java微服务从何学起
参考文档:https://www.zhihu.com/question/42061683/answer/251131634
https://www.jianshu.com/p/7d6853140e13
学了一个多月的微服务框架,下面就把自己的学习方向,分享给大家,希望大家少走弯路。
想要了解微服务,首先要知道为什么微?目的是什么?
建议大家了解一下mysql数据库的分库分表(垂直分库,垂直分表,水平分库分表,水平分表),以及出现的问题,2PC和3PC去解决分库分表中出现的事物不同步的问题。需要的前置知识,mysql事物,ACID,redolog,undolog,binlog;脏读,幻读,可重复读;以及行锁,表锁,间隙锁,排他锁,共享锁,MVCC多线程并发控制。
可能刚看的时候有点困难,可以去看看什么是CAP理论,柔性事物和刚性事物,以及base理论,和一些解决方式。
了解了为什么微,接下来,应该看看redis基础(需要前置知识NIO的理解......)以及主从集群架构和升级版的 Cluster模式。必看。
接下来是重头戏 Zookeeper,这个是必须要看的。
脑子里有了基本知识之后,接下来可以看springCloud以及相关组件,要看springcloud必备的前置知识,spring,springboot,springMVC。
springcloud中首先要看eureka注册中心,然后是Ribbon负载均衡,接下来是http请求组件feign和RestTemple,这些看完了,就要去了解Hystrix熔断降级,Zuul网关,这些看完之后,还需要一个最重要的东西,消息中间件,可以选择kafka(需要前置知识Zookeeper,强关联),或者分布式集群很火的RocketMQ,本人直接看的RocketMQ。
如果有时间,建议再看看Dubbo(阿里巴巴的开源框架)和docker(打包方便并且可移植),LVS网关。
后续学习会继续更新,目前就看到这些.......
----------------------------------------------------------------------------------------------
什么是微服务?
微服务架构风格,就像是把一个单独的应用程序开发为一套小服务,每个小服务运行在自己的进程中,并使用轻量级机制通信,通常是 HTTP API。这些服务围绕业务能力来构建,并通过完全自动化部署机制来独立部署。这些服务使用不同的编程语言书写,以及不同数据存储技术,并保持最低限度的集中式管理。
微服务架构风格(microservice architectural style):把应用程序构建为一套服务。事实是,服务可以独立部署和扩展,每个服务提供了一个坚实的模块边界,甚至不同的服务可以用不同的编程语言编写。它们可以被不同的团队管理。
微服务风格的特性:
组件化(Componentization )与服务(Services)
组件(component)是一个可独立替换和升级的软件单元。
微服务架构(Microservice architectures)会使用库(libraries),但组件化软件的主要方式是把它拆分成服务。
微服务架构(Microservice architectures)会使用库(libraries),但组件化软件的主要方式是把它拆分成服务。我们把库(libraries)定义为组件,这些组件被链接到程序,并通过内存中函数调用(in-memory function calls)来调用,而服务(services )是进程外组件(out-of-process components),他们利用某个机制通信,比如 WebService 请求,或远程过程调用(remote procedure call)。组件和服务在很多面向对象编程中是不同的概念。
把服务当成组件(而不是组件库)的一个主要原因是,服务可以独立部署。如果你的应用程序是由一个单独进程中的很多库组成,那么对任何一个组件的改变都将导致必须重新部署整个应用程序。但是如果你把应用程序拆分成很多服务,那你只需要重新部署那个改变的服务。当然,这也不是绝对的,有些服务会改变导致协调的服务接口,但是一个好的微服务架构的目标就是通过在服务契约(service contracts)中解耦服务的边界和进化机制来避免这些。
发布的接口是指一个类向外公开的成员,比如 Java 中的声明为 Public 的成员。
------------------------------------------------------------------------------------------------------------
一直听说SOA,RPC,注册中心,到底是些什么东东,今天想把这些概念先树立起来........
