正则表达式入门
正则表达式
正则——规则、模式
一. 复习字符串操作:
字符串的位置也包括0。
- search——查找
var str='abcdef'
alert(str.search('bc'));
弹出结果为1,表示字符串b出现的位置。如果查找一个不存在的字符,返回的值为-1。
- substring——获取子字符串
var str='abcdef'
alert(str.substring(1,4));
得到的字符串值为bcd。注意从起始位置开始,不包括结束位置,但如果你不定义结束位置,则取值从开始到字符串结束。
- charAt——获取某个字符串
var str='abcdef'
alert(str.charAt(0));
弹出结果为:a
- split——分割字符串,获得数组
var str='abc-12-u-uw'
alert(str.split('-'));
得到abc,12,u,uw四个元素的数组。
以上四个方法数用的最多的操作。
二. 关于正则
你可以不用正则做任何事情,但是——
【例1】有一个字符串var str='12,87 76 -ddf ddf 89',要求把所有数字挑出来。
不用正则的情况下:
var str='12,87 76 -ddf ddf 89'
var tmp='';
var arr=[];
var i=0;
for(i=0;i<str.length;i++){
if(str.charAt(i)>='0'&&str.charAt(i)<='9'){
tmp+=str.charAt(i);
}else{
if(tmp){
arr.push(tmp);
tmp='';
}
}
}
if(tmp){
arr.push(tmp);
tmp='';
}//最后一个数加进去
alert(arr);
整个过程相当麻烦。
如果用正则——
var str='12,87 76 -ddf ddf 89';
var re=/\d+/g;
alert(str.match(re));
结果是一样的。
这——就是为什么用正则——大大简化了代码。
到底什么叫正则表达式
台译法为“规则表达式”。常见的各种字符串都有邮箱,网址,手机号,身份证号,qq号等。像邮箱——一串字母数字下划线@英文(数字),一串英文,.号,又一串英文。
强大的字符串匹配工具。
正则能做什么
只能操作字符串。——正常人难以读懂。
【例2】
var str='abcdef';
var re=new RegExp('a');//检测字符串是否有a——定义规则。
alert(re.test(str));//检测字符串是否符合规则,返回true
正则表达式是大小写敏感的。如果要忽略大小写,应该在规则写上:
var re=new RegExp('a','i');也就是用i来忽略大小写——属于javascript风格。
同理,上面的正则的简写为
var re=/a/i;
一般都是采用下面的写法——Perl风格。所谓perl程序是正则的最早提出者。
现在关注一下,字符串和正则是如何配合的。
var str='abcdef';
alert(str.search(/b/));
和str.search('a')的过程是完全一样的。
【例2.1】再看一个例子:
var str='asdf3 4323 fas23';
var re=/\d/;//杠d表示就是数字
alert(str.search(re));//查找首个数字出现的位置
返回结果为4所谓\d表示数字。(digtal)
【例3】检测浏览器版本
检测浏览器常用userAgent方法——
alert(window.navigator.userAgent);
弹出的是当前使用浏览器的类型和版本。通常是一大串字符串,比如:
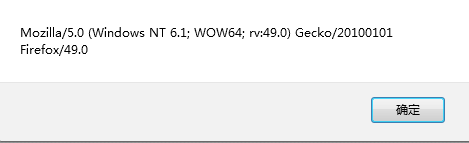
现在可以通过正则来把关键字符取出来——然后判断。
if(window.navigator.userAgent.search(/firefox/i)!=-1){
alert('这是火狐');
}else if(window.navigator.userAgent.search(/chrome/i)!=-1){
alert('这是chrome');
}else if(window.navigator.userAgent.search(/msie 9/i)!=-1){
alert('这是IE9');
}
并且,你可以封装为一个函数到处去用。
三. march方法——匹配
【例4】匹配符合正则的东西,返回一个数组。
在例2.1的例子中,稍作修改
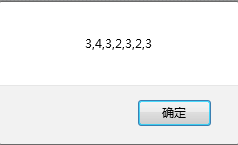
var str='asdf3 4323 fas23';
var re=/\d/g;//杠d表示就是数字
alert(str.match(re));
输出结果为:
如果不加g(global)返回一个3
如果我需要一个两个连着的字符串——
var re=/\d\d/g;就返回的是彼此连着的字符串组。但是,不连着的就被过滤掉了。

+号表示量词——衡量东西的数量,“许多”的意思。
var re=/\d+/g;表示多个数字
修改之后:
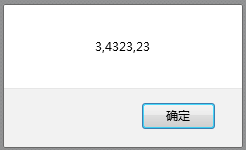
所有的数字都出来了。
四. replace——用来替换
【例5】
replace本身是一个字符串的操作:
var str='abcdef';
alert(str.replace('a','A'));
在上面的demo中str内的第一个小写a被替换为大写的'A'.正是因为第一个,成为了此方法的最大缺陷。
