续的TLP不做处理,直接丢弃。
- ACKNAK_LATENCY_TIMER:ACKNAK_LATENCY_TIMER是用来记录第一个ACK DLLP计划发出到当前时间的长度。Device B当该值溢出或者超出预设值时,实际发出返回一个ACK DLLP。
这里我们要区别一下计划发出与实际发出之间的区别,计划发出是表明Device将要发出一个但是实际上还没有发出,实际发出就是真正有一个DLLP从链路发出。使用ACKNAK_LATENCY_TIMER的原因主要是想要减轻ACK DLLP占用链路带宽,具体方法后面介绍。
- ACK/NAK DLLP Generator: 这一部分主要是用来产生ACK/NAK DLLP。其中产生的DLLP中的ACKNAK_RCV_SEQ=NEXT_RCV_SEQ-1。
在详细介绍ACK/NAK原理图中的几个部分之后,下面介绍这个工作流程。分为发送端(Device A)和接收端(Device B)。
- 发送端工作流程
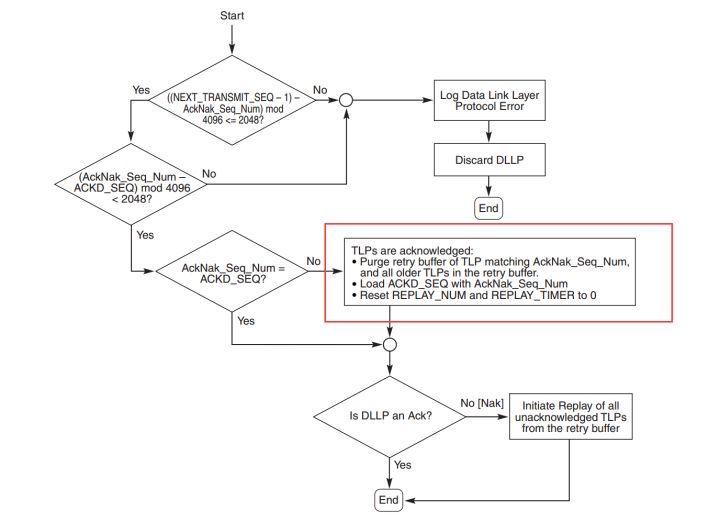
图6 发送方工作流程
图4中,在Device A接收到来自TL层传递的TLP之后,会首先在TLP数据包的前段添加Sequence Number,在数据包后添加CRC,之后将数据包放入Buffer中。于此同时会进行两个判断,
- (NEXT_TRANSMIT_SEQ - ACKD_SEQ)mod 4096>2048
- 判断Buffer是否已经写满
这两个判断B将说明DLL接收来自TLP数据包是否过多,如果过多将会阻止TL再传递数据包。然后Device A发送Buffer中的数据包。等待Device B返回的ACK/NAK DLLP。
当接收到Device B返回的DLLP数据包之后,会首先按照图5对DLLP进行错误检查。检查无误之后按照图6流程进行相应的流程。对于接收到的DLLP,不管是ACK/NAK,都将进行图6红框内操作。
除了图6所示的方式引起Replay Buffer的再次发送,另外一种引起再次发送的方式就是REPLAY_TIMER 计数器到达预设值。
- 接收端工作流程
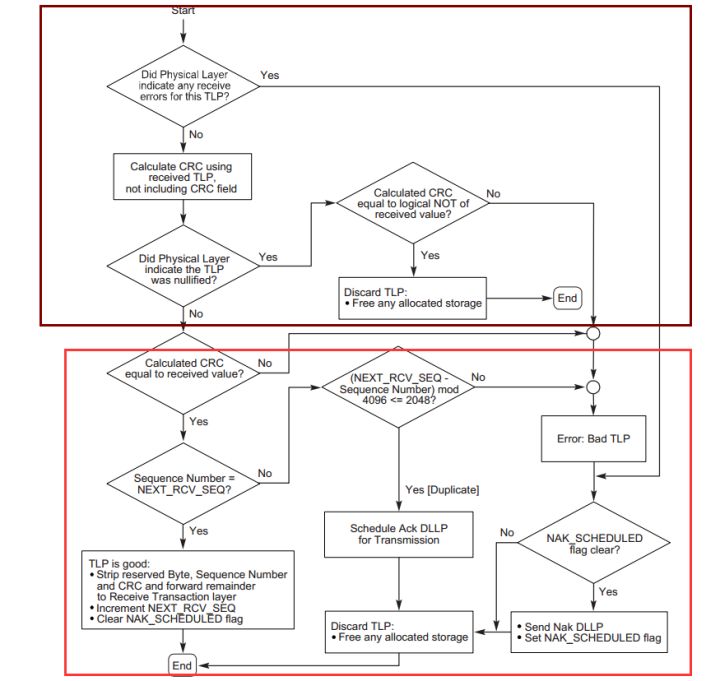
图7 接收方工作流程
图7中显示Device B接收数据包之后的工作流程,首先会进行褐色方框内的检查,方框中工作主要是物理层进行的工作,检查给数据包接收是否出现问题,以及这个数据包是否是一个被丢弃的数据包。这里不做过多讲述。重点介绍红框里面的内容。
在完成褐色框的检查之后,数据包会首先进行CRC错误检查,如果检查不通过,说明接收的TLP数据包存在错误,那么将会判断NAK_SCHEDULED是否置位,如果未置位,那个将该位置1,同时立即返回一个NAK DLLP,然后丢弃这个TLP。(这里NAK_SCHEDULED的作用体现出来了,你可以结合前面的内容想想它的作用)
如果检查通过之后,将判断Sequence Number是否等于NEXT_RCV_SEQ,如果两者相等那就将接收到的TLP进行处理,传递给TL层,同时将NEXT_RCV_SEQ加一,清除NAK_SCHEDULED标志位。如果不等,将判断
(NEXT_RCV_SEQ - Sequence Number)mod 4096<2048(判断两者大小)是否成立。
如果成立,说明该TLP Device B之前已经接收过,是一个重复发送的TLP,那么Device A计划发送一个ACK DLLP。如果不成立,说明Sequence Number大于NEXT_RCV_SEQ ,则说明TLP有部分TLP数据包丢失,应该立即返回NAK DLLP,同时置位NAK_SCHEDULED。
如果本篇看完后还是一头雾水,请看下篇。
PCIE开发笔记(八)DLL介绍(下)
在PCIE开发笔记(七)DLL介绍(上)中我们大致介绍了DLL工作的流程,但是对于一些重要的细节,和一些常见的情况还没有介绍,这样会使读者对整个流程没有一个直观的了解,现在我将就几个常见的情况进一步介绍。

图1 ACK/NAK DLLP
在《DLL介绍(上)》中我们大致介绍了ACK/NAK协议的工作原理,其中ACK/NAK DLLP扮演着非常重要的角色,所以很有必要在这里重新详细地介绍这两个DLLP。如图1所示,DLLP有以下几个部分:
- Type字段 Byte 0 bit7:0 :表明该DLLP是ACK还是NAK,对于ACK DLLP 该字节为0000 0000。对于NAK DLLP该字节为0001 0000。
- AckNak_Seq_Num字段: 该字段主要是提供给发送端来表明那些TLP发送成功或者失败。AckNak_Seq_Num=NEXT_RCV_SEQ(After Incrementing) -1 这里有一个需要注意的细节!!!!在上一篇我们说到一个,当Device B(接收端)接收一个TLP数据包,如果其Sequence Number等于NEXT_RCV_SEQ,那么NEXT_RCV_SEQ将自行加一。如果此时Device B需要返回一个ACK DLLP,那么此时公式中的NEXT_RCV_SEQ为自行加一后的值。其他的所有情况,不存在NEXT_RCV_SEQ值变化,所以不需要考虑这个细节。协议做这样的定义使非常的巧妙,在下面你将会体会到它的巧妙。
- 16-bit CRC: 用来校验
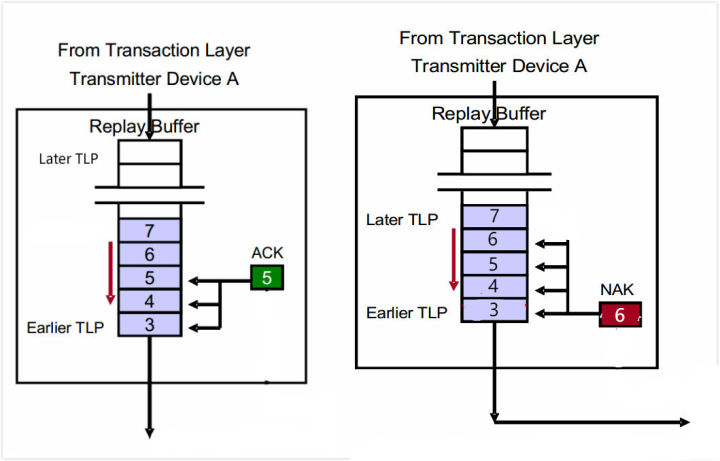
图2 发送端接收DLLP
ACK和NAK DLLP表示的意义不同。以图二为例,当发送端接收一个Sequence Number为5的ACK DLLP,则表示接收端已经接收序号为5和更早的TLP,在此之后发送端将会从Replay Buffer中删除这些数据包。当发送端接收到一个序列号为6的NAK DLLP,则表示接收端没有成功接收序列号为7的TLP,但是于此同时间接的表明序号6及更早的TLP已经成功接收。也就是说不论接收到ACK/NAK DLLP,总是能够证明接收端已经成功接收若干TLP。
接收端并不需要对每一个TLP都要返回一个DLLP,这样可以有效减小ACK DLLP对链路带宽的占用。
从上一篇我们可以看到,发送端不会发送两个序列号不同的NAK DLLP。例如在图2,如果接收端发现序号4 TLP出现错误,那个它将发送一个NAK,如果此后发现 5 TLP错误,那个接收方不会再发送一个NAK,直到它成功接收到序号4 TLP。也就是说不可能有两个NAK同时在传播。
当发送端正在再次发送Buffer中的TLP时,如果此时发送端接收到ACK/NAK DLLP,那么允许发送端先完成这个再次发送,之后再去处理接收的DLLP(尽管这可能不是一种高效的机制)。如果发送端接收一个ACK之后有接收一个新的ACK,那么含有较早序列号的ACK将会被丢弃。
结合一些实例讲述整个流程。
实例一:接收到ACK DLLP,着重点在Device A
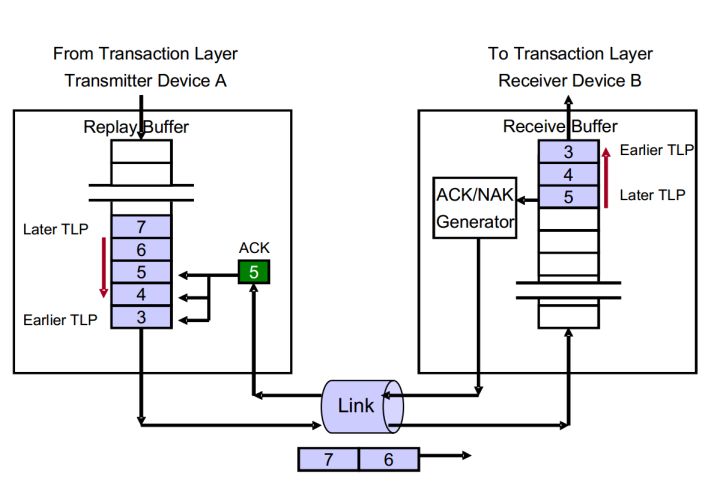
图3 接收ACK DLLP之后的行为
在上一篇中我已经以流程图的形式说明了这个流程,这里我就用图3简要的再阐述一下整个流程。
- Device A发送序列号为3、4、5、6、7 TLP,TLP3是第一个发送的,TLP7是最后发送的
- Device B按顺序接收TLP 3、4、 5。TLP 6,7还正在发送途中。
- Device B将会对TLP3、4、5进行错误检查,确认成功接收了这几个TLP之后,它将返回一个序列号为5的ACK,表明接收了TLP3、4、5。
- Device A接收到ACK 5。
- Device A消除Buffer中TLP3、4、5。
- 当Device B接收到TLP6、7。则重复步骤3-4。
我们可以这样总结,当Device A接收到一个ACK DLLP数据包之后,Device A需要做如下工作:
- 使用DLLP数据包中的AckNak_Seq_Num[11:0]更新ACKD_SEQ寄存器。
- 将计数器REPLAY_NUM和REPLAY_TIMER重置为0。
- 消除Buffer中序列号为AckNak_Seq_Num[11:0]及更早的TLP。
实例2 接收到NAK ,着重点在Device A
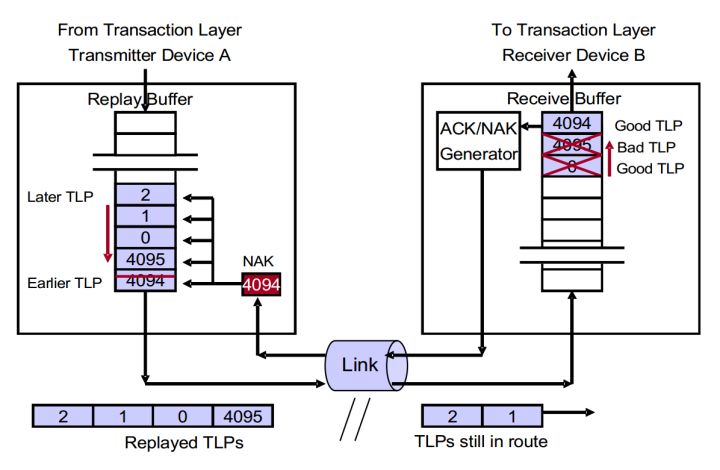
图4 接收NAK DLLP之后的行为
如图4所示,简述整个流程。
- Device A发送TLP 4094、4095、0、1、2。其中TLP 4094是第一个TLP,TLP 2是最后一个TLP。
- Device B按顺序接收TLP 4094、4095、0。TLP1、2还在传输途中。
- Device B成功接收TLP4094,TLP4094不存在问题。同时将NEXT_RCV_SEQ增加至4095。
- Device B接收到含有CRC错误的TLP 4095。
- Device B返回一个序列号为4094的NAK DLLP。
- Device A接收到这个NAK 4094,阻塞DLL继续接收TL层传递的新的TLP,直到再次发送结束。
