第四次作业
1.用图与自己的话,简要描述Hadoop起源与发展阶段。(作业3中剪过来)
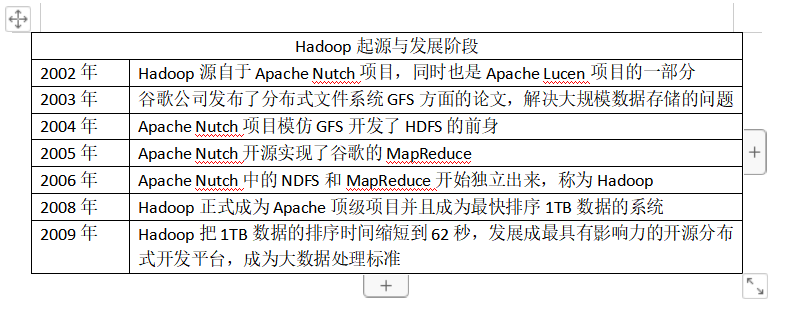
最初Hadoop来源于2002年Apache Nutchd的一个开源的网络搜索引擎,是APACHE lUCENE 项目的一部分,2003年谷歌公司发布了分布式文件GFS方面的论文解决了大规模数据存储的问题;2004年Apache Nutch项目模仿GFS,也就是HDFS的前身;2008年Hadoop正式成为Apache顶级项目,成为最快排序1TB数据的系统,从此Hadoop发展成大数据时代最具有影响力的开源分布式开发平台,成为事实上的大数据标准。
2.用图与自己的话,简要描述名称节点、第二名称节点、数据节点的主要功能及相互关系。
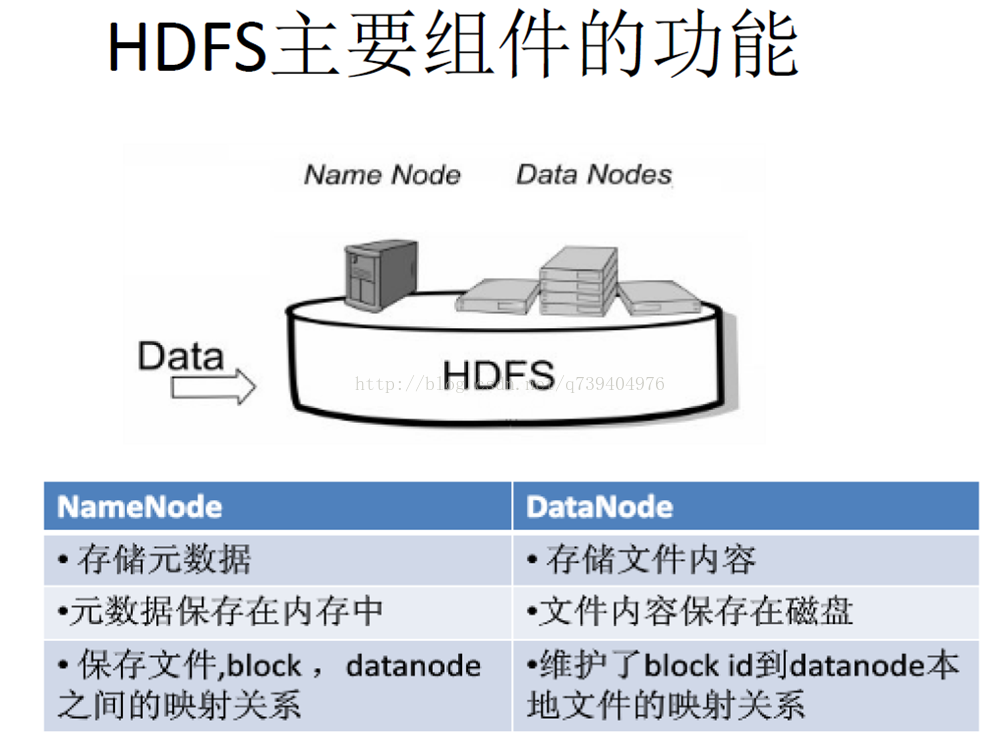
在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即FsImage和EditLog和FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据,操作日志文件EditLog中记录了所有针对文件的创建、删除、重命名等操作。但为了防止EditLog过大的问题:引入了第二名称节点(SecondaryNameNode),第二名称节点:是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间。SecondaryNameNode一般是单独运行在一台机器上。DataNode:数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表
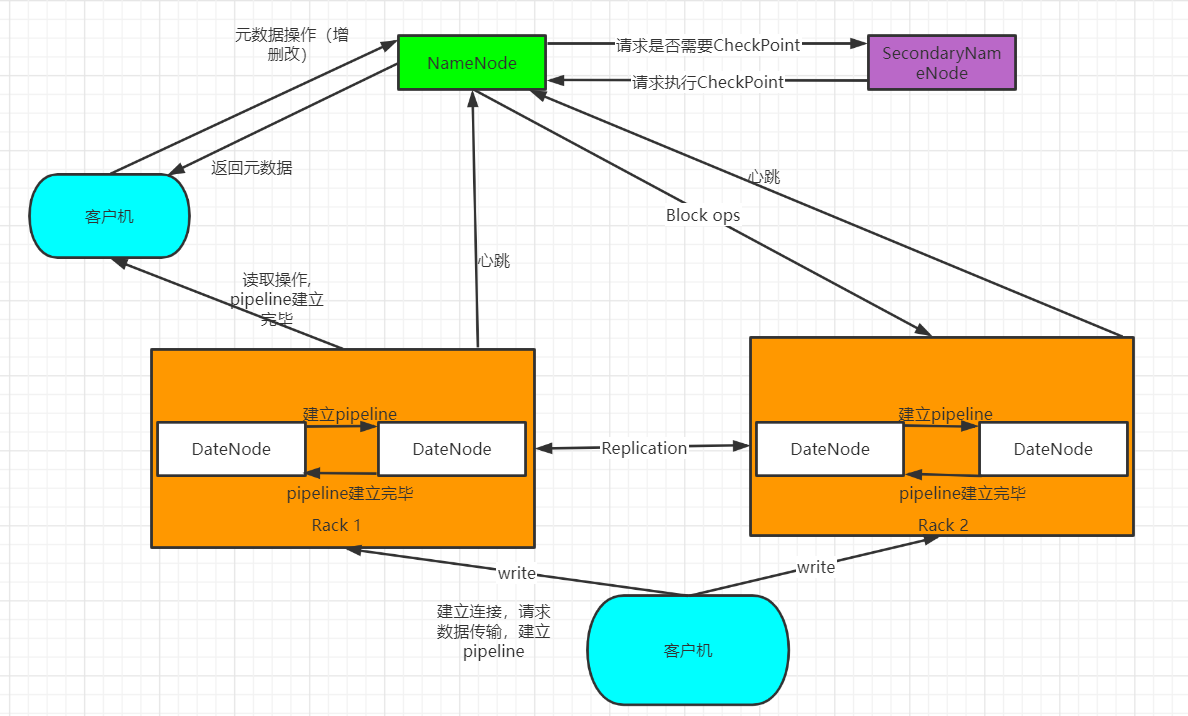
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
- 客户端与HDFS
- 客户端读
- 客户端写
- 数据结点与集群
- 数据结点与名称结点
- 名称结点与第二名称结点
- 数据结点与数据结点
- 数据冗余
- 数据存取策略
- 数据错误与恢复
![]()
4.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述。
- Master主服务器的功能
- Region服务器的功能
- Zookeeper协同的功能
- Client客户端的请求流程
- 与HDFS的关联
Master职责
1 为Region server分配region
2 负责region server的负载均衡
3 发现失效的region server并重新分配其上的region
4 HDFS上的垃圾文件回收
5 处理schema更新请求
