


os,sys,json,pickle 模块
os模块
//getcwd()方法,获取当前正在执行的python脚本的工作目录
import os print(os.getcwd()) 结果 C:\python编程
//chdir()方法,改变当前脚本的工作目录
import os print(os.getcwd()) os.chdir("test") print(os.getcwd()) 结果 C:\python编程 C:\python编程\test
//curdir <--> "." pardir<-->".."
//makedirs()方法,递归生成文件夹//当然传的也可以是绝对路径,只不过不传绝对路径则在当前执行文件的层里找
import os os.makedirs('tt1\st2\s\s\s\s\s\s') 结果 在脚本的同一层里生成一个叫‘tt1’的文件夹,在‘tt1’里再生成‘st2’文件夹,在‘st2’里面再生成‘s'文件夹 递归生成下去 注意是生成文件夹而不是包
//mkdir()方法,和上面的一样,不过这个只生成一个目录,不可以生成多个//当然传的也可以是绝对路径,只不过不传绝对路径则在当前执行文件的层里找
//removedirs()方法,递归删除空文件夹直到遇到某个不为空的文件夹则停止//当然传的也可以是绝对路径,只不过不传绝对路径则在当前执行文件的层里找
原本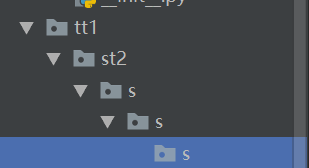
import os # os.makedirs('tt1\st2\s\s\s\s\s\s') os.removedirs('tt1\st2\s\s\s') 结果 直接删除 啥都没
原本

import os # os.makedirs('tt1\st2\s\s\s\s\s\s') os.removedirs('tt1\st2\s\s\s\s\s\s')
结果
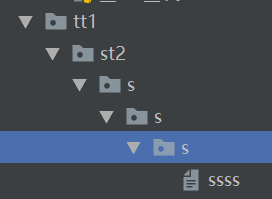
//rmdir()方法,和上面的一样,不过它只可以删除一个空目录,如果这一个目录不为空则无法删除 //当然传的也可以是绝对路径,只不过不传绝对路径则在当前执行文件的层里找
//remove()方法,直接删除一个文件,无论空不空都可以删除 但是只删除一个//当然传的也可以是绝对路径,只不过不传绝对路径则在当前执行文件的层里找
//listdir()方法,将脚本所在层的所有文件列出来//当然传的也可以是绝对路径,只不过不传绝对路径则在当前执行文件的层里找
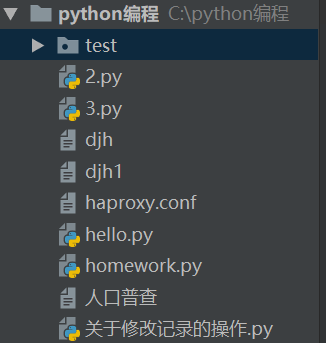
import os print(os.listdir())//返回一个列表 结果 ['.idea', '2.py', '3.py', 'djh', 'djh1', 'haproxy.conf', 'hello.py', 'homework.py', 'test', '__pycache__', '人口普查', '关于修改记录的操作.py']
//stat()方法,返回一个文件的相关信息 //当然传的也可以是绝对路径,只不过不传绝对路径则在当前执行文件的层里找
import os,time a = os.stat('hello.py')//返回一个啥?不知道怎么说 print(a) print(time.ctime(a.st_atime),time.ctime(a.st_mtime),time.ctime(a.st_ctime)) os.stat_result(st_mode=33206, st_ino=36028797018978551, st_dev=819522828, st_nlink=1, st_uid=0, st_gid=0, st_size=6335, st_atime=1533745991, st_mtime=1533745991, st_ctime=1527918566) Thu Aug 9 00:33:11 2018 Thu Aug 9 00:33:11 2018 Sat Jun 2 13:49:26 2018 //st_atime 是上一次的查看时间 st_mtime 上一次的修改时间 st_ctime 这个文件的创建时间
//system()方法,使用终端的命令
os.system('cls')
//path.abspath()方法,输入一个文件名,返回该文件名的绝对路径
import os print(os.path.abspath('2.py')) 结果 C:\python编程\2.py
//path.split()方法,path.dirname()方法,path.basename()方法
import os a = os.path.abspath('2.py') print(a) print(os.path.split(a))//将绝对路径切成目录和文件名这个二元组 print(os.path.dirname(a))//返回绝对路径的目录 print(os.path.basename(a))//返回绝对路径的文件名 结果 C:\python编程\2.py ('C:\\python编程', '2.py') C:\python编程 2.py
//path.exists()方法,传一个路径(相对绝对都可以) 如果该路径存在则返回True 否则 False
//path.isabs()方法,传一个路径(上面的是判断一个路径是否存在,而这个是已经知道该路径存在,只是判断该路径是否是绝对路径)
//path.isfile()方法,传一个路径,如果该路径的最后一级是文件则True否则False (因为路径的最后一级有可能是文件夹)
//path.ispath()方法,和上面一样,只不过这个是判断传来的路径是否是目录(也就是最后一级是文件夹)是则True 否则False
//path.join()方法,路径拼接
import os a = 'C:\python编程' b = '2.py' c = os.path.join(a,b) print(c) 结果 C:\python编程\2.py
//os.path.getatime()方法,传入一个路径,返回该路径的所指的文件夹或文件的最后读取时间
//os.path.getmtime()方法,传入一个路径,返回该路径所指的文件夹或文件的最后修改时间
sys模块
//sys.path方法,返回一个列表,里面的元素是模块的搜索路径 (注意是五括号的)
//sys.exit()方法,直接退出程序,相当于c++里的main主函数的 return 0 直接将程序退出
//sys.maxsize方法,返回最大的 int 值 无括号的
//sys.argv 这个叼毛有点烦 sys.argv[]说白了就是一个从程序外部获取参数的桥梁,这个“外部”很关键,所以那些试图从代码来说明它作用的解释一直没看明白。因为我们从外部取得的参数可以是多个,所以获得的是一个列表(list),也就是说sys.argv其实可以看作是一个列表,所以才能用[]提取其中的元素。其第一个元素是程序本身,随后才依次是外部给予的参数。 其实就是可以直接输入任意个参数,返回一个列表,第一个元素是文件的绝对路径,之后的便是你自己输入的了
这个东西要在 命令窗口 用才有效,在pycharm里直接执行没叼用
import sys a = sys.argv[1:] print(a)

