
数据聚合与分组操作-数据透视表
数据聚合与分组操作-数据透视表
import numpy as np
import pandas as pd
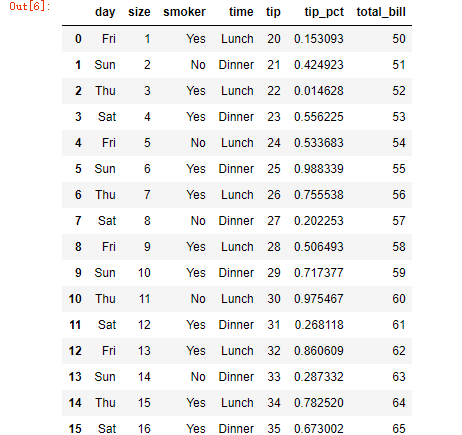
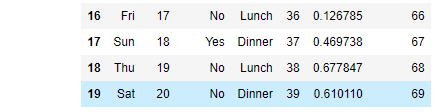
tips = pd.DataFrame({'total_bill':np.arange(50,70),
'tip':np.arange(20,40),
'smoker':['Yes','No','Yes']*6+['No','No'],
'day':['Fri','Sun','Thu','Sat']*5,
'time':['Lunch','Dinner']*10,
'size':np.arange(1,21),
'tip_pct':np.random.rand(20)})
tips
tips.pivot_table(index=['day','smoker']) # 默认取平均值
| size | tip | tip_pct | total_bill | ||
|---|---|---|---|---|---|
| day | smoker | ||||
| Fri | No | 11.000000 | 30.000000 | 0.330234 | 60.000000 |
| Yes | 7.666667 | 26.666667 | 0.506731 | 56.666667 | |
| Sat | No | 14.000000 | 33.000000 | 0.406182 | 63.000000 |
| Yes | 10.666667 | 29.666667 | 0.499115 | 59.666667 | |
| Sun | No | 8.000000 | 27.000000 | 0.356128 | 57.000000 |
| Yes | 11.333333 | 30.333333 | 0.725151 | 60.333333 | |
| Thu | No | 15.000000 | 34.000000 | 0.826657 | 64.000000 |
| Yes | 8.333333 | 27.333333 | 0.517562 | 57.333333 |
tips.groupby(['day','smoker']).mean() # 与上句同效果
| size | tip | tip_pct | total_bill | ||
|---|---|---|---|---|---|
| day | smoker | ||||
| Fri | No | 11.000000 | 30.000000 | 0.330234 | 60.000000 |
| Yes | 7.666667 | 26.666667 | 0.506731 | 56.666667 | |
| Sat | No | 14.000000 | 33.000000 | 0.406182 | 63.000000 |
| Yes | 10.666667 | 29.666667 | 0.499115 | 59.666667 | |
| Sun | No | 8.000000 | 27.000000 | 0.356128 | 57.000000 |
| Yes | 11.333333 | 30.333333 | 0.725151 | 60.333333 | |
| Thu | No | 15.000000 | 34.000000 | 0.826657 | 64.000000 |
| Yes | 8.333333 | 27.333333 | 0.517562 | 57.333333 |
tips.pivot_table('tip_pct',index=['time','smoker'],columns='day',
aggfunc=len,margins=True)
| day | Fri | Sat | Sun | Thu | All | |
|---|---|---|---|---|---|---|
| time | smoker | |||||
| Dinner | No | NaN | 2.0 | 2.0 | NaN | 4.0 |
| Yes | NaN | 3.0 | 3.0 | NaN | 6.0 | |
| Lunch | No | 2.0 | NaN | NaN | 2.0 | 4.0 |
| Yes | 3.0 | NaN | NaN | 3.0 | 6.0 | |
| All | 5.0 | 5.0 | 5.0 | 5.0 | 20.0 |
tips.pivot_table('tip_pct',index=['time','smoker'],columns='day',
aggfunc='count',margins=True) # 集成函数写成'count',与上句同效果
| day | Fri | Sat | Sun | Thu | All | |
|---|---|---|---|---|---|---|
| time | smoker | |||||
| Dinner | No | NaN | 2.0 | 2.0 | NaN | 4.0 |
| Yes | NaN | 3.0 | 3.0 | NaN | 6.0 | |
| Lunch | No | 2.0 | NaN | NaN | 2.0 | 4.0 |
| Yes | 3.0 | NaN | NaN | 3.0 | 6.0 | |
| All | 5.0 | 5.0 | 5.0 | 5.0 | 20.0 |
