
More Effective C++学习笔记
1.指针和引用的区别
- 指针和引用都是间接的指向其他对象
- 指针指向可以为空,可以不初始化(危险的做法);使用指针之前必须检查它的合法性即判断其是否为空。
- 引用不能指向空值,引用必须初始化指向一个对象,且终生绑定。所以当变量必须指向一个对象且不允许为空时,你应该使用引用。不存在指向空值的引用这个事实意味着使用引用的代码效率比使用指针的要高。因为在 使用引用之前不需要测试它的合法性。
- 指针可以被重新赋值以指向另一个不同的对象,但是引用则总是指向在初始化时被指定的对象,以后不能改变即终生绑定。
- 以下情况下你应该使用指针,一是你考虑到存在不指向任何对象的可能(在这种情况下,你能够设置指针为空),二是你需要能够在不同的时刻指向不同的对象(在这种情况下,你能改变指针的指向)。如果总是指向一个对象并且一旦指向一个对象后就不会改变指向,那么你应该使用引用。还有一种情况,就是当你重载某个操作符时,你应该使用引用。最普通的例子是操作符 []。这个操作符典型的用法是返回一个目标对象,其能被赋值。
- 当你知道你必须指向一个对象并且不想改变其指向时,或者在重载操作符并为防止不必 要的语义误解时,你不应该使用指针。而在除此之外的其他情况下,则应使用指针。
2.使用C++风格的类型转换
- 传统C风格类型转换,是无条件强制类型转换:(type)expression。
- static_cast:可用于普通内置类型之间的转换、基础体系向上转型(派生类--->基类)
- const_cast:一般只用于去除const属性和volatile属性
- dynamic_cast:用于继承体系中的向下(基类--->派生类对象)安全转型,转换失败则结果为空,一般只用于多态即含有虚函数的类。
- reinterpret_cast:使用这个操作符的类型转换, 其转 换结果几乎都是执行期定 义( implementation-defined ), 因 此使用reinterpret_casts的代码很难移植。reinterpret_casts 的最普通的用途就是在函数指针类型之间进行转换。类似C风格的强制转换,可以任意解释,但是转换结果不一定合法。
3.不要对数组使用多态
- 因为在遍历数组时步进的大小,编译器是根据静态类型来确定的,当基类和派生类大小不一样时,得不到正确的结果。
- 如果一定要使用数组来多态调用,则可以使用指针数组,即数组里面每一个元素都是指向派生类实例的指针。
class Base { public: Base(int i = 0):id(i) { std::cout << "Base Ctor " << id << std::endl; } ~Base() { std::cout << "Base Dtor " << id << std::endl; } virtual void Print() { std::cout << "Base Print " << id << std::endl; } private: int id = 0; }; class Sub : public Base { public: Sub(int sub, int i = 0) : Base(i), subid(sub) { std::cout << "Sub Ctor, Sub Id= " << subid << std::endl; } ~Sub(){ std::cout << "Sub Dtor, Sub Id= " << subid << std::endl; } virtual void Print() { std::cout << "Sub Print " << subid << std::endl; } private: int subid = 0; }; void Test(Base p[], int length) { assert(p != nullptr); for (int i = 0; i < length; ++i) { p[i].Print(); // 地址递增步长使用的是静态类型,sizeof(Base) } } int main(int argc, char* argv[]) { Base bArr[5] = { Base(1), Base(2) ,Base(3) ,Base(4) ,Base(5) }; Sub sArr[5]{ Sub(11),Sub(22) ,Sub(33) ,Sub(44) ,Sub(55) }; std::cout << "-------------------------------------------" << std::endl; Test(bArr, 5); std::cout << "-------------------------------------------" << std::endl; Test(sArr, 5); // Error system("pause"); return 0; }
4.避免无意义的缺省构造函数
- 一个类的构造函数必须确保所有的部分都被正确初始化
- 提供无意义的缺省构造函数也会影响类的工作效率,因为它可能并没有把所有成员(或者说必须的成员)都正确初始化。
5.谨慎定义类型转换函数
- C++编译器能够在两种数据类型之间进行隐式转换(implicit conversions),有两种函数允许编译器进行这些的转换:单参数构造函数( single-argument constructors)和隐式类型转换运算符。单参数构造函数是指只用一个参数即可以调用的构 造函数。该函数可以是只定义了一个参数,也可以是虽定义了多个参数但第一个参数以后的 所有参数都有缺省值。
- 隐式类型转换运算符只是一个样子奇怪的成员函数:operator 关键字,其后跟一个类型符号。你不用定义函数的返回类型,因为返回类型就是这个函数的名字。如:operator double() const;
- 编译器有时会自动进行隐式转换,但是这种转换很可能并不是你需要的,所以你必须谨慎定义类型转换函数。对于非必要的转换函数,你可以采用公有方法来实现,如用 double ToDouble() const;来取代operator double() const;,这样既可以避免某些时候不必要的类型转换,又可以在用户需要时显示调用公有接口来实现。
- 一般来说,越有经验的 C++程序员就越喜欢避开类型转换运算 符。例如在 C++标准库委员会工作的人员是在此领域最有经验的,他们加在库函数中的 string 类型没有包括隐式地从 string 转换成 C 风格的 char*的功能,而是定义了一个成员函数 c_str 用来完成这个转换。通过不声明运算符(operator)的方法,可以克服隐式类型转换运算符的缺点。
- 通过单参数构造函数进行隐式类型转换更难消除。而且在很多情况下这些函数所导致的问题要甚于隐式类型转换运算符。消除方法有2个:一是构造函数用 explicit 声明,这样做编译器会拒绝为了隐式类型转换,且显式类型转换依然合法;二、使用代理类型,不要直接使用一些内置类型,如用枚举类型代替int做构造函数的参数
6.自增(increment)、自减(decrement)操作符前缀与后缀形式的区别
- C++ 规定重载运算符的后缀形式有一个int 类型参数,当函数被调用时,编译器会传递一个 0 做为 int 参数的值给该函数。后缀操作符函数并没有使用它的参数,它的参数只是用来区分前缀与后缀函数调用。
- 前缀与后缀形式返回值类型是不同的。前缀形式返回一个引用,后缀形式返回一个const类型对象
- 记住 increment 的前缀形式有时叫做“增加然后取回”,后缀形式叫做“取回然后增加”
-
class UPInt { public: // ++前缀 UPInt& operator++() { *this += 1; return *this; } // ++后缀 const UPInt operator++(int) { /* 关于后缀形式的返回值: 一个后缀++必须返回一个对象(它返回的是增加前的值),但是为什么是const对象呢?假设不是const对象,下面的代码就是正确的: UPInt i; i++++; // 两次++后缀 这组代码与下面的代码相同: i.operator++(0).operator++(0); 很明显,第一个调用的 operator++函数返回的对象调用了第二个 operator++函数.有两个理由不支持这种做法: 第一是与内置类型行为不一致。当设计一个类遇到问题时,一个好的准则是使该类的行为与内置类型一致。如int类型不允许连续进行两次后缀++: int i; i++++; // 错误! 第二个原因是使用两次后缀++所产生的结果与调用者期望的不一致。如上所示,第二次调用operator++改变的值是第一次调用返回对象的值,而不是原始对象的值。 因此如果:i++++;是合法的,i将仅仅增加一次。 C++禁止 int 类型这么做,同时你也必须禁止你自己写的类有这样的行为。最容易的方法是让后缀increment返回 const 对象。当编译器遇到这样的代码: i++++; // same as: i.operator++(0).operator++(0); 它发现从第一个 operator++函数返回的 const 对象又调用 operator++函数,然而这个函数是一个 non-const 成员函数,所以 const 对象不能调用这个函数,从而阻止了第二次的调用。 效率问题: 后缀形式必须建立一个临时对象以做为它的返回值,这个临时对象必须被构造并在最后被析构。前缀函数没有这样的临时对象。 由此得出一个结论,如果仅为了提高代码效率,UPInt 的调用者应该尽量使用前缀,少用后缀,除非确实需要使用后缀。当处理用户定义的类型时,尽可能地使用前缀,因为它的效率较高。 */ UPInt oldValue = *this; ++(*this); return oldValue; } // --前缀 UPInt& operator--() { *this -= 1; return *this; } // --后缀 const UPInt operator--(int) { UPInt oldValue = *this; --(*this); return oldValue; } UPInt& operator+=(int rhs) { this->m_int += rhs; return *this; } UPInt& operator-=(int rhs) { this->m_int -= rhs; return *this; } private: long long m_int = 0; };