- Device A去除Buffer中已经接收的TLP,本例为TLP 4094。
- Device A再次发送TLP 4095、0、1、2。但是不从Buffer中去除这些TLP。
我们可以这样总结,当Device A接收到一个NAK DLLP数据包之后,Device A需要做如下工作:
- 消除Buffer中序列号为AckNak_Seq_Num[11:0]及更早的TLP。
- 使用DLLP数据包中的AckNak_Seq_Num[11:0]更新ACKD_SEQ寄存器。
- 只有当NAK DLLP中AckNak_Seq_Num[11:0]在当前ACKD_SEQ之后,才将REPLAY_NUM重置为0。(确保Device A是在向前传输TLP,而不是在原地踏步)同时将REPLAY_TIMER置零。
- 再次发送整个Buffer中的TLP。
每次Device A接收到NAK DLLP,Device A将会再次发送Buffer中的TLP,同时阻止DLL的Buffer接收来自TL层传递的TLP,直到再次发送这个过程结束。在Device A再次发送过程中,Device A接收到ACK/NAK DLLP,那么允许Device A先完成这个再次发送,完成之后再去处理接收的DLLP(尽管这可能不是一种高效的机制)。每次再次发送时,Device A使用REPLAY_NUM来记录再次发送的次数,也就是说接收NAK之后,再次发送这个Buffer中的TLP,如果再次发送的TLP没有一个被Device B接收,那么REPLAY_NUM继续加1,并再次再次发送整个Buffer,如果再次发送的TLP有部分被Device B成功接收,那么Device A将REPLAY_NUM置零。如果Device A再次发送Buffer四次,而Device B每次一个TLP都没有接收成功,则表示整个链路存在一些问题,那么DLL层停止工作,并通知PL层进行链路训练。
引起DLL再次发送Buffer有两中情况:
- Device A接收到NAK DLLP。
- Device A Replay Timer计数器溢出。如果Device A发送TLP以后,但是迟迟没有接收到返回的ACK/NAK DLLP,进而Device A什么措施都不选取显然是非常不合理的。Device A迟迟没有接收到返回的ACK/NAK DLLP的原因可能是DLLP在链路传播途中丢失,或者途中DLLP变化,被Device A接收到之后进行CRC检查发现错误而将它丢弃,或者Device B出现问题而不能发送DLLP。因此很有必要引入一个机制避免这种情况发生。Device A通过设置一个时间计数器,如果长时间接收不到DLLP,那么Device A再次发送整个Buffer,来解决这种情况的发生。
综合实例一,二。我们可以看出,无论是ACK/NAK DLLP,都表明AckNak_Seq_Num[11:0]及更早的TLP已经成功的被Device B 成功的接受。这样做事很巧妙地。我们从上一篇可以看出,Device A对NAK DLLP处理只是在ACK DLLP处理的基础上多了一个再次发送Buffer的部分,这样大大简化了电路。
实例3 返回一个ACK DLLP,着重点在Device B
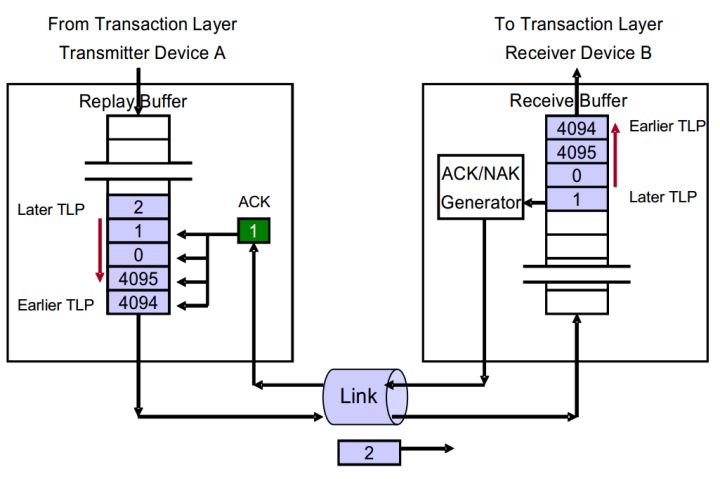
图5 Device B返回ACK DLLP的情况
如图5所示,简述整个流程。
- Device A发送TLP 4094、4095、0、1、2。其中TLP 4094是第一个发送的,TLP 2是最后发送的。
- Device B按顺序接收到TLP 4094、4095、0、1。NEXT_RCV_SEQ增加至2。TLP 2还在发送中。
- Device B进行CRC检查,发送一个ACK DLLP,序列号为1。
- Device B将TLP 4094、4095、0、1传递给TL层。
- Device B最终接收TLP 2。重复步骤2-4。
我们可以这样总结,Device B主要是做如下工作:
- 进行CRC检查,TLP正确并将TLP传递给TL层。
- 对比TLP的Sequence Number和NEXT_RCV_SEQ,发现相同,说明是Device B想接收的TLP。递增NEXT_RCV_SEQ。这一步保证Device B按顺序接收TLP。
- 清除NAK_SCHEDULED。
- 在ACKNAK_LATENCY_TIMER溢出时,返回ACK DLLP,它的序列号为溢出时的NEXT_RCV_SEQ -1 。
实例4 返回一个NAK DLLP,着重点在Device B
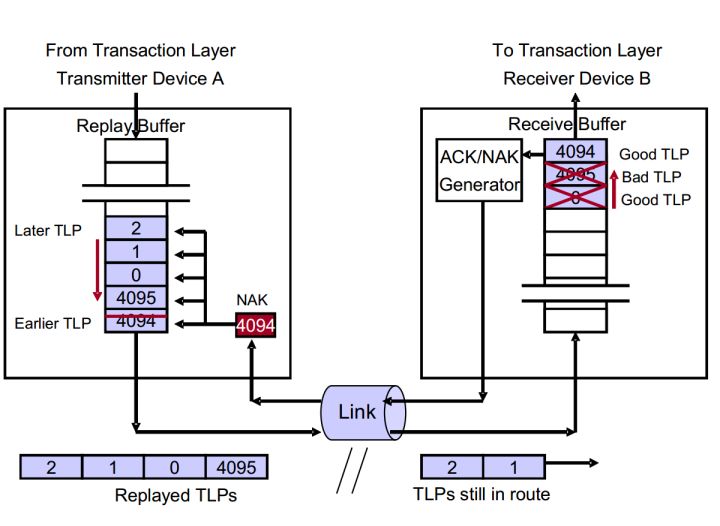
图6 Device B返回NAK DLLP的情况
如图6所示,简述整个流程。
- Device A发送TLP 4094、4095、0、1、2。
- Device B按顺序接收TLP 4094、4095、0。TLP 1、2还在链路上传递。
- Device B正确无误地接收TLP 4094,并将它传递至TL层。并将NEXT_RCV_SEQ增加至4095。
- Device B发现TLP 4095存在CRC错误。那么设置NAK_SCHEDULED为1,同时返回一个NAK DLLP,序号为4094。NEXT_RCV_SEQ不增加。
- Device B丢弃TLP 4095。
- Device B依旧丢弃TLP 0,尽管它是一个正确的TLP。当TLP 1、2到达时同样也丢弃。
- Device B不为TLP 0、1、2发送ACK DLLP。因为NAK_SCHEDULED被设置为1。
- Device A接收到NAK 4094。
- Device A不再接收来自TL的TLP。
- Device A将TLP 4094从Buffer中清楚。
- Device A再次发送TLP 4095、0、1、2。
- 再次发送的TLP 4095、0、1、2依次到达Device B。
- 在确认接收的TLP无错误之后,Device B发现TLP 4095为再次发送的TLP,因为TLP的Sequence Number等于NEXT_RCV_SEQ。清楚NAK_SCHEDULED。
- Device B将这些TLP按顺序传递给TL层。
我们可以这样总结,Device B主要是做如下工作:
- 进行CRC检查,发现TLP出现TLP错误。表明接收TLP失败,那么设置NAK_SCHEDULED位。同时返回一个NAK DLLP,序列号为NEXT_RCV_SEQ -1。
- 如果CRC检查通过,那么查看TLP的Sequence Number是否等于NEXT_RCV_SEQ。如果相等,则表明是Device B期望接收的TLP。如果小于,则表明这个TLP Device B之前已经接收,那么丢弃这个数据包,并将NAK_SCHEDULED置零。
- 如果大于,说明存在TLP丢失。那么如果此时NAK_SCHEDULED为0,就将NAK_SCHEDULED置1,返回一个NAK DLLP。如果NAK_SCHEDULED为1,那么保持原状,不返回NAK DLLP。
综合实例一,二。我们可以总结,出现以下情况后会立即返回一个NAK,并将NAK_SCHEDULED置1:首先返回NAK DLLP的一个大前提是NAK_SCHEDULED=0,然后出现以下任意情况
- PL层发现接受的TLP有问题。
- TLP CRC检查不通过。
- TLP Sequence Number大于NEXT_RCV_SEQ,丢失TLP。
当TLP通过CRC,并且Sequence Number小于等于NEXT_RCV_SEQ。则Device B仅仅将NAK_SCHEDULED清零。
当以下条件满足,Device A将返回一个ACK DLLP:
- DLL层处于工作状态。
- 结合成功的TLP已经传递给TLP。但是还没有返回一个ACK DLLP。
- AckNak_LATENCY_TIMER溢出或者到达设置的值。
- 用于传输ACK DLLP的链路已经处于L0状态。
- 用于传输ACK DLLP的链路当前没有传输其他数据包。
- NAK_SCHEDULED=0。
当NAK_SCHEDULED=1时,Device A不会返回任何DLLP,直到它被清0。
从上面的总结我们可以看出返回一个ACK DLLP更像是一个无意识的行为,只要这些条件满足就自动返回一个ACK DLLP。而返回NAK DLLP目的性更加明显,一旦需要返回NAK DLLP时,只需要置位NAK_SCHEDULED就马上返回。“NAK的立即发送”可以随时打断“ ACK的等待条件满足再发送”,而不会产生任何问题。
到这里我们对ACK/NAK协议介绍已经结束了。
下面我们介绍更多发生错误的实例,来体现ACK/NAK协议保证TLP的正确传输。
实例1:传输途中丢失TLP。
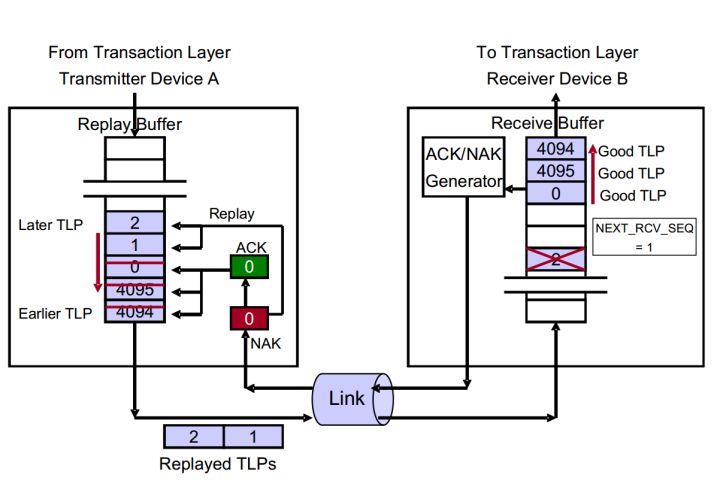
图6 丢失TLP
- Device A按顺序发送发送TLP 4094、4095、0、1、2.
