2017-2018-20172309 《程序设计与数据结构》第五周学习总结
2017-2018-20172309 《程序设计与数据结构》第五周学习总结
一、教材学习内容总结(排序与查找)
查找
- 特点:
1.要么找到它、要么确认他不存在。
2.为使查找算法高效,我们应尽可能使比较次数最少化。
- 线性查找法:一个接下一个找,要么找到,要么确认没有要找的元素。空间复杂度为:O(n)
- 二分查找法:
进行二分查找的数组必须是已经经过排序的。
它会从中间开始找,然后又会从两边的中间找,直至找到,或确认没有该元素。
二分查找每次都会删除一半的可行候选项。空间复杂度为nlog2 n
- 两种查找的比较:
| 选项 | 线性查找 | 二分查找 |
|---|---|---|
| 空间复杂度 | O(n) | nlog2 (n) |
| 特点 | 简单,编程与调试容易,但效率低 | 效率高,不浪费资源但数组需经过排序 |
排序
-
排序的方法有:选择排序、插入排序、冒泡排序、快速排序、归并排序和基数排序法。其中前三个已经学过,不在赘述,主要讲解写后面三个:
- 快速排序法:
- 在列表中选择一个元素作为“点”,名为“基准”。
- 将小于该基准的元素放到左边,大于的放到右边。
- 递归的将基准两边的子列表进行快速排序(重复步骤一。)
- 直至每一个子列表都只含有一个元素的时候结束。
-
举个例子:

-
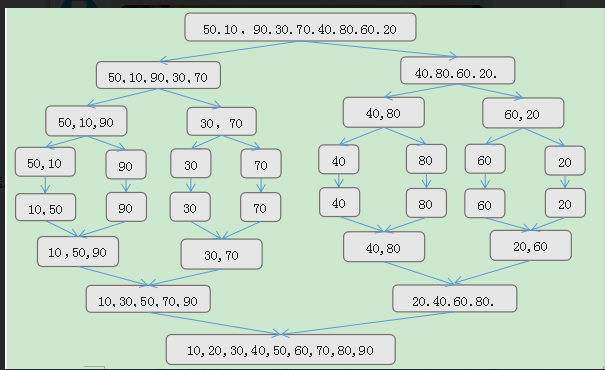
归并排序法:
- 首先将列表分成两个达到约相等的子列表。
- 然后对每一个子列表递归调用本身,至每个子列表只含有一个元素。
- 然后将这些子列表归并到一个排序顺序中。、
- 举个例子:这张图应该能很好说明这个问题!
- 基数排序法:见下面问题。
-
各种排序方法时间复杂度的比较:
- O(n^2):选择排序、插入排序、冒泡排序。
- O(nlog2 n):快速排序、归并排序。
- 基数排序法的时间复杂度为O(d(n+r)),其中,d为位数,r为基数。
二、教材学习中的问题和解决过程
- 问题1:线性查找算法怎么优化?
- 问题1解决方案:
原代码:
while (!found && index <= max) //每一次index都得与max进行比较。
{
found = data[index].equals(target);
index++;
}
上述算法中,每一次循环index都得max进行一次比较,当max趋于无穷大时,就会很拖延时间。因此我们得尽可能的减少比较的次数,但是如何解决他呢?
我们可以让数组的最后一个元素为target(目标),那么这样肯定会找到,只需找到时返回index,如果index=max+1;那么就是咋们添加的元素,即没找到!
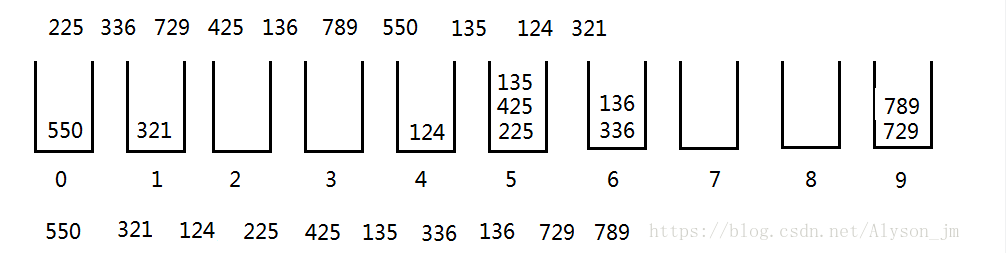
- 问题2:什么是基数排序方法,如何理解?
- 问题2解决方法:
- 直接举个例子吧
- 比较个位数字,分别将它们放到对应号码的桶里。然后分别取出来(从桶底取出来)。
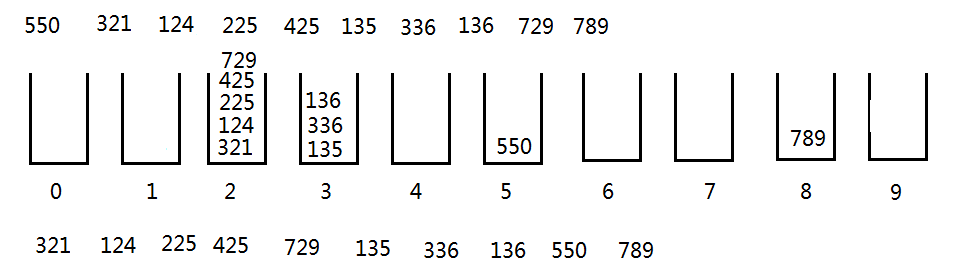
- 比较十位数字,分别将它们放到对应号码的桶里。然后分别取出来(从桶底取出来)。
- 比较百位数字,分别将它们放到对应号码的桶里。然后分别取出来(从桶底取出来)。
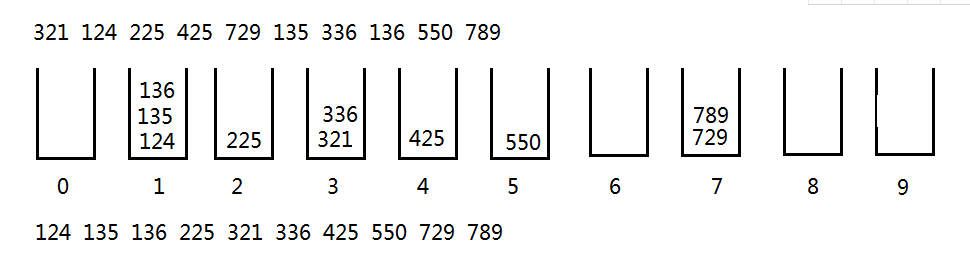
- 一开始的是后还是想不到为什么最后结果为啥就排好了序,仔细一想是这样:
- 百分位越大的就大。(第三次排序)
- 百分位相同的,十分位大的大。(第二次排序)
- 十分位相同的,个位大的大。(第一次排序)
- 问题三:书中基数排序法用到了队列,咋们以前还学过列表,他们有何异同点?
- 问题三解决方法:
- 队列:队列可以用一个循环的数组表示,大小为MAX;有头和尾两个标记head与rear,rear=(rear+1)%MAX;遵循先进先出FIFO原则;