SOA:把系统按照实际业务,拆分成刚刚好大小的、合适的、独立部署的模块,每个模块之间相互独立。
也就是说,将相同业务拆分到一台服务器上,当请求此业务,直接到这台服务器去找就可以了,不需要在多个服务器出现这个业务的代码。
这样一来,要修改关于注册用户的业务方法只要改这个服务就好了,很好的解耦。同理,其他业务都可以单独形成服务部署在单独服务器上。
如果原有的一台部署了注册服务的服务器承受不了这么高的并发,这时候就可以单独集群部署这个注册服务,提供多几台服务器提供注册服务,而其他服务还不忙,那就维持原样。
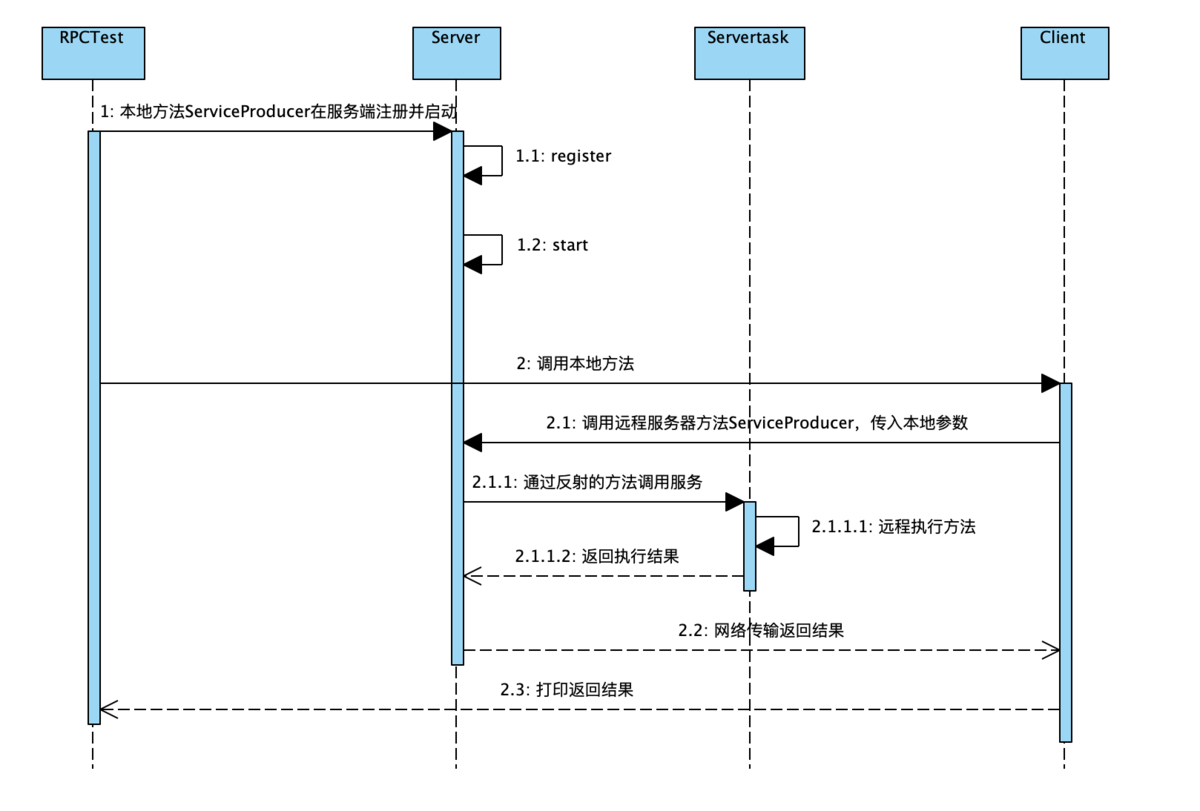
RPC
- RPC(Remote Procedure Call)远程过程调用,简单的理解是一个节点请求另一个节点提供的服务
- 本地过程调用:如果需要将本地student对象的age+1,可以实现一个addAge()方法,将student对象传入,对年龄进行更新之后返回即可,本地方法调用的函数体通过函数指针来指定。
- 远程过程调用:上述操作的过程中,如果addAge()这个方法在服务端,执行函数的函数体在远程机器上,如何告诉机器需要调用这个方法呢?