Region Server职责
1 Region server维护Master分配给它的region,处理对这些region的IO请求
2 Region server负责切分在运行过程中变得过大的region
可以看到,client访问hbase上数据的过程并不需要master参与(寻址访问zookeeper和region server,数据读写访问regione server),master仅仅维护者table和region的元数据信息,负载很低。
Zookeeper
1 保证任何时候,集群中只有一个master
2 存贮所有Region的寻址入口—-root表在哪台服务器上。
3 实时监控Region Server的状态,将Region server的上线和下线信息实时通知给Master
4 存储Hbase的schema,包括有哪些table,每个table有哪些column family
Client
1 包含访问hbase的接口,client维护着一些cache来加快对hbase的访问,比如regione的位置信息。

HDFS是Hadoop分布式文件系统。
HBase的数据通常存储在HDFS上。HDFS为HBase提供了高可靠性的底层存储支持。
Hbase是Hadoop database即Hadoop数据库。它是一个适合于非结构化数据存储的数据库,HBase基于列的而不是基于行的模式。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据。
HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。 Sqoop则为HBase提供了方便的RDBMS(关系型数据库)数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
5.完整描述Hbase表与Region的关系,三级寻址原理。
HBase通过三级索引结果实现region的寻址。我们逆序描述这个设计的思路,HBase的所有数据region元数据被存储在.META.表中,但是随着region增多,显然.META.会越大越大,最终也会分裂成多个region;-ROOT-表实现定位.META.表的region的位置,保存.META.表中所有region的元数据。而且-ROOT-不会分裂,只有一个region。Zookeeper会记录-ROOT-表的位置信息。
我们在正序描述寻址过程,Client通过ZK找到-ROOT-表的位置,通过-ROOT-表查找到.META.的位置,再从.META.查找用户Region的位置。可以实现最多三次跳转就可以定位任意一个region的效果。为了加快访问速度,.META.表的所有Region全部保存在内存中。客户端会将查询过的位置信息缓存起来,且缓存不会主动失效。