7.不要重载“&&”,“||”, 或“,”
- 与 C 一样,C++使用布尔表达式短路求值法(short-circuit evaluation)。这表示一旦确定了布尔表达式的真假值,即使还有部分表达式没有被测试,布尔表达式也停止运算。如:
-
char *p; ... if ((p != NULL) && (strlen(p) > 10)) ... //这里不用担心当 p 为空时 strlen 无法正确运行,因为如果 p 不等于 0 的测试失败,strlen不会被调用。
- 逗号表达式首先计算逗号左边的表达式,然后计算逗 号右边的表达式;整个表达式的结果是逗号右边表达式的值。
- &&、||需遵循短路求值原则,且从左到右计算。逗号表达式需遵循从左到右的计算顺序。通过重载运算符函数调用的方式无法实现其特性
-
// &&、||需遵循短路求值原则,且从左到右计算 #if 0 char *p; ... if ((p != 0) && (strlen(p) > 10)) ... //这里不用担心当 p 为空时 strlen 无法正确运行,因为如果 p 不等于 0 的测试失败,strlen不会被调用。 C++允许重载函数 operator&& 和 operator||,你能在全局重载或每个类里重载。但是你必须知道使用这种方法: 是以函数调用法替代了短路求值法。也就是说如果你重载了操作符&&,对于你来说代码是这样的: if (expression1 && expression2) ... 对于编译器来说,等同于下面代码之一: if (expression1.operator&&(expression2)) ... // when operator&& is a member function if (operator&&(expression1, expression2)) ...// when operator&& is a global function 但是函数调用法与短路求值法是绝对不同的: 1.首先当函数被调用时,需要 运算其所有参数,注意是所有参数或表达式都要运算!!! 所以调用函数 functions operator&& 和 operator||时,操作符左右两个参数都需要计算,即没有采用短路计算法!!! 2.C++语言规范没有定义函数参数的计算顺序!!! 所以没有办法确定表达式 1 与表达式 2 哪一个先计算。完全有可能是与正常的具有从左参数到右参数计算顺序的短路计算法相反! 因此如果你重载&&或 || ,就没有办法得到期望和使用的行为特性(即和语言内置的行为不一样),所以不要重载&&和 || !!! #endif // 逗号表达式需遵循从左到右的计算顺序 #if 0 如果你写一个成员/非成员运算符函数 operator,你不能保证左边的表达式先于右边的表达式计算!!! 因为函数调用时两个表达式做为参数被传递,但是你不能控制函数参数的计算顺序。 #endif // 其他不能重载的操作符 #if 0 . .* :: ?: new delete sizeof typeid static_cast dynamic_cast const_cast reinterpret_cast #endif
8.不同含义的new和delete
- new 操作符:语言内置,它要完成的功能分成两部分:第一部分是分配足够的内存以便容纳所需类型的对象;第二部分是它调用构造函数初始化内存中的对象。new 操作符总是做这两件事情,你不能以任何方式改变它的行为,因此也不能重载 new 操作符。
- new 操作符调用一个函数来完成内存分配,可以重写或重载这个函数来改变它的行为。new 操作符分配内存所调用函数的名就是 operator new
- 跟 malloc 一样,operator new 的职责只是分配内存。它对构造函数一无所知。
- 每个动态内存分配必须与一个等同相反的 deallocation 对应。函 数 operator delete 与 delete 操作符的关系与 operator new 与 new 操作符的关系一样。
- 如果你用 placement new 在内存中建立对象,你应该避免在该内存中用 delete 操作符。
- 数组的分配与释放:opeator new[]和operator delete[]
-
#if 0 1. new 操作符(new operator)和 new 操作(operator new)的区别 (1)new 操作符 当你写这样的代码: string *ps = new string("Memory Management"); 你使用的 new 是 new 操作符。这个操作符就象 sizeof 一样是语言内置的,你不能改变它的含义,它的功能总是一样的。 它要完成的功能分成两部分:第一部分是分配足够的内存以便容纳所需类型的对象;第二部分是它调用构造函数初始化内存中的对象。 new 操作符总是做这两件事情,你不能以任何方式改变它的行为,因此也不能重载 new 操作符 (2)operator new 函数 new 操作符调用一个函数来完成内存分配,你能够重写或重载这个函数来改变它的行为。new 操作符分配内存所调用函数的名就是 operator new 函数 operator new 通常这样声明: void * operator new(size_t size); 返回值类型是 void*,因为这个函数返回一个未经处理(raw)的指针,未初始化的内存。就象 malloc 一样,operator new 的职责只是分配内存。它对构造函数一无所知。 (你可以重载 operator new 函数,在返回一个指针之前能够初始化内存以存储一些数值,但是一般不这么做) 参数 size_t 确定分配多少内存。你能增加额外的参数重载函数 operator new,但是第一个参数类型必须是 size_t。 (3) new 操作符对象初始化过程 把 operator new 返回的未经处理的指针传递给一个对象是 new 操作符的工作。当你的编译器遇见这样的语句: string *ps = new string("Memory Management"); 它生成的代码与下面的代码相似: void *memory = operator new(sizeof(string)); // 得到未经处理的原始内存 call string::string("Memory Management") on *memory; // 调用构造函数初始化内存 string *ps = static_cast<string*>(memory); // 新的对象 注意第二步包含了构造函数的调用,程序员被禁止这样去做,编译器则没有这个约束,它可以做它想做的一切。因此如果你想建立一个堆对象就必须用 new 操作符, 不能直接调用构造函数来初始化对象。 (4)两者关系 堆上建立一个对象应该用 new 操作符。它既分配内存又为对象调用构造函数。 仅仅想分配内存,就应该调用 operator new 函数;它不会调用构造函数。 想定制自己的在堆对象被建立时的内存分配过程,你应该写你自己的 operator new 函数,然后使用 new 操作符,new 操作符会调用你定制的 operator new。 如果你想在一块已经获得指针的内存里建立一个对象,应该用 placement new。 2.placement new 如果想直接调用构造函数(在一个已存在的对象上调用构造函数是没有意义的,因为构造函数用来初始化对象,且一个对象仅仅能在给它初值时被初始化一次) 处理一些已经分配的raw内存,用这些内存构造一个对象。你可以使用一个特殊的 operator new ,即 placement new void *buffer = malloc(sizeof(Widget)); // class Widget; ctor: Widget(int n); // placement new Widget* w = new(buffer)Widget(1001); 此时 new 操作符分配内存调用的这个 operator new 就是 placement new,它看上去象这样: void * operator new(size_t, void *location) { return location; } 这可能比你期望的要简单,但是这就是 placement new 需要做的事情.operator new的目的是为对象分配内存然后返回指向该内存的指针。 在使用 placement new 的情况下,调用者已经获得了指向raw内存的指针,placement new 必须做的就是返回转递给它的指针。(没有用的(但是强制的)参数 size_t 没有名字,以防止编译器发出警告说它没有被使用) 3.每个动态内存分配必须与一个等同相反的 deallocation 对应。函数 operator delete 与 delete 操作符的关系与 operator new 与 new 操作符的关系一样。 string *ps = new string("Memory Management"); ... delete ps; // 使用 delete 操作符 你的编译器会生成代码来析构对象并释放对象占有的内存。