
第三十章:Set集合
Set接口简介
Set集合最大的特点就是不允许保存重复元素,其也是Collection子接口。
在JDK1.9以前Set集合与Collection集合的定义并无差别,Set继续使用了Collection接口中提供的方法进行操作,但是从JDK1.9后,Set集合也想List集合一样扩充了一些static方法,Set集合的定义如下: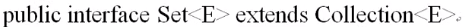
需要注意的是Set集合并不像List集合那样扩充了许多的新方法,所以无法使用List集合中提供的get()方法,也就是说,它无法实现指定索引数据的获取,Set继承关系如下: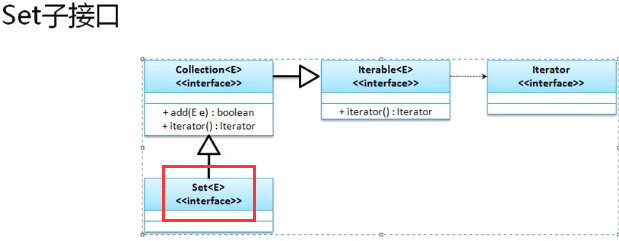
从JDK1.9之后,Set集合也提供了像List集合之中类似的of()的静态方法。但是用of()方法向Set集合保存重复元素时会发现抛出异常,因为它不能保存重复元素。
Set集合的常规实用性是一定是依靠子类进行实例化的,所以Set接口之中有两个子类:HashSet、TreeSet.
HashSet子类
HashSet是Set接口里面使用最多的一个子类,其最大的特点就是保存的数据是无序的,而HashSet类的继承关系如下: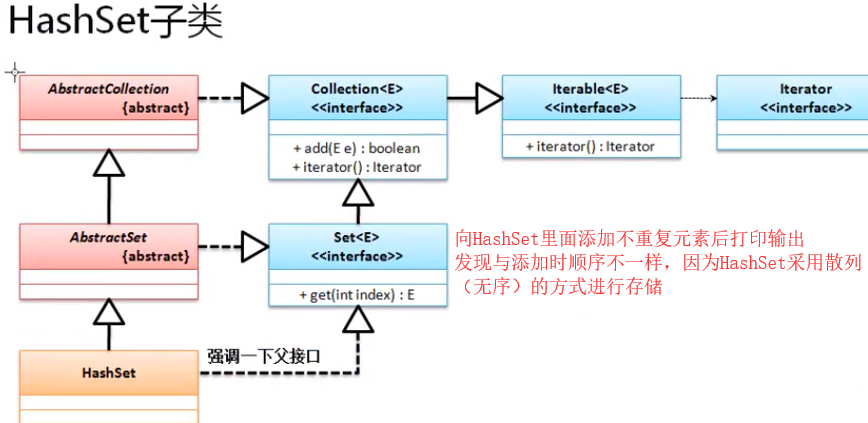
Hash子类的操作特点:
不允许保存重复元素(Set接口定义的,虽然add()时不会保存,但是添加不进去)
HashSet中保存的数据是无序的(Hash这种算法就是计算哪地有位置就往哪保存)
TreeSet子类
Set接口的另外一个子类就是TreeSet,与HashSet最大的区别在于TreeSet里面所保存的数据是有序的,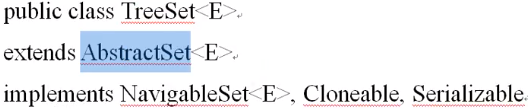
在这个子类里面依然继承了AbstractSet父抽象类,同时又实现了一个NavigableSet父接口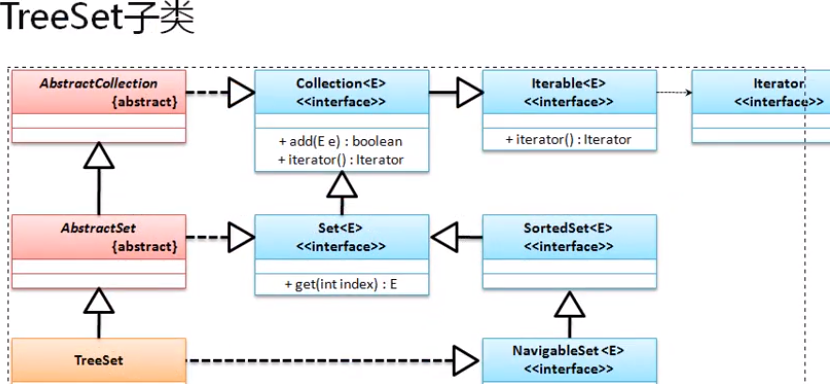
当利用TreeSet保存数据的时候所有的数据都将按照数据的升序进行自动的排序处理(字符串按字母大小)
分析TreeSet子类排序操作
经过分析之后TreeSet子类之中保存的数据是允许排序的,那么下面就使用自定义的类进行排序操作(这个类必须实现Comparable接口,重新CompareTo方法,定义出排序的规则,只有这样才能确认大小关系。)
TreeSet本质是利用TreeMap子类实现的集合数据的存储,TreeSet是利用Compareable接口确认重复数据的,由于TreeSet在操作过程中需要将类中的所有属性进行比对,这样的实现难度太高了,那么在实际的开发之中应该首选HashSet子类进行存储。
(个人总结:如果要把一个自定义类的对象保存在TreeSet里面一定要让它实现Comparable接口)
分析重复元素消除
TreeSet子类是利用了Comparable接口来实现了重复元素的判断,但是Set集合的整体特征是不允许保存重复元素。但是HashSet判断重复元素的方式并不是利用Comparable接口完成的,它利用的是Object类中提供的方法实现的: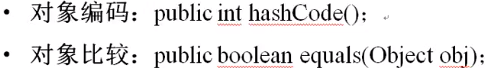
在进行重复元素判断的时候首先利用hashCode()进行编码匹配,如果该编码不存在则表示数据不存在,表示数据没有重复,如果该编码存在了,则进一步进行对象比较处理,如果发现重复了,则次数据是不允许包存的。如果使用的是Eclipse开发工具,则可以帮助开发者创建hashCode()与equals()方法,
在java程序之中真正的重复元素的判断处理利用的就是hashCode()与equals()两个方法共同作用完成的,而只有在排序的要求情况下(TreeSet)才会使用Comparable接口来实现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号