- Device B接收到TLP 4094、4095、0。并返回ACK 0。并将这些TLP传递给TL层。同时递增NEXT_RCV_SEQ至1。
- Device A接收到ACK 0,清楚Buffer中的TLP 4094、4095、0。
- TLP 1在传输途中丢失。
- TLP 2到达Device B。Device B对比TLP 2的Sequence Number和NEXT_RCV_SEQ发现 TLP 2的Sequence Number较大。说明TLP存在丢失。
- Device B丢弃TLP 2。返回NAK 0(NEXT_RCV_SEQ-1)。
- Device A接收到NAK 0。再次发送TLP 1、2。
- TLP 1、2被Device B正确的接收,并传递给TL层。
实例2:传输途中丢失ACK DLLP
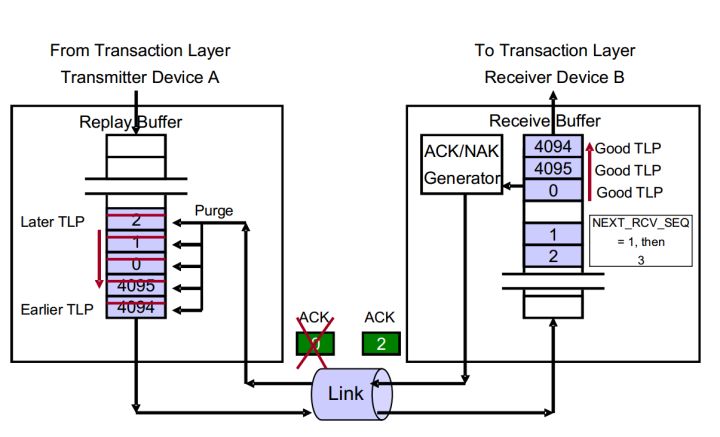
图7 丢失ACK DLLP
- Device A按顺序发送TLP 4094、4095、0、1、2。
- Device B接收到TLP 4094、4095、0。并返回ACK 0。并将这些TLP传递给TL层。同时递增NEXT_RCV_SEQ至1。
- ACK 0丢失。TLP 4094、4095、0仍旧保存在Buffer中。
- TLP 1、2紧跟到达Device B,并被成功接收。NEXT_RCV_SEQ增加至3。
- Device B返回ACK 2,并将TLP 1、2传递给TL层。
- ACK 2到达Device A。
- Device A清除Buffer中的TLP 4094、4095、0、1、2。
在这个事例中,如果ACK 0存在CRC错误,后续流程也是一样的。
如果返回的ACK 2也丢失或者存在CRC错误,那么后续将不会再有ACK/NAK DLLP返回,那么Device A的REPLAY_TIMER将会溢出,导致Device A再次发送Buffer中的TLP。最终Device B将它们全部接收,并返回ACK 2。整个传输任务成功完成。
实例3:传输途中丢失ACK DLLP
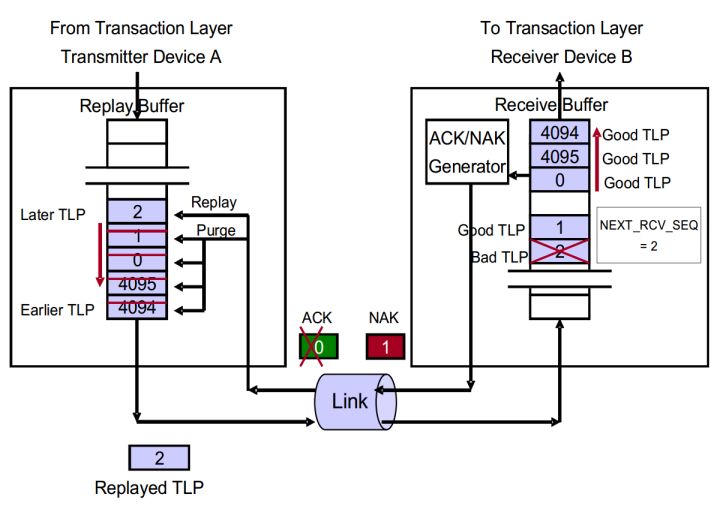
图8 丢失ACK DLLP
- Device A按顺序发送TLP 4094、4095、0、1、2。
- Device B接收到TLP 4094、4095、0。并返回ACK 0。并将这些TLP传递给TL层。同时递增NEXT_RCV_SEQ至1。
- ACK 0丢失。TLP 4094、4095、0仍旧保存在Buffer中。
- TLP 1、2紧跟到达Device B。TLP 1并被成功接收,NEXT_RCV_SEQ增加至2。TLP 1被传递至TL层。
- TLP 2存在错误。NEXT_RCV_SEQ值保持在2。
- Device B返回NAK 1,丢弃TLP 2。
- NAK 1到达Device A。
- Device A清楚TLP 4094、4095、0、1。
- Device A再次发送TLP 2。
- TLP 2到达Device B,此时NEXT_RCV_SEQ为2。
- Device B接收这个正确的TLP 2,并将它传递给TL层。NEXT_RCV_SEQ增加至3。
- 如果此时ACKNAK_LATENCY_TIMER正好溢出,Device B返回ACK 2。
- Device A接收ACK 2,清楚Buffer中的TLP 2。
到此DLL层主要功能介绍结束。
深入PCI与PCIe之一:硬件篇
PCI总线和设备树是X86硬件体系内很重要的组成部分,几乎所有的外围硬件都以这样或那样的形式连接到PCI设备树上。虽然Intel为了方便各种IP的接入而提出IOSF总线,但是其主体接口(primary interface)还依然是PCIe形式。我们下面分成两部分介绍PCI和他的继承者PCIe(PCI express):第一部分是历史沿革和硬件架构;第二部分是软件界面和UEFI中的PCI/PCe。
自PC在1981年被IBM发明以来,主板上都有扩展槽用于扩充计算机功能。现在最常见的扩展槽是PCIe插槽,实际上在你看不见的计算机主板芯片内部,各种硬件控制模块大部分也是以PCIe设备的形式挂载到了一颗或者几颗PCI/PCIe设备树上。固件和操作系统正是通过枚举设备树们才能发现绝大多数即插即用(PNP)设备的。那究竟什么是PCI呢?
PCI/PCIe的历史
在我们看PCIe是什么之前,我们应该要了解一下PCIe的祖先们,这样我们才能对PCIe的一些设计有了更深刻的理解,并感叹计算机技术的飞速发展和工程师们的不懈努力。
1. ISA (Industry Standard Architecture)
2. MCA (Micro Channel Architecture)
3. EISA (Extended Industry Standard Architecture)
4. VLB (VESA Local Bus)
5. PCI (Peripheral Component Interconnect)
6. PCI-X (Peripheral Component Interconnect eXtended)
7. AGP (Accelerated Graphics Port)
8. PCI Express (Peripheral Component Interconnect Express)
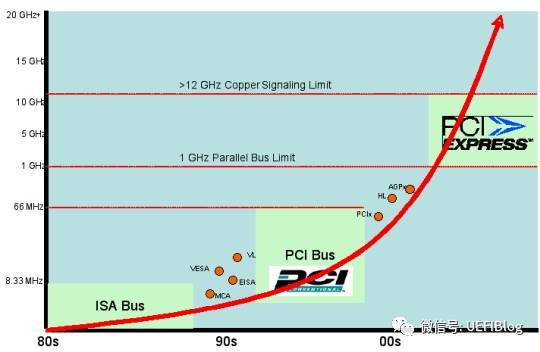
科技的每一步前进都是为了解决前一代中出现的问题,这里的问题就是速度。作为扩展接口,它主要用于外围设备的连接和扩展,而外围设备吞吐速度的提高,往往会倒推接口速度的提升。第一代ISA插槽出现在第一代IBM PC XT机型上(1981),作为现代PC的盘古之作,8位的ISA提供了4.77MB/s的带宽(或传输率)。到了1984年,IBM就在PC AT上将带宽提高了几乎一倍,16位ISA第二代提供了8MB/s的传输率。但其对传输像图像这种数据来说还是杯水车薪。
IBM自作聪明在PS/2产品线上引入了MCA总线,迫使其他几家PC兼容机厂商联合起来捣鼓出来EISA。因为两者都期待兼容ISA,导致速度没有多大提升。真正的高速总线始于VLB,它绑定自己的频率到了当时486 CPU内部总线频率:33MHz。而到了奔腾时代,内部总线提高到了66MHz,给VLB带来了严重的兼容问题,造成致命一击。
Intel在1992年提出PCI(Peripheral Component Interconnect)总线协议,并召集其它的小伙伴组成了名为 PCI-SIG (PCI Special Interest Group)(PCI 特殊兴趣组J)的企业联盟。从那以后这个组织就负责PCI和其继承者们(PCI-X和PCIe的标准制定和推广。
不得不点赞下这种开放的行为,相对IBM当时的封闭,合作共赢的心态使得PCI标准得以广泛推广和使用。有似天雷勾动地火,统一的标准撩拨起了外围设备制造商的创新,从那以后各种各样的PCI设备应运而生,丰富了PC的整个生态环境。
PCI总线标准初试啼声就提供了133MB/s的带宽(33MHz时钟,每时钟传送32bit)。这对当时一般的台式机已经是超高速了,但对于服务器或者视频来说还是不够。于是AGP被发明出来专门连接北桥与显卡,而为服务器则提出PCI-X来连接高速设备。
2004年,Intel再一次带领小伙伴革了PCI的命。PCI express(PCIe,注意官方写法是这样,而不是PCIE或者PCI-E)诞生了,其后又经历了两代,现在是第三代(gen3,3.0),gen4有望在2017年公布,而gen5已经开始起草中。
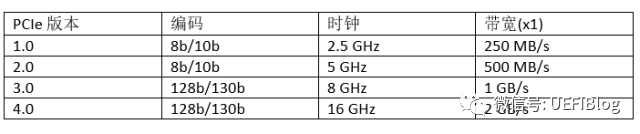
下面这个大表列出所有的速度比较。其中一些x8,x16的概念后面细节部分有介绍。
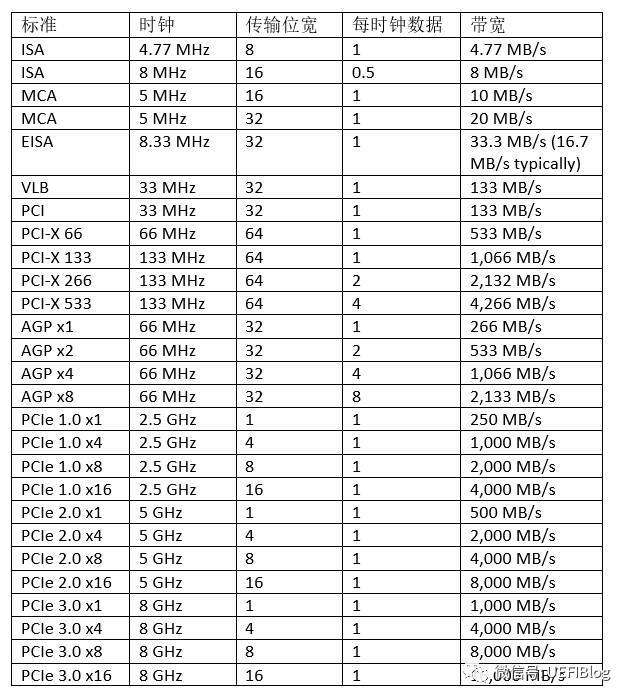
从下面的主频变化图中,大家可能注意到更新速度越来越快。
PCI和PCIe架构
1。PCI架构
一个典型的桌面系统PCI架构如下图:
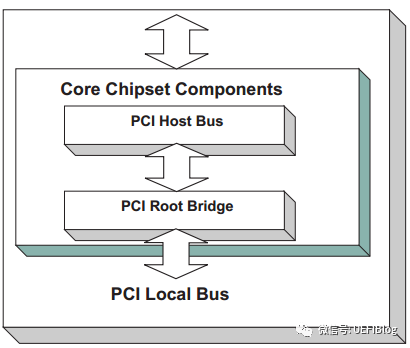
如图,桌面系统一般只有一个Host Bridge用于隔离处理器系统的存储器域与PCI总线域,并完成处理器与PCI设备间的数据交换。每个Host Bridge单独管理独立的总线空间,包括PCI Bus, PCI I/O, PCI Memory, and PCI