Operator delete 用来释放内存,它被这样声明:void operator delete(void *memoryToBeDeallocated); 因此: delete ps;导致编译器生成类似于这样的代码: ps->~string(); // call the object's dtor operator delete(ps); // deallocate the memory the object occupied 4. operator new[] 建立数组时 new 操作符的行为与单个对象建立有些不同: 第一是内存不再用 operator new 分配,而是数组分配函数operator new[](经常被称为 array new)它与 operator new 一样能被重载。 第二是 new 操作符调用构造函数的数量。对于数组,在数组里的每一个对象的构造函数都必须被调用 operator new[]对于 C++来说是一个比较新的东西,某些编译器可能不支持它。如果它不支持,无论在数组中的对象类型是什么全局 operator new 将被用来给每个数组 分配内存。在这样的编译器下定制数组内存分配是困难的,因为它需要重写全局 operator new 缺省情况下,全局 operator new 处理程序中所有的动态内存分配, 所以它行为的任何改变都将影响全局的动态内存分配。基于这些考虑,在缺乏 operator new[]支持的编译器里为数组定制内存管理(即重写)不是一个合理的设计。 5.operator delete[] 同样当 delete 操作符用于数组时,它为每个数组元素调用析构函数,然后调用 operatordelete[]来释放内存 就象你能替换或重载 operator delete 一样,你也替换或重载 operator delete[]。 #endif
9.使用析构函数防止资源泄漏
- 建立一个类,让它的构造函数与析构函数来获取和释放资源。即 RAII 技术
- 使用智能指针,来取代原始指针。
10.在构造函数中防止资源泄漏
- 构造函数中如果抛出异常,析构函数是不可能被调用的,此时在构造函数中已分配的资源(非局部对象)将无法释放
-
#if 0 // 用于图像数据 class Image { public: Image(const string& imageDataFileName) { // ... } // ... }; // 用于声音数据 class AudioClip { public: AudioClip(const string& audioDataFileName) { // ... } // ... }; // 用于存储电话号码 class PhoneNumber { //... }; // 通讯录中的条目 class BookEntry { public: BookEntry(const string& name, const string& address = "", const string& imageFileName = "", const string& audioClipFileName = "") : theName(name), theAddress(address), theImage(nullptr), theAudioClip(nullptr) { #if 0 // 改造后 try { if (imageFileName != "") { theImage = new Image(imageFileName); } if (audioClipFileName != "") { // 假设创建theAudioClip对象时抛出异常(如可能是内存分配导致) theAudioClip = new AudioClip(audioClipFileName); } } catch (...) { cleanup(); throw; // 继续传递异常 } #endif // 改造后 } ~BookEntry() { //delete theImage; //delete theAudioClip; cleanup(); } // 改造后将资源释放放到一个函数中 void cleanup() { delete theImage; delete theAudioClip; } // 通过这个函数加入电话号码 void addPhoneNumber(const PhoneNumber& number) { //... } private: string theName; // 姓名 string theAddress; // 地址 list<PhoneNumber> thePhones; // 电话号码 Image *theImage; // 来电图像 AudioClip *theAudioClip; // 来电声音 }; 1.C++仅仅能删除被完全构造的对象(fully contructed objects), 只有一个对象的构造函数完全运行完毕,这个对象才被完全地构造!!! 所以如果一个 BookEntry 对象 b 做为局部对象建立,如下: void testBookEntryClass() { BookEntry b("Addison-Wesley Publishing Company", "One Jacob Way, Reading, MA 01867"); // ... } 并且在构造 b 的过程中,一个异常被抛出,那么 b 的析构函数不会被调用。 而且即使你试图采取主动手段处理异常情况,即当异常发生时调用 delete 如下所示: void testBookEntryClass() { BookEntry *pb = nullptr; try { pb = new BookEntry("Addison-Wesley Publishing Company", "One Jacob Way, Reading, MA 01867"); // ... } catch (...) { // 捕获所有异常 delete pb; // 删除 pb,当抛出异常时 throw; // 传递异常给调用者 } delete pb; // 正常删除 pb } 你会发现在 BookEntry 构造函数里为 Image 分配的内存仍旧被丢失了,这是因为如果 new 操作没有成功完成,程序不会对 pb 进行赋值操作 即如果 BookEntry 的构造函数抛出一异常,pb 将是nullptr。此情况采用智能指针也是一样的结果 C++拒绝为没有完成构造操作的对象调用析构函数是有原因的:在很多情况下这么做是没有意义的,甚至是有害的。如果为没有完成构造 操作的对象调用析构函数,析构函数如何去做呢?仅有的办法是在每个对象里加入一些字节来指示构造函数执行了多少步?然后让析构函数检测这些字节并判断该执行哪些操作。 这样的记录会减慢析构函数的运行速度,并使得对象的尺寸变大。C++避免了这种开销,但是代价是不能自动地删除被部分构造的对象。 2.改造构造函数防止资源泄漏 当const指针资源初始化时又该如何?(一种方法:封装各个初始化函数,在函数中处理异常,初始化列表中调用) class BookEntry { public: ... // 其他同上 BookEntry(const string& name, const string& address, const string& imageFileName, const string& audioClipFileName) : theName(name), theAddress(address), theImage(initImage(imageFileName)), theAudioClip(initAudioClip(audioClipFileName)) {} private: ... // 其他同上 Image * const theImage; // 指针现在是const 类型 AudioClip * const theAudioClip; // 初始化列表中成员根据声明顺序初始化,theImage 被首先初始化,所以即使这个初始化失败也 不用担心资源泄漏,这个函数不用进行异常处理。 Image * initImage(const string& imageFileName) { if (imageFileName != "") return new Image(imageFileName); else return 0; } // theAudioClip 被第二个初始化, 所以如果在 theAudioClip 初始化过程中抛出异常,它必须确保 theImage 的资源被释放 AudioClip * initAudioClip(const string& audioClipFileName) { try { if (audioClipFileName != "") { return new AudioClip(audioClipFileName); } else return 0; } catch (...) { delete theImage; throw; } } }; 3.更好的解决方法:使用智能指针 class BookEntry { public: ... // 同上 BookEntry(const string& name, const string& address, const string& imageFileName, const string& audioClipFileName) : theName(name), theAddress(address), theImage(imageFileName != "" ? new Image(imageFileName) : nullptr), theAudioClip((audioClipFileName != "" ? new AudioClip(audioClipFileName) : nullptr)) {} private: ... const unique_ptr<Image> theImage; const unique_ptr<AudioClip> theAudioClip; }; #endif
11.禁止异常信息(exceptions)传递到析构函数外
