字符编码
1文本编辑器存储文件的原理
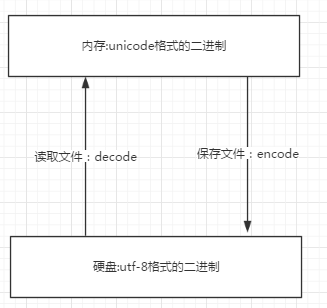
打开编辑器就打开启动了一个进程,是在内存中的 所以在编辑器编写的内容也都是存放在内存中的,断电后数据丢失
因而需要保存在硬盘上,点击保存按钮,就从内存中把数据写到硬盘上。
在这一点上,我们编写一个Py文件(没有执行),跟编写其他文件没有区别,都是编写一堆字符而已。
python解释器执行py文件的原理
第一阶段:python解释器相当于文本编辑器
第二阶段:python解释器去打开py文件,从硬盘上将文件内容读取到内存中(py的解释性决定了解释器只关心文件内用,不关心文件后缀名)
第三阶段:python 解释器解释执行刚刚加载到内存的代码(在该阶段,及执行时,才会识别python的语法,执行代码文件,执行 比如 name=‘egon’)会开辟到内存空间存放字符串‘egon’
总结 py解释器与文本编辑器的异同
相同点:py解释器是解释执行文件的内容,因而python解释器具备读py文件的功能,这一点与文本编辑器一样
不同点:文本编辑器将文件内容读入内存后,是为了显示/编辑,而python解释器将文件内容读入内存后,是为了显示编辑,而python解释器将文件读入内存后,是为了执行(识别语法)
2什么是字符编码
计算机要想工作必须通电,也就是说电驱动计算机干活,而电的特性,就是高低电频(也就是是高电频二进制数1 ,低电频即二进制数0)
如何能让计算机读懂
必须有过程
字符----------(翻译过程)-----数字
这个过程实际就是一个字符如何对应一个特定数字的标准 这个标准称为字符编码
一下两个场景涉及到字符编码的问题
1一个python文件中的内容是有一堆字符组成的(未执行时候)
2python中的数据类型字符串由一串字符组成的(python文件执行时)
强调
unicode:简单粗暴,所有字符都是2Bytes,优点是字符->数字的转换速度快,缺点是占用空间大
utf-8:精准,对不同的字符用不同的长度表示,优点是节省空间,缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号