AARRR:2.3
1.留存指标
新用户的留存和所有用户留存不太一样
方法一:python
import pandas as pd
df=pd.read_csv('user_behavior.csv')
df=df[['user_id','timestamps']]
df['timestamps']=pd.to_datetime(df['timestamps'],unit='s')
df['date']=df['timestamps'].dt.strftime('%Y-%m-%d').astype('datetime64[ns]')
new=pd.merge(df,df,on='user_id',how='left')
new=new[['user_id','date_x','date_y']]
new['diff']=(new['date_y']-new['date_x']).dt.days
new=new.drop_duplicates()
new=new[(new['diff']==0)|(new['diff']==1)|(new['diff']==3)|(new['diff']==7)]
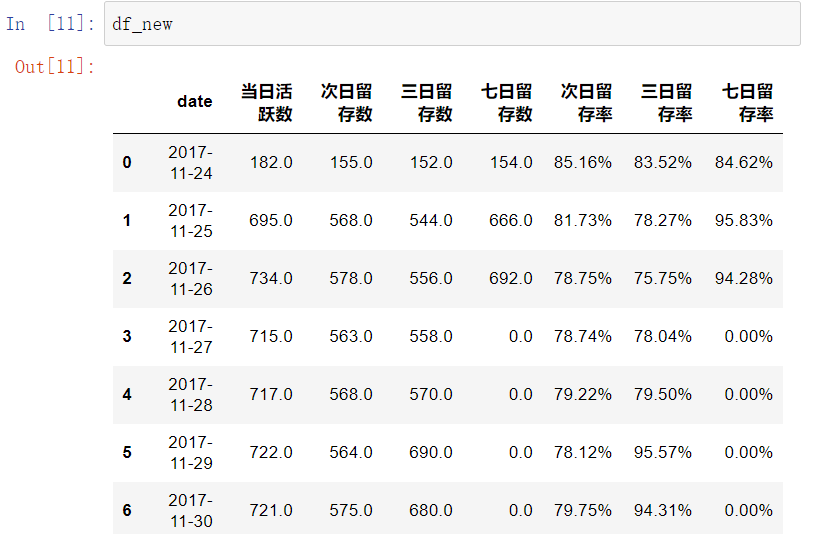
df_new=new.pivot_table(index='date_x',columns='diff',values='user_id',aggfunc='count').reset_index().fillna(0)
df_new.columns=['date','当日活跃数','次日留存数','三日留存数','七日留存数']
df_new['次日留存率']=(df_new['次日留存数']/df_new['当日活跃数']).apply(lambda x: format(x,'.2%'))
df_new['三日留存率']=(df_new['三日留存数']/df_new['当日活跃数']).apply(lambda x: format(x,'.2%'))
df_new['七日留存率']=(df_new['七日留存数']/df_new['当日活跃数']).apply(lambda x: format(x,'.2%'))
或者先去重在连接,而不是先连接在去重:
df1=df.drop_duplicates(subset=['user_id','date'])
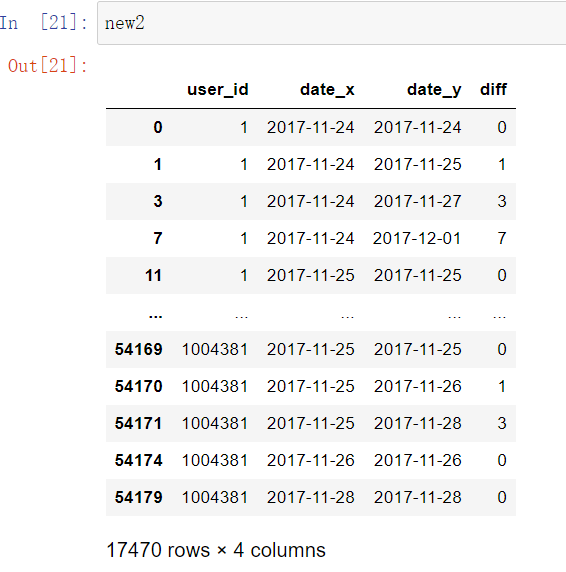
new2=pd.merge(df1,df1,on='user_id',how='left')
new2=new2[['user_id','date_x','date_y']]
new2['diff']=(new2['date_y']-new2['date_x']).dt.days
new2=new2[(new2['diff']==0)|(new2['diff']==1)|(new2['diff']==3)|(new2['diff']==7)]
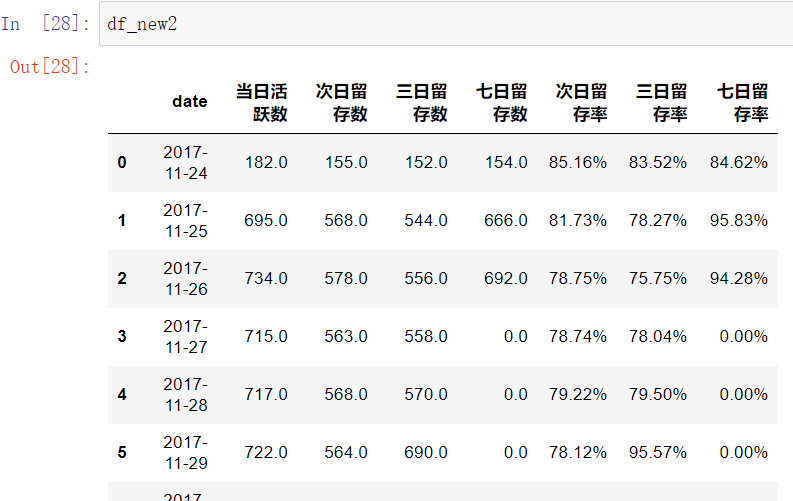
df_new2=new2.pivot_table(index='date_x',columns='diff',values='user_id',aggfunc='count').reset_index().fillna(0)
df_new2.columns=['date','当日活跃数','次日留存数','三日留存数','七日留存数']
df_new2['次日留存率']=(df_new2['次日留存数']/df_new2['当日活跃数']).apply(lambda x: format(x,'.2%'))