- Call ID映射。首先客户端需要告诉服务器,需要调用的函数,这里函数和进程ID存在一个映射(这个ID在所有进程中都是唯一的),客户端远程调用时,需要查一下函数,找到对应的ID,然后执行函数的代码。
-
序列化和反序列化。客户端需要把本地参数传给远程函数,本地调用的过程中,直接压栈即可,但是在远程调用过程中不再同一个内存里,无法直接传递函数的参数,因此需要客户端把参数转换成字节流,传给服务端,然后服务端将字节流转换成自身能读取的格式,是一个序列化和反序列化的过程。
- 网络传输。数据准备好了之后,如何进行传输?网络传输层需要把调用的ID和序列化后的参数传给服务端,然后把计算好的结果序列化传给客户端,因此TCP层即可完成上述过程,gRPC中采用的是HTTP2协议。
// Client端 // Student student = Call(ServerAddr, addAge, student) 1. 将这个调用映射为Call ID。 2. 将Call ID,student(params)序列化,以二进制形式打包 3. 把2中得到的数据包发送给ServerAddr,这需要使用网络传输层 4. 等待服务器返回结果 5. 如果服务器调用成功,那么就将结果反序列化,并赋给student,年龄更新 // Server端 1. 在本地维护一个Call ID到函数指针的映射call_id_map,可以用Map<String, Method> callIdMap 2. 等待服务端请求 3. 得到一个请求后,将其数据包反序列化,得到Call ID 4. 通过在callIdMap中查找,得到相应的函数指针 5. 将student(params)反序列化后,在本地调用addAge()函数,得到结果 6. 将student结果序列化后通过网络返回给Client
在微服务的设计中,一个服务A如果访问另一个Module下的服务B,可以采用HTTP REST传输数据,并在两个服务之间进行序列化和反序列化操作,服务B把执行结果返回过来。
2.1. gRPC与REST
- REST通常以业务为导向,将业务对象上执行的操作映射到HTTP动词,格式非常简单,可以使用浏览器进行扩展和传输,通过JSON数据完成客户端和服务端之间的消息通信,直接支持请求/响应方式的通信。不需要中间的代理,简化了系统的架构,不同系统之间只需要对JSON进行解析和序列化即可完成数据的传递。
- 但是REST也存在一些弊端,比如只支持请求/响应这种单一的通信方式,对象和字符串之间的序列化操作也会影响消息传递速度,客户端需要通过服务发现的方式,知道服务实例的位置,在单个请求获取多个资源时存在着挑战,而且有时候很难将所有的动作都映射到HTTP动词。
- 正是因为REST面临一些问题,因此可以采用gRPC作为一种替代方案,gRPC 是一种基于二进制流的消息协议,可以采用基于Protocol Buffer的IDL定义grpc API,这是Google公司用于序列化结构化数据提供的一套语言中立的序列化机制,客户端和服务端使用HTTP/2以Protocol Buffer格式交换二进制消息。
- gRPC的优势是,设计复杂更新操作的API非常简单,具有高效紧凑的进程通信机制,在交换大量消息时效率高,远程过程调用和消息传递时可以采用双向的流式消息方式,同时客户端和服务端支持多种语言编写,互操作性强;不过gRPC的缺点是不方便与JavaScript集成,某些防火墙不支持该协议。
-
注册中心:当项目中有很多服务时,可以把所有的服务在启动的时候注册到一个注册中心里面,用于维护服务和服务器之间的列表,当注册中心接收到客户端请求时,去找到该服务是否远程可以调用,如果可以调用需要提供服务地址返回给客户端,客户端根据返回的地址和端口,去调用远程服务端的方法,执行完成之后将结果返回给客户端。这样在服务端加新功能的时候,客户端不需要直接感知服务端的方法,服务端将更新之后的结果在注册中心注册即可,而且当修改了服务端某些方法的时候,或者服务降级服务多机部署想实现负载均衡的时候,我们只需要更新注册中心的服务群即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号