Prefetchable Memory Space。桌面系统也一般只有一个Root Bridge,每个Root Bridge管理一个Local Bus空间,它下面挂载了一颗PCI总线树,在同一颗PCI总线树上的所有PCI设备属于同一个PCI总线域。一颗典型的PCI总线树如图:
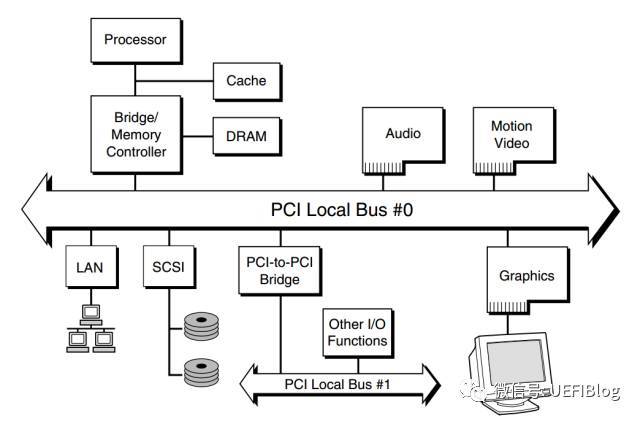
从图中我们可以看出 PCI 总线主要被分成三部分:
1. PCI 设备。符合 PCI 总线标准的设备就被称为 PCI 设备,PCI 总线架构中可以包含多个 PCI 设备。图中的 Audio、LAN 都是一个 PCI 设备。PCI 设备同时也分为主设备和目标设备两种,主设备是一次访问操作的发起者,而目标设备则是被访问者。
2. PCI 总线。PCI 总线在系统中可以有多条,类似于树状结构进行扩展,每条 PCI 总线都可以连接多个 PCI 设备/桥。上图中有两条 PCI 总线。
3. PCI 桥。当一条 PCI 总线的承载量不够时,可以用新的 PCI 总线进行扩展,而 PCI 桥则是连接 PCI 总线之间的纽带。
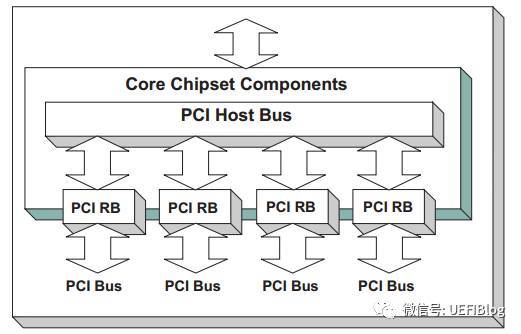
服务器的情况要复杂一点,举个例子,如Intel志强第三代四路服务器,共四颗CPU,每个CPU都被划分了共享但区隔的Bus, PCI I/O, PCI Memory范围,其构成可以表示成如下图:
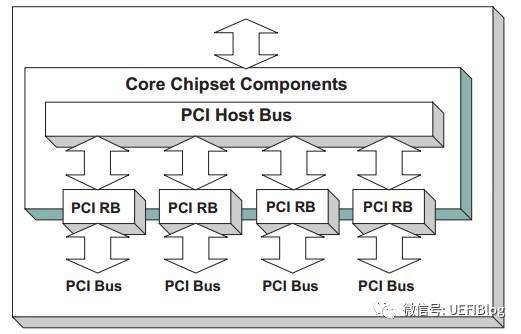
可以看出,只有一个Host Bridge,但有四个Root Bridge,管理了四颗单独的PCI树,树之间共享Bus等等PCI空间。
在某些时候,当服务器连接入大量的PCI bridge或者PCIe设备后,Bus数目很快就入不敷出了,这时就需要引入Segment的概念,扩展PCI Bus的数目。如下例:
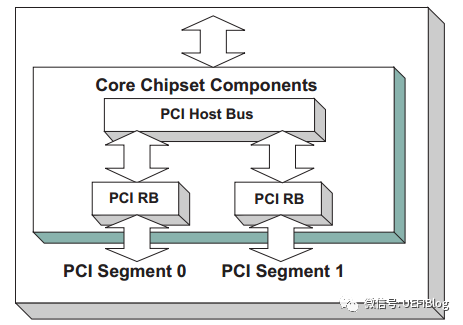
如图,我们就有了两个Segment,每个Segment有自己的bus空间,这样我们就有了512个Bus数可以分配,但其他PCI空间因为只有一个Host Bridge所以是共享的。会不会有更复杂的情况呢? 在某些大型服务器上,会有多个Host bridge的情况出现,这里我们就不展开了。
PCI标准有什么特点吗?
1. 它是个并行总线。在一个时钟周期内32个bit(后扩展到64)同时被传输。引脚定义如下:
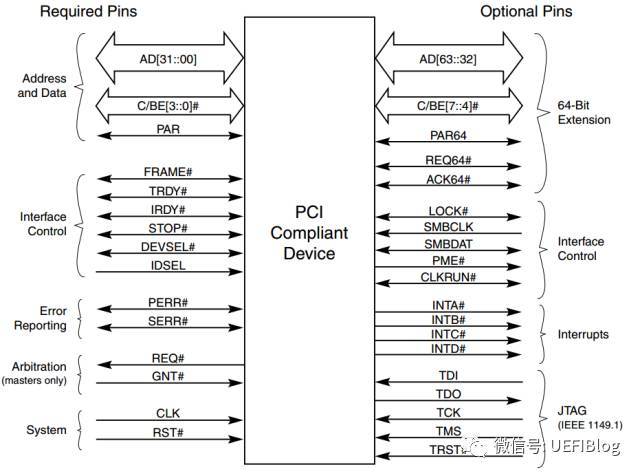
地址和数据在一个时钟周期内按照协议,分别一次被传输。
2. PCI空间与处理器空间隔离。PCI设备具有独立的地址空间,即PCI总线地址空间,该空间与存储器地址空间通过Host bridge隔离。处理器需要通过Host bridge才能访问PCI设备,而PCI设备需要通过Host bridge才能主存储器。在Host bridge中含有许多缓冲,这些缓冲使得处理器总线与PCI总线工作在各自的时钟频率中,彼此互不干扰。Host bridge的存在也使得PCI设备和处理器可以方便地共享主存储器资源。处理器访问PCI设备时,必须通过Host bridge进行地址转换;而PCI设备访问主存储器时,也需要通过Host bridge进行地址转换。
深入理解PCI空间与处理器空间的不同是理解和使用PCI的基础。
3.扩展性强。PCI总线具有很强的扩展性。在PCI总线中,Root Bridge可以直接连出一条PCI总线,这条总线也是该Root bridge所管理的第一条PCI总线,该总线还可以通过PCI桥扩展出一系列PCI总线,并以Root bridge为根节点,形成1颗PCI总线树。在同一条PCI总线上的设备间可以直接通信,并不会影响其他PCI总线上设备间的数据通信。隶属于同一颗PCI总线树上的PCI设备,也可以直接通信,但是需要通过PCI桥进行数据转发。
2。PCIe架构
PCI后期越来越不能适应高速发展的数据传输需求,PCI-X和AGP走了两条略有不同的路径,PCI-x不断提高时钟频率,而AGP通过在一个时钟周期内传输多次数据来提速。随着频率的提高,PCI并行传输遇到了干扰的问题:高速传输的时候,并行的连线直接干扰异常严重,而且随着频率的提高,干扰(EMI)越来越不可跨越。
乱入一个话题,经常有朋友问我为什么现在越来越多的通讯协议改成串行了,SATA/SAS,PCIe,USB,QPI等等,经典理论不是并行快吗?一次传输多个bit不是效率更高吗?从PCI到PCIe的历程我们可以一窥原因。
PCIe和PCI最大的改变是由并行改为串行,通过使用差分信号传输(differential transmission),如图
相同内容通过一正一反镜像传输,干扰可以很快被发现和纠正,从而可以将传输频率大幅提升。加上PCI原来基本是半双工的(地址/数据线太多,不得不复用线路),而串行可以全双工。综合下来,如果如果我们从频率提高下来得到的收益大于一次传输多个bit的收益,这个选择就是合理的。我们做个简单的计算:
PCI传输: 33MHz x 4B = 133MB/s
PCIe 1.0 x1: 2.5GHz x 1b = 250MB/s (知道为什么不是2500M / 8=312.5MB吗?)
速度快了一倍!我们还得到了另外的好处,例如布线简单,线路可以加长(甚至变成线缆连出机箱!),多个lane还可以整合成为更高带宽的线路等等。
PCIe还在很多方面和PCI有很大不同:
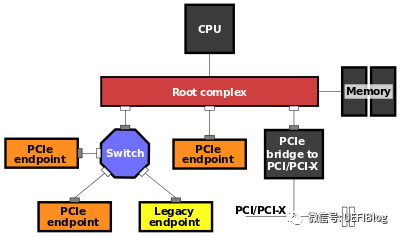
1. PCI是总线结构,而PCIe是点对点结构。一个典型的PCIe系统框图如下:
一个典型的结构是一个root port和一个endpoint直接组成一个点对点连接对,而Switch可以同时连接几个endpoint。一个root port和一个endpoint对就需要一个单独的PCI bus。而PCI是在同一个总线上的设备共享同一个bus number。过去主板上的PCI插槽都公用一个PCI bus,而现在的PCIe插槽却连在芯片组不同的root port上。
2. PCIe的连线是由不同的lane来连接的,这些lane可以合在一起提供更高的带宽。譬如两个1lane可以合成2lane的连接,写作x2。两个x2可以变成x4,最大直到x16,往往给带宽需求最大的显卡使用。
3. PCI配置空间从256B扩展为4k,同时提供了PCIe memory map访问方式,我们在软件部分会详细介绍。
4.PCIe提供了很多特殊功能,如Complete Timeout(CTO),MaxPayload等等几十个特性,而且还在随着PCIe版本的进化不断增加中,对电源管理也提出了单独的State(L0/L0s/L1等等)。这些请参见PCIe 3.0 spec,本文不再详述。
5. 其他VC的内容,和固件理解无关,本文不再提及。INT到MSI的部分会在将来介绍PC中断系统时详细讲解。
PCIe 1.0和2.0采用了8b/10b编码方式,这意味着每个字节(8b)都用10bit传输,这就是为什么2.5GHz和5GHz时钟,每时钟1b数据,结果不是312.5MB/s和625MB/s而是250MB/s和500MB/s。PCIe 3.0和4.0采用128b/130b编码,减小了浪费(overhead),所以才能在8GHz时钟下带宽达到1000MB/s(而不是800MB/s)。即将于今年发布的PCIe 4.0还会将频率提高一倍,达到16GHz,带宽达到2GB/s每Lane。
后记
对于一般用户来说,PCIe对用户可见的部分就是主板上大大小小的PCIe插槽了,有时还和PCI插槽混在一起,造成了一定的混乱,其实也很好区分:

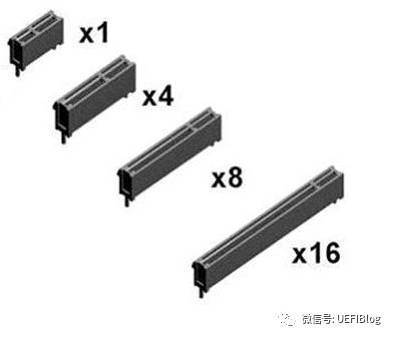
如图,PCI插槽都是等长的,防呆口位置靠上,大部分都是纯白色。PCIe插槽大大小小,最小的x1,最大的x16,防呆口靠下。各种PCIe插槽大小如下:
常见问题:
Q:我主板上没有x1的插槽,我x1的串口卡能不能插在x4的插槽里。
A: 可以,完全没有问题。除了有点浪费外,串口卡也将已x1的方式工作。
Q:我主板上只有一个x16的插槽,被我的显卡占据了。我还有个x16的RAID卡可以插在x8的插槽内吗?