//sys.stdout.write()方法,其实print()函数的根本就是这个方法,只不过在这个基础上加了些其他东西 ,现在搞个进度条给你看看,
import time,sys for each in range(10): sys.stdout.write("#") time.sleep(0.5) 结果 ##########//但是,进度条是一个一个缓慢输出的,以上的代码无法实现这个动态的过程,因为在输出东西到屏幕时,包括print()函数,都是将要输出的东西先放进缓存里,等全部放进 缓存之后再一次性输出,所以是看不到动态的过程的 import time,sys for each in range(10): sys.stdout.write("#") time.sleep(0.5) sys.stdout.flush()//刷新缓存,就是在缓存里有多少东西就输出多少东西
json模块
因为json模块是负责进行任何语言之间的交流的,所以很重要!----其实就是因为各种语言都遵守json字符串格式,所以才可以通过json字符串进行任意语言的交流,比如如果传一个python的列表字符串过去给c++,c++就会有类似于eval()的函数,将字符串里的数据结构列表给提取出来变成一个数组
//json.dumps()方法,将python的数据类型转换为 json字符串(具有json格式的字符串,即将要转换的参数里的单引号全部改成双引号,然后再在最外层加个双引号)
a = [11,22,'33'] b = 8 c = 'asd' d = {'name':'djh','age':18} print(json.dumps(a)) print(json.dumps(b)) print(json.dumps(c)) print(json.dumps(d)) 结果 [11, 22, "33"] <class 'str'>//将里面的单引号全部变成双引号 再在最外层加给双引号 所以变成字符串 8 <class 'str'> "asd" <class 'str'>//将里面的单引号全部变成双引号 再在最外层加给双引号 所以输出时才会有 "" {"name": "djh", "age": 18} <class 'str'>
//json.dump()方法,专门用于文本时的操作,相当于简化了操作
import json dic = {'name': 'DJH', "age": 18} with open('djh', 'w', encoding="utf-8") as f_w: json.dump(dic,f_w)//两步结合在一起了 相当于 import json dic = {'name': 'DJH', "age": 18} with open('djh', 'w', encoding="utf-8") as f_w: dic_str = json.dumps(dic) f_w.write(dic_str)
//json.loads()方法,提取 json字符串 里的数据结构,注意是 json字符串 如果是普通的字符串是不可以用这个方法的(当然,如果你自己写的字符串是按json字符串的格式写的话还是可以用该方法的),只可以用eval()函数,当然json字符串也可以用eval()函数
import json dic = {'name': 'djh', "age": 18} dic = json.dumps(dic) print(dic,type(dic)) with open('djh', 'w', encoding="utf-8") as f_w: f_w.write(dic) with open('djh','r',encoding='utf_8') as f_r: data = f_r.read() print(data,type(data)) data = json.loads(data) print(data,type(data)) 结果 {"name": "djh", "age": 18} <class 'str'> {"name": "djh", "age": 18} <class 'str'> {'name': 'djh', 'age': 18} <class 'dict'>
//json.load()方法,专门用于文本的操作
import json with open('djh', 'r', encoding="utf-8") as f_r: data = json.load(f_r)//两步合在一起 相当于 import json with open('djh', 'r', encoding="utf-8") as f_r: r = f_r.read() data = json.load(r)
pickle模块
pickle模块是不可以跨语言的,其实pickle模块和json模块的用法一模一样,甚至连方法的名字都一样,比如 load() dump() 之类的,而方法的用法也是一模一样,参数也是!只不过pickle是将数据结构变成 bytes 类型,也就是字节类型,而json是变成字符串类型,区别在于一个数据类型 json.loads() 之后存进一个文本里是可看的,人类是看得懂的,但是pickle.loads()之后存进文本是不可看的,也就是人类是看不懂得!
当然 因为pickle 是将数据结构变成字节得=的形式,所以写进文件时需要以 "wb" 方式写入,读取时要以 "rb" 方式读取
shelve模块
shelve模块也是不可以跨语言的,其实shelve模块是对pickle模块进行了更高级的封装,让我们操作起来就像是对字典进行操作一样,仅此而已,他会生成3个文件,这三个文件我们都是看不懂的
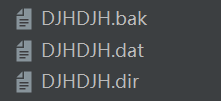
import shelve f = shelve.open('DJHDJH')//先打开一个文件 f['name'] = {"name":"DJH","age":19}//就像字典添加一样添加元素 f['age'] = 19//同上 a = f.get('name')['name']//想字典取值一样,只不过这里是借助get()方法 b = f.get('age') print(a,b) f.close() 结果 DJH 19