- 列表:列表是有方向的,由一个个节点组成,每个节点除了包含的元素外,还有只想下一个节点的指针。

- 队列:队列可以用一个循环的数组表示,大小为MAX;有头和尾两个标记head与rear,rear=(rear+1)%MAX;遵循先进先出FIFO原则;
代码调试中的问题和解决过程
-
问题1:如何调用形参中有泛型的方法?我出现了这么个鬼:

-
问题1解决方案:上面说int[] 不是 T[],这是因为基本数据类型的数组类型不是T[]的子类.
而应该这样调用:
Integer a[]={5,3,6,8,7,2,1,9,4};
gapSort(a,1);
-
问题2:在做pp9.2项目的间隔排序法时(gap sort),需选择一个大于1的整数i作为间隔进行冒泡排序。当完成一轮迭代时,让i--。直到i=0;
但仔细一想:前面的排序都是没有用的,只有最后一次才是真正的有意义的,所以我就怀疑出题者的意图 -
问题3:如何计算程序的运行时间?
-
问题三解决方案:
- 最初想这个问题是想写一个方法用于计算一个方法的运行时间,传入的参数是一个方法。之后上网查了一下,说是一个方法不能作为形式参数传进另一个方法的。
- 所以还是要用其他方法,因此我选择让每个方法都返回一个String类型的返回值。例如:
return "此方法为insertSort()! "+"比较次数为:"+count+"运行时间为"+(endTime-startTime)+" 纳秒"; - 其中计算时间的代码是:
- long startTime = System.nanoTime();//获取开始的时间;
- long endTime = System.nanoTime();//获取结束的时间
课后作业运行截图:
-
pp9.2:
代码链接:https://gitee.com/CS-IMIS-23/20172309_javaProgramming/commit/6fdf09effa93705d7ef2141d3d005269f278168c -
pp9.3:

代码链接:https://gitee.com/CS-IMIS-23/20172309_javaProgramming/commit/9a51605dbf49a625ec30c91012231b98c11fecb2
代码托管

上周考试错题总结
- 上周无错题。
点评模板:
本周结对学习情况
- [20172310]( http://www.cnblogs.com/Qiuxia2017/)
- 结对学习内容
- 对链表类的测试
- 对第九章的查找与排序的学习。
上周博客互评情况
- [20172310](https://www.cnblogs.com/Qiuxia2017/p/9781103.html)
- [20172301](https://www.cnblogs.com/hzy0628/p/9786586.html)
- ...
其他(感悟、思考等,可选)
- 这一章中,主要讲了查找与排序,查找有线性查找与二分查找。其中二分查找是属于新学的方法,但思想以前有了解过。排序前三个排序方法已经学过,后面两个是属于新学的,个人感觉比较难。但最后还是理解了。通过分析这五个排序的时间复杂度,发现好的算法能够大大地提高效率。因此,设计出一个好的算法是非常重要的。
学习进度条(上学期截止7200)
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 260/0 | 1/1 | 05/05 | |
| 第二周 | 300/560 | 1/2 | 13/18 | |
| 第三周 | 212/772 | 1/4 | 21/39 | |
| 第四周 | 330/1112 | 2/7 | 21/60 | |
| 第五周 | 1321/2433 | 1/8 | 30/90 |
参考资料
- 1.怎样理解基数排序法
- 2.队列、列表、栈
- 3.如何理解基数排序法
- 4.java各种排序方法的算术实现