A: 你也许会惊讶,但我的答案同样是:可以!你的RAID卡将以x8的方式工作。实际上来说,你可以将任何PCIe卡插入任何PCIe插槽中! PCIe在链接training的时候会动态调整出双方都可以接受的宽度。最后还有个小问题,你根本插不进去!呵呵,有些主板厂商会把PCIe插槽尾部开口,方便这种行为,不过很多情况下没有。这时怎么办?你懂的。。。。
Q: 我的显卡是PCIe 3.0的,主板是PCIe2.0的,能工作吗?
A: 可以,会以2.0工作。反之,亦然。
Q: 我把x16的显卡插在主板上最长的x16插槽中,可是benchmark下来却说跑在x8下,怎么回事?!
A: 主板插槽x16不见得就连在支持x16的root port上,最好详细看看主板说明书,有些主板实际上是x8。有个主板原理图就更方便了。
Q: 我新买的SSD是Mini PCIe的,Mini PCIe是什么鬼?
A: Mini PCIe接口常见于笔记本中,为54pin的插槽。多用于连接wifi网卡和SSD,注意不要和mSATA弄混了,两者完全可以互插,但大多数情况下不能混用(除了少数主板做了特殊处理),主板设计中的防呆设计到哪里去了!请仔细阅读主板说明书。另外也要小心不要和m.2(NGFF)搞混了,好在卡槽大小不一样。
PCI系列二: 深入PCI与PCIe之二:软件篇 - 知乎专栏
欢迎大家关注本专栏和用微信扫描下方二维码加入微信公众号"UEFIBlog",在那里有最新的文章。同时欢迎大家给本专栏和公众号投稿!

用微信扫描二维码加入UEFIBlog公众号
编辑于 2017-10-28
深入PCI与PCIe之二:软件篇
我们前一篇文章(深入PCI与PCIe之一:硬件篇 - 知乎专栏)介绍了PCI和PCIe的硬件部分。本篇主要介绍PCI和PCIe的软件界面和UEFI对PCI的支持。
PCI/PCIe软件界面
1。配置空间
PCI spec规定了PCI设备必须提供的单独地址空间:配置空间(configuration space),前64个字节(其地址范围为0x000x3F)是所有PCI设备必须支持的(有不少简单的设备也仅支持这些),此外PCI/PCI-X还扩展了0x400xFF这段配置空间,在这段空间主要存放一些与MSI或者MSI-X中断机制和电源管理相关的Capability结构。
前文提到过,PCI配置空间和内存空间是分离的,那么如何访问这段空间呢?我们首先要对所有的PCI设备进行编码以避免冲突,通常我们是以三段编码来区分PCI设备,即Bus Number, Device Number和Function Number,以后我们简称他们为BDF。有了BDF我们既可以唯一确定某一PCI设备。不同的芯片厂商访问配置空间的方法略有不同,我们以Intel的芯片组为例,其使用IO空间的CF8h/CFCh地址来访问PCI设备的配置寄存器:

CF8h: CONFIG_ADDRESS。PCI配置空间地址端口。
CFCh: CONFIG_DATA。PCI配置空间数据端口。
CONFIG_ADDRESS寄存器格式:
31 位:Enabled位。
23:16 位:总线编号。
15:11 位:设备编号。
10: 8 位:功能编号。
7: 2 位:配置空间寄存器编号。
1: 0 位:恒为“00”。这是因为CF8h、CFCh端口是32位端口。
如上,在CONFIG_ADDRESS端口填入BDF,即可以在CONFIG_DATA上写入或者读出PCI配置空间的内容。
PCIe规范在PCI规范的基础上,将配置空间扩展到4KB。原来的CF8/CFC方法仍然可以访问所有PCIe设备配置空间的头255B,但是该方法访问不了剩下的(4K-255)配置空间。怎么办呢?Intel提供了另外一种PCIe配置空间访问方法:通过将配置空间映射到Memory map IO(MMIO)空间,对PCIe配置空间可以像对内存一样进行读写访问了。如图
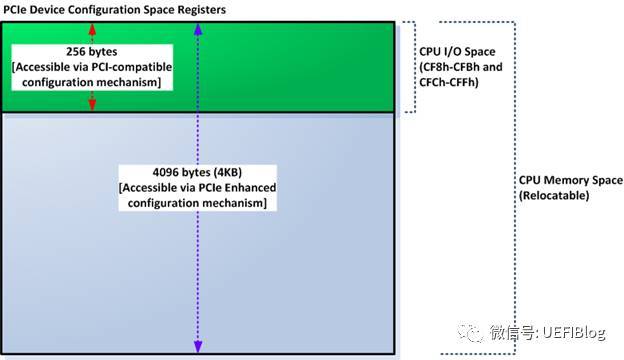
这样再加上PCI板子上的RAM或者ROM,整个PCIe Device空间如下图:
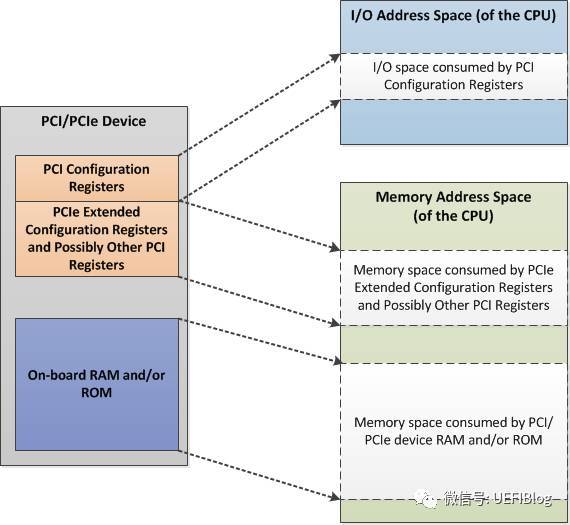
MMIO这段空间有256MB,因为按照PCIe规范,支持最多256个buses,每个Bus支持最多32个PCI devices,每个device支持最多8个function,也就是说:占用内存的最大值为:256 * 32 * 8 * 4K = 256MB。在台式机上我们很多时候觉得占用256MB空间太浪费(造成4G以下memory可用空间变少,虽然实际memory可以映射到4G以上,但对32位OS影响很大),PCI Bus也没有那么多,所以可以设置成最低64MB,即最多64个Bus。那么这个256MB的MMIO空间在在哪里呢?我们以Intel的Haswell平台为例:
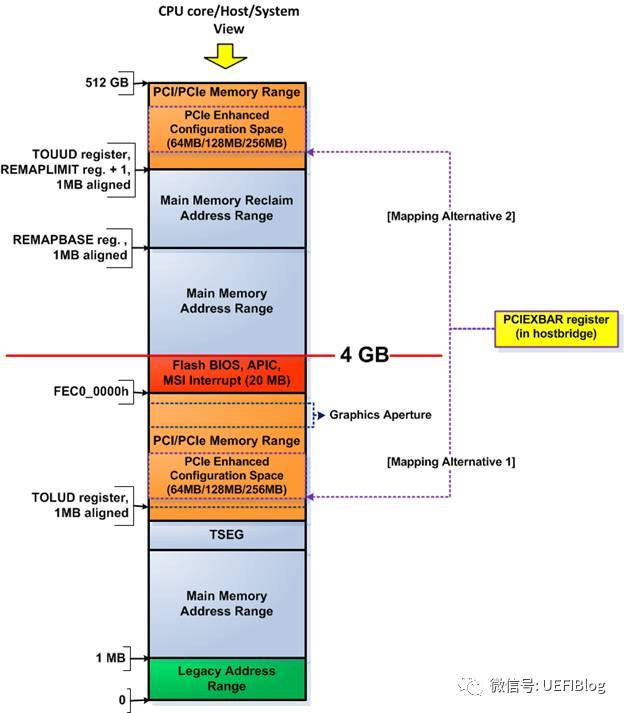
其中PCIEXBAR就是这个MMIO的起始位置,在4G下面占据64MB/128MB/256MB空间(4G以上部分不在本文范围内,我们今后会详细介绍固件中的内存布局),其具体位置可以由平台进行设置,设置寄存器一般在Root complex(下文简称RC)中。
如果大家忘记RC,可以参考前文硬件部分的典型PCIe框图。
RC是PCIe体系结构的一个重要组成部件,也是一个较为混乱的概念。RC的提出与x86处理器系统密切相关,PCIe总线规范中涉及的RC也以x86处理器为例进行说明,而且一些在PCIe总线规范中出现的最新功能也在Intel的x86处理器系统中率先实现。事实上,只有x86处理器才存在PCIe总线规范定义的“标准RC”,而在多数处理器系统,并不含有在PCIe总线规范中涉及的,与RC相关的全部概念。
在x86处理器系统中,RC内部集成了一些PCI设备、RCRB(RC Register Block)和Event Collector等组成部件。其中RCRB由一系列的寄存器组成的大杂烩,而仅存在于x86处理器中;而Event Collector用来处理来自PCIe设备的错误消息报文和PME消息报文。RCRB的访问基地址一般在LPC设备寄存器上设置。
如果将RC中的RCRB、内置的PCI设备和Event Collector去除,该RC的主要功能与PCI总线中的Host Bridge类似,其主要作用是完成存储器域到PCI总线域的地址转换。但是随着虚拟化技术的引入,尤其是引入MR-IOV技术之后,RC的实现变得异常复杂。
2。BAR空间
现在我们来看看在配置空间里具体有些什么。我们以一个一般的type 0(非Bridge)设备为例:
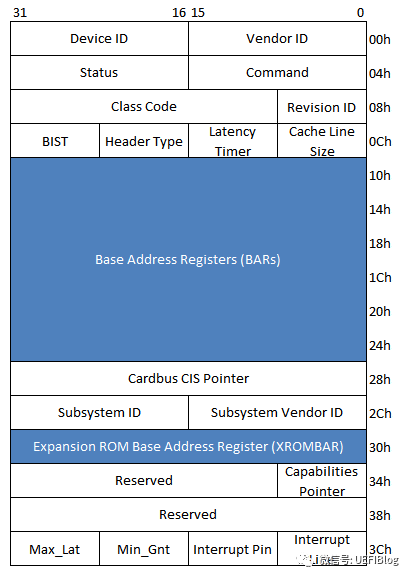
其中Device ID和Vendor ID是区分不同设备的关键,OS和UEFI在很多时候就是通过匹配他们来找到不同的设备驱动(Class Code有时也起一定作用)。为了保证其唯一性,Vendor ID应当向PCI特别兴趣小组(PCI SIG)申请而得到。
我们重点来了解一下这些Base Address Registers(BAR)。BAR是PCI配置空间中从0x10 到 0x24的6个register,用来定义PCI需要的配置空间大小以及配置PCI设备占用的地址空间。
每个PCI设备在BAR中描述自己需要占用多少地址空间,UEFI通过所有设备的这些信息构建一张完整的关系图,描述系统中资源的分配情况,然后在合理的将地址空间配置给每个PCI设备。
BAR在bit0来表示该设备是映射到memory还是IO,bar的bit0是readonly的,也就是说,设备寄存器是映射到memory还是IO是由设备制造商决定的,其他人无法修改。
下图是BAR寄存器的结构,分别是Memory和IO:
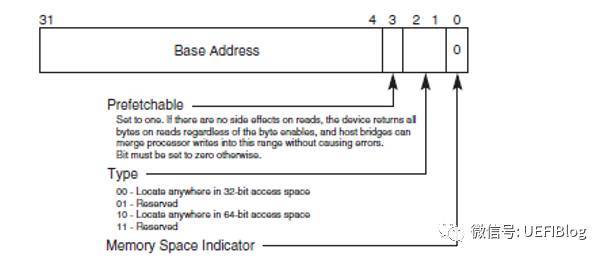
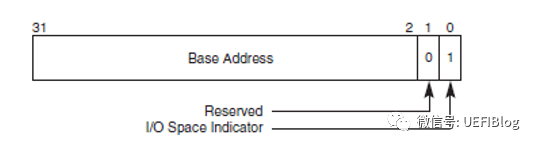
BAR通过将某些位设置为只读,且0来表示需要的地址空间大小,比如一个PCI设备需要占用1MB的地址空间,那么这个BAR就需要实现高12bit是可读写的,而20-4bit是只读且位0。地址空间大小的计算方法如下:
a.向BAR寄存器写全1
b.读回寄存器里面的值,然后clear 上图中特殊编码的值,(IO 中bit0,bit1, memory中bit0-3)。
c.对读回来的值去反,加一就得到了该设备需要占用的地址内存空间。