这个问题很好解决,结合正则应用就可以了:
var str='abacAdef';
alert(str.replace(/a/g,'T'));
输出TbTcAdef。还是不完善——如果想把A也改为T——只需要把正则写成:alert(str.replace(/a/gi,'T'));,就完美解决了问题。
【例5.1】应用——敏感词过滤
<textarea id="txt1" row="10" cols="40"></textarea><br>
<input id="btn1" type="button" value="过滤"><br>
<textarea id="txt2" row="10" cols="40"></textarea>
现在要求在txt1上输入,点击过滤之后,输入文本的三国杀敏感词变为**。
window.onload=function(){
var oTxt1=document.getElementById('txt1');
var oTxt2=document.getElementById('txt2');
var oBtn=document.getElementById('btn1');
oBtn.onclick=function(){
var re=/忠臣|反贼|内奸/g;
oTxt2.value=oTxt1.value.replace(re,'**');
}
}

竖线|的作用:就是或者的意思。
五. 字符类
【例6】
字符类就是方括号
var re=/1[abc]2/;
表示出现在1,2之间出现的任何a,b,c。等效于/1a2|1b2|1c2/
例5.1中,如果把正则写为:var re=/f[uc]k/g;在文本框输入测试文字fuck,效果为:***k
结论——但凡出现在方括号内的都表示或者。
另外一个用法
[0-9]表示所有数字
[a-z]表示所有小写字母
[0-9a-z]表示数字+小写字母
[^a]表示取反,除了a以外什么都可以。只要不是a
结合应用
[^0-9a-z]就表示特殊字符
【例6.1】偷小说——应用
采集器的原理:采集过来的实际上是一堆html代码。代码不能直接塞到网站中。因此需要过滤里面的标签。
比如“霸道总裁”系列:
<h1 >霸道总裁爱上我</h1>
<a href="[javascript:;](javascript:;)" class="edit-lemma cmn-btn-hover-blue cmn-btn-28 j-edit-link"><em class="cmn-icon wiki-lemma-icons wiki-lemma-icons_edit-lemma"></em>编辑</a>
<a class="lock-lemma" target="_blank" href="[/view/10812319.htm](http://baike.baidu.com/view/10812319.htm)" title="锁定"><em class="cmn-icon wiki-lemma-icons wiki-lemma-icons_lock-lemma"></em>锁定</a>
</dd>
</dl><div class="promotion-declaration">
</div><div class="lemma-summary" label-module="lemmaSummary">
<div class="para" label-module="para">几年前,他无助时,她救了他,他那时候觉得她只是对她有一点好感,却不知道,自己已经已经陷入爱情的深渊,他爱上了她,几年后,她在闺蜜榕衫介绍的工作下,无意中当上了他的女仆,他发现了,她就是几年前的她…… (本故事及人物纯属虚构,如有雷同,纯属巧合,切勿模仿。)</div>
需要把html标签过滤掉。
转换器设置和例5.1的html一样,写入如下代码
window.onload=function(){
var oTxt1=document.getElementById('txt1');
var oTxt2=document.getElementById('txt2');
var oBtn=document.getElementById('btn1');
oBtn.onclick=function(){
var re=/<.+>/g;
oTxt2.value=oTxt1.value.replace(re,'');
}
}
var re=/<.+>/g;中,.表示匹配尖括号内所有的内容。按理来说所有的都应该被匹配了。然而——转换结果一片空白。
正则的特点在于——贪婪。在解析过程中只认尽可能长的代码段,因此把中间的尖括号全部都算入替代中了。必须重新考虑规则。
实际上在html标签内唯独不可能出现左右尖括号本身。一次正则改为:var re=/<[^<>]+>/g,就没问题了。

\w——word包括数字英文字母和下划线\s——space包括空格。
比如:去除所有字符内的空格:
var str='das aasvg dvf d d2 2';
alert(str.replace(/\s+/g,''));
大写字母:——也是是取反,不过是比较高级的取反。
\D代表[^0-9]\W代表[^a-z0-9]\S代表除了空格字符以外的所有东西
六. 量词
什么是量词:一个东西出现的次数。现在进一步深入了解下。
基本用法:{n,m}——至少出现n次,最多m次。
常用量词
{n,}至少n次,最多不限制。
{,m}做多m次,最少不限
{n}恰好n次。
【例6.2】案例:查找QQ号。
qq号的位数——5-11,第一位不能是0.