- 有两种情况下会调用析构函数。第一种是在正常情况下删除一个对象,例如对象超出 了作用域或被显式地 delete。第二种是异常传递的堆栈辗转开解(stack-unwinding即栈解旋)过程 中,由异常处理系统删除一个对象。
- 在上述两种情况下,调用析构函数时异常可能处于激活状态也可能没有处于激活状态。 遗憾的是没有办法在析构函数内部区分出这两种情况。因此在写析构函数时你必须保守地假设有异常被激活。因为如果在一个异常被激活的同时,析构函数也抛出异常,并导致程序控 制权转移到析构函数外,C++将调用 terminate 函数。这个函数的作用正如其名字所表示的: 它终止你程序的运行,而且是立即终止,甚至连局部对象都没有被释放。
- 所以必须禁止析构函数内部抛出异常。如果一个异常被析构函数抛出而没有在函数内部捕获住,那么析构函数就不会完全运行(它会停在抛出异常的那个地方上)。
- 综上所述,我们知道禁止异常传递到析构函数外有两个原因,第一能够在异常转递的堆 栈辗转开解(stack-unwinding)的过程中,防止 terminate 被调用。第二它能帮助确保析 构函数总能完成我们希望它做的所有事情。
-
#include <cstdio> #include <cstdlib> #include <cassert> #include <iostream> class Session { public: Session() { logCreation(this); //startTransaction(); // 启动 database transaction } ~Session() { // 如果下面这个函数抛出异常异常没有被 Session 的析构函数捕获住 // 所以它被传递到析构函数的调用者那里。但是如果析构函数本身的调用就是源自于某些其它异常的抛出(即在此之前已经发生了异常), // 那么 terminate 函数将被自动调用,彻底终止你的程序。 // 就好像是这样一种操作: #if 0 Session* p = new Session; try { // ...其他操作,假设这里面某些操作发生了异常 } catch (...) { // ... delete p; // } #endif logDestruction(this); // 阻止异常被传递到析构函数的外面 // 如果一个异常被析构函数抛出而没有在函数内部捕获住,那么析构函数就不会完全运行(它会停在抛出异常的那个地方上) #if 0 try { logDestruction(this); } catch (...) {} // catch 表面上好像没有做任何事情,实际上它阻止了任何从logDestruction 抛出的异常被传递到析构函数的外面 // 如果你再catch代码块中加入其他操作,里面又发生了异常,则异常又将被传递到析构函数外面 #endif // 如果上面发生了异常,则析构函数无法完成后面的操作 //endTransaction(); // 结束 database transaction } //... private: static void logCreation(Session *objAddr) {} static void logDestruction(Session *objAddr) { throw; } }; int main(int argc, char* argv[]) { Session* p = new Session; try { // ...其他操作,假设这里面某些操作发生了异常 throw 12; } catch (...) { // ... delete p; // 可以在 catch 中再放入 try,但是这总得有一个限度,否则会陷入循环,所以还是得阻止Session类的析构函数再抛出异常 } // ... system("pause"); return 0; }
12.理解“抛出一个异常”与“传递一个参数”或“调用一个虚函数”间的差异
- 异常对象在传递时总被进行拷贝;当通过传值方式捕获时,异常对象被拷贝了两次。对象做为参数传递给函数时不一定需要被拷贝,异常对象的存储和普通对象不一样,Windows中它们时建立在TIB(线程信息块)中,在抛出异常时通过拷贝构造函数生成。
- 对象做为异常被抛出与做为参数传递给函数相比,前者类型转换比后者要少(前者只有两种转换形式:派生类与基类间转换与类型指针转void*,不支持隐式类型转换)
- catch 子句进行异常类型匹配的顺序是它们在源代码中出现的顺序,第一 个类型匹配成功的 catch 将被执行。当一个对象调用一个虚拟函数时,采用最佳匹配方式
-
#if 0 //一个类 class Widget { ... }; class SpecialWidget : public Widget { ... }; // 一些函数,其参数分别为Widget, Widget&,或Widget* 类型 void f1(Widget w); void f2(Widget& w); void f3(const Widget& w); void f4(Widget *pw); void f5(const Widget *pw); //一些 catch 子句,用来捕获异常,异常的类型为Widget, Widget&,或Widget* catch (Widget w) ... catch (Widget& w) ... catch (const Widget& w) ... catch (Widget *pw) ... catch (const Widget *pw) ... // 函数参数传递和异常传递的异同点: 1.传递函数参数与异常都可以是传值、传递引用或传递指针。但是传递参数和异常时,系统所要完成的操作过程则是完全不同的。 原因是:调用函数时,程序的控制权最终还会返回到函数的调用处,但是抛出一个异常时,控制权永远不会回到抛出异常的地方 #if 0 istream operator>> (istream& is, Widget& w); void passAndThrowWidget() { // local Widget localWidget; // call operator>> function cin >> localWidget; // throw exception throw localWidget; } /* 当传递localWidget到函数 operator>>里,不用进行拷贝操作,而是把 operator>>内的引用类型变量 w 指向 localWidget,任何对 w 的操作实际上都施加到 localWidget 上。 这与抛出 localWidget 异常有很大不同。不论外部是通过传值捕获异常还是通过引用捕获(不能通过指针捕获这个异常,因为此处类型不匹配)都将进行 lcalWidget 的拷贝操作, 也就说传递到 catch 子句中的是 localWidget 的拷贝。必须这么做,因为当 localWidget 是局部对象,离开作用域后其析构函数将被调用。如果把 localWidget 本身传递给 catch 子句, 这个子句接收到的只是一个被析构了的 Widget,这是无法使用的。因此C++规范要求被做为异常抛出的对象必须被复制!!!即使被抛出的对象不会被释放,也会进行拷贝操作!!! 如把localWidget改用静态变量,当抛出异常时仍将复制出 localWidget 的一个拷贝。这表示即使通过引用来捕获异常,也不能在 catch 块中修改 localWidget; 仅仅能修改 localWidget 的拷贝。对异常对象进行强制复制拷贝,这个限制有助于我们理解参数传递与抛出异常的第二个差异:抛出异常运行速度比参数传递要慢。 */ #endif 2.C++规范要求被做为异常抛出的对象必须被复制!!!即使被抛出的对象不会被释放,也会进行拷贝操作!!! 对异常对象进行强制复制拷贝,这个限制有助于我们理解参数传递与抛出异常的第二个差异:抛出异常运行速度比参数传递要慢。 3.当异常对象被拷贝时,拷贝操作是由对象的拷贝构造函数完成的。该拷贝构造函数是对象的静态类型(static type)所对应的拷贝构造函数, 而不是对象的动态类型(dynamic type)的拷贝构造函数。 #if 0 void passAndThrowWidget() { static SpecialWidget localWidget; Widget& rw = localWidget; // 抛出的异常对类型是 Widget,即使 rw 引用的是一个 SpecialWidget。因为 rw 的静态类型(static type)是 Widget throw rw; } #endif 4.再次抛出异常时,一般来说,你应该用 throw 来重新抛出当前的异常,因为这样不会改变被传递出去的异常类型,而且更有效率,因为不用生成一个新拷贝。 #if 0 // 以下2种的区别 try { // ... throw SpecialWidget(); } catch (Widget& w) { // ... throw; // 重新抛出当前捕获的异常,让它继续传递,不拷贝也不会改变原来的类型(抛出时的类型,即SpecialWidget) } try { // ... throw SpecialWidget(); } catch (Widget& w) { // ... throw w; // 传递的是被捕获异常的拷贝,类型变成Widget } #endif 5.一个被异常抛出的对象(总是一个临时对象)可以通过普通的引用捕获;可以不通过指向 const 对象的引用捕获。 但是在函数调用中不允许转递一个临时对象到一个非 const 引用类型的参数里(比如不允许返回局部变量的普通引用),但是在异常中却被允许。 catch (Widget w) // 传值捕获,会建立两个被抛出对象的拷贝,一个是所有异常都必须建立的临时对象(即throw的时候),第二个是把临时对象拷贝进 w 中(重要:是两个!) catch (Widget& w) // 引用捕获,这仍旧会建立一个被抛出对象的拷贝:拷贝同样是一个临时对象。