这样我们就可以在构建一张大表,用于记录所有PCI设备所需要的空间。这也是PCI枚举的主要任务之一。另外别忘记设置Command寄存器enable这些BARs。
3。PCI桥设备
PCI桥在PCI设备树中起到呈上起下的作用。一个PCI-to-PCI桥它的配置空间如下:
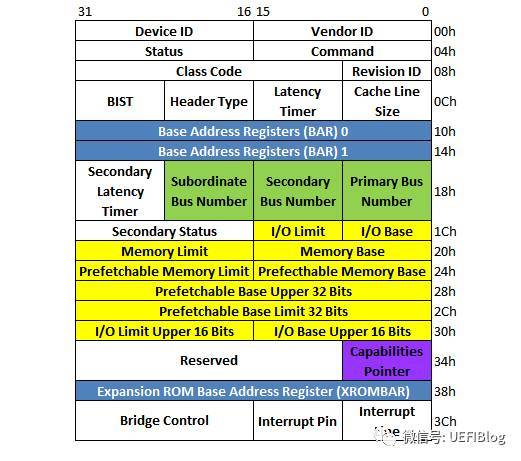
注意其中的三组绿色的BUS Number和多组黄色的BASE/Limit对,它决定了桥和桥下面的PCI设备子树相应/被分配的Bus和各种资源大小和位置。这些值都是由PCI枚举程序来设置的。
4。Capabilities结构
PCI-X和PCIe总线规范要求其设备必须支持Capabilities结构。在PCI总线的基本配置空间中,包含一个Capabilities Pointer寄存器,该寄存器存放Capabilities结构链表的头指针。在一个PCIe设备中,可能含有多个Capability结构,这些寄存器组成一个链表,其结构如图:
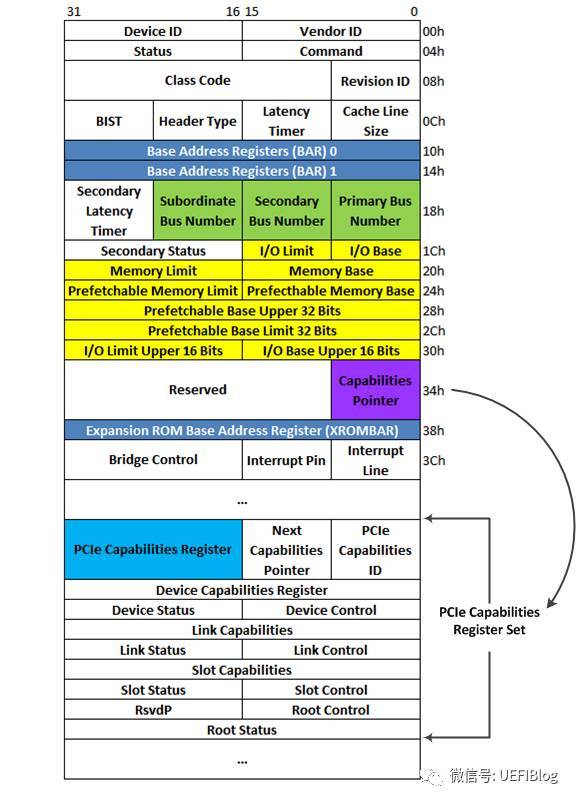
PCIe的各种特性如Max Payload、Complete Timeout(CTO)等等都通过这个链表链接在一起,Capabilities ID由PCIe spec规定。链表的好处是如果你不关心这个Capabilities(或不知道怎么处理),直接跳过,处理关心的即可,兼容性比较好。另外扩展性也强,新加的功能不会固定放在某个位置,淘汰的功能删掉即好。
5。PCI枚举
PCI枚举是个不断递归调用发现新设备的过程,PCI枚举简单来说主要包括下面几个步骤:
A. 利用深度优先算法遍历整个PCI设备树。从Root Complex出发,寻找设备和桥。发现桥后设置Bus,会发现一个PCI设备子树,递归回到A)
B. 递归的过程中通过读取BARs,记录所有MMIO和IO的需求情况并予以满足。
C. 设置必要的Capabilities
在整个过程结束后,一颗完整的资源分配完毕的树就建立好了。
6。地址译码
在PCI总线中定义了两种“地址译码”方式,一个是正向译码,一个是负向译码。当访问Bus N时,其下的所有PCI设备都将对出现在地址周期中的PCI总线地址进行译码。如果这个地址在某个PCI设备的BAR空间中命中时,这个PCI设备将接收这个PCI总线请求。这个过程也被称为PCI总线的正向译码,这种方式也是大多数PCI设备所采用的译码方式。
但是在PCI总线上的某些设备,如PCI-to-(E)ISA桥(或LPC)并不使用正向译码接收来自PCI总线的请求, PCI BUS N上的总线事务在三个时钟周期后,没有得到任何PCI设备响应时(即总线请求的PCI总线地址不在这些设备的BAR空间中),PCI-to-ISA桥将被动地接收这个数据请求。这个过程被称为PCI总线的负向译码。可以进行负向译码的设备也被称为负向译码设备。
在PCI总线中,除了PCI-to-(E)ISA桥可以作为负向译码设备,PCI桥也可以作为负向译码设备,但是PCI桥并不是在任何时候都可以作为负向译码设备。在绝大多数情况下,PCI桥无论是处理“来自上游总线(upstream)”,还是处理“来自下游总线(downstream)”的总线事务时,都使用正向译码方式。如图:
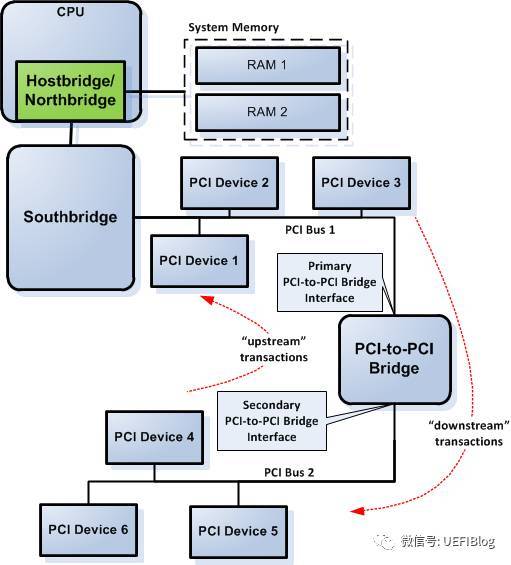
在某些特殊应用中,PCI桥也可以作为负向译码设备。PCI总线规定使用负向译码的PCI桥,其Base Class Code寄存器为0x06,Sub Class Code寄存器为0x04,而Interface寄存器为0x01;使用正向译码方式的PCI桥的Interface寄存器为0x00。
如笔记本在连接Dock插座时,也使用了PCI桥。因为在大多数情况下,笔记本与Dock插座是分离使用的,而且Dock插座上连接的设备多为慢速设备,此时用于连接Dock插座的PCI桥使用负向译码。在该桥管理的设备并不参与处理器系统对PCI总线的枚举过程。当笔记本插入到Dock之后,系统软件并不需要重新枚举Dock中的设备并为这些设备分配系统资源,而仅需要使用负向译码PCI桥管理好其下的设备即可,从而极大降低了Dock对系统软件的影响。
UEFI对PCI/PCIe的支持
UEFI对于PCI总线的支持包括以下三个方面:
1) 提供分配PCI设备资源的协议(Protocol)。
2) 提供访问PCI设备的协议(Protocol)。
3) 提供PCI枚举器,枚举PCI总线上的设备以及分配设备所需的资源。
4) 提供各种Lib,方便驱动程序访问PCI/PCIe配置空间或者MMIO/IO空间。
1.PCI驱动
UEFI BIOS提供了两个主要的模块来支持PCI总线,一个是PCI Host Bridge控制器驱动,另一个是PCI总线驱动。
PCI Host Bridge控制器驱动是跟特定的平台硬件绑定的。根据系统实际I/O空间和memory map,为PCI设备指定I/O空间和Memory空间的范围,并且产生PCI Host Bridge Resource Allocation 协议(Protocol)供PCI总线驱动使用。该驱动还对HostBridge控制器下所有RootBridge设备产生句柄(Handle),该句柄上安装了PciRootBridgeIoProtocol。PCI总线驱动则利用PciRootBridgeIo Protocol枚举系统中所有PCI设备,发现并获得PCI设备的Option Rom,并且调用PCI Host Bridge Resource Allocation 协议(Protocol)分配PCI设备资源。PCI Host Bridge Resource Allocation协议的实现是跟特定的芯和平台相结合的,毕竟只有平台所有者才知道资源从哪里来和有多少。每一个PCI HostBridge Controller下面可以接一个或者多个PCI root bridges,PCI Root Bridge会产生PCI local Bus。正如我们前文举得例子,如Intel志强第三代四路服务器,共四颗CPU,每个CPU都被划分了共享但区隔的Bus, PCI I/O, PCI Memory范围,其构成可以表示成如下图:
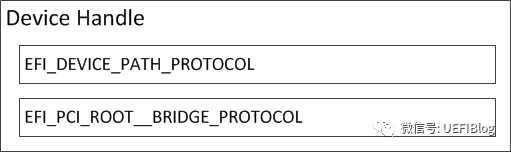
其他情况可见上文。PCI设备驱动不会使用PCI Root Bridge I/O协议访问PCI设备,而是会使用PCI总线驱动为PCI设备产生的PCI IO Protocol来访问PCI设备的IO/MEMORY空间和配置空间。PCI Root Bridge I/O协议(Protocol)是安装在RootBridge设备的句柄上(handle),同时在该handle上也会有表明RootBridge设备的DevicePath协议(Protocol),如下图所示
PCI总线驱动在BDS阶段会枚举整个PCI设备树并分配资源(BUS,MMIO和IO等),它还会在不同的枚举点调用Notify event通知平台,平台的Hook可以挂接在这些点上做些特殊的动作。具体各种点的定义请参阅UEFI spec。
PCI bus驱动在这里:tianocore/edk2
2。PCI Lib
在MdePackage下有很多PCI lib。有Cf8/CFC形式访问配置空间的,有PCIe方式访问的。都有些许不同。注意Cf8/CFC只能访问255以内的,而PCIe方式访问的要配置正确PCIe base address PCD。
结语
本篇没有介绍下列内容,以后有机会再补。
\1. Non-transparent bridge
\2. LPC
\3. 各种PCIe的feature
\4. MSI中断处理
如果你还觉得意犹未尽,仔细思考一下下面这些问题并找找资料有助于你更深入了解PCI/PCIe
1. 前文说过,PCIe的速度和Lane的数目是在Training的时候由Root Port和EndPoint协调得到的。那这个Training的过程发生在什么时候呢? (提示,Hard Strap,Soft Strap, Wait for BIOS/Bifurcation)。
2. UEFI PCI Bus枚举发生在BDS阶段,很靠后。那我们如果在芯片初始化阶段需要对PCI设备MMIO空间的寄存器甚至Bridge后面的设备做些设置,该怎么办呢?
欢迎大家关注本专栏和用微信扫描下方二维码加入微信公众号"UEFIBlog",在那里有最新的文章。同时欢迎大家给本专栏和公众号投稿!