var str='我的qq号是:123456789;你的是:123456;他的是1234567吗?';
var re=/[1-9]\d{4,10}/g;
//表示:必须1-9开头,后面为数字且最少出现4次,最多出现10次
alert(str.match(re));
输出的是三个qq号的数组。
*任意次数{0,}——可以出现也可以不出现,不建议使用,用+号就好。?0次或1次{0,1}——可以出现也可以不出现。出现的话只能出现1次。+1次或任意次——实际意思是只要出现就被全部逮着。
七. 实例分析:常用正则表达式的应用
【例7】邮箱校验
邮箱规则是:
第一部分用户名(字母,数字,下划线)——\w+
第二部分为@
第三部分是既能是域名可以是英文数字——但不能是下划线——[a-z,0-9]+
第四部分是.,但.本身是有特殊含义的,表示任意字符。所以必须转义——用\.来替代。
第四部分为一串英文,长度-4位
按部就班来写:
var str='asads@asda.xxx';
var re=/\w+@[a-z0-9]+\.[a-z]{2,4}/g;
alert(re.test(str));
如果返回的结果为false,表示str不符合email的正则表达式。但是这样写有两个问题:
(1)当用户名有中文时,校验居然可以通过
(2)当域名多于4位时,校验还是能够通过。
首先,正则含义表示当前字符串部分符合,验证就被通过了。
因此,需要引入行首和行尾的概念。
之前说过,方括号内的^表示取反,但是在方括号之外,就是行首的意思。另一方面$表示行尾。因此把正则写成:
var re=/^\w+@[a-z0-9]+\.[a-z]{2,4}$/
就算完成了。
校验必须加行首行尾。
【例7.1】去除首尾空格
用户在输入字符串时总是不小心输入到前面有空格。可以通过首尾来验证这段错误的字符串。
var str=' sssd asd ds ';
var re=/^\s+/;//把左边的空格(任意个)选中了。
alert('('+str.replace(re,'')+')');
如果我想行首行尾一块用呢?
注意$的写法——写在右边,:
var re=/^\s+|\s$/g;
两边的空格被去掉了。中段的空格被保留。
【例8】中文校验——[\u4e00-\u9fa5]
在婚恋类网站中,经常要求用户名必须是中文。
怎么理解[\u4e00-\u9fa5]:网页都是UTF-8编码的。\u代表汉字。这里是一个范围,表示从utf-8编码的第一个汉字到最后一个utf-8编码的汉字。可以在在线utf-8编码转换器上测试,\u加上转出来的最后四位就是这个汉字的正则表达式。
var str='sad葡萄asd';
var re=/[\u4e00-\u9fa5]/;
alert(re.test(str));
返回为true。
【例9】原生javascript的class选择器——getByClass
原版的getByClass思想是:传入一个父级的参数,然后遍历所有父级内的元素,当className值为目标的class名时,push到数组中。
function getByClass(oParent,sClass){
var aEle=oParent.getElementsByTagName('*');//选择父元素的所有标签
var aResult=[];
var i=0;
for(i=0;i<aEle.length;i++){
if(aEle[i].className==sClass){
aResult.push(aEle[i]);
}
}
return aResult;
}
有什么局限性呢?有时候布局时,存在两个class同时存在于一个标签时,这个class就不能被被选中。必须使用字符串方法,判断这个标签的className包不包含class。
思路
(1)一个不靠谱的办法是用search方法:
function getByClass(oParent,sClass){
var aEle=oParent.getElementsByTagName('*');//选择父元素的所有标签
var aResult=[];
var i=0;
for(i=0;i<aEle.length;i++){
if(aEle[i].className.search(sClass)!=-1){
aResult.push(aEle[i]);
}
}
return aResult;
}
(2)另一个不靠谱的办法如下
然而,只是看到了包含的一面,却没有考虑诸如从<a class="btn default">搜寻.btn这样的情形。严格的方法需要用到单词边界(\b)来实现。
什么是单词边界呢?单词之间是由空格,标点等区分开的。这个元素称为单词边界。
var re=new RegExp('\\b'+sClass+'\\b');
表示sClass是一个单独的单词。为什么是'\\b'呢,因为还有一个是转义的\。
所以完美版的class选择器是:
function getByClass(oParent,sClass){
var aEle=oParent.getElementsByTagName('*');//选择父元素的所有标签
var aResult=[];
var re=new RegExp('\\b'+sClass+'\\b','i');
var i=0;
for(i=0;i<aEle.length;i++){
if(re.test(aEle[i].className)){
aResult.push(aEle[i]);
}
}
return aResult;
}
结果还是有问题:先在获取到的className值两边加上空格,这样就保证了className里的每个值两边都会有空格,然后再用正则去匹配。
function getByClass(oParent, sClass){
if(oParent.getElementsByClassName){
return oParent.getElementsByClassName(sClass);
}else{
var res=[];
var re=new RegExp(' '+sClass+' ','i')
var aEle=oParent.getElementsByTagName('*');
for(var i=0; i<aEle.length; i++){
if(re.test(' '+aEle[i].className+' ')){
res.push(aEle[i]);
}
}
return res;
}
}
总结:
- 字符串的基本操作:重点的4个——search(查找首个字符串出现的位置),substring(获取子字符串),charAt(定位获取字符串的一部分),split(按照一定的规则切割字符串)
- 正则表达式是把字符串规则告诉计算机的表达形式。创建正则对象有两种方法:javascript风格和perl风格。
正则的选项:一个是i——忽略大小写,g——是搜索全部 - search依旧是查找,match是挑选匹配,replace是替换符合规则的字符串
- 字符类:[abc]——任意字符;范围[a-z],[0-9];在方括号内有
^表示取反排除。 - 转义字符——
.代表所有的字符,\d表示左右数字,\s表示空格。当使用大写的时候,表示取反。 - 量词——出现的次数,最普通是
{n,m}最少n最多m次。 - 正则的例子——邮箱中文,qq号等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号