6.理解并描述Hbase的三级寻址。
第 1 步:Client 请求 ZooKeeper 获取.META.所在的 RegionServer 的地址。
第 2 步:Client 请求.META.所在的 RegionServer 获取访问数据所在的 RegionServer 地址,Client会将.META.的相关信息 cache 下来,以便下一次快速访问。
第 3 步:Client 请求数据所在的 RegionServer,获取所需要的数据。
简单地说:
从.META.表里面查询哪个Region包含这条数据。
获取管理这个Region的RegionServer地址。
连接这个RegionServer, 查到这条数据。
7.假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且每个Region限制为2GB,通过HBase的三级寻址方式,理论上Hbase的数据表最大有多大?
(1)用户通过查找zk(zookeeper)的/hbase/root-region-server节点来知道-ROOT-表在什么RegionServer上。
(2)访问-ROOT-表,查看需要的数据在哪个.META.表上,这个.META.表在什么RegionServer上。
(3)访问.META.表查看查询的行健在什么Region范围里面。
(4)连接具体的数据所在的RegionServer,这回就真的开始用Scan来遍历row了。
说明:
.META.表每行保存一个region的位置信息,row key 采用表名+表的最后一样编码而成。
为了加快访问,.META.表的全部region都保存在内存中。
假设,.META.表的一行在内存中大约占用1KB。并且每个region限制为2GB。
那么上面的三层结构可以保存的region数目为:
(2048MB/1KB) * (2048MB/1KB) = = 2^35个region
Client会将查询过的位置信息保存缓存起来,缓存不会主动失效,因此如果client上的缓存全部失效,则需要进行6次网络来回,才能定位到正确的region(其中三次用来发现缓存失效,另外三次用来获取位置信息)。
8.MapReduce的架构,各部分的功能,以及和集群其他组件的关系。
- 1)Client:
用户编写的Mapreduce程序通过Client提交到JobTracker端;同时,用户可通过Client提供的一些接口查看作业运行状态。在Hadoop内部用“作业”(Job)表示Mapreduce程序。
- 2)JobTracker:
JobTracker主要负责资源监控和作业调度。JobTracker监控所有TaskTracker与作业的健康状况,一旦发现失败情况后,会将 相应的任务转移到其他节点;同时,JobTracker会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器,而调度器会在资源出现空闲时,选择合适的任务使用这些资源。