(throw的时候) // 当我们通过引用传递函数参数时,没有进行对象拷贝。当抛出一个异常时,系统构造的(以后会析构)被抛出对象的拷贝数量 // 比以相同对象做为参数传递给函数时构造的拷贝数要多一个。 // 不过,通过指针抛出异常与通过指针传递参数是相同的。不论哪种方法都是一个指针变量的拷贝被传递。但,抛出的指针不能指向局部变量 // 因为当异常离开局部变量的生存空间时,该局部变量已经被释放。Catch 子句将获得一个指向已经不存在的对象的指针。 catch (const Widget& w) // const引用捕获 6.第二个差异:在函数调用者或抛出异常者与被调用者或异常捕获者之间的类型匹配的过程不同。 函数调用时形参可能进行隐式类型转换如int--->double,但是catch进行异常类型匹配时不会进行这种转换,必须和throw的类型严格匹配。 不过在 catch 子句中进行异常匹配时可以进行两种类型转换: 第一种是继承类与基类间的转换,如基类类型可以捕获派生类异常。 第二种是允许从一个类型化指针(typed pointer)转变成无类型指针(untypedpointer),所以带有 const void* 指针的 catch 子句能捕获任何类型的指针类型异常: catch (const void*) ... //捕获任何指针类型异常 7.最后一点差别是 catch 子句匹配顺序总是取决于它们在程序中出现的先后顺序。可以这样说虚拟函数采用最优适合法, 而异常处理采用的是最先适合法。例如: try { ... } catch (logic_error& ex) { // 这个 catch 块 将捕获所有的 logic_error异常, 包括它的派生类 ... } catch (invalid_argument& ex) { // 这个块永远不会被执行 ... //因为所有的invalid_argument(logic_error的派生类)异常 都被上面的catch 子句捕获。 } #endif
13.通过引用捕获异常
- 捕获异常的方式:指针(by pointer),传值(by value) 引用(by reference)。
- 指针方式捕获理论上是效率最高的,因为不用拷贝指针所指的对象,但是必须确保当程序控制权离开抛出指针的函数后,所指对象还存在(通过定义全局/静态对象,创建在堆上时异常对象谁来删除?)。这种方式不推荐使用,通过指针捕获异常也不符合 C++语言本身的规范。四个标准异常:bad_alloc(当 operator new无法分配足够的内存时被抛出),bad_cast(针对一个reference操作失败时被抛出)bad_typeid(当 dynamic_cast 对空指针进行操作时被抛出)和 bad_exception(用于 unexpected 异常)――都不是指向对象的指针,所以你必须通过值或引用来捕获它们。
- 通过值捕获异常(catch-by-value)可以解决异常对象删除的问题和使用标准异常类型的问题。但是当它们被抛出时系统将对异常对象拷贝两次(参见条款 12)。而且它会产生 slicing problem(就是第二次拷贝时导致的切片),即派生类的异常对象被做为基类异常对象捕获时, 那它的派生类行为就被切掉了(sliced off)。这样sliced后的对象实际上是一个基类对象: 它们没有派生类的成员,而且当调用它们的虚函数时,系统解析后调用的是基类对象的函数。(当一个对象通过值传递方式给函数,也会发生一样的情况,即无法产生多态)。
- 通过引用捕获异常能使你避开上述所有问题。不像通过指针捕获异常,这种方法不会有对象删除的问题而且也能捕获标准异常类型。也不象通过值捕获异常,这种方法没有 slicing problem,而且异常对象 只被拷贝一次。
-
#include <cstdio> #include <cstdlib> #include <cassert> #include <iostream> #include <exception> class MyException : public std::exception { public: virtual const char* what() const throw() { return "MyException Occur!\n"; } }; void Func(int num) { if (num <= 0) { throw MyException(); // 抛出的是临时对象的拷贝 } else { std::cout << "num:" << num << std::endl; } } void CatchByValue() { try { Func(-1); // 抛出MyException异常 } catch (std::exception ex) { // 捕获所有标准异常及其派生类,这里会再一次进行拷贝(导致了slicing problem),将throw出的对象拷贝到catch的参数ex std::cerr << ex.what(); // 调用的是std::exception::what() 因为MyException对象被切片 } } void CatchByReference() { try { Func(-1); // 抛出MyException异常 } catch (std::exception& ex) { // 捕获所有标准异常及其派生类,且这里的ex是throw对象的引用,不会再拷贝一次 std::cerr << ex.what(); } } int main(int argc, char* argv[]) { CatchByValue(); CatchByReference(); system("pause"); return 0; }
14.审慎使用异常规格(exception specifications)
- 异常规格是一个特性:明确地描述了一个函数可以抛出什么样的异常。
- 如果一个函数抛出一个不在异常规格范围里的异常,系统在运行时能够检测出这个错误,然后一个特殊函数 unexpected 将被自动调用。函数 unexpected 缺省的行为是调用函数 terminate,而 terminate 缺省的行为是调用函数 abort, 所以一个违反异常规格的程序其缺省的行为就是 halt(停止运行)。在激活的栈中的局部变量没有被释放,因为abort 在关闭程序时不进行清除操作。
- 不幸的是写出导致这种灾难的函数,因为编译器仅能部分地检测异常的使用是否与异常规格保持一致。如果一个函数(设为A)调用了另一个函数(设为B),并且B可能抛出一个 违反A函数异常规格的异常,编译器不对此种情况进行检测,并且C++语言标准允许这种调用方式(尽管编译器可能显示警告信息)。
- 编译器仅仅能部分地检测异常规格是否一致,在模板中使用它们会有问题,一不注意它们就很容易被违反,并且在缺省的情况下 它们被违反时会导致程序终止运行。异常规格还有一个缺点就是它们能导致 unexpected 被触发,即使一个 high-level 调用者准备处理被抛出的异常。
-
#if 0 // 编译器允许你调用一个函数,其抛出的异常当前函数的异常规格不一致,但是调用这种函数可能导致程序执行被终止 // 例如函数 f1 没有声明异常规格,这样的函数就可以抛出任意种类的异常: extern void f1(); // 可以抛出任意的异常 // 函数 f2 通过它的异常规格来声明其只能抛出 int 类型的异常: void f2() throw(int); // f2调用f1是非常合法的,即使f1可能抛出一个违反f2异常规格的异常,但是当别人调用f2时可能导致程序终止: void f2() throw(int) { //... f1(); // 即使 f1 抛出不是 int 类型的异常,这也是合法的。 //... } // 避免在带有类型参数的模板内使用异常规格 // a poorly designed template wrt exception specifications template<class T> bool operator==(const T& lhs, const T& rhs) throw() { return &lhs == &rhs; } // 这个模板包含的异常规格表示模板生成的函数不能抛出异常。但是事实可能不会这样,因为 opertor& 能被一些类型对象重载。 // 如果被重载的话,opertor&可能会抛出一个异常,这样就违反了operator==的异常规格,使得程序控制跳转到 unexpected。 // 如果在一个函数内调用其它没有异常规格的函数时应该去除这个函数的异常规格。如上面的f2就应该去除,因为f1没有异常规格 // 避免调用 unexpected 的第三个方法是处理系统本身抛出的异常. // 这些异常中最常见的是 bad_alloc,当内存分配失败时它被 operator new 和 operator new[]抛出 // 虽然防止抛出 unexpected 异常是不现实的,但是 C++允许你用其它不同的异常类型替换 unexpected 异常 // 例如你希望所有的 unexpected 异常都被替换为UnexpectedException 对象。你能这样编写代码: class UnexpectedException {}; // 所有的 unexpected 异常对象被替换为这种类型对象 void convertUnexpected() // 如果一个 unexpected 异常被抛出,这个函数被调用 { throw UnexpectedException(); } // 通过用 convertUnexpected函数替换缺省的 unexpected函数,来使上述代码开始运行。: set_unexpected(convertUnexpected); // 当这么做了以后,一个 unexpected 异常将触发调用 convertUnexpected 函数。