

实习2
需求:
将同一个身份证出现不同地市的提取出来,其余的提取出来。例如:
广州 id1;广州 id2;深圳 id1;广州 id2;惠州 id3;就是把id1对应的两条数据取出来,其余的取出来。
数据共有16673条,字段如下:
解决一:mysql提取数据
经过尝试加深了对mysql的理解:group by和聚合函数同时使用的易错点
(1):
select *,count(distinct 地市) as num
from cbss
having num > 1
结果返回的是一条语句,因为*返回16673条,聚合函数count返回1条,所以结果是随机返回一条。
(2):
select *,count(distinct 地市) as num
from cbss
group by 身份证
having num > 1
用身份证进行分组,结果返回741条语句,同样有问题,根据num的计算,结果也只是7980条数据
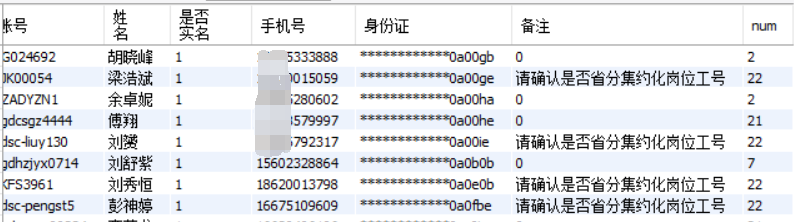
问题在于类似广州 id1;广州 id1;深圳 id1根据身份id分组只会返回两条数据。
方法一:因为(2)找出来身份,但没找出数量,先把身份选出来,再用in 即可
select * from cbss
where 身份证 in
(select 身份证 from
(select *,count(distinct 地市) as num
from cbss
group by 身份证
having num > 1
) t1
)
一共返回8746条数据
方法二:借鉴参考网上的思路,就是表连接运行的速度慢了点
select * from cbss
where 身份证 in
(
select 身份证
from cbss A
group by 身份证
having
(select count(distinct 地市) from cbss B
where A.身份证 = B.身份证) > 1
)
方法三:
select * from cbss
where 身份证 in
(
select 身份证 from
(select 身份证,count(distinct 地市) as num
from cbss
group by 身份证
) A
where num > 1
)
和一区别是严格按照原则:select 后的语句要么是聚合函数,要么在group by 后面。
然后其余的使用not in即可
select * from cbss
where 身份证 not in
(
select 身份证 from
(select 身份证,count(distinct 地市) as num
from cbss
group by 身份证
) A
where num > 1
)
或者num=1
select * from cbss
where 身份证 in
(
select 身份证 from
(select 身份证,count(distinct 地市) as num
from cbss
group by 身份证
) A
where num = 1
)
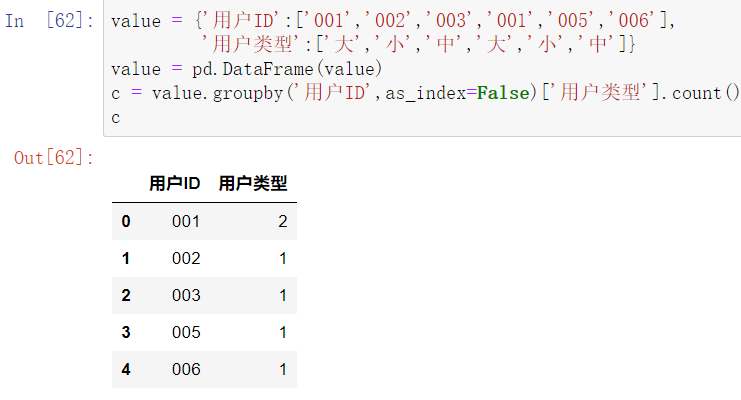
解决二:python 函数
导入数据:

cbss_1 = cbss.drop_duplicates(subset = ['地市','身份证 - 转码'])
首先进行去重,原因是groupby函数在分组汇总时会把形如
广州 id1;广州id1和深圳id3,广州id3当成同一类,个数均为2,去重后为11038条数据。
然后根据身份证分组,计算地市的数量,把数量大于1的信息取出来。共741条数据。
最后把源数据包含这741条的身份证信息取出来。共8746条数据。

注意:as_index的设置,不设置默认为True,对应的序列,不好处理;设置的话,对应的是dataframe,方便处理,又能导入导出,很关键!
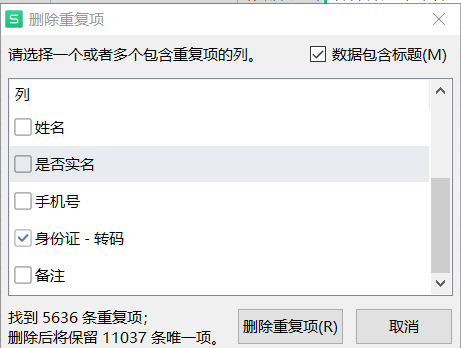
解决三:excel
首先进行去重,根据身份证和地市去重
然后通过数据透视表,将身份证作为行,地市作为值计数,
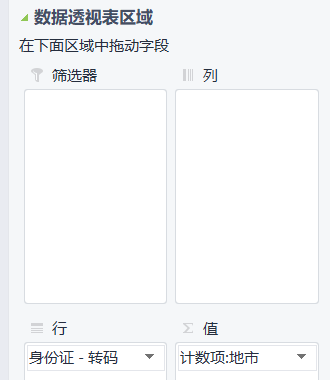
然后通过筛选大于1的对应的就是想要的身份信息
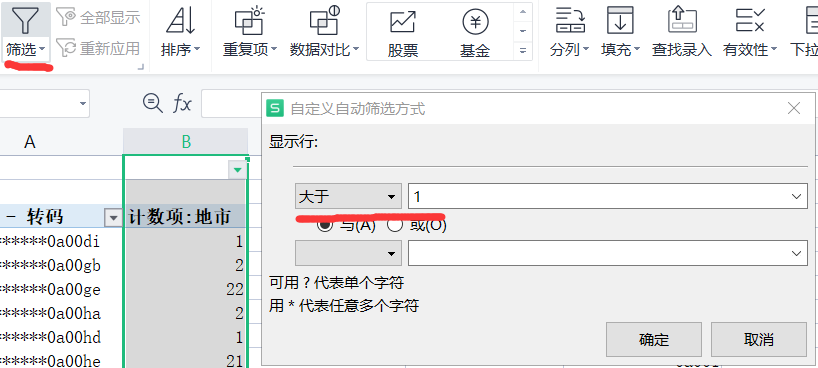
得到741条数据。
最后利用实习1中类似:=IFERROR(VLOOKUP(G2,Sheet2!E:E,1,0),0),删除为0的值。
最终得到8746条数据
over!
小补充:
1.快速查看数量,直接点击表头,下方会自动显示计数,求和,平均值信息

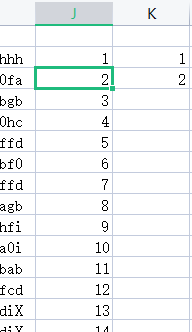
2.快速填充,单元格内右下方出现+号,双击即可快速填充
注意:左边不能有空列,比如在J处可以,在K处不可以。
参考:
类似sql中in 和not in 的pandas函数:https://blog.csdn.net/weixin_43064185/article/details/91374033
groupby分组后保持dataframe格式:https://blog.csdn.net/jcjic/article/details/118110092


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!