- 3)TaskTracker:
TaskTracker会周期性的通过Heartbeat将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)。TaskTracker使用“slot”等量划分本节点上的资源量。
- 4)Task:
Task分为Map Task和Reduce Task两种,均由TaskTracker启动。从上篇HDFS文档中知道,HDFS以固定大小的block为基本单位存储数据,而对于Mapreduce而言,其处理单位是split。split是一个逻辑概念,它只包含一些元数据信息,比如数据起始位置、数据长度、数据所在节点等
9.MapReduce的工作过程,用自己词频统计的例子,将split, map, partition,sort,spill,fetch,merge reduce整个过程梳理并用图形表达出来。
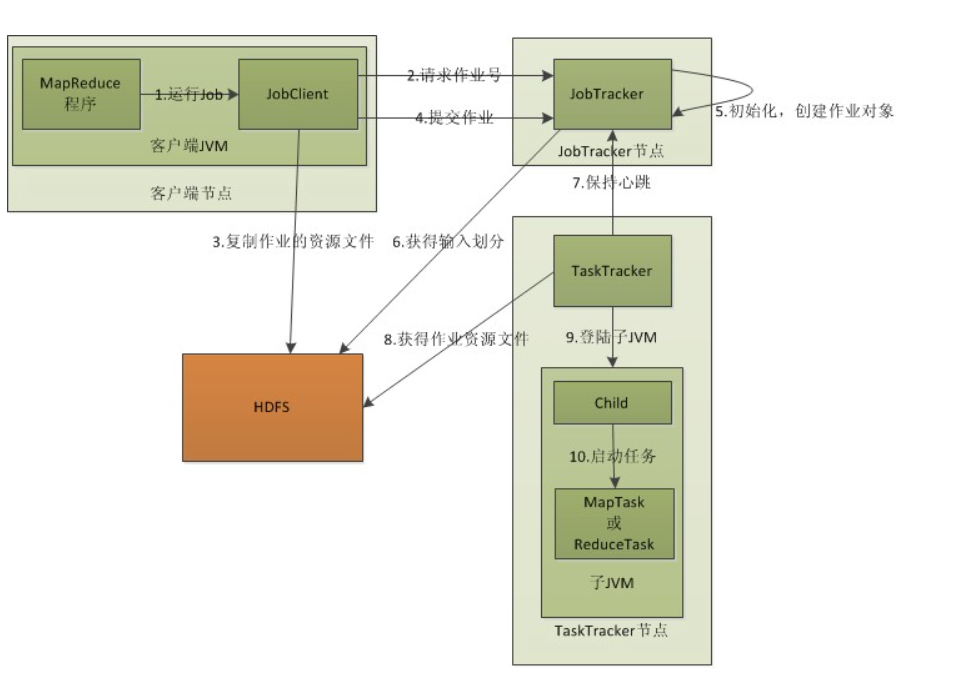

- 客户端(Client):编写mapreduce程序,配置作业,提交作业,这就是程序员完成的工作;
- 向JobTracker请求一个Job ID;
-
将运行作业所需要的资源文件复制到HDFS上,包括MapReduce程序打包的JAR文件、配置文件和客户端计算所得的输入划分信息。这些文件都存放在JobTracker专门为该作业创建的文件夹中。文件夹名为该作业的Job ID。JAR文件默认会有10个副本(mapred.submit.replication属性控制);输入划分信息(Split)告诉了JobTracker应该为这个作业启动多少个map任务等信息。
-
JobTracker接收到作业后,将其放在一个作业队列里(一般来说,公司部门都与自己的队列,默认的调度方法是FIFO,也就是first in first out-队列),等待作业调度器对其进行调度,当作业调度器根据自己的调度算法调度到该作业时,会根据输入划分信息(Split)为每个划分创建一个map任务,并将map任务分配给TaskTracker执行。
-
TaskTracker每隔一段时间会给JobTracker发送一个心跳,告诉JobTracker它依然在运行,同时心跳中还携带着很多的信息,比如当前map任务完成的进度等信息。当JobTracker收到作业的最后一个任务完成信息时,便把该作业设置成“成功”。当JobClient查询状态时,它将得知任务已完成,便显示一条消息给用户。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号