Unexpected 异常被 UnexpectedException 异常替换。 // 如果被违反的异常规格包含 UnexpectedException 异常,那么异常传递将继续下去,好像异常规格总是得到满足。 // 如果异常规格没有包含 UnexpectedException,terminate 将被调用,就好像你没有替换unexpected 一样 // 另一种把 unexpected 异常转变成知名类型的方法是替换 unexpected 函数,让其重新抛出当前异常,这样异常将被替换为 bad_exception。 // 你可以这样编写: void convertUnexpected() // 如果一个 unexpected 异常被抛出,这个函数被调用 { throw; // 它只是重新抛出当前 } set_unexpected(convertUnexpected); // 安装异常处理器 // 如果这么做,你应该在所有的异常规格里包含 bad_exception(或它的基类,标准类exception)。 // 任何违反异常规格的异常都将被替换为 bad_exception,这个异常代替原来的异常继续传递。 // 异常规格还有一个缺点就是它们能导致 unexpected 被触发,即使一个 high - level 调用者准备处理被抛出的异常 class Session { public: // ... ~Session { // 现在假设被 logDestruction 调用的函数抛出了一个异常,而 logDestruction没有捕获 // 则当这个异常通过 logDestruction 传递出来时,unexpected 将被调用,缺省情况下将导致程序终止执行。 // 这种情况下使用try...catch也没用,根本没机会处理异常 try { logDestruction(this); } catch (...) { // ... } } // ... private: // ... // 异常规格声明表示该函数不会抛出任何异常(但是不保证它内部调用的函数不会抛异常) // 现在假设被 logDestruction 调用的函数抛出了一个异常,而 logDestruction没有捕获 // 则当这个异常通过 logDestruction 传递出来时,unexpected 将被调用,缺省情况下将导致程序终止执行。--- 这种情况下使用try...catch也没用,根本没机会处理 // 但是如果 logDestruction 没有异常规格,这种事情就不会发生!!! static void logDestruction(Session *objAddr) throw(); };
15.了解异常处理的系统开销
- 为了在运行时处理异常,程序要记录大量的信息。无论执行到什么地方,程序都必须能够识别出如果在此处抛出异常的话,要释放哪一个对象;程序必须知道每一个入口点, 以便从 try 块中退出;对于每一个 try 块,他们都必须跟踪与其相关的 catch 子句以及这些 catch 子句能够捕获的异常类型。这种信息的记录不是没有代价的。虽然确保程序满足异常规格不需要运行时的比较(runtime comparisons),而且当异常被抛出时也不用额外的开销来释放相关的对象和匹配正确的 catch 子句。但是异常处理确是有代价的,即使你没有使用 try,throw 或 catch 关键字,你同样得付出一些代价。异常是 C++的一部分,C++编译器必须支持异常,所以即使你不使用异常处理你也很难避免这种开销,你无法保证你程序中链接的其他程序库也不用异常处理。
- 使用异常处理的第二个开销来自于 try 块:如果你使用 try 块,代码的尺寸将增加 5%-10%并且运行速度也同比例减慢(不用编译器实现会有差异)。这还是假设程序没有抛出异常的情况下,所以,为了减少开销,你应该避免使用无用的 try 块。
- 与一个正常的函数返回相比,通过抛出异常从函数里返回可能会慢三个数量级。这个开销很大,但是仅仅当你抛出异常时才会有这个开销,一般不会发生。
16.80-20准则
-
80-20 准则说的是大约 20%的代码使用了 80%的程序资源;大约 20%的代码耗用了大约 80%的运行时间;80%的维护投入于大约 20%的代码上;通过无数台机器、操作系统和应用程序上 的实验这条准则已经被再三地验证过。
-
用尽可能多的数据 profile 你的软件。此外,你必须确保每组数据在客户(或至少是最重要的客户)如何使用软件的方面能有代表性。通常获取有代表性的数据是很容易的,因为许多客户都愿意让你用他们的数据进行 profile。毕竟你是为了他们需求而优化软件。
17.考虑使用懒惰计算法
等到真正需要时才执行操作。常用的一些例子:
- 引用计数实现隐式内存共享:构造时浅拷贝,内存共享,只有当需要修改内存值时才真正拷贝一份数据。
18.分期摊还期望的计算
核心:过度热情及算法,隐藏在 over-eager evaluation 后面的思想是如果你认为一个操作需要频繁进行,你就可以设计一个数据结构高效地处理这些计算需求,这样可以降低每次计算需求时的开销。
- 采用 over-eager 最简单的方法就是 caching(缓存)那些已经被计算出来而以后还有可能需要的值,如缓存数据库查询数据。Prefetching(预提取)是另一种方法。
- 例如磁盘控制器从磁盘读取数据时,它们会读取一整块或整个扇区的数据,即使程序仅需要一小块数据。这是因为一次读取一大块 数据比在不同时间读取两个或三个小块数据要快。而且经验显示如果需要一个地方的数据, 则很可能也需要它旁边的数据。这是位置相关现象。正因为这种现象,系统设计者才有理由 为指令和数据使用磁盘 cache 和内存 cache,还有使用指令prefetch。再比如vector容器的扩容,每次扩容时都会预先分配比需求数量多的内存。
-
int FincCubicleNumber(const std::string& empName) { typedef std::map<std::string, int> CubicleMap; static CubicleMap cubs; // 先尝试查找缓存数据中是否存在 auto it = cubs.find(empName); // 不存在时采取数据库查找 if (it == cubs.end()) { int cubiicle = 11111; // 从数据库中查询,这里省略... cubs[empName] = cubiicle; return cubiicle; } else { // 返回的是(*it).second,而不是常用的 it->second。为什么?答案是这是为了遵守 STL 的规则 // 简单地说,iterator 是一个对象,不是指针,所以不能保证”->”被正确应用到它上面。不过 STL 要求”.”和”*” // 在 iterator 上是合法的,所以(*it).second 在语法上虽然比较繁琐,但是保证能运行 return (*it).second; // } }
19.理解临时对象的来源
- 建立一个没有命名的非堆(non-heap)对象会产生临时对象。这种未命名的对象通常在两种条件下产生:为了使函数成功调用而进行隐式类型转换和函数返回对象时。
- 首先考虑为使函数成功调用而建立临时对象这种情况。当传送给函数的对象类型与参数类型不匹配时会产生这种情况,允许的情况下编译器会进行隐式类型转换构造临时对象。仅当通过传值(by value)方式传递对象或传递常量引用(reference-to-const)参数时,才会发生这些类型转换。当传递一个非常量引用(reference-to-non-const)参数对象, 就不会发生。
void PrintString1(std::string str) { std::cout << "Arg type std::string :" << str << std::endl; } void PrintString2(std::string& str) { std::cout << "Arg type std::string& :" << str << std::endl; } void PrintString3(const std::string& str) { std::cout << "Arg type const std::string& :" << str << std::endl; } void TestFunc() { // 什么情况下会发生这种转换 char buf[256] = "qqqqqqqqqqq"; PrintString1(buf); // Error 无法进行隐式转换,因为PrintString2参数为非常量引用,里面可能需要通过引用修改实参,构造临时对象用来修改是没有意义的
// 这就是为什么 C++语言禁止为非常量引用(reference-to-non-const) 产生临时对象 //PrintString2(buf); PrintString3(buf); }
- 建立临时对象的第二种环境是函数返回对象时。
- 临时对象是有开销的,应该尽可能地去除它们。在任何时候只要见到常量引用(reference-to-const) 参数,就存在建立临时对象而绑定在参数上的可能性。在任何时候只要见到函数返回对象, 就会有一个临时对象被建立(以后被释放)。
20.协助完成返回值优化
- 一个返回对象的函数很难有较高的效率,因为传值返回会导致调用对象内的构造和析构函数。一些函数(如operator*/operator+等运算符函数)必须要返回对象。以某种方法返回对象,能让编译器消除临时对象的开销,这种技巧是返回 constructor argument 而不是直接返回对象(也有人叫临时对象被扶正)。
-
