
线程池问题--ThreadPoolExecutor
|
Java线程池的完整构造函数
|
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
//...
}
|
|
corePoolSize(线程池基本大小)
|
当向线程池提交一个任务时,若线程池已创建的线程数小于corePoolSize,即便此时存在空闲线程,也会通过创建一个新线程来执行该任务,直到已创建的线程数大于或等于corePoolSize时,(除了利用提交新任务来创建和启动线程(按需构造),也可以通过 prestartCoreThread() 或 prestartAllCoreThreads() 方法来提前启动线程池中的基本线程。)
|
|
maximumPoolSize(线程池最大大小)
|
线程池里允许有的最大线程数量
|
|
keepAliveTime(线程存活保持时间)
|
当线程池中线程数大于核心线程数时,线程的空闲时间如果超过线程存活时间,那么这个线程就会被销毁,直到线程池中的线程数小于等于核心线程数。如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0
|
|
unit
|
keepAliveTime的时间单位,有7种单位:
TimeUnit.DAYS; //天
TimeUnit.HOURS; //小时
TimeUnit.MINUTES; //分钟
TimeUnit.SECONDS; //秒
TimeUnit.MILLISECONDS; //毫秒
TimeUnit.MICROSECONDS; //微妙
TimeUnit.NANOSECONDS; //月
|
|
BlockingQueue<Runnable> workQueue
|
用于传输和保存等待执行任务的阻塞队列。
|
|
threadFactory(线程工厂)
|
用于创建新线程。threadFactory创建的线程也是采用new Thread()方式,threadFactory创建的线程名都具有统一的风格:pool-m-thread-n(m为线程池的编号,n为线程池内的线程编号)。
|
|
handler(线程饱和策略)
|
当线程,队列都满了,之后采取的策略,比如抛出异常等策略
○ ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。默认的拒绝策略,如果是比较关键的业务,推荐使用此拒绝策略,这样子在系统不能承载更大的并发量的时候,能够及时的通过异常发现。
○ ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,不做任何处理。使用此策略,可能会使我们无法发现系统的异常状态。建议是一些无关紧要的业务采用此策略。例如,本人的博客网站统计阅读量就是采用的这种拒绝策略。
○ ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务。此拒绝策略,是一种喜新厌旧的拒绝策略。是否要采用此种拒绝策略,还得根据实际业务是否允许丢弃老任务来认真衡量。
○ ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务,如果任务被拒绝了,则由调用线程(提交任务的线程)直接执行此任务
