

学习5:58二手房
1.几个概念
'''
聚焦爬虫:爬取页面中的页面内容
--编码流程:
-指定url
-发起请求
-获取相应数据
-数据解析
-持久化存储
数据解析分类:
--正则
--bs4
--xpath(重点)
数据解析原理概述:
--解析的局部文本内容都会在标签之间或者标签对应的属性中进行存储
--1.进行指定标签的定位
--2.标签或者标签对应的属性中存储的数据值进行提取(解析)
'''
import requests
#爬取图片
url='https://bkimg.cdn.bcebos.com/pic/e61190ef76c6a7efce1b559256aeb851f3deb48fc870'
#content返回的是二进制形式的图片数据
#text字符创,content二进制,
img_data = requests.get(url=url).content
with open('./elephant.jpg','wb') as fp:
fp.write(img_data)

'''
-xpath解析:最常用且便捷高效的解析方式
--1.实例化一个etree对象,且需要被解析的页面源码数据加载到该对象中
--2.调用etree对象中的xpath方法结合xpath表达式实现标签的定位和捕获
-环境的安装:
--pip install lxml
-如何实例化一个etree对象
--将本地的html文档中的源码数据加载到etree对象中
etree.parse(filepath)
--将互联网上捕获的源码数据加载到该对象中
etreeHTML
2.实例:二手房爬取
'''
# -*- coding: utf-8 -*-
# 目标:通过xpath表达式爬取58同城二手房标题信息
# 导入lxml库里的etree对象:该对象中包含有我们需要的xpath方法
# 导入网页请求库:
import requests
from lxml import etree
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
url = 'https://anqiu.58.com/ershoufang/'
page_text = requests.get(url = url,headers = headers).text
tree = etree.HTML(page_text)
li_List = tree.xpath('//section[@class = "list"]/div')
fp = open('58.txt','w',encoding='utf-8')
for li in li_List:
title = li.xpath('./a/div[2]//div/h3/text()')[0]
print(title)
fp.write(title+'\n')
注意:如果返回空列表,可能是访问频繁,要先登录进行滑动验证,然后在进行爬取
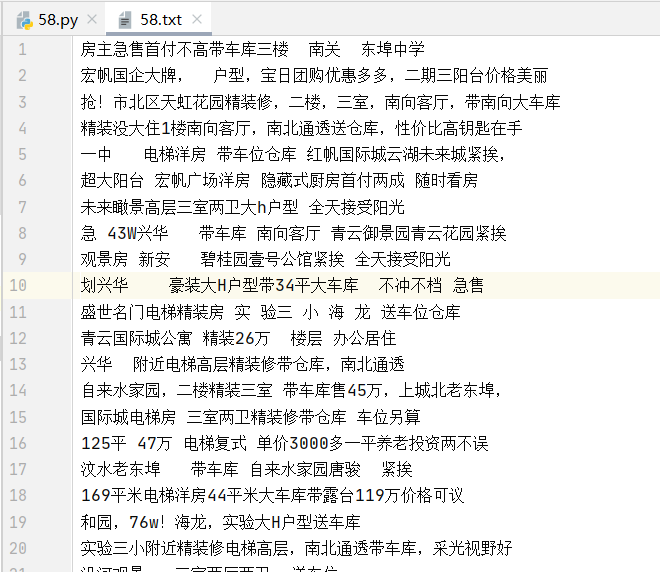
58.txt结果如下:
参考:
https://www.bilibili.com/video/BV1ha4y1H7sx?p=25下相关评论


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异