#if 0 // 一种高效和正确的方法,用来实现返回对象的函数 const Rational operator*(const Rational& lhs, const Rational& rhs) { // 这个表达式建立一个临时对象,函数把它拷贝给函数的返回值。 // 返回 constructor argument 不用创建局部对象,这种方法还会给你带来很多开销,但是你仍旧必须为在函数内临时对象的构造和释放而付出代价, // 你仍旧必须为函数返回对象的构造和释放而付出代价。 // 但是,C++规则允许编译器优化不出现的临时对象(temporary objects out of existence) return Rational(lhs.numerator() * rhs.numerator(), lhs.denominator() * rhs.denominator()); } // 调用 Rational a = 10; Rational b(1, 2); Rational c = a * b; // 这里调用 operator* ,然后又拷贝构造,临时对象被扶正 //编译器就会被允许消除在 operator*内的临时变量和 operator*返回的临时变量。它们 //能在为目标 c 分配的内存里构造 return 表达式定义的对象。如果你的编译器这样去做,调 //用 operator*的临时对象的开销就是零:没有建立临时对象。你的代价就是调用一个构造函 //数――建立 c 时调用的构造函数。而且你不能比这做得更好了,因为 c 是命名对象,命名对 //象不能被消除。不过你还可以通过把函数声明为 inline 来消除 operator*的调用开销 // 这种叫named return value optimization。但注意,这种优化对普通的赋值运算无效, // 编译器不能够用拷贝构造函数取代赋值运算动作 #endif
21.通过重载避免隐式类型转换
- 隐式类型转换是需要建立临时对象,是有开销的。但是,没有必要实现大量的重载函数,除非你有理由确信程序使用重载函数以后其整体效率会有显著的提高
-
class UPInt { public: UPInt(); UPInt(int value); // ... public: friend const UPInt operator+(const UPInt& lhs, const UPInt& rhs); friend const UPInt operator+(const UPInt& lhs, int rhs); friend const UPInt operator+(int lhs, const UPInt& rhs); }; UPInt upi1, upi2; UPInt upi3 = upi1 + upi2; upi3 = upi1 + 10; // 正确, 没有由 10 生成的临时对象 upi3 = 10 + upi2; // 正确, 没有由 10 生成的临时对象
22.考虑用运算符的赋值形式(op=)取代其单独形式(op)
- 确保 operator 的赋值形式(assignment version)(例如 operator+=)与一个 operator 的单独形式(stand-alone)(例如 operator+ )之间存在正常的关系,一种好方法是后者根据前者来实现(参见条款 M6)。
class Rational { public: ... Rational& operator+=(const Rational& rhs); const Rational operator+(const Rational& lhs, const Rational& rhs) { return Rational(lhs) += rhs; } };
- 总的来说 operator 的赋值形式比其单独形式效率更高,因为单独形式要返回一个新对象,从而在临时对象的构造和释放上有一 些开销(参见条款M19和条款M20,还有 Effective C++条款 23)。operator 的赋值形式把结果写到左边参数,因此不需要生成临时对象来容纳 operator 的返回值。一般提供 operator 的赋值形式的同时也要提供其标准形式,允许类的客户端在便利与效率上做出折衷选择。
// 想想为什么不写成像下面这样? const Rational operator+(const Rational& lhs, const Rational& rhs) { Rational tmp(lhs); return tmp += rhs; } // 如果这样写就需要创建一个命名的局部对象,这个命名对象意味着不能在 operator+ 里使用返回值优化(参见条款 M20)。 // 第一种实现方法总可以使用返回值优化,所以编译器为其生成优化代码的可能就会更大 // 第一个函数实现也有这样的临时对象开销,就象你为使用命名对象 result 而耗费的开销一样。 // 然而未命名的对象通常比命名对象更容易清除,因此当我们面对在命名对象和临时对象间进行选择时,用临时对象更好一些。 // 它的开销不会比命名的对象多,特别是使用老编译器时,它的耗费会更少。
23.考虑变更程序库
- 不同的程序库在效率、可扩展性、移植 性、类型安全和其他一些领域上蕴含着不同的设计理念,通过变换使用给予性能更多考虑的程序库,有时可以大幅度地提高软件的效率
24.理解虚拟函数、多继承、虚基类和RTTI所需的代价
- vtbl 通常是一个函数指针数组(一些编译器使用链表来代替数组,但是基本方法是一样的)类只要声明了虚函数或继承了虚函数,它就有自己的 vtbl, vtbl 中存放的每一个元素是指向虚函数实现体的指针。这个论述引出了虚函数所需的第一个代价:你必须为每个包含虚函数的类的 virtual talbe 留出空间。类的 vtbl 的大小与类中声明的虚函数的数量成正比(包括从基类继承的虚函数)。每个类只有一个 virtual table,所以 virtual table 所需的空间不会太大, 但是如果你有大量的类或者在每个类中有大量的虚函数,你会发现 vtbl 会占用大量的地址 空间。
class C1 { public: C1(); virtual ~C1(); virtual void f1(); virtual int f2(char c) const; virtual void f3(const string& s); void f4() const; ... }; class C2 : public C1 { public: C2(); virtual ~C2(); // 重写函数 virtual void f1(); // 重写函数 virtual void f5(char *str); // 新的虚函数 ... };
// 避免把虚函数声明为内联函数


- vptr:每个声明了虚函数的对象都包含vptr成员,它是一个看不见的数据成员,指向对应类的 virtual table。在每个包含虚函数的类的对象里,你必须为额外的指针付出代价,大小为对应平台下一个指针所占字节数。

- 虚函数调用过程
-
1. 通过对象的 vptr 找到类的 vtbl。这是一个简单的操作,因为编译器知道在对象内哪里能找到 vptr(毕竟是由编译器放置的它们)。 因此这个代价只是一个偏移调整(以得到vptr)和一个指针的间接寻址(以得到 vtbl)。 2. 找到对应 vtbl 内的指向被调用函数的指针。这也是很简单的,因为编译器为每个虚函数在 vtbl 内分配了一个唯一的索引。 这步的代价只是在 vtbl 数组内的一个偏移。 3. 调用第二步找到的的指针所指向的函数。
- 在多继承中,在对象里为寻找 vptr 而进行的偏移量计算会变得更复杂。在单个对象里有多个 vptr(每一个基类对应一个);除了自己的 vtbl 以外,还得为基类生成特殊的 vtbl。 因此增加了每个类和每个对象中的虚函数额外占用的空间,而且运行时调用所需的代价也增加了一些。而且菱形继承还需要特殊处理。
- RTTI 能在运行时找到对象和类的有关信息,这些信息被存储在类型为 type_info 的对象里,你能通过使用 typeid 操作符访问一个类的 type_info 对象。C++ RTTI是在类的 vtbl 基础上实现
- 使用嵌套的 switch 语句或层叠的 if-else 语句模拟虚函数的调用,其产生的代码比虚函数的调用还要多,而且代码 运行速度也更慢。
25.将构造函数和非成员函数虚拟化
26.限制某个类所能产生的对象数量
- 在类中的静态对象(还有全局的)实际上总是被构造(和释放),即使不使用该对象。函数中的静态对象只有第一次执行函数时,才会建立函数中的静态对象,所以如果没有调用函数,就不会建立对象。 (不过你得为此付出代价,每次调用函数时都得检查是否需要建立对象。)
- 类中的静态成员还有一个缺点,就是它的初始化时间不确定。我们能够准确地知道函数中的静态成员什么时候被初始化:“在第一次执行函数时”。C++没有定义一个类的静态成员被初始化的时间。C++为一个 translation unit(也就是生成一个 object 文件的源代码的集合)内的静态成员的初始化顺序提供某种保证,但是对于在不同 translation unit 中的静态成员的初始化顺序则没有这种保证(参见 Effective C++条款 47)
27.要求或禁止在堆内存中创建对象
- 当在堆上分配对象时,会调用operator new来分配raw memory。(当类重载了operator new则调用类的,否则调用全局的::operator new)但是为数组分配内存的是 operator new[],而不是 operator new。
class UPNumber { public: UPNumber() { if (!m_bOnHeap) { throw std::exception("Object not on heap!"); } m_bOnHeap = false; // 为下一个对象清除标记 } static void* operator new(size_t size) { std::cout << "UPNumber operator new!" << std::endl; m_bOnHeap = true; return ::operator new(size); } private: static bool m_bOnHeap; }; bool UPNumber::m_bOnHeap = false;