用微信扫描二维码加入UEFIBlog公众号
编辑于 2017-10-28
PCIe的通道是怎么分分合合的?详解PCIe bifurcation
随着AMD新一代CPU的发布,PCIe 4.0 (Gen4)也进入了人们的视线。然而Intel随后宣传PCIe 4.0对消费市场用处不大,AMD则反讽Intel吃不到葡萄说葡萄酸。正在吃瓜群众搬板凳看热闹的时间,一件事情正在发生。PCIe的标准制定组织,PCI-SIG(Peripheral Component Interconnect Special Interest Group)发布了PCIe 6.0(Gen6)的标准!对,你没有看错,不是5.0而是6.0。实际上5.0刚刚发布,如果我们看最近这个组织的活动轨迹:
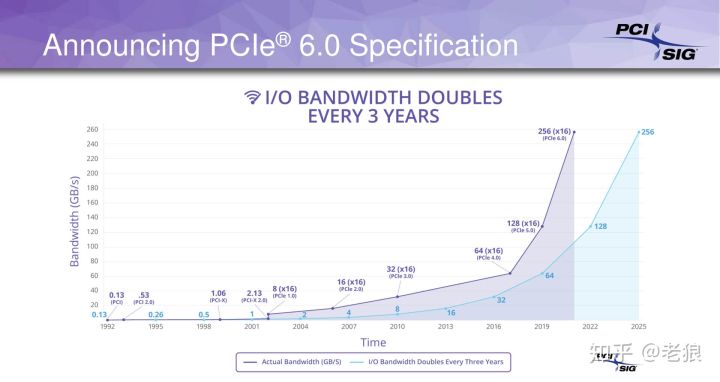
也许是哪里来的莫名其妙王子用亲吻唤醒了她,在蛰伏了7年之后,PCI-SIG加速以翻一番的速度发布新标准,从2017年的Gen4,2018年的Gen5,到2019的Gen6,这个节奏简直疯狂。如果说Intel现在的节奏是Tock、Tock、Tock...,那PCIe就是打了鸡血般的Tick、Tick和Tick!这让主板厂商情何以堪?吃瓜群众也一脸懵懂,到底我是不是该升级呢?
尽管我不认为我们在2021年底之前能看到任何的PCIe 6.0的设备,但PCIe标准的高歌猛进让人们更加关注PCIe这个现代计算机的脊柱总线,也是好事一件。我已经有两篇文章介绍PCIe的基本知识:
老狼:深入PCI与PCIe之一:硬件篇zhuanlan.zhihu.com 老狼:深入PCI与PCIe之二:软件篇zhuanlan.zhihu.com
老狼:深入PCI与PCIe之二:软件篇zhuanlan.zhihu.com
PCIe Lane(通道)
我在前面文章介绍过,PCIe是串行总线,通过使用差分信号传输(differential transmission),如图
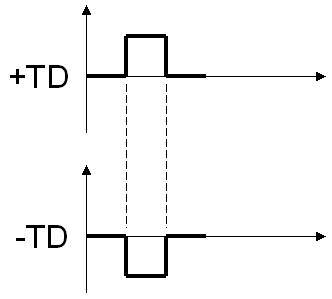
相同内容通过一正一反镜像传输,干扰可以很快被发现和纠正,从而可以将传输频率大幅提升。加上PCI原来基本是半双工的(地址/数据线太多,不得不复用线路),而串行可以全双工。
这样一对差分信号组成一个PCIe Lane,也叫做x1通道。把n组绑定在一起,可以让PCIe设备大幅提高传输带宽。如M.2接口的NVMe SSD一般用四组,四个Lane,也就是x4;而最耗带宽的显卡一般要用16组,就是x16。注意这个n应该是2的幂,所以不存在奇数组或者x10等组合。
PCIe通道的组合和差分
现在PCIe的设备越来越多,Intel的台式机/笔记本平台为了让主板厂商能够灵活满足客户的需求,在CPU和南桥PCH后面都提供了不少PCIe通道:
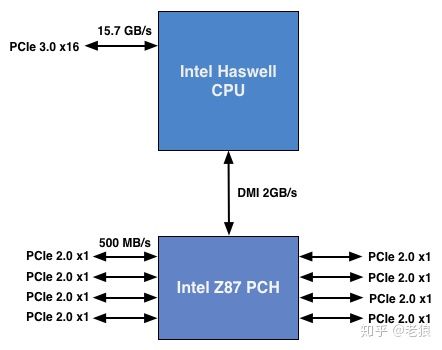
这是个Haswell的例子,比较老,但和现在系统没有本质区别(现在南桥换成PCIe Gen3了)。CPU一般提供PCIe x16通道给显卡,南桥则提供更多的通道,但因为要经过DMI这个小水管,一般不建议链接显卡等需要高带宽的设备。
计算机用户多种多样,有的用户需要插两组显卡,有的则需要很多x1的插槽。为了给主板厂商提供灵活的空间,芯片厂商通过一种叫做bifurcation(分叉)的方式让主板厂商可以灵活配置,组合或者拆分PCIe通道,来做出满足细分市场的产品来。
PCIe初始化一般分为:
1.bifurcation。
2.Root Port Training。根据信号完整性的不同,尽管Root port支持PCIe Gen3/4,但主板走线有问题,有干扰,可能只能Training出Gen2,甚至Gen1的速度来。信号完整性可以参考我的这篇文章:老狼:芯片中的数学——均衡器EQ和它在高速外部总线中的应用
\3. PCI枚举。
\4. PCI/PCIe的各种特性(Feature)设置,如CTO等等。
作为初始化的第一步,bifurcation的重要性自不待言。它决定了各个设备和PCIe插槽的通道宽度。它一般有三种方式:Hard Strap,Soft Strap或者Wait for BIOS。
Hard Strap
所谓Hard,是指这种方式是硬件连线,不能后期修改。在酷睿桌面CPU后面的PCIe通道通常采用这些方式。我们来看个例子,下面所有内容来自Intel官网,7代i5的Datasheet[1]
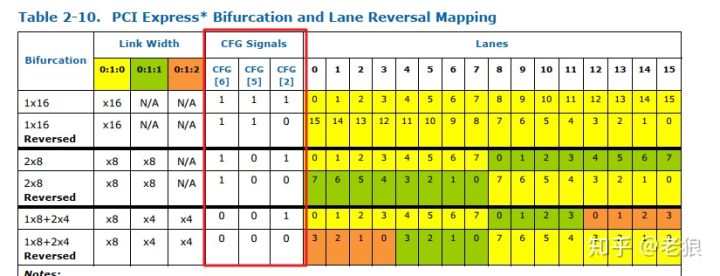 注意红框部分
注意红框部分
我们可以看到这种bifurcation,CPU后面的PCIe是一个x16,还是两个x8,亦或1个x8家两个x4,取决于CFG信号。
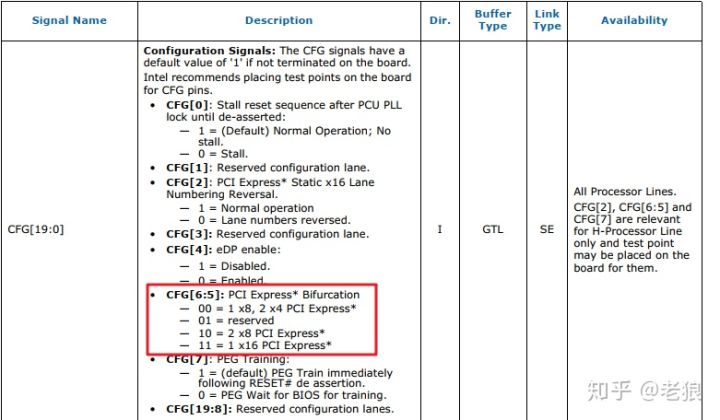
主板厂商根据自己主板样式,如提供了一个显卡插槽,则把CFG[6:5]信号都连高电平,就是一个x16;如果提供两个显卡插槽,则把CFG[6:5]信号连接一高一低,就是两个x8,即两个PCIe显卡就降成x8使用;还有些厂商喜欢把NVMe的m.2连接到CPU后面,来提高存储速度,则可以把CFG[6:5]信号都连低电平,则是1个x8连接显卡,两个x4来连接M.2 SSD。
这种bifurcation一旦确定,就不能更改,除非重新布线。
Soft Strap
所谓Soft,就是软件可以修改。PCH下PCIe root port一般是这种方式。这种配置一般储存在BIOS Image前面的discription中,可以通过工具修改:
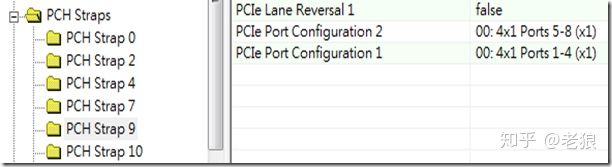
这种修改一般和BIOS程序无关,修改后直接烧录BIOS即可。当然BIOS在Image没有被锁定的情况下,可以重新修改这个区域,但修改后需要重新启动才可以生效。
主板厂商一般根据自己的主板设计情况,在烧录BIOS的时候就用软件改好了相应的值,BIOS一般没有界面去修改这个值。
Wait For BIOS
这种方式是纯BIOS设置,也就是在PCIe Training之前,通过BIOS对相关PCIe root complex的寄存器进行设置来确定通道宽度。
这种方式一般用于至强系列CPU,它们在CPU后面提供高达40个Lanes的支持:
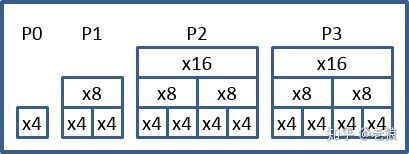 为什么是44个Lane?
为什么是44个Lane?
