

B+Tree 学习
通过阅读GO 语音版本的B+Tree来理解一下B+Tree, B+Tree最有名的应用是用在mysql里面用做索引查找数据
先来一张图说明一下, 这个图来自于https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html,用这个可视化的工具可以通过动画的方式来观看到数据是如何组织的,非常直观
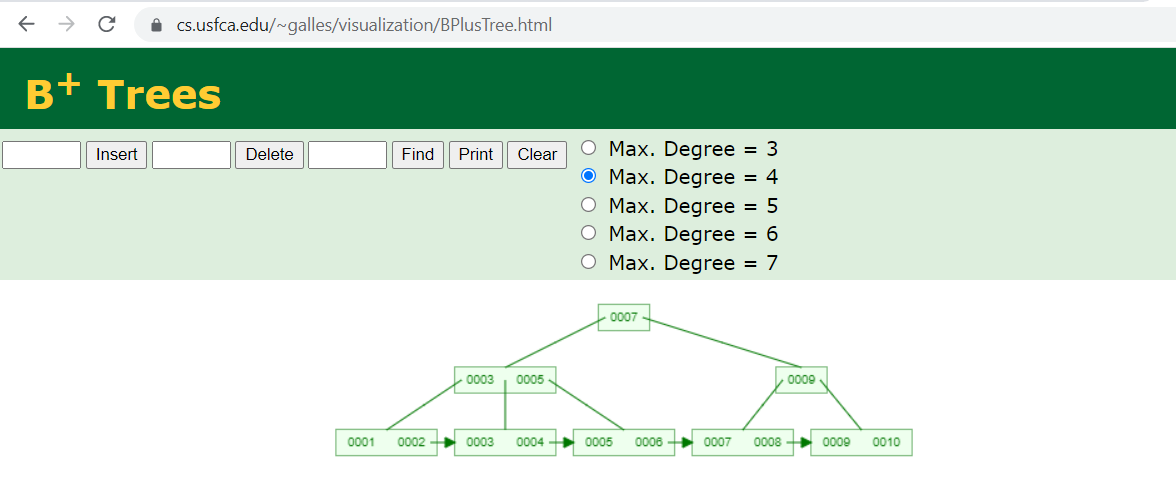
通过图来说明下概念
Max.Degree
这里Max.Degree =4 的意思是说,每个节点最多多少个元素,当等于4个元素的时候就要发生分裂。 比如我再插入11,最后一个节点只有3个,不会发生分裂

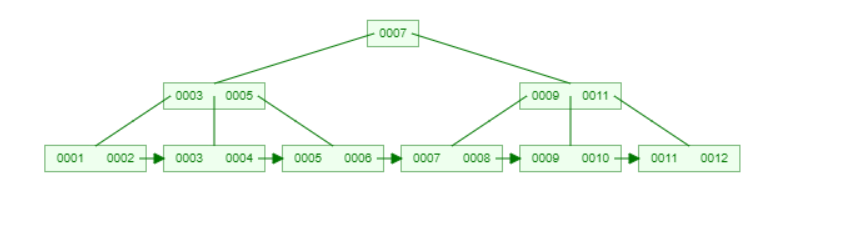
我再插入一个12, 最后一个结点就有4个了,就发生了分裂,分裂成两个
这个是B+Tree很重要的一个概念,mysql 引擎为什么使用B+Tree, 因为数据库的磁盘结构,一个页可以存储16KB, B+Tree的一个Node的Key(8B)和索引(8B), 算起来一个页就可以存1千个Key, 如果有三层的话就可以存储10亿条key, 这里1千个key就是这个Max Degree。
结点和叶子
最下面的结点就是叶子,叶子里面存放着所有的key和数据指针,所有数据再叶子上都能找到,而且是有序排列着,这样查找一段范围的数据,只要找到起始key, 往后就很容易找到范围内的点了。
最上面的结点007 就是root,我们搜索的时候就是从root开始,一直寻找到比key值小的叶子结点,然后在叶子节点中找到对应的key就完成了查找
我们先来看下节点的定义
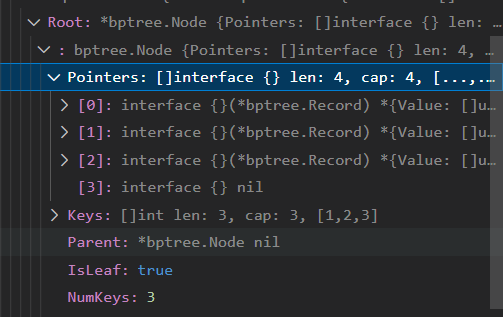
type Node struct {
Pointers []interface{} //用来存指针,指向数据或者别的节点
Keys []int //用来存放key
Parent *Node //指向父节点
IsLeaf bool //是否叶子节点
NumKeys int //key的个数
Next *Node
}
我们再来看下树的定义, 就是一个指向根节点的指针
type Tree struct {
Root *Node
}
下面我们看插入数据代码
func (t *Tree) Insert(key int, value []byte) error {
var pointer *Record
var leaf *Node
if _, err := t.Find(key, false); err == nil {
return errors.New("key already exists")
}
pointer, err := makeRecord(value)
if err != nil {
return err
}
if t.Root == nil {
return t.startNewTree(key, pointer)
}
leaf = t.findLeaf(key, false)
if leaf.NumKeys < order-1 {
insertIntoLeaf(leaf, key, pointer)
return nil
}
return t.insertIntoLeafAfterSplitting(leaf, key, pointer)
}
代码非常好读, 查找叶子,如果叶子节点中的NumKeys < order-1. order就是我们前文中提到的Max.Degree, 就直接插入; 否则就是分裂后插入。insertIntoLeafAfterSplitting 会递归的方式插入到节点中。
下面我们结合可视化图和代码来说明下插入过程和分离过程
1,第一次记录插入1