- 第一是我们极不愿意在全局域定义任何东西,特别是那些已经具有某种含义的函数,象 operator new 和 operator delete。 正如我们所知,只有一个全局域,只有一种具有正常特征形式(也就是参数类型)的 operator new 和 operator delete(条款 9)。这样做会使得我们的软件与其它也实现全局版本的 operator new 和 operator delete 的软件(例如许多面向对象数据库系统)不兼容。
#if 0 // 判断对象是否在堆中 // 混合类; 用于跟踪从 operator new 返回的 ptr class HeapTracked { public: class MissingAddress {}; // 异常类 virtual ~HeapTracked() = 0; static void *operator new(size_t size); static void operator delete(void *ptr); bool isOnHeap() const; private: typedef const void* RawAddress; static list<RawAddress> addresses; }; // 以下是 HeapTracked 的全部实现: // mandatory definition of static class member list<RawAddress> HeapTracked::addresses; // HeapTracked 的析构函数是纯虚函数,使得该类变为抽象类。 // (参见 Effective C++条款 14). 然而析构函数必须被定义,所以我们做了一个空定义。. HeapTracked::~HeapTracked() {} void * HeapTracked::operator new(size_t size) { void *memPtr = ::operator new(size); // 获得内存把地址放到 list 的前端 addresses.push_front(memPtr); return memPtr; } void HeapTracked::operator delete(void *ptr) { list<RawAddress>::iterator it = find(addresses.begin(), addresses.end(), ptr); if (it != addresses.end()) { // 如果元素是堆中分配的, 则可以delete addresses.erase(it); ::operator delete(ptr); // 释放内存 } else { // 否则 throw MissingAddress(); // ptr 是用 operator new分配的,所以抛出一个异常 } } bool HeapTracked::isOnHeap() const { // 带有多继承或虚基类的对象会有几个地址,这导致编写全局函数 // isSafeToDelete会很复杂。这个问题在 isOnHeap 中仍然会遇到,但是因为 isOnHeap 仅仅 // 用于 HeapTracked 对象中,我们能使用 dynamic_cast 操作符(参见条款 M2)的一种特殊的 // 特性来消除这个问题。只需简单地放入 dynamic_cast,把一个指针 dynamic_cast 成 void* // 类型(或 const void*或 volatile void* 。。。。。),生成的指针将指向“原指针指向对象内存”的开始处。 // dynamic_cast 只能用于“指向至少具有一个虚拟函数的对象”的指针 // 得到一个指针,指向*this 占据的内存空间的起始处 const void *rawAddress = dynamic_cast<const void*>(this); // 在 operator new 返回的地址 list 中查到指针 list<RawAddress>::iterator it = find(addresses.begin(), addresses.end(), rawAddress); return it != addresses.end(); // 返回 it 是否被找到 } // 通过继承,子类一样具备追踪功能 class Asset : public HeapTracked { private: UPNumber value; ... }; // 我们能够这样查询 Assert*指针,如下所示: void inventoryAsset(const Asset *ap) { if (ap->isOnHeap()) { // ap is a heap - based asset — inventory it as such; } else { // ap is a non - heap - based asset — record it that way; } } #endif
- 禁止在堆中建立对象
#if 0 // 通常对象创建有三种情况:对象被直接实例化(堆、栈、全局等);对象做为派生类的基类被实例化;对象被嵌入到其它对象内作为成员。 // 1.禁止在堆中直接实例化 // 堆对象总是调用 new 来建立这种对象,你能够禁止用户调用 new。你不能影响 new 操作符的可用性(这是内嵌于语言的), // 但是可以利用 new 操作符总是调用 operator new 函数这个特点来达到目的,即把它声明为 private。 // 如果想禁止堆对象数组,可以把 operator new[]和 operator delete[](参见条款 M8)也声明为 private class UPNumber { private: static void *operator new(size_t size); static void operator delete(void *ptr); // ... }; // 2.作为基类被实例化 // 把 operator new 声明为 private 经常会阻碍 UPNumber 对象做为一个位于堆中的派生类对象的基类被实例化(即派生类没法new一个对象) // 因为 operator new 和 operator delete 是自动继承的,如果 operator new 和 operator delete 没有在派生类中被声明为 public //(需进行overwrite),它们就会继承基类中 private 的版本 class NonNegativeUPNumber : public UPNumber // 派生类没有重写 operator new, 默认继承基类的 { // ... // 如果派生类声明它自己的 operator new,当在堆中分配派生对象时,就会调用这个函数 }; NonNegativeUPNumber n1; // 正确 static NonNegativeUPNumber n2; // 也正确 NonNegativeUPNumber *p = new NonNegativeUPNumber; // 错误! 试图调用private operator new // 3.对象作为其他类的成员 // UPNumber 的 operator new是 private 这一点,不会对包含 UPNumber 成员对象的对象的分配产生任何影响 class Asset { public: Asset(int initValue); //... private: UPNumber value; }; // 正确, 调用Asset::operator new(如果Asset声明了) 或::operator new, 不是UPNumber::operator new Asset *pa = new Asset(100); #endif
28.智能指针
智能指针最大的作用时管理动态分配的内存或者说资源,避免用户忘记释放,以及在发生异常时能够避免内存泄漏。智能指针提供了与原始指针一样的行为,如operator->和operator*。
29.引用计数
- 引用计数是这样一个技巧,它允许多个有相同值的对象共享这个值的实现。这个技巧有两个常用动机:第一个是简化跟踪堆中的对象的过程,第二个是共享实现
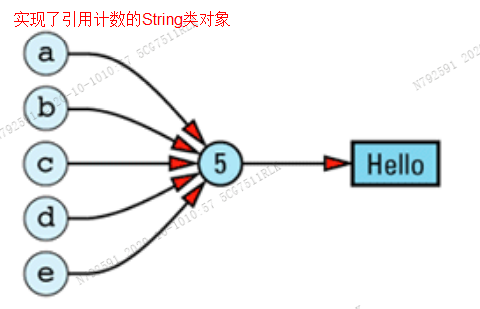
- 实现引用计数不是没有代价的。每个被引用的值带一个引用计数,其大部分操作都需 要以某种形式检查或操作引用计数。对象的值需要更多的内存,而我们在处理它们时需要执 行更多的代码。
- 引用计数是基于对象通常共享相同的值的假设的优化技巧(参见 Item M18)。如果假设 不成立的话,引用计数将比通常的方法使用更多的内存和执行更多的代码。另一方面,如果你的对象确实有具体相同值的趋势,那么引用计数将同时节省时间和空间。共享的值所占内存越大,同时共享的对象数目越多,节省的内存也就越大。创建和销毁这个值的代价越大, 你节省的时间也越多。总之,引用计数在下列情况下对提高效率很有用:1.少量的值被大量的对象共享;2.对象的值的创建和销毁代价很高昂,或它们占用大量的内存。
30.代理类
- 代理类说白了就是为了辅助实现某种功能的内部嵌套类,如用于实现二维数组的下标操作和用于识别operator[]是读操作还是写操作。
- Proxy 类可以完成一些其它方法很难甚至不可能实现的行为。多维数组是一个例子,左 /右值的区分是第二个,限制隐式类型转换(见条款5)是第三个。
- Proxy类也有缺点:作为函数返回值,proxy 对象是临时对象,必须被构造和析构。Proxy 对象的存在增加了软件的复杂度,因为额外增加的类使得事情更难设计、实现、 理解和维护。
31.让函数根据一个以上的对象来决定怎么虚拟
待更新