|
- newCachedThreadPool :创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。(线程最大并发数不可控制)
- newFixedThreadPool:创建一个固定大小的线程池,可控制线程最大并发数,超出的线程会在队列中等待。
- newScheduledThreadPool : 创建一个定时线程池,支持定时及周期性任务执行。
- newSingleThreadExecutor :创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
SingleThreadExecutor 相当于特殊的 FixedThreadPool,它的执行流程如下:
- 线程池中没有线程时,新建一个线程执行任务
- 有一个线程以后,将任务加入阻塞队列,不停的加
- 唯一的这一个线程不停地去队列里取任务执行
SingleThreadExecutor 用于串行执行任务的场景,每个任务必须按顺序执行,不需要并发执行。
1 public class SingleThreadExecutorTest { 2 3 public static void main(String[] args) { 4 ExecutorService executorService = Executors.newSingleThreadExecutor(); 5 MyRunnable myRunnable = new MyRunnable(); 6 for (int i = 0; i < 5; i++) { 7 executorService.execute(myRunnable); 8 } 9 10 System.out.println("线程任务开始执行"); 11 executorService.shutdown(); 12 } 13 14 }
newFixedThreadPool
FixedThreadPool 的核心线程数和最大线程数都是指定值,也就是说当线程池中的线程数超过核心线程数后,任务都会被放到阻塞队列中。
此外 keepAliveTime 为 0,也就是多余的空余线程会被立即终止(由于这里没有多余线程,这个参数也没什么意义了)。
而这里选用的阻塞队列是 LinkedBlockingQueue,使用的是默认容量 Integer.MAX_VALUE,相当于没有上限。
因此这个线程池执行任务的流程如下:
- 线程数少于核心线程数,也就是设置的线程数时,新建线程执行任务
- 线程数等于核心线程数后,将任务加入阻塞队列
- 由于队列容量非常大,可以一直加
- 执行完任务的线程反复去队列中取任务执行
FixedThreadPool 用于负载比较重的服务器,为了资源的合理利用,需要限制当前线程数量。
newCachedThreadPool
CachedThreadPool 没有核心线程,非核心线程数无上限,也就是全部使用外包,但是每个外包空闲的时间只有 60 秒,超过后就会被回收。
CachedThreadPool 使用的队列是 SynchronousQueue,这个队列的作用就是传递任务,并不会保存。