df_new2['三日留存率']=(df_new2['三日留存数']/df_new2['当日活跃数']).apply(lambda x: format(x,'.2%'))
df_new2['七日留存率']=(df_new2['七日留存数']/df_new2['当日活跃数']).apply(lambda x: format(x,'.2%'))
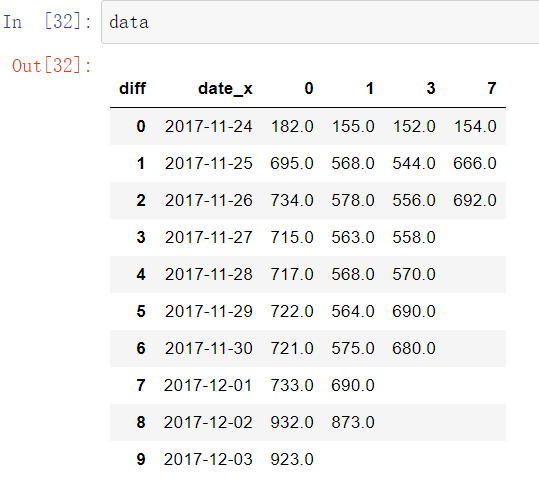
或者这样去重:
data = pd.pivot_table(new3,values='user_id',index='date_x',columns='diff',
aggfunc=lambda x:len(x.unique()),
fill_value='').reset_index()
方法二:mysql
先连接再去重比较慢,python 还能做,但是mysql运行很久
select distinct user_id, date1
from userbehavior
select * from
(select distinct user_id, date1
from userbehavior
) a
left join
(select distinct user_id, date1
from userbehavior
) b
on a.user_id = b.user_id
作差就能得到相差的天数:
select 日期1,count(distinct user_id),
sum(case when 天数=1 then 1 else 0 end) as '次日留存数',
sum(case when 天数=3 then 1 else 0 end) as '3日留存数',
sum(case when 天数=7 then 1 else 0 end) as '7日留存数',
sum(case when 天数=1 then 1 else 0 end)/count( user_id) as '次日留存率',
sum(case when 天数=3 then 1 else 0 end)/count( user_id) as '3日留存率',
sum(case when 天数=7 then 1 else 0 end)/count( user_id) as '7日留存率'
from
( select a.user_id,a.date1 as '日期1',b.date1 as '日期2',datediff(b.date1,a.date1) as '天数' from
(select user_id, date1
from userbehavior
group by user_id, date1
order by date1
) a
left join
(select user_id, date1
from userbehavior
group by user_id, date1
order by date1
) b
on a.user_id = b.user_id
) c
#where 日期1 >= '2017-11-24' and 日期1 <= '2017-12-04'
group by 日期1
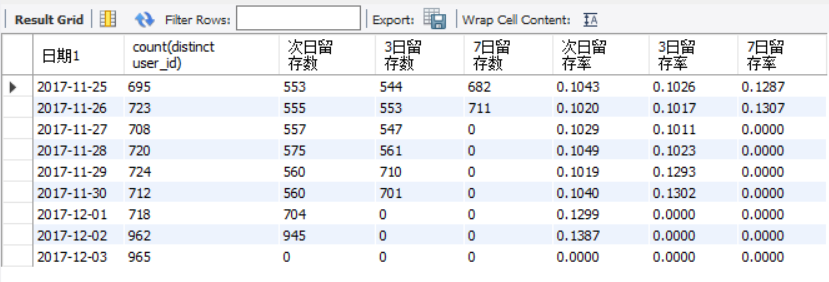
但是得到的活跃度指标比python 少了一部分,为啥?先连接没法计算,大约1000万条数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号