代码调用startNewTree
func (t *Tree) startNewTree(key int, pointer *Record) error {
t.Root, err = makeLeaf()
if err != nil {
return err
}
t.Root.Keys[0] = key
t.Root.Pointers[0] = pointer
t.Root.Pointers[order-1] = nil
t.Root.Parent = nil
t.Root.NumKeys += 1
return nil
}
可以看到tree的,Root就是我们新加的节点,这个节点也是叶子节点, Root的父节点为空,没有父节点,也没有指向别的节点。
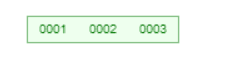
2, 插入记录2和3,过程一样,调用insertIntoLeafwang往叶子节点中插入数据
Keys里面有三个Key, Pointers指向三个Value。
3, 插入记录4,这里就会发生分裂, 会调用insertIntoLeafAfterSplitting
会新建一个叶子节点,然后把003移动的和新节点下面,再新建一个根节点,如下图所示
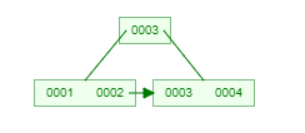
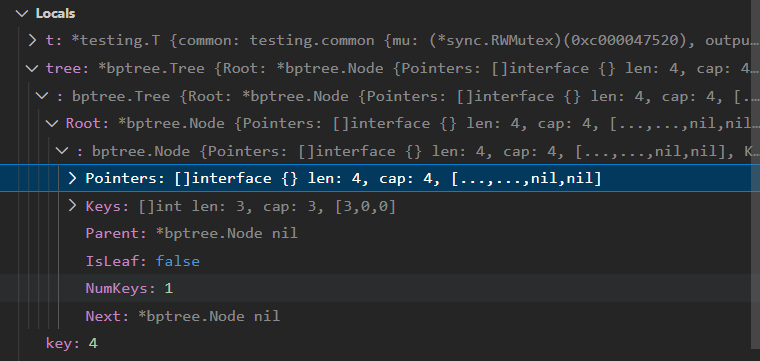
由上图可以看出Root已经换成了0003,并且它的IsLeaf=false了。
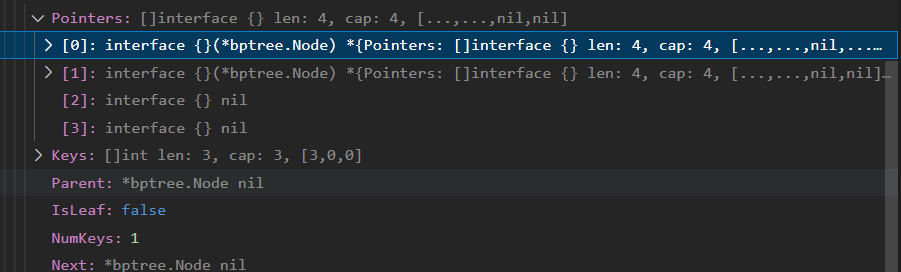
由两个指针分别指向两个叶子节点
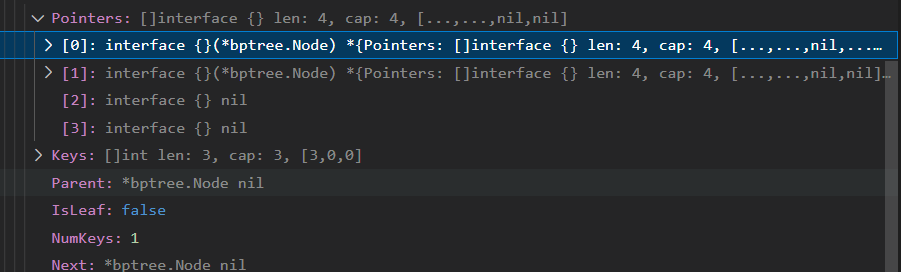
叶子节点中, 0和1分别是数据节点, 3就是指向下一个节点的指针。
到这里插入数据就演示完毕,后面再插入多了,非叶子节点也会发生分裂,重新生成跟结点,过程就是递归,这里不详述。
我们再来看下查找的方法
func (t *Tree) findLeaf(key int, verbose bool) *Node {
i := 0
c := t.Root
if c == nil {
if verbose {
fmt.Printf("Empty tree.\n")
}
return c
}
for !c.IsLeaf {
i = 0
for i < c.NumKeys {
if key >= c.Keys[i] {
i += 1
} else {
break
}
}
c, _ = c.Pointers[i].(*Node)
}
return c
}
这里就是一直循环到叶子节点,查找key 小于我们要找的key。
c.Pointers[i].(*Node), 这里是强制把接口转换为Node指针, 通过递归node来达到查找到对应的节点的效果。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具