因此当提交任务的速度大于处理任务的速度时,每次提交一个任务,就会创建一个线程。极端情况下会创建过多的线程,耗尽 CPU 和内存资源。
它的执行流程如下:
- 没有核心线程,直接向 SynchronousQueue 中提交任务
- 如果有空闲线程,就去取出任务执行;如果没有空闲线程,就新建一个
- 执行完任务的线程有 60 秒生存时间,如果在这个时间内可以接到新任务,就可以继续活下去,否则就拜拜
- 由于空闲 60 秒的线程会被终止,长时间保持空闲的 CachedThreadPool 不会占用任何资源。
CachedThreadPool 用于并发执行大量短期的小任务,或者是负载较轻的服务器。
newScheduledThreadPool
ScheduledThreadPoolExecutor 的执行流程如下:
- 添加一个任务
- 线程池中的线程从 DelayQueue 中取任务
- 然后执行任务
具体执行任务的步骤也比较复杂:
-
线程从 DelayQueue 中获取 time 大于等于当前时间的 ScheduledFutureTask
-
执行完后修改这个 task 的 time 为下次被执行的时间
-
然后再把这个 task 放回队列中
ScheduledThreadPoolExecutor 用于需要多个后台线程执行周期任务,同时需要限制线程数量的场景。
Executors和ThreaPoolExecutor创建线程池的区别
Executors 各个方法的弊端:
- newFixedThreadPool 和 newSingleThreadExecutor:
主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至 OOM。 - newCachedThreadPool 和 newScheduledThreadPool:
主要问题是线程数最大数是 Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至 OOM。
ThreaPoolExecutor
- 创建线程池方式只有一种,就是走它的构造函数,参数自己指定
两种提交任务的方法
ExecutorService 提供了两种提交任务的方法:
- execute():提交不需要返回值的任务
- submit():提交需要返回值的任务
execute() 的参数是一个 Runnable,也没有返回值。因此提交后无法判断该任务是否被线程池执行成功。
submit() 有三种重载,参数可以是 Callable 也可以是 Runnable。
同时它会返回一个 Funture 对象,通过它我们可以判断任务是否执行成功。
获得执行结果调用 Future.get() 方法,这个方法会阻塞当前线程直到任务完成。
-----------------------------------------------------------------------------------------------
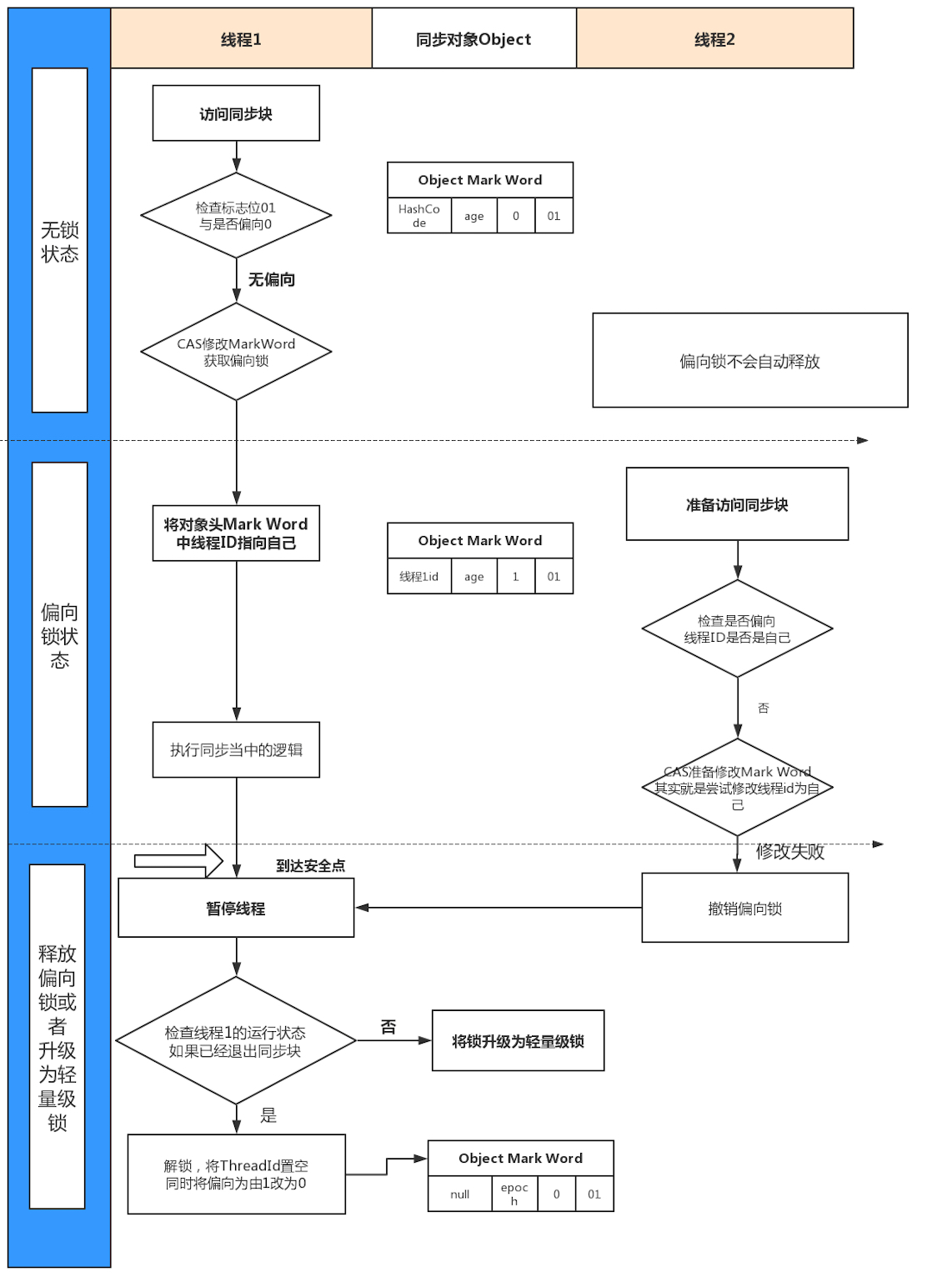
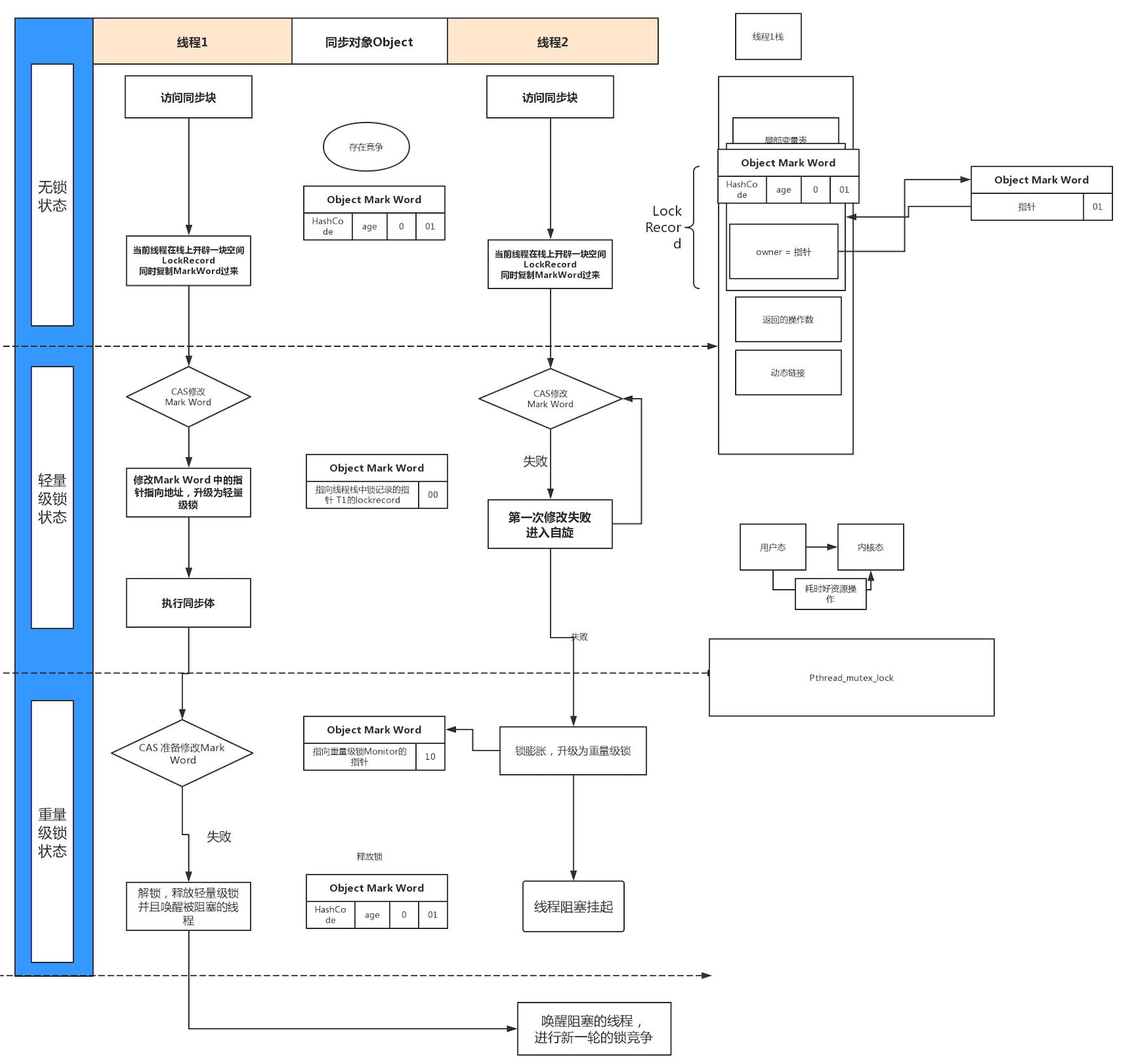
多线程锁的升级

 浙公网安备 33010602011771号
浙公网安备 33010602011771号