如图中,我们数一下,一共是44个Lane,不是说40个Lane吗?其实P0的lane是给DMI用的,如果在多路情况下,除了第一个Socket,其他CPU才可以把它用起来。
这么多Lane,因为最高一个设备只支持x16,所以分为几组。一般一组是一个PCIe device,分为4个function,在bifurcation之后,如果该Function轮空,需要我们禁掉该function来省电。
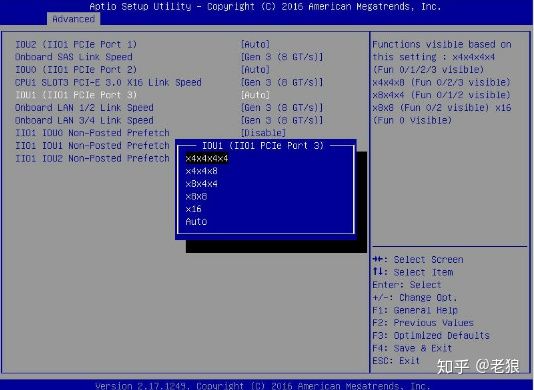
这种方式是最灵活的方式,它赋予至强CPU的用户极大的灵活性,一般会有配置界面来配置:
结论
这许多细节也许比较枯燥,但只有了解现象后面的本质,我们才能够更深刻地理解计算机是怎么工作的。
最后来解决一下有些同学的实际问题,有的同学主板只有一个X16的槽,但想要插两个显卡(想想什么情况下需要),怎么办呢?可以借助一种叫做bifurcation卡的PCIe卡:

现在你知道为什么叫做bifurcation了吧,顾名思义,真的就是分叉啊。
欢迎大家关注本专栏和用微信扫描下方二维码加入微信公众号"UEFIBlog",在那里有最新的文章。

用微信扫描二维码加入UEFIBlog公众号
参考
发布于 2019-06-21
一张图对PCIe进行扫盲(史无前例的好文章)
博观而约取,厚积而薄发
写在开始的话,不知道看了多少资料才总结出一点知识,能输入已经很不容易,何况想要输出,有十能输出一二就算不错了。所以这个过程中真的很难坚持下来,何况没有实际项目作为载体,真的不知道实际运用中这些知识够不够用,这只是基于我之前的经验,认为一个全新的硬件模块中需要掌握的部分。
1 首先要了解这个硬件的用途,物理接口,pin定义。
2 要知道需要做什么样的配置才能使得设备达到我们的预期。
3 设备工作中最重要的就是三个模块,正确识别,注册中断以及终端处理函数,数据传输。
完成以上三步一个硬件模块的bringup就完成了。本文忽略了大部分细节,只为了用最短的篇幅描述好PCIe。
MSI、MSI-X中断和TLP这里不详细展开去说,必要的时候会带出来。
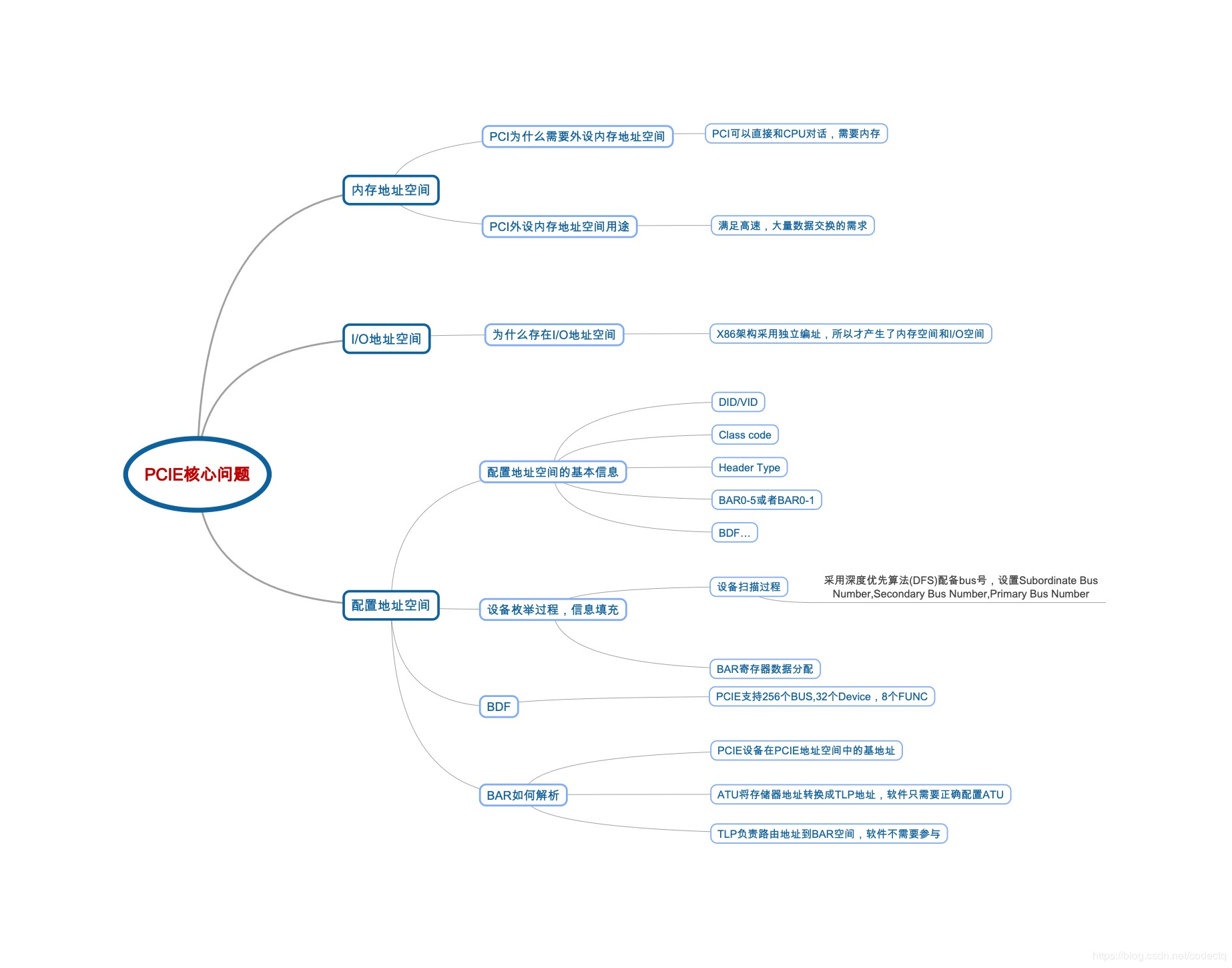
首先用一张图来直观的呈现出要了解PCIe,我们需要知道的一些基本概念。
用华为hisi的芯片来描述PCIe在linux中的驱动注册过程,可以参考本文:https://blog.csdn.net/chengch512/article/details/52635736?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
参考文章链接:
https://www.cnblogs.com/szhb-5251/p/11620310.html
https://www.cnblogs.com/yangxingsha/p/11551472.html
https://blog.csdn.net/kunkliu/article/details/94380357
https://www.sohu.com/a/300238384_505795
https://blog.csdn.net/buyi_shizi/article/details/51068609
https://blog.csdn.net/abcamus/article/details/74157026
https://blog.csdn.net/abcamus/article/details/74157026
一个PCIe设备能够被识别,大致需要经过以下步骤:
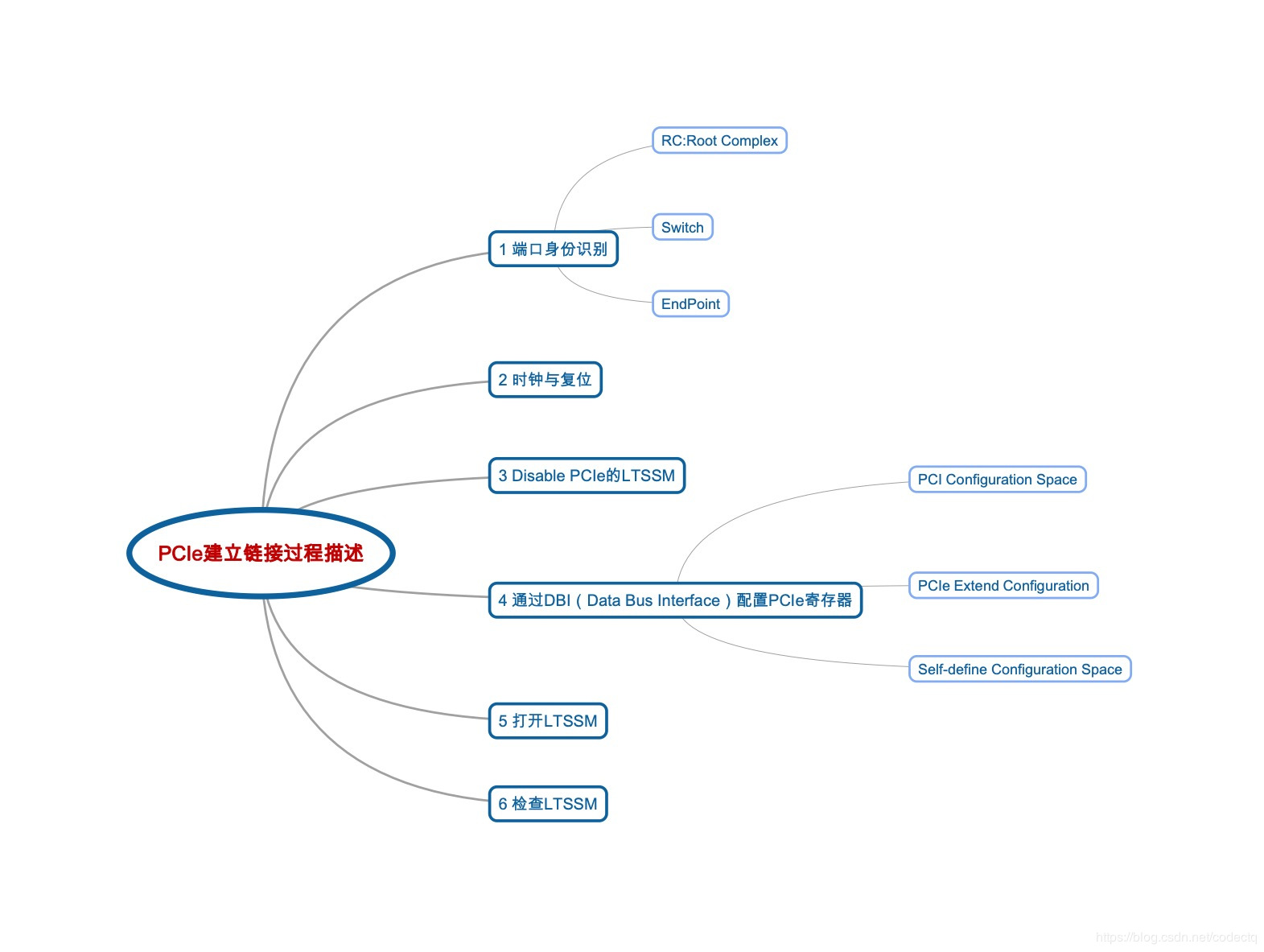
上述过程的详细描述可以参考这个链接:
https://blog.csdn.net/maxwell2ic/article/details/90759280
https://blog.csdn.net/yijingjijng/article/details/48196531
上面的描述我们也能看到,一个设备之所以能够被检测并正确的识别,需要很多个过程,首先这个设备能够从物理上被识别到。而识别到这个设备的第一个关键步骤就是物理层上能够检测到。在设备中按照OSI模型,都会有多个层次结构。对于PCIe同样也不例外,下图就是一个PCIe的层次结构。
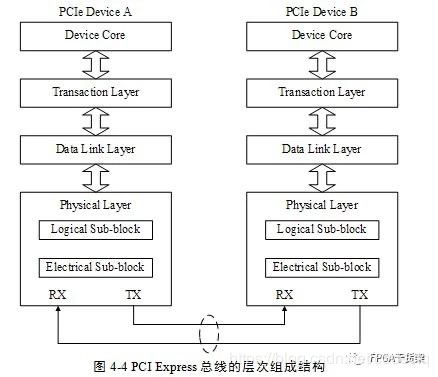
此处只简单描述下PHY层(也就是物理层)中的链路训练状态机(LTSSM,Link Training and Status State Mechine)。
主要包含五类状态:
1 链路训练状态(Link Training State)
Detect
Polling
Configuration
2 重训练状态(Re-Training(Recovery)State)
Recovery
3 软件驱动功耗管理状态(Software Driven Power Managment State)
L2
L0
L1
4 活动状态功耗管理状态(Active-State Power Management State,ASPM State)
L1
L0s
5 其它状态(Other State)
From Configuration or Recovery :Disabled\External Loopback。
From Recovery: Hot Reset。
具体我们可以通过这张图来了解一下LTSSM:
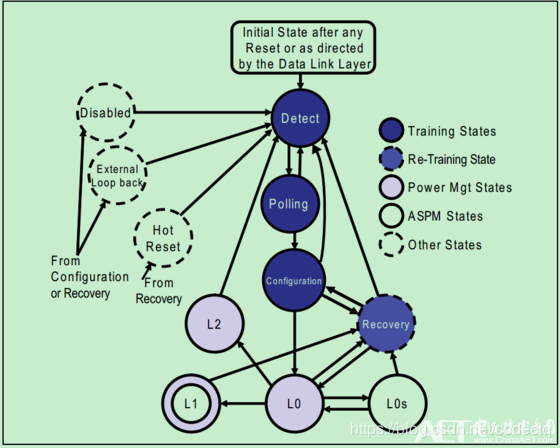
这一部分更为详细的描述,我们可以通过这个链接来看:https://blog.csdn.net/kunkliu/article/details/94594501
以上是在理论层面上全面的了解了PCIe,具体我们在使用的过程中,需要通过软件的方式来实现,从而能够正确的被上层应用使用。
pci驱动在linux中的描述如下:
Once the driver knows about a PCI device and takes ownership, the
driver generally needs to perform the following initialization:
Enable the device
Request MMIO/IOP resources
Set the DMA mask size (for both coherent and streaming DMA)
Allocate and initialize shared control data (pci_allocate_coherent())
Access device configuration space (if needed)
Register IRQ handler (request_irq())
Initialize non-PCI (i.e. LAN/SCSI/etc parts of the chip)
Enable DMA/processing engines
When done using the device, and perhaps the module needs to be unloaded,
the driver needs to take the follow steps:
Disable the device from generating IRQs
Release the IRQ (free_irq())
Stop all DMA activity
Release DMA buffers (both streaming and coherent)
Unregister from other subsystems (e.g. scsi or netdev)
Release MMIO/IOP resources
Disable the device

 浙公网安备 33010602011771号
浙公网安备 33010602011771号